[PYTHON] Tipps und Vorsichtsmaßnahmen bei der Datenanalyse
Einführung
Zum Aufschreiben von Punkten, die Sie beachten müssen, wenn Sie die Datenanalyse selbst durchführen
- ** Tipps zur Analyse **
- ** Hinweise zur Analyse **
Vorherige Informationen
Dieses Mal werde ich die Verwendung der im Kaggle-Wettbewerb verwendeten Daten erläutern.
Kaggle House Prices DataSet
Kaggle House Prices Kernel
Machen Sie sich eine Notiz mit.
Bitte beachten Sie, dass wir uns nicht um die Modellgenauigkeit usw. kümmern, da wir diese für Memo aufbewahren
Inhalt der Daten
Insgesamt gibt es 81 Funktionen, von denen SalePrices als Zielvariable (Ziel) für die Analyse verwendet wird.
Die erklärenden Variablen sind andere als SalePrices.
Tips Zunächst ist es besser, dies für die Daten zu tun
Vorverarbeitung
Lesen Sie zunächst die Daten (DataFrame-> df) und führen Sie "EDA (Exploratory Data Analysis)" durch.
-. head (): Am Anfang der Daten anzeigen, 5 Zeilen extrahieren, wenn (5), der Defalt-Wert 5 ist --.info (): Datenübersicht (Anzahl der Zeilen, Anzahl der Spalten, Spaltenname jeder Spalte, Art der in jeder Spalte gespeicherten Daten usw.) -. beschreiben (): Grundlegende Datenstatistik (min, max, 25% usw. .....) -. shape [0], .shape [1]: Überprüfen Sie die Anzahl der Zeilen und Spalten der Daten -. Spalten: Abrufen der Spaltennamen von Daten -. isnull (). Sum (): Überprüfen Sie die Anzahl der fehlenden Bereiche in jeder Spalte
- .dtypes: Überprüfen Sie den Typtyp jeder Spalte
# import
import pandas as pd
import matplotlib.pyplot as plt ## for drawing graph
## load Data
df = pd.read~~~~(csv , json etc...)
#Top Anzeige der Daten
df.head()
#Zusammenfassende Anzeige von Daten
df.info()
#Anzahl der Dimensionen von Daten (wie viele Zeilen und Spalten)
print('There are {} rows and {} columns in df'.format(df.shape[0], df.shape[1]))
#Datenspalte abrufen
df.columns
#Zählen Sie die Anzahl der fehlenden Werte in den einzelnen Spaltendaten
df.isnull().sum()
#Typtypbestätigung für jede Spaltendaten
df.dtypes
Sie können die Spaltennamen mit df.columns abrufen. Wenn Sie jedoch eine Liste mit Spaltennamen nach Typtyp führen, können Sie diese möglicherweise verwenden, wenn Sie später darüber nachdenken. Beschreiben Sie den Code. Es ist auch möglich, "include" in "type type (float64 etc ...)" zu ändern.
obj_columns = df.select_dtypes(include=['object']).columns
numb_columns = df.select_dtypes(include=['number']).columns
Handlungsbeispiel
Histogramm jeder Spalte (Merkmalsmenge)
Die Merkmalsmenge jeder Spalte wird in ein Histogramm umgewandelt. Dies kann jedoch nur "numerische Daten" verarbeiten. Da es nicht auf "Zeichenkettendaten" angewendet werden kann, wird es später beschrieben.
- .hist(bins=**, figsize=(,))
Bins ist die Einstellung der Feinheit des Klassenwerts für die Analyse der Frequenz, und figsize ist die Einstellung der Größe der Figur. Sie können viele andere Argumente vorbringen. Bitte beziehen Sie sich auf Folgendes. official pyplot.hist document
df.hist(bins=50, figsize=(20,15))
plt.show()
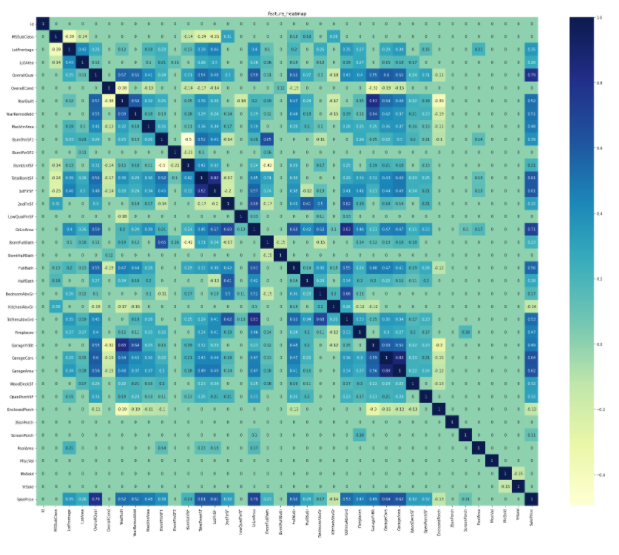
Korrelationsmatrix-Wärmekarte
Beim maschinellen Lernen ist es wichtig, die Korrelationsmatrix für jede Merkmalsgröße zu finden. Visualisieren Sie es mit einer Heatmap, um die Korrelationsmatrix zu visualisieren.
