Die Python Engineer-Zertifizierungsdatenanalyseprüfung bestanden haben
Es ist nicht schwierig, aber es ist organisiertes Wissen
** [Achtung] Dieser Artikel beschreibt den Inhalt der Prüfung nicht direkt. ** ** ** Ich habe bestanden, wie der Titel sagt.
 |
 |
|---|---|
| Python CDA Pass Zertifikat | Testergebnisse |
Die Python-Ingenieur-Zertifizierungsprüfung umfasst eine Grundprüfung und eine Datenanalyseprüfung (Stand: 27. Oktober 2020). Zumindest ist der Datenanalysetest nicht so schwierig, aber Sie können ihn normalerweise debuggen und die Grammatik nachschlagen, um die Sie sich online Sorgen machen, aber Sie können im Test nichts sehen **. Es scheint, dass es viele Fehler gab, weil ich keine Maßnahmen ernst genommen habe. Im Folgenden finden Sie einige Dinge, die Sie bei dieser Prüfung überprüfen sollten.
Mathematik / Statistik
Erstens sind Funktionen wie Exponentiallogarithmus und Sinusakkorde, Vektoren / Matrizen und Differenzierung / Integration wesentliche Elemente. Ich bin ein Student der Naturwissenschaften, deshalb habe ich nicht für diese Prüfung studiert. Wahrscheinlichkeitsstatistiken sind auch für die Datenanalyse unverzichtbar. Beispielsweise kann die Häufigkeitsverteilungstabelle über den Rückgabewert von ax.hist ausgegeben werden, der von matplotlib verarbeitet wird.
Reichweite oder Anzahl
Können Sie die folgende Ausgabe definitiv beantworten? Es gibt Zeiten, in denen ich mich unwohl fühle. Question 1~4
import numpy as np
# Question 1
q1 = range(1, 10, 1)
print( q1 )
# Question 2
q2 = np.arange(1, 10, 1)
print( q2 )
# Question 3
q3 = np.arange(1.0, 10.0, 0.1)
print( q3 )
# Question 4
q4 = [ len( q1 ), len( q2 ), len( q3 ) ]
print( [ f'q{i+1} length = {a}' for i, a in enumerate(q4)] ) # print( q4 )
Antwort q1 ~ q4 (kann je nach Browser standardmäßig angezeigt werden)
# Answer for Question 1
range(1, 10)
# Answer for Question 2
9
# Answer for Question 3
[1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7
2.8 2.9 3. 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4. 4.1 4.2 4.3 4.4 4.5
4.6 4.7 4.8 4.9 5. 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.8 5.9 6. 6.1 6.2 6.3
6.4 6.5 6.6 6.7 6.8 6.9 7. 7.1 7.2 7.3 7.4 7.5 7.6 7.7 7.8 7.9 8. 8.1
8.2 8.3 8.4 8.5 8.6 8.7 8.8 8.9 9. 9.1 9.2 9.3 9.4 9.5 9.6 9.7 9.8 9.9]
# Answer for Question 4
90
# Answer for Question 1
range(1, 10)
# Answer for Question 2
9
# Answer for Question 3
[1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7
2.8 2.9 3. 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4. 4.1 4.2 4.3 4.4 4.5
4.6 4.7 4.8 4.9 5. 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.8 5.9 6. 6.1 6.2 6.3
6.4 6.5 6.6 6.7 6.8 6.9 7. 7.1 7.2 7.3 7.4 7.5 7.6 7.7 7.8 7.9 8. 8.1
8.2 8.3 8.4 8.5 8.6 8.7 8.8 8.9 9. 9.1 9.2 9.3 9.4 9.5 9.6 9.7 9.8 9.9]
# Answer for Question 4
90
Question 5~8
# Question 5
q5 = [ i for i in range(1, 10, 3) ]
print( q5 )
q6 = q5[-1]
print( q6 )
