Datenanalyse beginnend mit Python (Datenvisualisierung 1)
Einführung
Dies ist der erste Beitrag von CEML (Clinical Engineer Machine Learning). Dieses Mal möchte ich die Datenanalyse mit Python für Anfänger erklären. Quellcode https://gitlab.com/ceml/qiita/-/blob/master/src/python/notebook/first_time_data_analysis.ipynb
Inhalt dieses Artikels
Wir erklären das Lesen von Daten bis zur einfachen Datenanalyse anhand eines Datensatzes, der der Öffentlichkeit kostenlos zugänglich ist.
Über den Datensatz
・ Bereitgestellt von: California Institute of Technology ・ Inhalt: Testdaten von Patienten mit Herzerkrankungen ・ URL: https://archive.ics.uci.edu/ml/datasets/Heart+Disease
- Verwenden Sie nur verarbeitete.cleveland.data in der obigen URL.
Analysezweck
Der Datensatz klassifiziert den Zustand des Patienten in fünf Klassen. Ich werde mit der Analyse fortfahren, um die Merkmale jeder Klasse zu erfassen.
Daten herunterladen
Greifen Sie auf die obige URL zu und laden Sie process.cleveland.data im Datenordner herunter.
Daten lesen
Importieren Sie Pandas und lesen Sie die Daten mit der read_csv-Methode von pandas. Der Spaltenname wird beim Lesen der Daten angegeben. Listen Sie die Spaltennamen auf und übergeben Sie sie als Argumente an Nemes in der Methode read_csv.
import pandas as pd
columns_name = ["age", "sex", "cp", "trestbps", "chol", "fbs", "restecg", "thalach", "exang", "oldpeak","slope","ca","thal","class"]
data = pd.read_csv("/Users/processed.cleveland.data", names=columns_name)
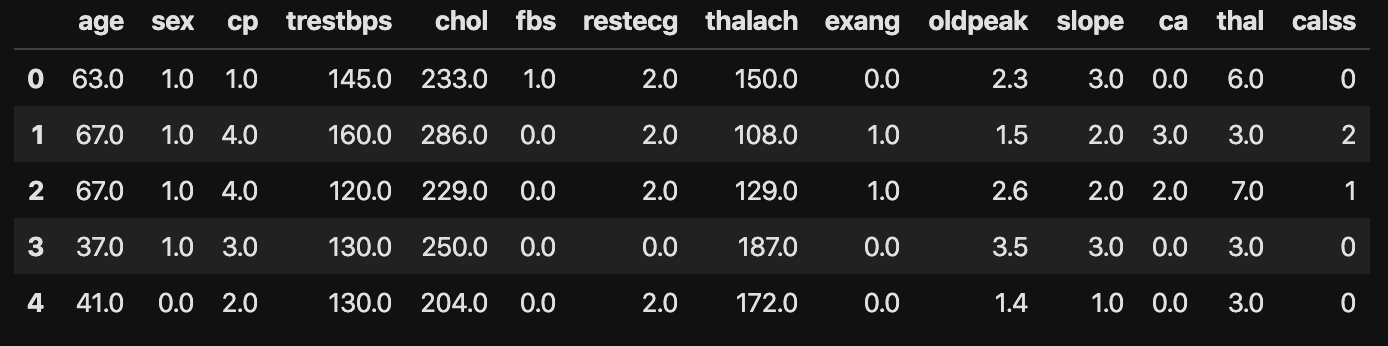
#Zeigen Sie die obersten 5 Datenzeilen an
data.head()
Das Folgende sind die gelesenen Daten.
 Ich werde die Kolumne kurz beschreiben. Einzelheiten entnehmen Sie bitte der Datenquelle.