- .heatmap(corr, annot=bool(True or False), cmap='***')
corr ist die Korrelationsmatrix, annot legt den Wert in der Zelle fest, cmap gibt die Farbe der Figur an Sie können viele andere Argumente vorbringen. Bitte beziehen Sie sich auf Folgendes. official seaborn.heatmap document
import seaborn as sns ## for drawing graph
corr = train_df.corr()
corr[np.abs(corr) < 0.1] = 0 ## corr<0.1 => corr=0
sns.heatmap(corr, annot=True, cmap='YlGnBu')
plt.show()
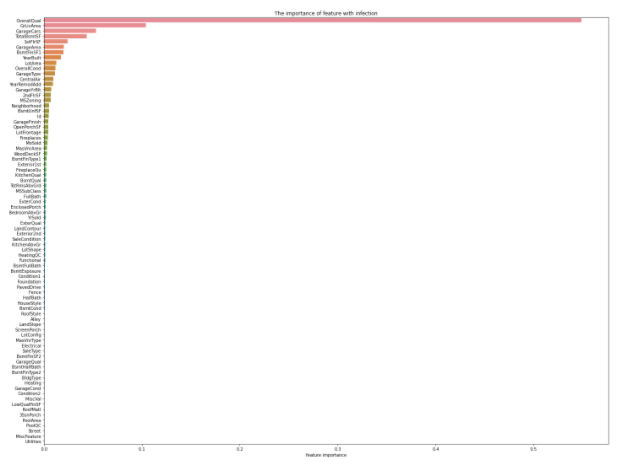
Einschätzung der Wichtigkeit von Merkmalen
Random Forest wird verwendet, um zu berechnen, welche Funktionen für die Zielverkaufspreise wichtig sind. Um RandomForest ausführen zu können, muss es zunächst in "erklärende Variable und objektive Variable" unterteilt werden. ** Dieses Mal werden alle Variablen außer target (SalePsices) als erklärende Variablen verwendet. ** ** **
-. drop ("***", Achse = (0 oder 1)): Geben Sie eine Spalte an, die nicht für *** verwendet wird, Zeile, wenn Achse = 0, Spalte, wenn 1. --RandomForestRegressor (n_estimators = **): n_estimators ist die Anzahl der Lernvorgänge
from sklearn.ensemble import RandomForestRegressor
X_train = df.drop("SalePrices", axis=1)
y_train = df[["SalePrices"]]
rf = RandomForestRegressor(n_estimators=80, max_features='auto')
rf.fit(X_train, y_train)
ranking = np.argsort(-rf.feature_importances_) ##In absteigender Reihenfolge der Wichtigkeit zeichnen
sns.barplot(x=rf.feature_importances_[ranking], y=X_train.columns.values[ranking], orient='h')
plt.show()
Verteilung der einzelnen Funktionen (zur Überprüfung von Ausreißern usw.)
Es wird gesagt, dass wenn Merkmalsgrößen bei der Durchführung einer Regressionsanalyse Ausreißer enthalten, dies wahrscheinlich die Genauigkeit des Modells beeinflusst. Daher wird davon ausgegangen, dass die Verarbeitung von Ausreißern für die Verbesserung der Genauigkeit des Modells unverzichtbar ist. Daher ist es einfach zu visualisieren und zu bestätigen, wie viele Abweichungswerte in jeder Merkmalsmenge enthalten sind.
Hier werden Diagramme der 30 wichtigsten Merkmale ausgeführt.