# Question 7, Which range is true?
# 1<=q7<=9 or 1<=q7<=10 or 2<=q7<=9 or 2<=q7<=10 ?
#q7 = [ random.randint(1, 10) for i in range(100) ]
q7 = random.randint(1, 10)
print( q7 )
# Question 8, Which range is true?
# 1<=q8<=9 or 1<=q8<=10 or 2<=q8<=9 or 2<=q8<=10 ?
#q8 = [ random.randrange(1, 10) for i in range(100)]
q8 = random.randrange(1, 10)
print(q8)
Antwort q5 ~ q8 (kann je nach Browser standardmäßig angezeigt werden)
# Answer for Question 5
[1, 4, 7]
# Answer for Question 6
7
# Answer for Question 7
#ex) 9
1<=q7<=10
# Answer for Question 8
#ex) 4
1<=q8<=9
# Answer for Question 5
[1, 4, 7]
# Answer for Question 6
7
# Answer for Question 7
#ex) 9
1<=q7<=10
# Answer for Question 8
#ex) 4
1<=q8<=9
Leicht der obige Kommentar (Bereich)
In Python führt die Verwendung von x = Bereich (a, b) normalerweise zu a <= x <b. Selbst im Fall von Numpy enthält es keine 10 wie q2 = np.arange (1, 10, 1). Gleiches gilt für Scheiben. Im Fall von q7 = random.randint (1, 10) ist dies jedoch kein Bereich, also 1 bis 10 (einschließlich 10). Wenn so etwas Schritte wie q5 = [i für i im Bereich (1, 10, 3)] enthält oder numpy oder ein Bruch wie q3 = np.arange (1.0, 10.0, 0.1) wird Diejenigen, die Python noch nicht kennen, sind möglicherweise verwirrt. Lassen Sie es uns gut verwenden, damit Sie das Ergebnis in Ihrem Kopf ausgeben können.
Reguläre Ausdrücke
Wenn Sie es nicht verwendet haben, verwenden Sie einfach "| (oder)" und "? (0 oder 1 Mal)".
import re
prog = re.compile('Mori(i|mori)t(a)?k(a)?y(o)?s(hi)?', re.IGNORECASE)
ret = prog.search('Moriitkys')
print(ret[0])
ret = prog.search('Moritkys')
print(ret[0])
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-48-3f281450d109> in <module>()
4 print(ret[0])
5 ret = prog.search('Moritkys')
----> 6 print(ret[0])
TypeError: 'NoneType' object is not subscriptable
Wie oben erwähnt, muss im Fall von (i | mori) einer von beiden enthalten sein. Andererseits ist im Fall von t (a) & agr; nur entweder "t" oder "ta" zulässig.
Pandas Ist es ein Merkmal des Datenanalysetests? Können Sie sich die Details von Pandas genau merken? Sehen Sie sich beispielsweise den Unterschied zwischen loc und iloc in einem Datenrahmen an.
import pandas as pd
df = pd.DataFrame([[101, "a", True],[102, "b", False],[103, "c", False]])
df.index = ["01", "02", "03"]
df.columns = ["A", "B", "C"]
a1 = df.loc["03", "A"]
a2 = df.iloc[2, 0]
print(a1, a2)
Antwort (kann je nach Browser standardmäßig angezeigt werden)
In beiden Fällen ist 103 die Ausgabe. Geben Sie für die Elementspezifikation den Index oder die Spalten für df.loc an und geben Sie den numerischen Wert von 0 für df.iloc an. Dies ist auch im Nachschlagewerk enthalten. Wenn Sie also die Prüfung ablegen möchten, müssen Sie sie auswendig lernen.
In beiden Fällen ist 103 die Ausgabe. Geben Sie für die Elementspezifikation den Index oder die Spalten für df.loc an und geben Sie den numerischen Wert von 0 für df.iloc an. Dies ist auch im Nachschlagewerk enthalten. Wenn Sie also die Prüfung ablegen möchten, müssen Sie sie auswendig lernen.
Darüber hinaus gibt es in df.head viele Dinge zu überprüfen, z. B. wie viele Datenzeilen von Anfang an zu nehmen sind und Details zur Verarbeitung fehlender Werte (dropna und fillna).
