[PYTHON] Datenanalyse zur Verbesserung von POG 3 ~ Regressionsanalyse ~
Rückblick bis zum letzten Mal
Datenanalyse zur Verbesserung des POG 2 ~ Analyse mit Jupiter-Notizbuch ~ zeigt den kausalen Zusammenhang zwischen dem Pferdeprofil und den während des POG-Zeitraums gewonnenen Preisen. Durch die Analyse konnten wir allgemeine Trends wie "weibliche Pferde sind nachteilig" und "frühere Geburt ist vorteilhafter" erfassen.
Zweck dieser Zeit
Bestimmen Sie die Möglichkeit einer Preisvorhersage für den POG-Zeitraum basierend auf dem Profil des Pferdes durch Regressionsanalyse.
Datenanalyse
Umgang mit qualitativen Daten
Werfen wir einen Blick auf den Inhalt der zu analysierenden Daten.

Da wir den Preisbetrag basierend auf dem Profil jedes Pferdes vorhersagen möchten, lautet die Zielvariable "POG-Zeitraum Prize_Jahr-Runde" und die erklärenden Variablen sind "Geschlecht", "Geburtsmonat", "Trainer", "Pferdebesitzer", "Produzent". , "Origin", "Seri Transaktionspreis", "Vater", "Mutter und Vater" wären angemessen. Da jedoch in der vorherigen Analyse keine signifikante Beziehung gefunden wurde, wird diesmal der "Seri-Transaktionspreis" von der Analyse ausgeschlossen.
Unter den erklärenden Variablen sind übrigens andere Daten als der "Seri-Transaktionspreis" sogenannte qualitative Daten. Daher kann die Regressionsanalyse nicht so durchgeführt werden, wie sie ist.
In einem solchen Fall scheint es eine allgemeine Methode * zu sein, eine Regressionsanalyse durchzuführen, nachdem qualitative Daten in Dummy-Variablen konvertiert wurden, damit sie als quantitative Daten behandelt werden können.
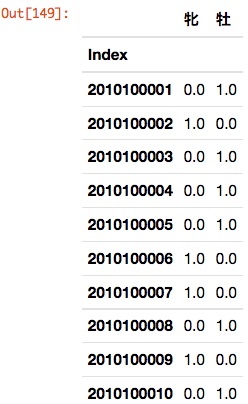
pandas hat die Funktion, qualitative Daten in Dummy-Variablen umzuwandeln. Ein Beispiel ist unten gezeigt.
python
horse_df = pd.read_csv('./horse_db/horse_prof_2010_2014_mod.csv', encoding='utf-8', header=0, index_col=0)
pd.get_dummies(horse_df[u'Sex'])[:3]
Einfache Regressionsanalyse
In dieser Analyse wird die OLS (Minimum Square Method) des Statistikmoduls verwendet. Der für die Analyse verwendete Code ist unten dargestellt.
python
#Modulimport
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font='Osaka')
import statsmodels.api as sm
import IPython.display as display
