Vorverarbeitungsvorlage für die Datenanalyse (Python)
Vorverarbeitungsvorlage für die Datenanalyse (Python)
Die Datenvorverarbeitung, die ich häufig verwende, ist im folgenden Vorlagenformat zusammengefasst. Die Beschreibung ist eine Vorlage ohne viel Erklärung.
Datensatz laden
Lesen im CSV-Format
read_data.py
trainval_filename = './train.csv'
test_filename = './test.csv'
df_trainval = pd.read_csv(trainval_filename)
df_test = pd.read_csv(test_filename)
Kombinieren Sie Datenrahmen mit concat
Dies ist praktisch, wenn Sie die Trainingsdaten und die Testdaten gleichzeitig vorverarbeiten möchten. Verwenden Sie es danach, wenn Sie Daten normal kombinieren möchten.
df_all = pd.concat([df_trainval,df_test],axis=0)
#axis=0 :Nach unten verbinden
#axis=1 :Verbinden Sie sich nach rechts
Einfache Variablenkonvertierung
Verarbeitung von Datums- und Uhrzeitinformationen durch to_datatime
Konvertieren Sie Datums- und Uhrzeitinformationen in den Zeitstempeltyp und konvertieren Sie sie in Jahr / Monat / Datum / Tag
'''
#Vor der Konvertierung
Date
0 1999-07-17
1 2008-02-14
2 2013-03-09
3 2012-02-02
4 2009-05-09
'''
df_all['Date'] = pd.to_datetime(df_all["Date"])
'''
#Nach der Behandlung
0 1999-07-17
1 2008-02-14
2 2013-03-09
3 2012-02-02
4 2009-05-09
'''
Informationskonvertierung auf Datum und Tag durch zutreffen
Das gleiche kann mit der Karte gemacht werden.
df_all['Year'] = df_all['Date'].apply(lambda x:x.year)
df_all['Month'] = df_all['Date'].apply(lambda x:x.month)
df_all['Day'] = df_all['Date'].apply(lambda x:x.day)
df_all['Weekday_name'] = df_all['Date'].apply(lambda x:x.weekday_name)
'''
#Nach der Konvertierung
Year Month Day Weekday_name
0 1999 7 17 Saturday
1 2008 2 14 Thursday
2 2013 3 9 Saturday
3 2012 2 2 Thursday
4 2009 5 9 Saturday
'''
Numerische Konvertierung von Etiketten mit LabelEncoder
Konvertieren Sie Beschriftungen in numerische Informationen. Unten werden die Stadtinformationen in numerische Informationen umgewandelt.
laberlencoder.py
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df_all['City'] = le.fit_transform(df_all['City'])
Elementersatz durch Karte
Verwenden Sie die Kartenfunktion, um Beschriftungen in diskrete Werte umzuwandeln.
map.py
'''
City Group Type
0 Big Cities IL
1 Big Cities FC
2 Other IL
3 Other IL
4 Other IL #Vor der Konvertierung
'''
df_all['City Group'] = df_all['City Group'].map({'Other':0,'Big Cities':1}) #There are only 'Other' or 'Big city'
df_all["Type"] = df_all["Type"].map({"FC":0, "IL":1, "DT":2, "MB":3}) #There are only 'FC' or 'IL' or 'DT' or 'MB'
'''
City Group Type
0 1 1
1 1 0
2 0 1
3 0 1
4 0 1 Nach der Konvertierung
'''
Erfassung von Dateninformationen mit der Funktion von Pandas
Spalteninformationen mit info () abrufen
Sie können die Anzahl der Spalten, die Spaltenlänge, den Datentyp usw. abrufen. Sehr angenehm
df.info()
'''<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
None
'''
describe() Verschiedene Informationen wie die Anzahl der Daten in jeder Spalte, der Durchschnitt, die Varianz und der Quadrant können erhalten werden.
df.describe()
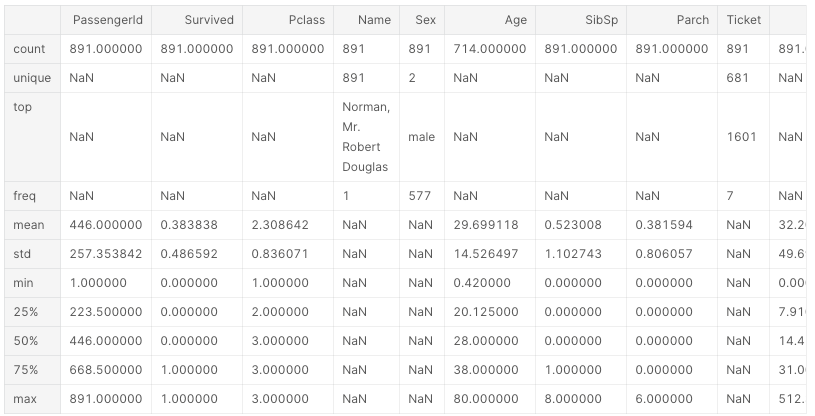
NaN-Aggregation
df.isnull().sum()
'''
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
Family_size 0
'''
Füllen Sie NaN
Es gibt verschiedene Möglichkeiten, es zu füllen. Persönlich verwende ich es nur um die Durchschnitts- und Medianwerte. Wenn es einen anderen guten Weg gibt, lassen Sie es mich bitte wissen.