· Erziehen
・ Geschlecht (1 = männlich; 0 = weiblich)
・ Cp: Brustschmerztyp
1:typical angina 2: atypical angina 3: non-anginal pain
4: asymptomatic
・ Trestbps: Ruheblutdruck (in mm Hg bei Krankenhauseinweisung)
・ Chol: Serum cholestoral in mg / dl
・ Fbs: Nüchternblutzucker> 120 mg / dl) (1 = wahr; 0 = falsch)
・ Restecg: Ruhende elektrokardiographische Ergebnisse
0: normal
1: having ST-T wave abnormality
(T wave inversions and/or ST elevation or depression of > 0.05 mV)
2: showing probable or definite left ventricular hypertrophy by Estes'criteria
・ Thalach: maximale Herzfrequenz erreicht
・ Exang: Belastungsinduzierte Angina (1 = Ja; 0 = Nein)
・ Oldpeak: ST-Depression durch körperliche Betätigung im Verhältnis zur Ruhe
・ Steigung: Die Steigung des ST-Segments der Spitzenübung
1: upsloping
2: flat
3: downsloping
・ Ca: Anzahl der durch Flourosopie gefärbten Hauptgefäße (0-3)
・ Thal: 3 = normal; 6 = fester Defekt; 7 = reversibler Defekt
・ Klasse: 0 ~ 5 (0 ist normal, je größer die Zahl, desto schlechter)
Ich werde die Kolumne kurz beschreiben. Einzelheiten entnehmen Sie bitte der Datenquelle.
