Datenanalyse beginnend mit Python (Datenvorverarbeitung - maschinelles Lernen)
Einführung
Für Anfänger möchte ich von der Datenvorverarbeitung mit Python bis zur Modellkonstruktion für maschinelles Lernen erklären. Verwenden Sie die Gradientenverstärkung für maschinelles Lernen.
Quellcode https://gitlab.com/ceml/qiita/-/blob/master/src/python/notebook/first_time_ml.ipynb
Inhalt dieses Artikels
Inhaltsverzeichnis
-
- Datenvorverarbeitung 1-1. Daten lesen 1-2. Daten kombinieren 1-3. Defekte Landergänzung 1-4. Feature-Erstellung 1-5. Datenaufteilung
- Maschinelles Lernen 2-1. Datensatzerstellung und Modelldefinition 2-2. Modellschulung und Bewertung 2-3. Bestätigen Sie die Wichtigkeit der Merkmalsmenge
Über den Datensatz
・ Bereitgestellt von: California Institute of Technology ・ Inhalt: Testdaten von Patienten mit Herzerkrankungen ・ URL: https://archive.ics.uci.edu/ml/datasets/Heart+Disease ・ Processed.cleveland.data, reprocessed.hungarian.data, reprocessed.hungarian.data, Processed.switzerland unter der obigen URL
- Siehe unten für den Daten-Download Datenanalyse beginnend mit Python (Datenvisualisierung 1) https://qiita.com/CEML/items/d673713e25242e6b4cdb
Analysezweck
Der Datensatz klassifiziert den Zustand des Patienten in fünf Klassen. Lassen Sie maschinelles Lernen diese fünf Klassen vorhersagen. Modelle für maschinelles Lernen verwenden die Gradientenverstärkung.
1. Datenvorverarbeitung
1.1 Daten laden
import pandas as pd
columns_name = ["age", "sex", "cp", "trestbps", "chol", "fbs", "restecg", "thalach", "exang", "oldpeak","slope","ca","thal","class"]
cleveland = pd.read_csv("/Users/processed.cleveland.data",header=None, names=columns_name)
hungarian = pd.read_csv("/Users/reprocessed.hungarian.data",sep=' ',header=None, names=columns_name)
va = pd.read_csv("/Users/processed.va.data",header=None, names=columns_name)
switzerland = pd.read_csv("/Users/processed.switzerland.data",sep=",",header=None, names=columns_name)
Der Sep, der dem Argument in Hubgarian und der Schweiz gegeben wurde, ist ein Zeichenbegrenzer. Da alle Daten dieser beiden Daten in einer Spalte enthalten sind, werden sie für jede Spalte durch sep getrennt.
- Einzelheiten zu Spalten finden Sie im Referenzartikel zum Herunterladen von Daten.
1-2. Daten kombinieren
Alle Daten können gleichzeitig kombiniert und verarbeitet werden.
merge_data = pd.concat([cleveland,hungarian,va,switzerland],axis=0)
print(merge_data.shape)
# output
'''(921, 14)'''
1-3. Ergänzung von mangelhaftem Land
In diesen Daten '? Da es eingegeben wurde, konvertieren Sie es in null und konvertieren Sie die Daten dann in einen numerischen Typ. Da wir diesmal die Gradientenverstärkung verwenden, verwenden wir den Nullwert unverändert, ohne ihn zu konvertieren. Bei anderen Modellen müssen wir jedoch Null durch einen numerischen Wert ersetzen.
merge_data.replace({"?":np.nan},inplace=True)
merge_data = merge_data.astype("float")
#Zeile fehlende Klasse löschen
merge_data.dropna(subset=["class"], inplace=True)
#Fehlende Wertbestätigung
print(merge_data.isnull().sum())
# output
'''
age 0
sex 0
cp 0
trestbps 58
chol 7
fbs 82
restecg 1
thalach 54
exang 54
oldpeak 62
slope 119
ca 320
thal 220
class 0
dtype: int64
'''
1-4. Feature-Erstellung
Dies ist der Schritt zum Erstellen einer neuen Feature-Menge aus der Feature-Menge. Normalerweise würde ich diesen Schritt zuerst überspringen und ein Modell erstellen, das nur die gesammelten Daten verwendet. Basierend auf der Genauigkeit dort werden wir eine neue Feature-Menge erstellen, um die Genauigkeit zu verbessern. Dieses Mal werde ich es von Anfang an erstellen, da es sich um ein Tutorial handelt. Erstellen Sie beispielsweise eine Differenz zum Durchschnittsalter als Merkmalsmenge.
merge_data['diff_age'] = merge_data['age'] - merge_data['age'].mean()
1-5. Datenaufteilung
Teilen Sie die Daten in drei Teile: Trainieren, Testen und Validieren. Eine Sache, die Sie zu diesem Zeitpunkt beachten sollten, ist, dass der Pathologieunterricht unausgewogen ist. Schauen wir es uns konkret an.