Matplotlib Wenn Sie Lust dazu haben, werde ich etwas zusammenfassen, aber zum Beispiel sind der Stil des Diagramms, die Einstellung des Titels usw. auch im Text geschrieben, sodass Sie es überprüfen müssen. Insbesondere die Diagrammtypen (ax.bar, ax.scatter, ax.hist, ax.boxplot, ax.pie usw.) sind als Testtitel für die Datenanalyse erforderlich.
Maschinelles Lernen
Es gibt verschiedene Methoden für maschinelles Lernen. Entscheidungsbaum, Hauptkomponentenanalyse, NN usw. Natürlich sollte ein Datenanalyst in der Lage sein, alles zu beherrschen. Ich denke jedoch, dass es notwendig ist, den Algorithmus, die Erklärung der Methode, das Scikit-Lernen usw. für die Methode zu überprüfen, die nicht oft verwendet wird. Im Nachschlagewerk hatte ich das Gefühl, dass das Lernen mit Lehrern und das Lernen ohne Lehrer verwirrt waren (Ist das nicht der Fall?). Vielleicht möchten Sie also mit oder ohne Lehrer zusammen lernen. Hmm.
Zusammenfassung des maschinellen Lernens
・ ** Datenvorverarbeitung (Verarbeitung fehlender Werte, Normalisierung von Merkmalen usw.) ** Für die Verarbeitung fehlender Werte wird die oben erwähnte Verarbeitung fehlender Werte durch Pandas eingeführt. Bitte überprüfen Sie das Nachschlagewerk für Details. Die Merkmalsnormalisierung erfordert Kenntnisse wie Wahrscheinlichkeitsstatistiken (verteilte Normalisierung, maximale Normalisierung usw.). Bei der Vorverarbeitung ist es außerdem wichtig, die Funktionsmenge der Daten auszuwählen und die Ausreißer auszuschließen (außerhalb des Testbereichs?). Sie sollten jedoch vorerst den Inhalt des Nachschlagewerks überprüfen.
・ ** Lernen mit dem Lehrer ** Das Nachschlagewerk erklärt die Support-Vektor-Maschine (SVC von sklearn.svm) und das lineare Regressionsmodell (LinearRegression von sklearn.linear_model). Weitere Informationen finden Sie dort.
・ ** Lernen ohne Lehrer ** Das Nachschlagewerk erläutert den Entscheidungsbaum (DecisionTreeClassifier von sklearn.tree), die zufällige Gesamtstruktur (RandomForestClassifier von sklearn.ensemble), die Dimensionsreduktion (PCA von sklearn.decomposition) und das Clustering (KMeans von sklearn.cluster, AgglomerativeClustering von sklearn.cluster). Bitte überprüfen Sie dort für Details.
・ ** Stärkung des Lernens ** Im Nachschlagewerk erscheint nur eine kurze Erklärung.
・ ** Variable Codierung ** ** [Kodierung der Kategorievariablen] ** Menschen geben Objekten Namen, damit sie die Welt, in der sie leben, leicht erkennen können. Beispielsweise werden die beiden an der Vorderseite des menschlichen Kopfes angebrachten Sinnesorgane, die Licht empfangen, als "Augen" bezeichnet, und die an der Vorderseite des menschlichen Kopfes angebrachten Riech- und Atmungsorgane werden als "Nase" bezeichnet. Auch wenn das Objekt auf diese Weise vom Zeichentyp interpretiert wird, müssen Eingabe und Ausgabe eine Folge sein (numerischer Wert), wenn Sie es durch Berechnung klassifizieren möchten. Die Zuordnung des numerischen Werts zum tatsächlichen Ziel erfolgt durch kategoriale Variablencodierung.
