[PYTHON] Eine Einführung in die statistische Modellierung für die Datenanalyse
Für mein eigenes Studium. Das Innere ist in R geschrieben, also werde ich es in Python umschreiben und mein Bestes geben. Kommentar im Code ist R-Sprache.
2.1 Beispiel: Statistische Modellierung von Startnummern
Es scheint, dass R Zähldaten für die Anzahl der Samen hat. Ich denke, es ist besser, Numpy und Pandas für die Verarbeitung zu verwenden. Daten werden auch für jede der Nummern "numpy.array" und "pandas.Series" vorbereitet. Auch "Pyplot" für Grafiken.
>>> data = [2, 2, 4, 6, 4, 5, 2, 3, 1, 2, 0, 4, 3, 3, 3, 3, 4, 2, 7, 2, 4, 3, 3, 3, 4, 3, 7, 5, 3, 1, 7, 6, 4, 6, 5, 2, 4, 7, 2, 2, 6, 2, 4, 5, 4, 5, 1, 3, 2, 3]
>>> import numpy
>>> import pandas
>>> matplotlib.pyplot as plt
>>> ndata = numpy.asarray(data)
>>> pdata = pandas.Series(data)
Die Anzahl der Samen beträgt 50.
# length(data)
>>> len(data)
50
>>> len(ndata)
50
>>> len(pdata)
50
Anzeigen des Stichprobenmittelwerts, des Minimalwerts, des Maximalwerts, der Quadrantenzahl usw. von Daten
# summary(data)
>>> pdata.describe()
count 50.00000
mean 3.56000
std 1.72804
min 0.00000
25% 2.00000
50% 3.00000
75% 4.75000
max 7.00000
dtype: float64
Häufigkeitsverteilung abrufen
# table(data)
>>> pdata.value_counts()
3 12
2 11
4 10
5 5
7 4
6 4
1 3
0 1
dtype: int64
Es kann bestätigt werden, dass die Anzahl der Samen 5 und die Anzahl der Samen 6 beträgt.
Zeigen Sie dies als Histogramm an
# hist(data, breaks = seq(-0.5, 9.5, 1))
>>> pdata.hist(bins=[i - 0.5 for i in xrange(11)])
<matplotlib.axes._subplots.AxesSubplot object at 0x10f1a9a10>
>>> plt.show()
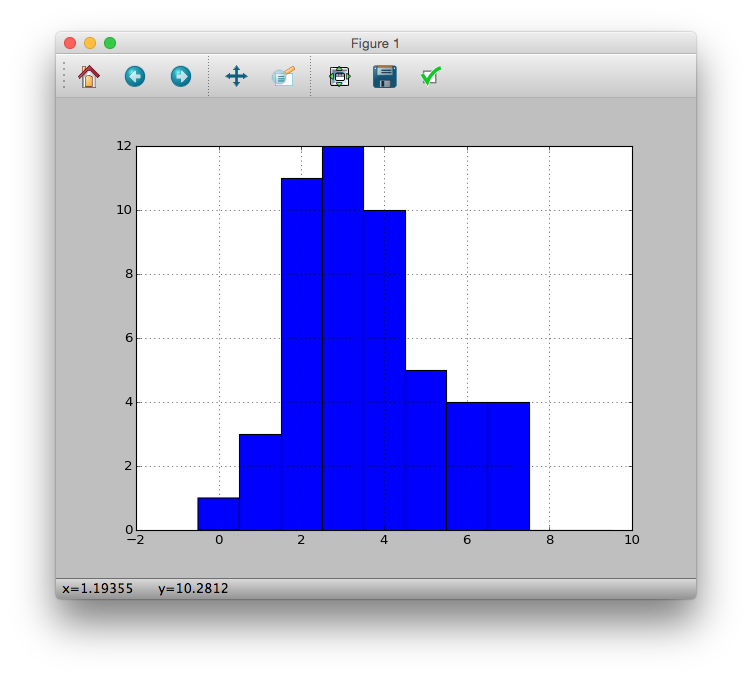
Berechnung der statistischen "Stichprobenvarianz", die die Variation der Daten darstellt. Es scheint, dass die Standardmethode zur Berechnung der Verteilung zwischen Numpy und Pandas unterschiedlich ist. (Referenz) Übrigens scheint es im Fall von R eine unvoreingenommene Schätzung zu sein.