· Erziehen
・ Geschlecht (1 = männlich; 0 = weiblich)
・ Cp: Brustschmerztyp
1:typical angina 2: atypical angina 3: non-anginal pain
4: asymptomatic
・ Trestbps: Ruheblutdruck (in mm Hg bei Krankenhauseinweisung)
・ Chol: Serum cholestoral in mg / dl
・ Fbs: Nüchternblutzucker> 120 mg / dl) (1 = wahr; 0 = falsch)
・ Restecg: Ruhende elektrokardiographische Ergebnisse
0: normal
1: having ST-T wave abnormality
(T wave inversions and/or ST elevation or depression of > 0.05 mV)
2: showing probable or definite left ventricular hypertrophy by Estes'criteria
・ Thalach: maximale Herzfrequenz erreicht
・ Exang: Belastungsinduzierte Angina (1 = Ja; 0 = Nein)
・ Oldpeak: ST-Depression durch körperliche Betätigung im Verhältnis zur Ruhe
・ Steigung: Die Steigung des ST-Segments der Spitzenübung
1: upsloping
2: flat
3: downsloping
・ Ca: Anzahl der durch Flourosopie gefärbten Hauptgefäße (0-3)
・ Thal: 3 = normal; 6 = fester Defekt; 7 = reversibler Defekt
・ Klasse: 0 ~ 5 (0 ist normal, je größer die Zahl, desto schlechter)
Datenvorverarbeitung