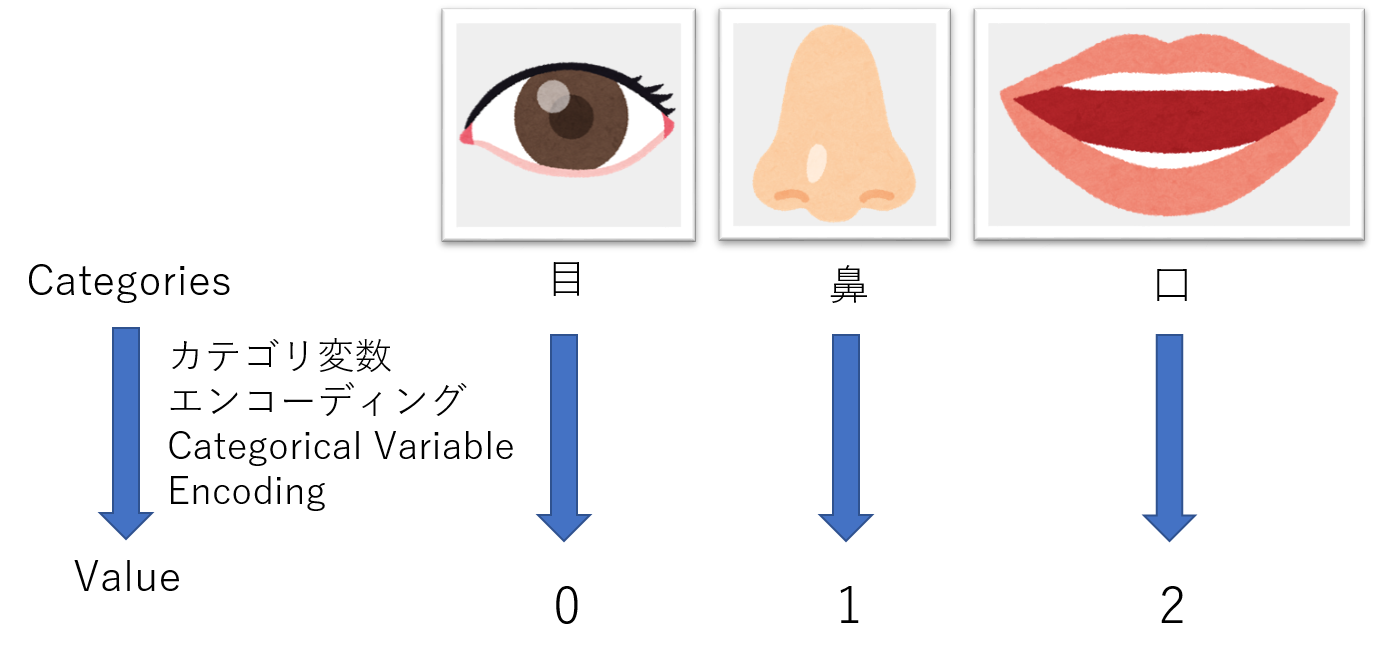 |
|---|
| Konzeptdiagramm der kategorialen Variablencodierung |
Insbesondere werde ich erklären, wo sich die Codierung der kategorialen Variablen in dem zuvor erstellten Programm befindet.
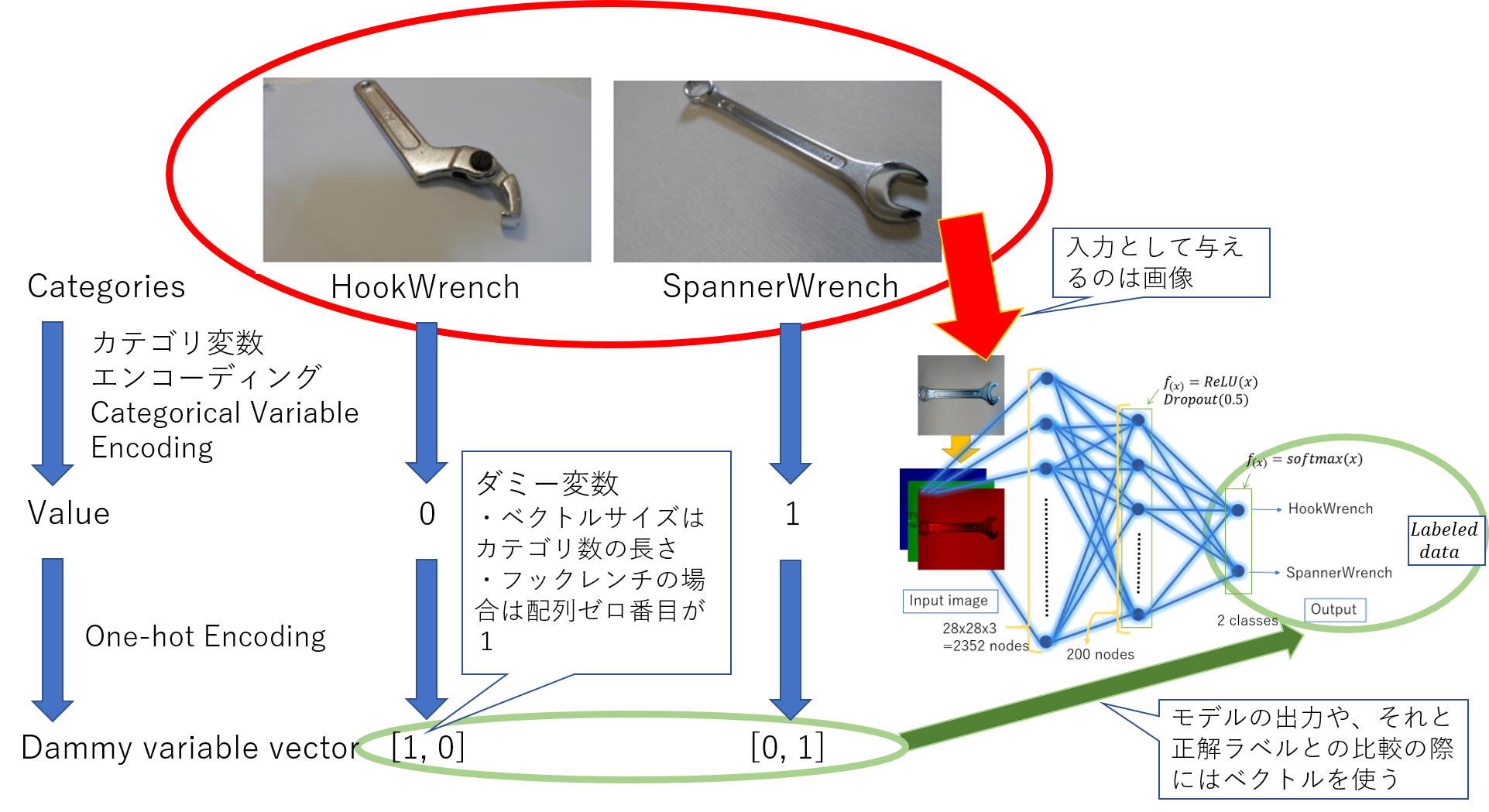 |
|---|
| Codierung von Kategorievariablen, Eins-Konzeptionelles Diagramm der Hot-Codierung |
Die folgende Seite ist ein Artikel zum Klassifizieren von Haken- und Schraubenschlüsseln mit PyTorch und Keras. https://qiita.com/moriitkys/items/316fcca8d83dfa706597 In diesem Fall ist die Codierung der kategorialen Variablen die Zuweisung des Wörterbuchs, das in Zelle 1, Zeile 56 des Programms MyOwnNN_pytorch.ipynb von GitHub (GitHub-moriitkys / MyOwnNN) ausgeführt wird.
#How many classes are in "dataset" folder
categories = [i for i in os.listdir(os.getcwd().replace("/mylib", "") + "/dataset")]
categories_idx = {}#ex) HookWrench:0, SpannerWrench:1
for i, name in enumerate(categories):
categories_idx[name] = i
nb_classes = len(categories)#ex) nb_classes=2
In diesem Fall wird der Hakenschlüssel auf 0 und der Schraubenschlüssel auf 1 umgewandelt. Für die Codierung kategorialer Variablen wird die Methode sklean.preprocessing im Nachschlagewerk vorgestellt.