-. iloc [:,:]: Extrahieren Sie den Wert durch Angabe einer Zeile oder Spalte --sns.regplot: Zeichnen durch Überlagern von 2D-Daten und Ergebnissen des linearen Regressionsmodells
X_train = X_train.iloc[:,ranking[:30]]
fig = plt.figure(figsize=(12,7))
for i in np.arange(30):
ax = fig.add_subplot(5,6,i+1)
sns.regplot(x=X_train.iloc[:,i], y=y_train)
plt.tight_layout()
plt.show()
wichtiger Punkt
Überprüfen Sie, ob das Ziel (Zielvariable) einer Normalverteilung folgt
In diesen Daten ist das Ziel SalePrices. Beim maschinellen Lernen ist es wichtig, ob die Zielvariable einer Normalverteilung folgt, da dies das Modell beeinflusst. Schauen wir uns also die Verteilung der SalePrices an. In dieser Abbildung zeigt die vertikale Achse das Verhältnis und die horizontale Achse die SalePrices.
sns.distplot(y_train, color="red", label="real_value")
plt.legend()
plt.show()
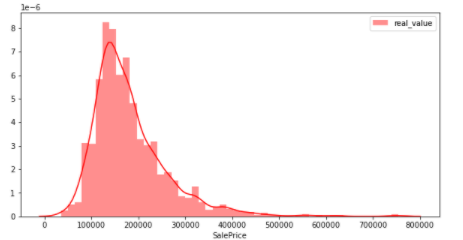
Aus der obigen Abbildung ist ersichtlich, dass die Verteilung leicht nach links vorgespannt ist. Es handelt sich nicht um eine Normalverteilung (Daten, bei denen die meisten numerischen Werte in der Mitte konzentriert sind, wenn sie grafisch dargestellt und in einer symmetrischen Glockenform "verteilt" werden). Daher sind die üblicherweise verwendeten ** logarithmischen und differentiellen Transformationen ** unten gezeigt, so dass die Zielvariable einer Normalverteilung folgt.
y_train2 = np.log(y_train)
y_train2 = y_train2.replace([np.inf, -np.inf], np.nan)
y_train2 = y_train2.fillna(0)
sns.distplot(y_train2, color="blue", label="log_value")
plt.legend()
plt.show()
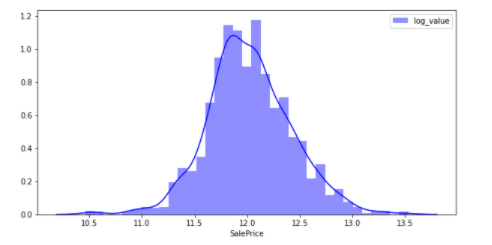
Durch die logarithmische Umwandlung kommt die Zahl einer Normalverteilung nahe.
y_train3 = y_train.diff(periods = 1)
y_train3 = y_train3.fillna(0)
sns.distplot(y_train3, color="green", label="diff_value")
plt.legend()
plt.show()
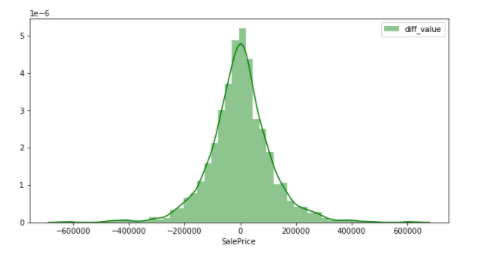
Es ist eine Zahl, die durch Ausführen einer Differenzumwandlung als Normalverteilung bezeichnet werden kann. Mit anderen Worten, es kann gefolgert werden, dass die Zielvariable, die die Genauigkeit des Modells nicht leicht beeinflusst, SalePrices ist, die einer differenziellen Konvertierung unterzogen wurden. Auf diese Weise ** ist es beim Umgang mit Daten besser zu prüfen, ob die Werte verzerrt sind. ** ** ** Ich möchte einen zukünftigen Artikel schreiben, in dem die Genauigkeit des Modells verglichen wird, wenn es tatsächlich der Normalverteilung folgt und wenn dies nicht der Fall ist.
Zusammenfassung
Das Obige ist eine Zusammenfassung dessen, was bei der Datenanalyse zuerst zu tun ist. In Zukunft möchte ich Artikel über den Umgang mit Zeichenkettendaten und den Umgang mit Zeitreihendaten schreiben, die ich bereits bei der Datenanalyse erwähnt habe.
Recommended Posts