%matplotlib inline
#Lesen Sie die Daten der Analysequelle
horse_df = pd.read_csv('./horse_db/horse_prof_2010_2014_mod.csv', encoding='utf-8', header=0, index_col=0)
#horse_df = horse_df[:50]
#Konvertieren Sie qualitative Daten in Dummy-Variablen
use_col = [
u'Sex',
#u'Geburtsmonat',
#u'Trainer',
#u'Pferdebesitzer',
#u'Produzent',
#u'Ursprung',
#u'Vater',
#u'Mutter Vater',
]
if len(use_col) == 1:
dum = pd.get_dummies(horse_df[use_col[0]])
else:
dum = pd.get_dummies(horse_df[use_col])
# X,Definition von y
X_col = dum.columns
y_col = u'POG-Preis_Das ganze Jahr'
tmp_df = pd.concat([dum, horse_df[y_col]], axis=1)
tmp_df = tmp_df.dropna()
tmp_df = tmp_df.applymap(np.int)
X = tmp_df[X_col].ix[:,:]
X = sm.add_constant(X)
y = tmp_df[y_col]
#Modellgenerierung
model = sm.OLS(y,X)
#Ergebnis
results = model.fit()
y_predict = results.predict()
plt.plot(y_predict, y, marker='o', ls='None', label='_'.join(use_col))
plt.xlabel(u'Prognose')
plt.ylabel(u'Tatsächliche Messung')
plt.legend(loc=0)
plt.title('R^2: %.3f, F: %.3f' % (results.rsquared, results.fvalue))
plt.savefig('./figure/fig_'+'_'.join(use_col)+'.png')
#display.display(results.summary())
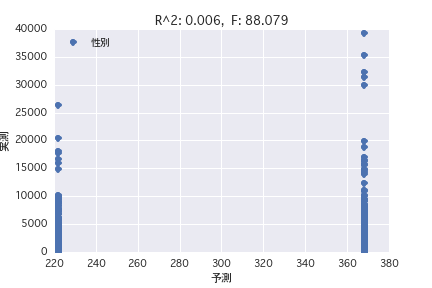
Sex
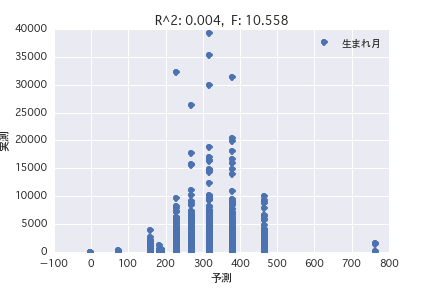
Geburtsmonat
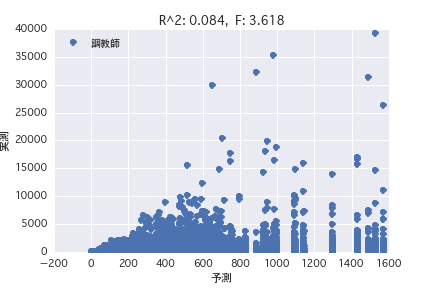
Trainer
Pferdebesitzer
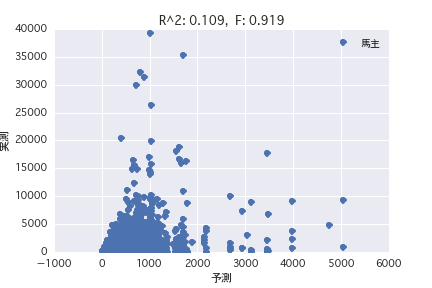
Produzent
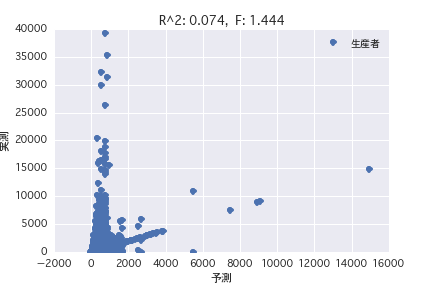
Ursprung
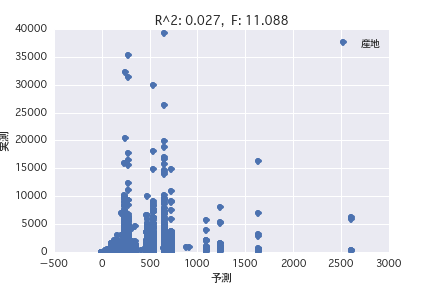
Vater
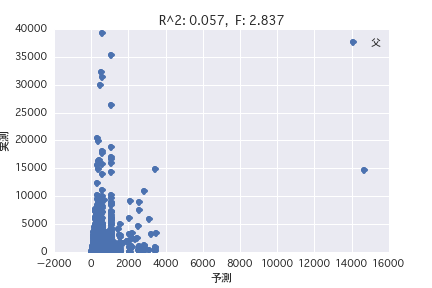
Mutter Vater
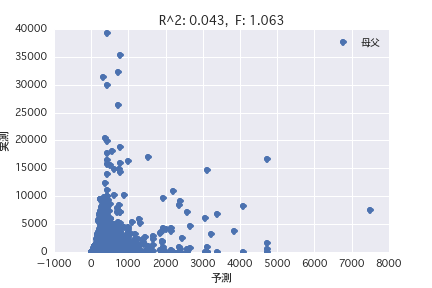
Multiple Regressionsanalyse
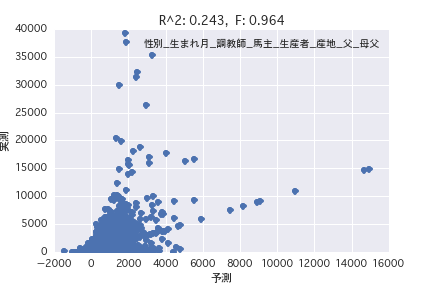
Diese Zusammenfassung
Eine Regressionsanalyse wurde mit der Zielvariablen als "POG-Zeitraum Preisjahr" und der erklärenden Variablen als verschiedene Pferdeprofile ("Geschlecht", "Vater" usw.) durchgeführt. Es wurde festgestellt, dass es schwierig ist, den Preisbetrag aus dem Pferdeprofil vorherzusagen, da R ^ 2 sowohl in der einfachen Regressionsanalyse als auch in der multiplen Regressionsanalyse klein ist.
von jetzt an
Diskriminierungsanalyse (Identifizierung von nicht gewonnenen, durchschnittlich offenen Pferden, erstklassigen Pferden) Analyse mit Schwerpunkt auf Stammbaum
Recommended Posts