** [One-Hot-Codierung] ** Dies ist auch die Arbeit, die erforderlich ist, um das gewünschte Ergebnis durch Berechnung zu erhalten. Da es beim maschinellen Lernen häufig bequemer ist, Ein- und Ausgaben als Arrays zu behandeln, ist es auch erforderlich, den Skalarwertdatensatz als Array zu konvertieren. Wenn beispielsweise zwei Kategorien vorhanden sind: Schraubenschlüssel: 0 und Hakenschlüssel: 1, konvertieren Sie den Schraubenschlüssel als [1, 0] und den Hakenschlüssel als [0, 1].
Insbesondere werde ich erklären, wo sich die Codierung der kategorialen Variablen in dem zuvor erstellten Programm befindet. Die One-Hot-Codierung erfolgt in der 13. bis 16. Zeile von Zelle 3.
y_train1=np_utils.to_categorical(y_train,nb_classes)
y_val1=np_utils.to_categorical(y_val,nb_classes)
Im Nachschlagewerk werden zwei Methoden der One-Hot-Codierung vorgestellt, sklean und pandas.
・ ** Modellbewertung ** ** [Kategoriebewertungsindex] ** Ich kann es verstehen, aber ich weiß nicht, ob ich es auswendig lerne, also habe ich es zusammengefasst. Diese Erklärung ist auch im Nachschlagewerk enthalten, daher ist es eine gute Idee, sie zu überprüfen.
| Positives Beispiel | Negatives Beispiel | |
|---|---|---|
| Positives Beispiel und Vorhersage | TP | FP |
| Negative Fälle und Vorhersagen | FN | TN |
TP (True Positive): Vorausgesagt als positives Beispiel und tatsächlich als positives Beispiel FP (False Positive): Vorausgesagt als positives Beispiel, aber tatsächlich als negatives Beispiel FN (False Negative): Wird als negatives Beispiel vorhergesagt, aber tatsächlich als positives Beispiel TN (True Negative): Wird als negativer Fall und tatsächlich als negativer Fall vorhergesagt
** Compliance-Rate **: Prozentsatz der tatsächlich positiven Fälle aus den vorhergesagten positiven Fällen. ・ Konformitätsratenformel P = TP / (TP + FP) ・ Die Genauigkeitsrate wird als Indikator dafür angesehen, wie klein die Fehler in der Vorhersageklasse sein können. ** Rückrufquote **: Prozentsatz der tatsächlich positiven Fälle, deren Richtigkeit vorhergesagt wird. ・ Rückrufratenformel R = TP / (TP + FN) ・ Es gibt einen Kompromiss zwischen Rückruf und Präzision ** F-Wert **: Harmonisierter Durchschnitt von Präzision und Rückruf. ・ F = 2PR / (P + R) ・ Anzeige, die das Gleichgewicht zwischen P und R verbessert ** Richtige Antwortrate **: Prozentsatz der Daten, deren Prognose und tatsächliche Ergebnisse übereinstimmen ・ Richtige Antwortratenformel A = (TP + TN) / (TP + FP)
** [Genauigkeit der Vorhersagewahrscheinlichkeit] ** Es ist nichts falsch daran, wenn Sie es wissen, aber das Nachschlagewerk erwähnt die ROC-Kurve (roc_curve in sklearn.metrics).
Zusammenfassung
Du solltest richtig lernen. Ich glaube nicht, dass es möglich ist, sich eine Scheinprüfung zu merken. Das Auswendiglernen von Nachschlagewerken mag nützlich sein, sollte aber verstanden werden.
Nachschlagewerk
Neues Lehrbuch zur Datenanalyse mit Python (Herr Terada, Shingo Tsuji, Takanori Suzuki, Shintaro Fukushima)
Autor dieses Artikels
moriitkys Takayoshi Morii Mach einen Roboter. Ich interessiere mich für KI / Robotik / 3D-Grafik. Vor kurzem habe ich darüber nachgedacht, wie ich Geld verdienen kann, und ich plane, mit diesem Geld Hardware zu verdienen. Qualifikation / Zertifizierung: G-Test, Python-Ingenieur-Zertifizierungsdatenanalyse-Test, AI-Implementierungstest A-Note, TOEIC: 810 (13.01.2019)
Recommended Posts