Python-Datenanalysevorlage
Python-Datenanalysevorlage
Wenn Sie an kaggle arbeiten, müssen Sie die Daten analysieren und Ihre eigenen Funktionen erstellen. Zu diesem Zeitpunkt wird die Datenanalyse anhand des Diagramms durchgeführt. In diesem Artikel werde ich eine Vorlage veröffentlichen, um ein Diagramm zum Zweck der Datenanalyse zu erstellen.
Bibliothek verwendet
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
Beobachtung der Korrelation
Streudiagramm zwischen allen Variablen
Wenn Sie Pandas verwenden, können Sie ein Streudiagramm auf einmal erhalten. Zwischen denselben Variablen wird ein Histogramm gezeichnet. (Weil die gleichen Variablen nur gerade Linien sind)
from pandas.plotting import scatter_matrix
scatter_matrix(df)
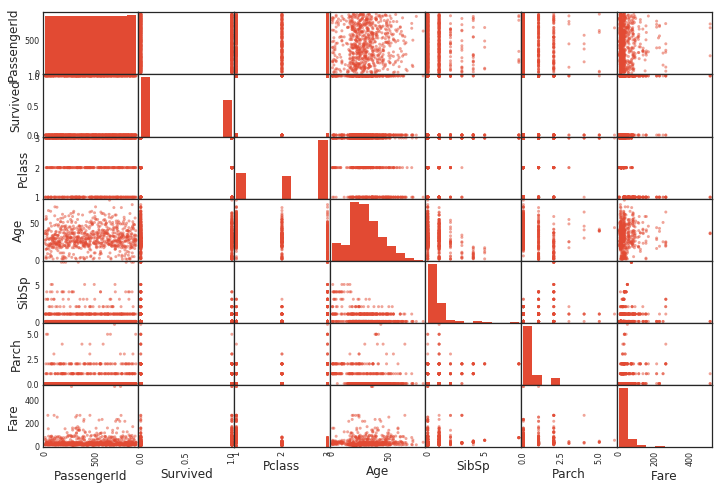
Streudiagramm
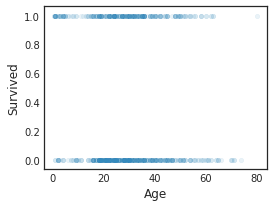
Darüber hinaus kann auf einfache Weise ein Streudiagramm bestimmter Variablen erstellt werden.
df.plot(kind='scatter',x='Age',y='Survived',alpha=0.1,figsize=(4,3))
Berechnung des Korrelationskoeffizienten
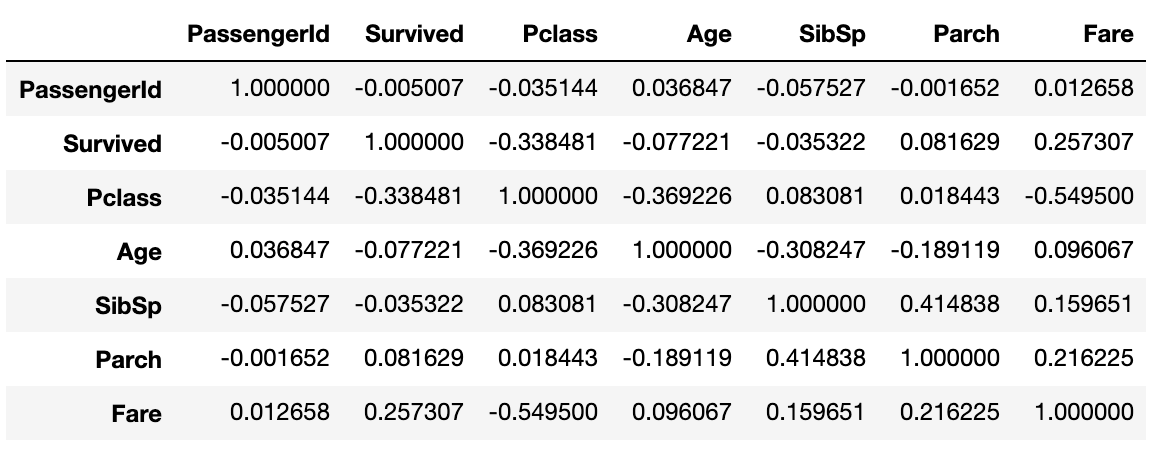
Korrelationskoeffizient
Der Pearson-Korrelationskoeffizient kann mit corr () auf einmal angezeigt werden. Sehr angenehm.