Überprüfen Sie diesmal als Vorverarbeitung den Datentyp jeder Spalte. Wenn es sich nicht um einen numerischen Typ handelt, konvertieren Sie ihn in einen numerischen Typ. Es fehlt ein Wert, der als? Eingetragen wurde. Ersetzen Sie ihn also durch null.
#Überprüfen Sie die Art der Daten
data.dtypes
#Typ in float konvertieren ,? Ersetzt durch einen Nullwert
data = data.replace("?",np.nan).astype("float")
Überprüfen Sie die grundlegenden Statistiken und fehlenden Werte der Daten
Bestätigung für jeden Funktionsbetrag (variabel)
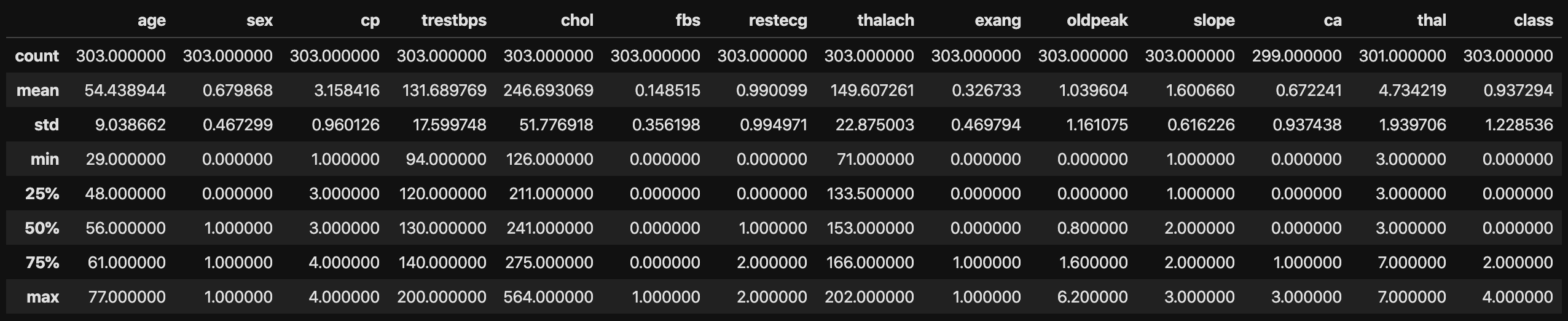
#Statistiken berechnen
data.describe()
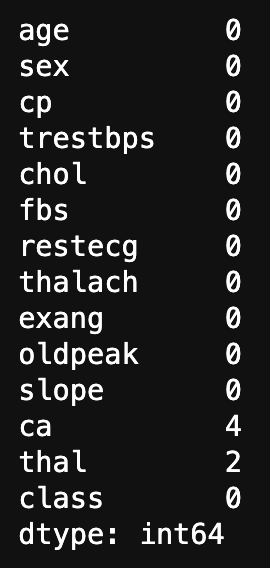
#Fehlende Werte zählen
data.isnull().sum()
Damit können Sie die fehlenden Werte in den Statistiken für jede Spalte sehen.
Die folgende Abbildung zeigt die Berechnungsergebnisse der Statistik.
Bestätigung jedes Merkmalsbetrags (variabel) für jede Klasse
Hier ist das Hauptproblem. Als Bestätigung dient diese Analyse dazu, die Merkmale jeder Klasse zu verstehen. Verwenden Sie in diesem Fall die Methode pandas group_by.
#Gruppieren nach Klassenspalte
class_group = data.groupby("class")
#Wenn Sie eine Klasse angeben und Statistiken abrufen