# var(data)
>>> numpy.var(ndata) #Beispielstatistik
2.9264000000000006
>>> numpy.var(ndata, ddof=True) #Unvoreingenommene Schätzung
2.9861224489795921
>>> pdata.var() #Unvoreingenommene Schätzung
2.986122448979593
>>> pdata.var(ddof=False) #Beispielstatistik
2.926400000000001
Die Standardabweichung scheint sich genauso zu verhalten wie die Dispersion. Diesmal nur das Beispiel der Pandas.
# sd(data)
>>> pdata.std()
1.7280400600042793
# sqrt(var(data))
2.2 Betrachtung der Entsprechung zwischen Daten und Wahrscheinlichkeitsverteilung
Es ist ersichtlich, dass die Samenzahldaten die folgenden Eigenschaften aufweisen.
--Zählen Sie Daten, die als eins, zwei, ... gezählt werden können.
- Die durchschnittliche Anzahl der Samen pro Person beträgt 3,56 USD ――Es gibt Unterschiede im Zweck jedes Einzelnen, und wenn Sie ein Histogramm zeichnen, handelt es sich um eine Bergverteilung.
Die ** Wahrscheinlichkeitsverteilung ** wird verwendet, um die Variation darzustellen. Darstellung der Seed-Number-Daten als statistisches Modell Dieses Mal scheint es, dass ** Poisson-Verteilung ** verwendet wird.
Die Anzahl der Samen $ y_i $ eines Pflanzenindividuums $ i $ wird als ** Wahrscheinlichkeitsvariable ** bezeichnet.
Wie groß ist die Wahrscheinlichkeit, dass die Anzahl der Samen in Individuum 1 $ y_1 = 2 $ sein kann?
Die Wahrscheinlichkeitsverteilung, die ausgedrückt wird, wird durch eine relativ einfache mathematische Formel definiert, und ihre Form wird durch die Parameter bestimmt.
Im Fall der Poisson-Verteilung ist der einzige Parameter ** Durchschnitt der Verteilung **.
In diesem Beispiel hat die Poisson-Verteilung einen Durchschnitt von 3,56 USD. Was die Verteilungsbeziehung betrifft, scheint "scipy" gut zu sein.
# y <- 0:9
# prob <- dpois(y, lambda = 3.56)
# plot(y, prob, type="b", lyt=2)
>>> import scipy.stats as sct
>>> y = range(10)
>>> prob = sct.poisson.pmf(y, mu=3.56)
>>> plt.plot(y, prob, 'bo-')
>>> plt.show()