data1.corr()
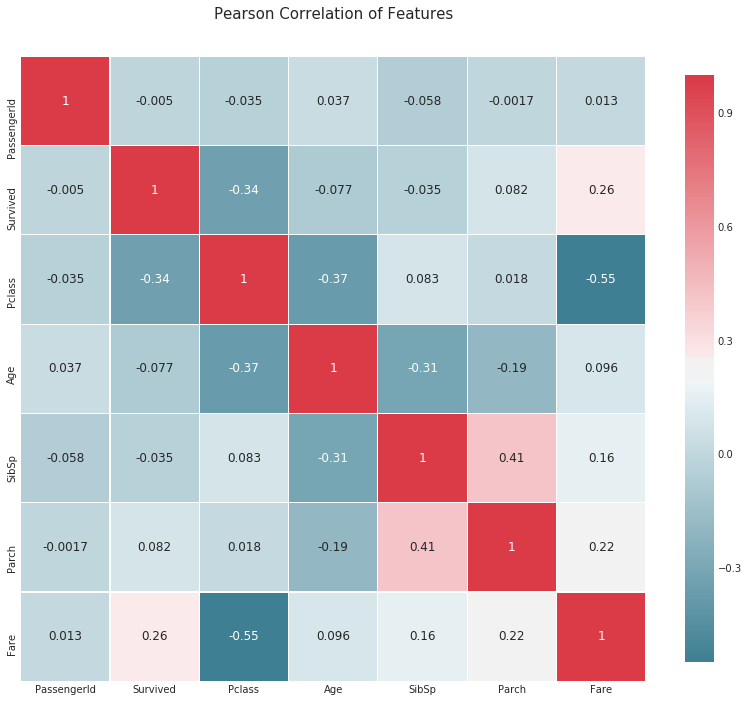
Wärmekarte des Korrelationskoeffizienten
def correlation_heatmap(df):
_ , ax = plt.subplots(figsize =(14, 12))
colormap = sns.diverging_palette(220, 10, as_cmap = True)
_ = sns.heatmap(
df.corr(),
cmap = colormap,
square=True,
cbar_kws={'shrink':.9 },
ax=ax,
annot=True,
linewidths=0.1,vmax=1.0, linecolor='white',
annot_kws={'fontsize':12 }
)
plt.title('Pearson Correlation of Features', y=1.05, size=15)
correlation_heatmap(data1)
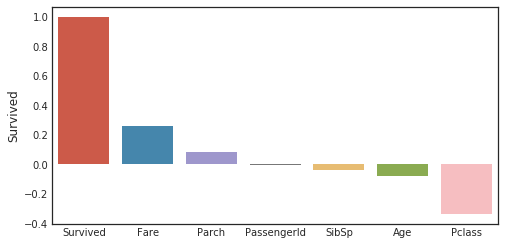
Korrelationskoeffizient für die Zielvariable
corr_matrix = data1.corr()
fig,ax=plt.subplots(figsize=(15,6))
y=pd.DataFrame(corr_matrix['Survived'].sort_values(ascending=False))
sns.barplot(x = y.index,y='Survived',data=y)
plt.tick_params(labelsize=10)
Histogramm
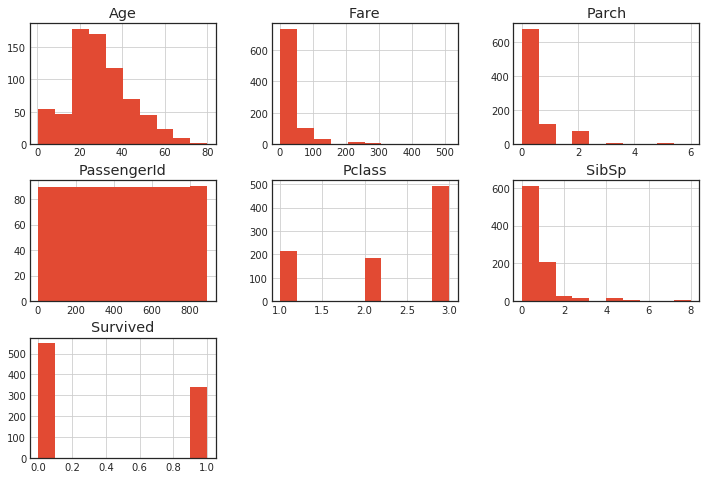
Variante aller Variablen
Sie können es auf einmal mit hist () erhalten.