# class_group.get_group(0).describe()
#Geben Sie Optionen an, damit alle Spalten angezeigt werden können (Notizbuch).
pd.options.display.max_columns = None
#Statistikanzeige für alle Klassen
class_group.describe()
Das Folgende zeigt die Statistiken für alle Klassen.

Es ist einfach. Da die Merkmalsmenge (Variable) und die Anzahl der klassifizierten Klassen (5) in diesen Daten gering sind, kann dies durch Anzeigen der Statistiken aller Klassen bestätigt werden. Wenn jedoch viele davon vorhanden sind, werden alle angezeigt und bestätigt. Es wird schwieriger.
Daten visualisieren
Überprüfen Sie die Verteilung der einzelnen Funktionen (Variablen).
Überprüfen Sie die Verteilung der Daten im Histogramm.
data.hist(figsize=(20,10))
#Verhindern Sie, dass sich die Diagramme überlappen
plt.tight_layout()
plt.show()
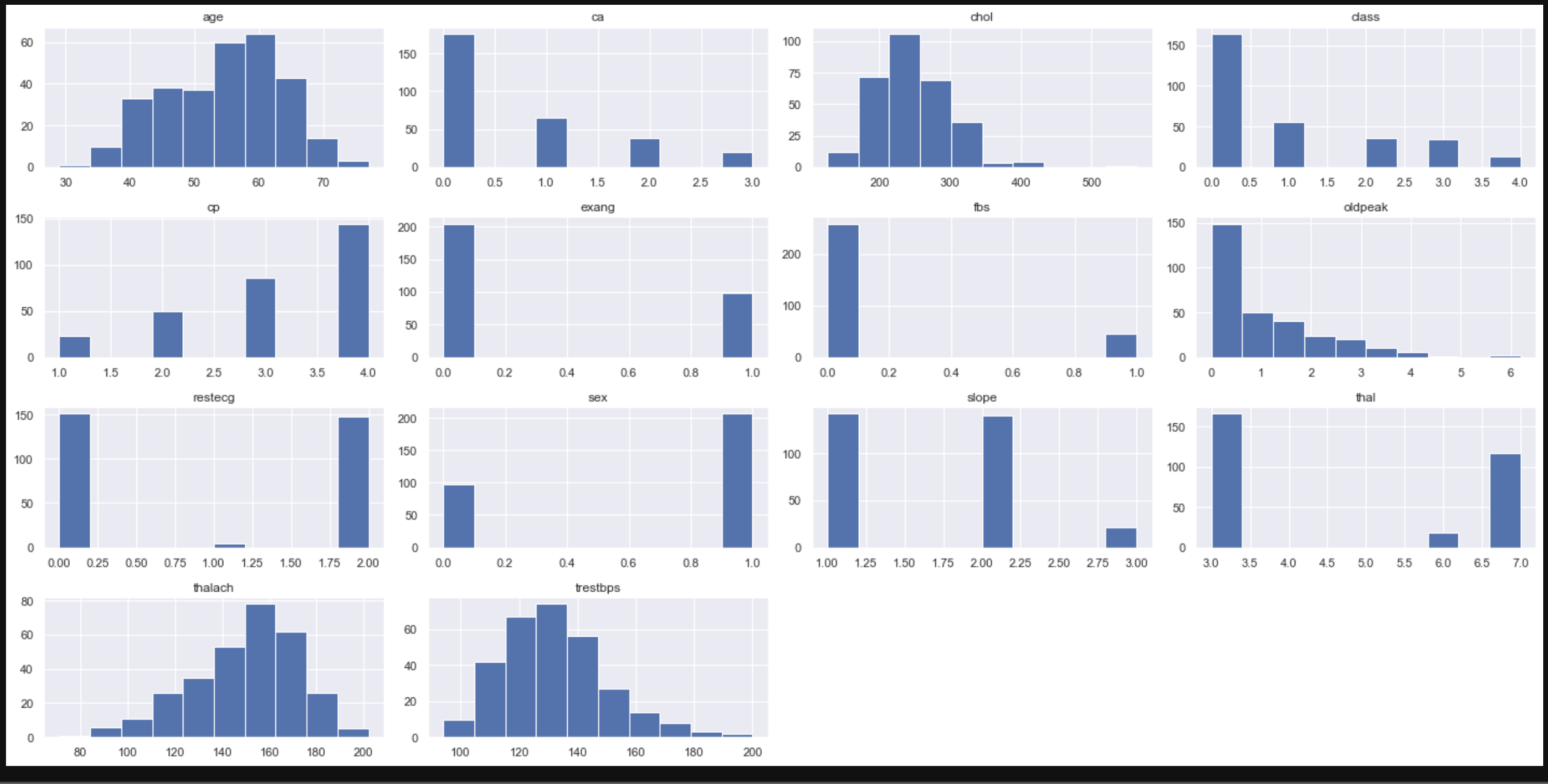
Zeigen Sie für jede Klasse ein Histogramm jedes Features (einer Variablen) an
#Handlung für sich
# class_group["age"].hist(alpha=0.7)
# plt.legend([0,1,2,3,4])
#Zeige alles
plt.figure(figsize=(20,10))
for n, name in enumerate(data.columns.drop("class")):