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
merge_data["class"].hist()
plt.xlabel("class")
plt.ylabel("number of sample")
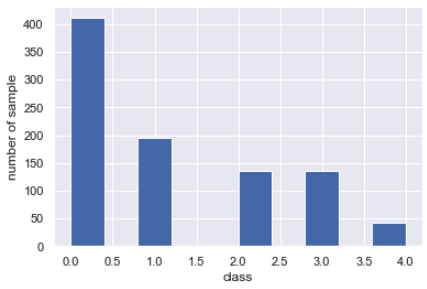
Es gibt viele 0 Klassen von gesunden Menschen, und die Anzahl schwerkranker Patienten nimmt ab. Es gibt viele solcher Ungleichgewichtsprobleme bei echten Problemen.
Sie müssen die Daten aufteilen, ohne diesen Prozentsatz zu ändern.
from sklearn.model_selection import StratifiedShuffleSplit
#Trennen Sie die Zielvariable
X = merge_data.drop("class",axis=1).values
y = merge_data["class"].values
columns_name = merge_data.drop("class",axis=1).columns
#Definieren Sie eine zu klassifizierende Funktion
sss = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=0)
def data_split(X,y):
for train_index, test_index in sss.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
X_train = pd.DataFrame(X_train, columns=columns_name)
X_test = pd.DataFrame(X_test, columns=columns_name)
return X_train, y_train, X_test, y_test
# train, test,Getrennt in val
X_train, y_train, X_test, y_test = data_split(X, y)
X_train, y_train, X_val, y_val = data_split(X_train.values, y_train)
#Formbestätigung
print("train shape", X_train.shape)
print("test shape", X_test.shape)
print("validation shape", X_val.shape)
#Überprüfen Sie den Klassenprozentsatz
plt.figure(figsize=(20,5))
plt.subplot(1,3,1)
plt.hist(y_train)
plt.subplot(1,3,2)
plt.hist(y_test)
plt.subplot(1,3,3)
plt.hist(y_val)
# output
'''
train shape (588, 14)
test shape (184, 14)
validation shape (148, 14)
'''
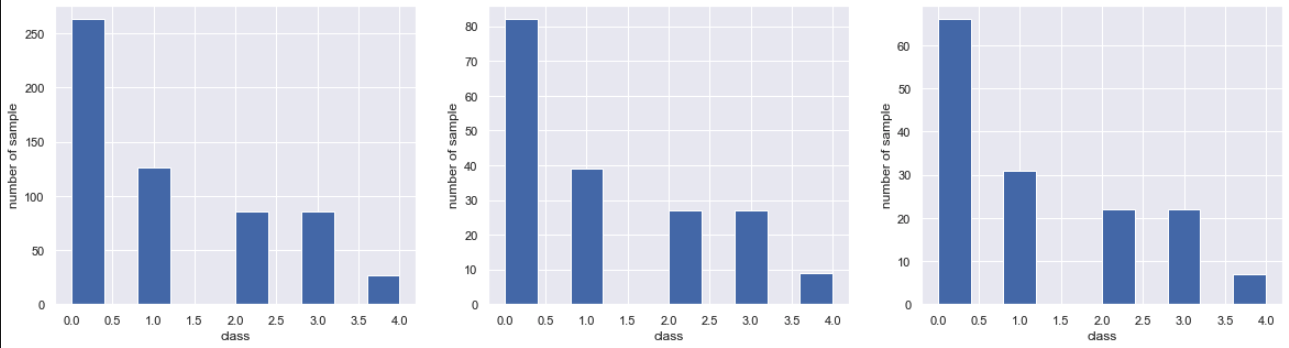 Es kann geteilt werden, ohne das Verhältnis zu ändern.
Es kann geteilt werden, ohne das Verhältnis zu ändern.