df.hist()
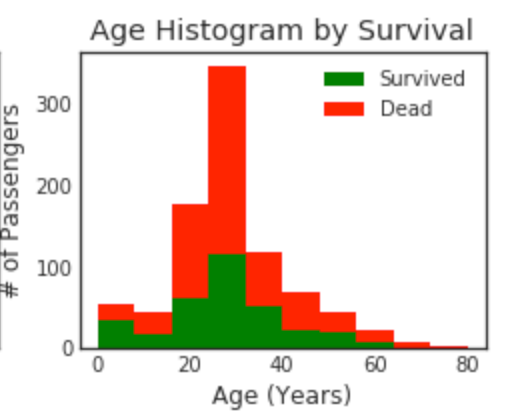
Überlagern Sie das Histogramm
plt.figure(figsize=[8,6])
plt.subplot(222)
plt.hist(x = [data1[data1['Survived']==1]['Age'], data1[data1['Survived']==0]['Age']], stacked=True, color = ['g','r'],label = ['Survived','Dead'])
plt.title('Age Histogram by Survival')
plt.xlabel('Age (Years)')
plt.ylabel('# of Passengers')
plt.legend()
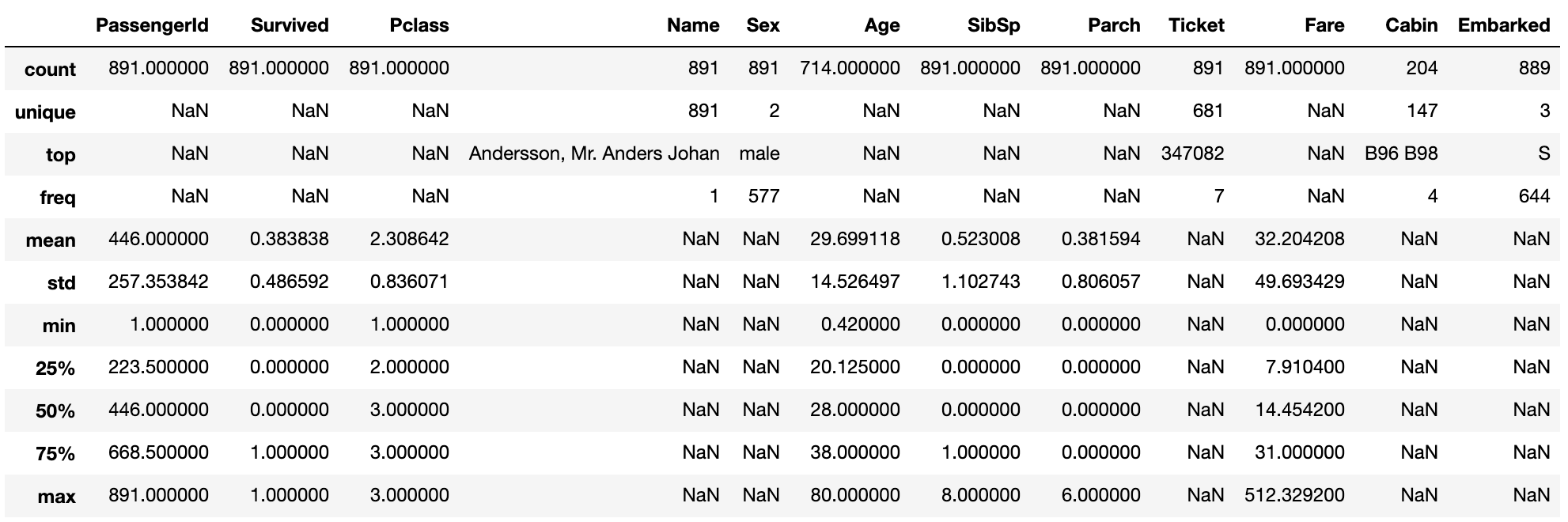
Beschreibung der Variablenverteilung
Wenn include = 'all' ist, werden auch Merkmalsgrößen angezeigt, die keine numerischen Werte sind.
data1.describe(include = 'all')
Quadrant
plt.figure(figsize=[8,6])
"""
o is treated as a Outlier.
minimun
Erster Quadrant des 25. Perzentils
50. Perzentil zweiter Quadrant (Median)
75. Perzentil dritter Quadrant
maximum
"""
plt.subplot(221)
plt.boxplot(data1['Age'], showmeans = True, meanline = True)
plt.title('Age Boxplot')
plt.ylabel('Age (Years)')
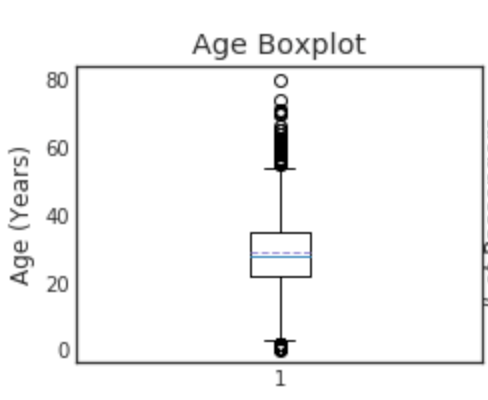
Sie können Boxplot überprüfen, um festzustellen, ob Ausreißer vorhanden sind. Dies kann auch verwendet werden, um fehlende Werte einzugeben. Wenn die Ausreißer übereinstimmen oder die Verteilung verzerrt ist, ist es besser, den Medianwert als den Mittelwert zu verwenden. Wenn andererseits die Verteilung links und rechts symmetrisch ist, ist es möglicherweise besser, den Durchschnittswert zu verwenden.
Recommended Posts