plt.subplot(4,4,n+1)
class_group[name].hist(alpha=0.7)
plt.title(name,fontsize=13,x=0, y=0)
plt.legend([0,1,2,3,4])
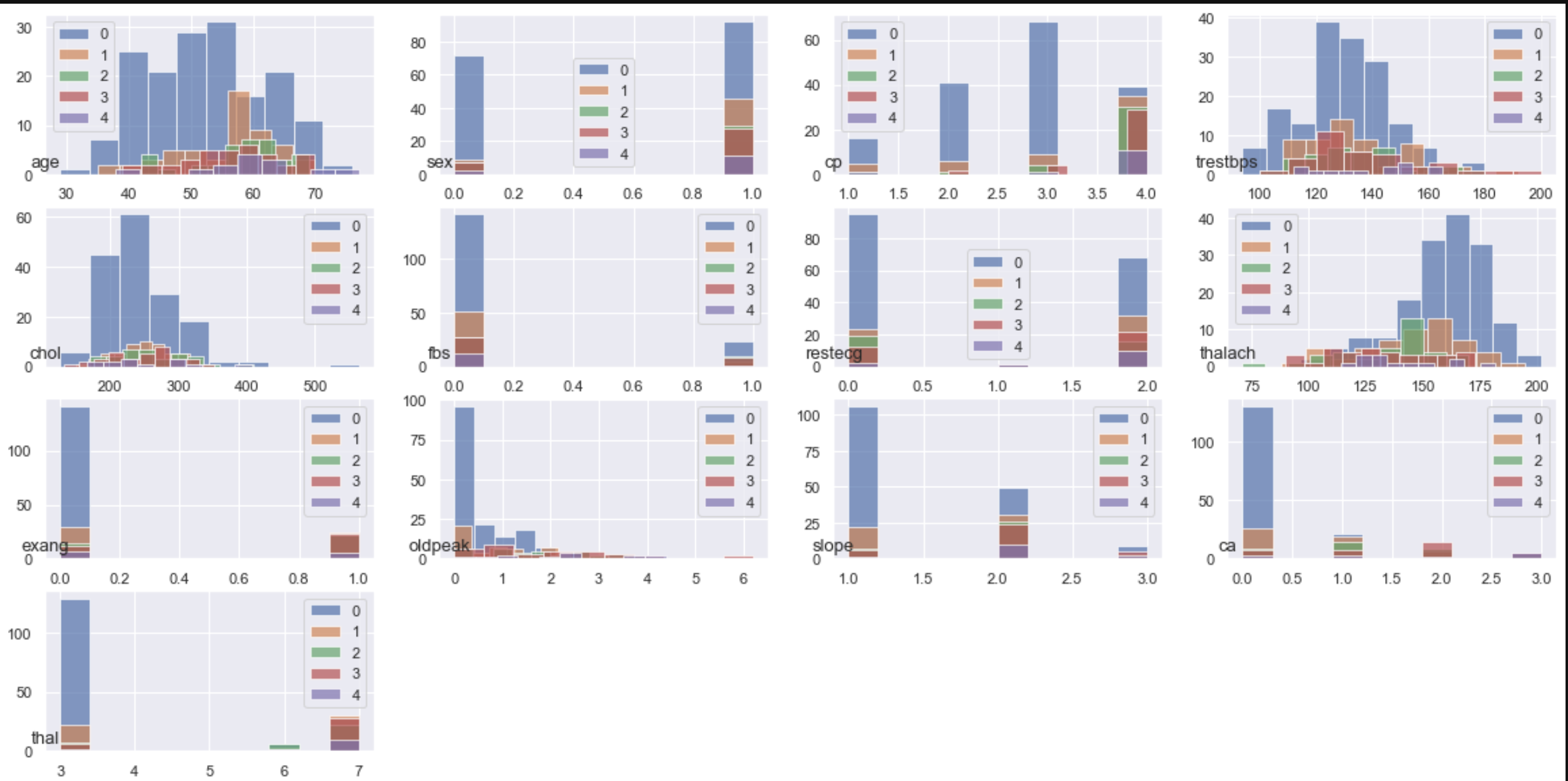
Zeigen Sie den Durchschnittswert und die Varianz jeder Merkmalsmenge (Variable) für jede Klasse in einem Balkendiagramm an
#Handlung für sich
# class_group.mean()["age"].plot.bar(yerr=class_group.std()["age"])
#Zeige alles
plt.figure(figsize=(20,10))
for n, name in enumerate(data.columns.drop("class")):
plt.subplot(4,4,n+1)
class_group.mean()[name].plot.bar(yerr=class_group.std()[name], fontsize=8)
plt.title(name,fontsize=13,x=0, y=0)
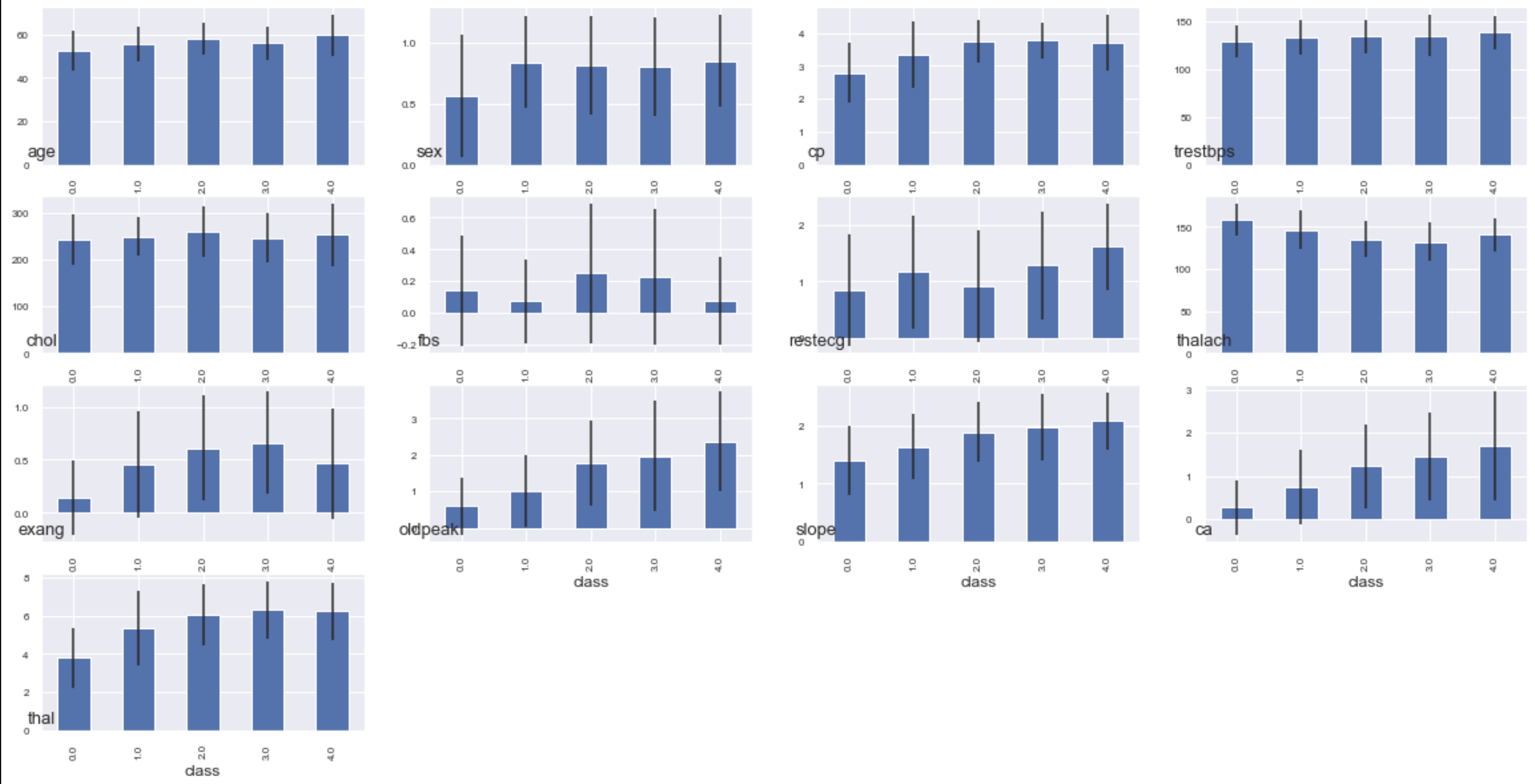
Ich habe versucht, es grob zu visualisieren, aber das Histogramm für jede Klasse kann nicht so gut gesehen werden, wie es ist. Das nächste Mal werde ich anhand von Grafiken, die verschoben werden können, und 3D-Plots analysieren.
Datenanalyse beginnend mit Python (Datenvisualisierung 2) https://qiita.com/CEML/items/e932684502764be09157 Datenanalyse beginnend mit Python (Datenvisualisierung 3) https://qiita.com/CEML/items/71fbc7b8ab6a7576f514
Recommended Posts