df['Age'].fillna(dataset['Age'].median()) #Medianversion
df['Age'].fillna(dataset['Age'].median()) #Durchschnittliche Version
df = df.dropna(how='all',axis=0) #Spalten, in denen alle Werte fehlen, werden gelöscht,axis=Für Linien auf 1 setzen.
df = df2.dropna(how='any',axis=0) #'any'Wenn diese Option aktiviert ist, werden Zeilen mit nur einem NaN gelöscht. (Standard)
Korrelationskoeffizient durch corr ()
Der Korrelationskoeffizient zwischen allen Variablen kann einfach mit corr () berechnet werden. Sehr angenehm.
print(df.corr())
'''
PassengerId Pclass Age SibSp Parch Fare
PassengerId 1.000000 -0.026751 -0.034102 0.003818 0.043080 0.008211
Pclass -0.026751 1.000000 -0.492143 0.001087 0.018721 -0.577147
Age -0.034102 -0.492143 1.000000 -0.091587 -0.061249 0.337932
SibSp 0.003818 0.001087 -0.091587 1.000000 0.306895 0.171539
Parch 0.043080 0.018721 -0.061249 0.306895 1.000000 0.230046
Fare 0.008211 -0.577147 0.337932 0.171539 0.230046 1.000000
Erstellen eines Histogramms mit hist ()
Verwenden Sie einfach hist () und es wird ein Histogramm gezeichnet. Dies ist auch sehr praktisch.
df.hist()
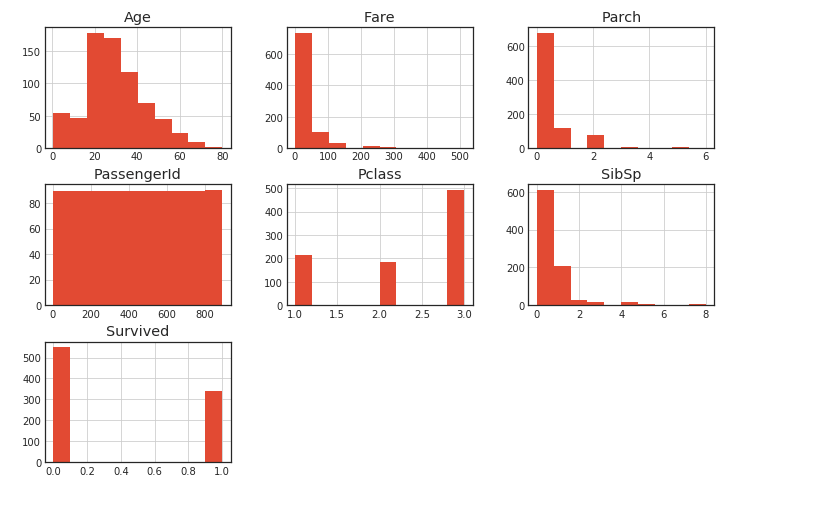
Scatter_matrix () Streudiagrammerstellung
Scatter_matrix () zeichnet ein Streudiagramm. Es wird ein Streudiagramm zwischen allen Variablen erstellt. Das Diagonaldiagramm zeigt ein Histogramm dieser Variablen.
pd.plotting.scatter_matrix(df)
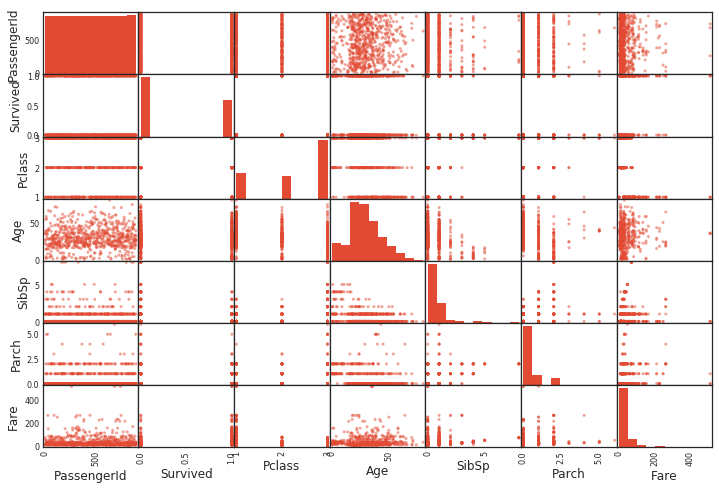
Gruppierung nach Gruppe nach
Die groupby-Funktion kann auf Beschriftungsvariablen angewendet werden. 'Sex' hat nur Frauen und Männer, daher kann es in diese beiden unterteilt werden Wenn Sie danach mean () hinzufügen, wird der Durchschnitt für jede Gruppe berechnet.
print(df[['Sex', 'Survival']].groupby('Sex', as_index=False).mean())
'''
Sex Survived
0 female 0.742038
1 male 0.188908
'''
Ich bearbeite jetzt.
Recommended Posts