2. Maschinelles Lernen
2.1 Datensatzerstellung und Modelldefinition
Erstellen Sie einen Datensatz und geben Sie ihm Parameter.
import lightgbm as lgb
#Erstellen Sie einen Datensatz
train = lgb.Dataset(X_train, label=y_train)
valid = lgb.Dataset(X_val, label=y_val)
#Modellparameter einstellen
params = {
'reg_lambda' : 0.2,
'objective': 'multiclass',
'metric': 'multi_logloss',
'num_class': 5,
'reg_alpha': 0.1,
'min_data_leaf': 100,
'learning_rate': 0.025,
# 'feature_fraction': 0.8,
# 'bagging_fraction': 0.8
}
2.2 Modellschulung und -bewertung
Geben Sie beim Training eines Modells ein frühzeitiges Anhalten an und beenden Sie das Lernen, wenn der Verlust nicht abnimmt. Die Vorhersage ist am wahrscheinlichsten mit Argmax. Die Bewertung basiert auf der Mischmatrix und dem Kappa-Koeffizienten. Nur eine Holdout-Überprüfung wird ohne Kreuzvalidierung durchgeführt.
#Trainiere das Modell
model = lgb.train(params,
train,
valid_sets=valid,
num_boost_round=5000,
early_stopping_rounds=500)
#Prognose
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_pred = np.argmax(y_pred, axis=1)
#-------------------------------------------------------------------------
from sklearn.metrics import confusion_matrix
from sklearn.metrics import cohen_kappa_score
#
result_matrix = pd.DataFrame(confusion_matrix(y_test,y_pred))
#
class_accuracy = [(result_matrix[i][i]/result_matrix[i].sum())*1 for i in range(len(result_matrix))]
result_matrix[5] = class_accuracy
#
kappa = cohen_kappa_score(y_test,y_pred)
print("kappa score:",kappa)
# plot
plt.figure(figsize=(7,5))
sns.heatmap(result_matrix,annot=True,cmap="Blues",cbar=False)
plt.xticks([5.5,4.5,3.5,2.5,1.5,0.5], ["accuracy",4, 3, 2, 1,0])
plt.ylabel('Truth',fontsize=13)
plt.xlabel('Prediction',fontsize=13)
plt.tick_params(labelsize = 13)
# output
'''
kappa score: 0.3368649587494572
'''
lgb.plot_importance(model, figsize=(8, 6))
plt.show()
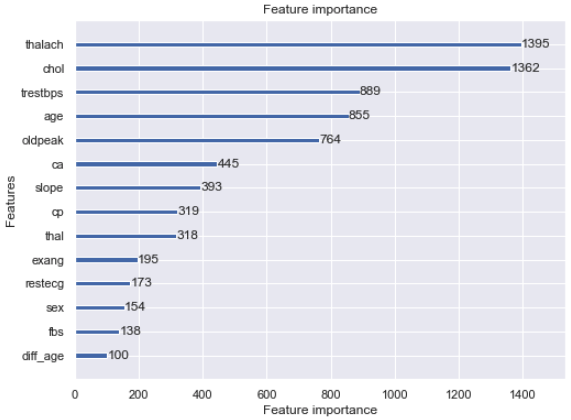
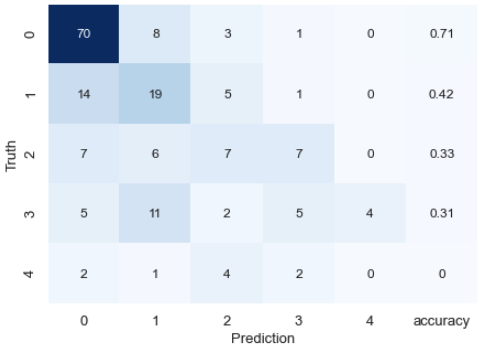
Erstellen Sie eine gemischte Matrix. Berechnen Sie die richtige Antwortrate für jede Klasse. Berechnen Sie den Kappa-Koeffizienten. Das Ergebnis ist nicht sehr gut. Überprüfen Sie außerdem die Wichtigkeit der Merkmalsmenge. 2-3. Bestätigen der Wichtigkeit der Feature-Menge Das Ergebnis war, dass die erstellte Feature-Menge die niedrigste war.
abschließend
Dieses Mal haben wir von der Datenvorverarbeitung bis zur Modellbewertung durch Holdout gearbeitet. Feature Engineering und hohe Parametersuche sind erforderlich, um die Genauigkeit zu verbessern. Darüber hinaus ist eine Kreuzvalidierungsbewertung erforderlich, um die Genauigkeit sicherzustellen.
Recommended Posts