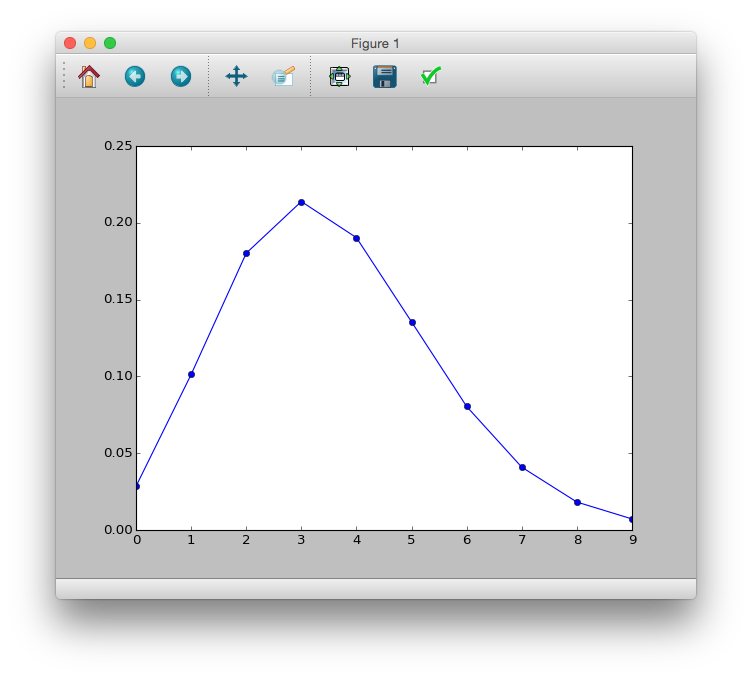
Überlagerung mit tatsächlichen Daten
>>> pdata.hist(bins=[i - 0.5 for i in range(11)])
>>> pandas.Series(prob*50).plot()
>>> plt.plot()
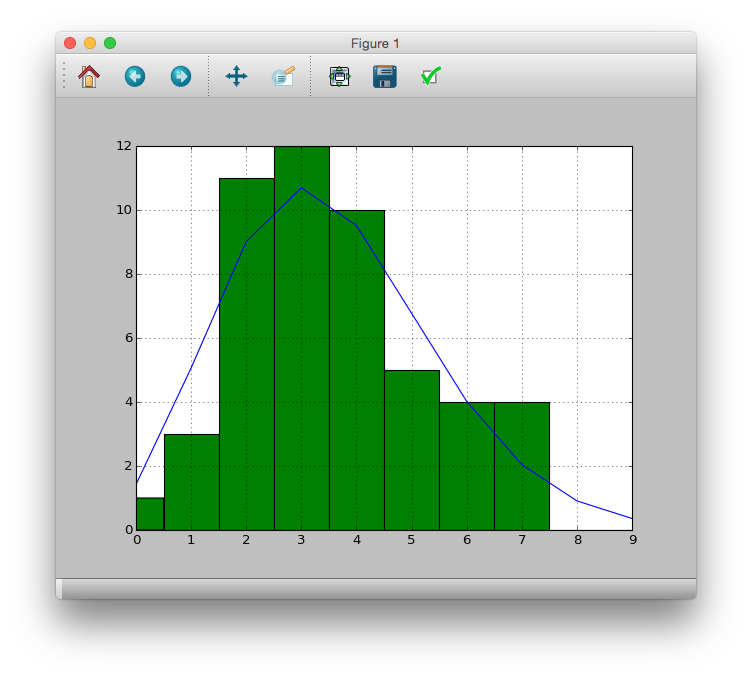
Aus diesem Ergebnis wird angenommen, dass die Beobachtungsdaten durch die Poisson-Verteilung ausgedrückt werden können.
2.3 Wie ist die Poisson-Verteilung?
Ein bisschen mehr Details über die Poisson-Distribution.
Definition der Poisson-Verteilung
Wahrscheinlichkeit, wenn der Mittelwert $ \ lambda $ ist Wahrscheinlichkeit, wenn die Variable $ y $ ist
p(y|\lambda) = \frac{\lambda ^{y}\exp(-\lambda)}{y!}
Natur
-Die Form der Kurve ändert sich abhängig vom Wert von $ \ lambda $ -Nehmen Sie den Wert von $ y \ in $ {$ 0, 1, 2, \ dots, \ infty $} und für alle $ y $
\sum^{\infty}_{y=0}p(y|\lambda) = 1
- Der Durchschnitt der Wahrscheinlichkeitsverteilung ist $ \ lambda $ ($ \ lambda \ geq 0 $)
- Verteilung und Mittelwert sind gleich
Gründe für die Wahl der Poisson-Distribution dieses Mal
- Der in den Daten enthaltene Wert $ y_i $ ist eine nicht negative Ganzzahl (Zähldaten)
- $ y_i $ hat eine Untergrenze (0), aber keine Obergrenze
- Der Mittelwert und die Varianz der beobachteten Daten sind nahezu gleich
2.4 Höchstwahrscheinlich Schätzung der Poisson-Verteilungsparameter
Höchstwahrscheinlich Schätzmethode
Eine Methode zur Bestimmung der "Anpassungsgüte" eines Modells namens ** Wahrscheinlichkeit **.
Bestimmen Sie im Fall der Poisson-Verteilung $ \ lambda $.
Das Produkt der Wahrscheinlichkeit $ p (y_i | \ lambda) $ für alle einzelnen $ i $, wenn ein bestimmtes $ \ lambda $ bestimmt wird
Die Wahrscheinlichkeit wird als $ L (\ lambda) $ geschrieben. In diesem Fall,
\begin{eqnarray*}
L( \lambda ) &=& (y_Wahrscheinlichkeit, dass 1 2 ist) \times (y_Wahrscheinlichkeit, dass 2 2 ist) \times \dots \times (y_Wahrscheinlichkeit, dass 50 3 ist)\\
&=& p(y_1 | \lambda) \times p(y_2 | \lambda) \times p(y_3 | \lambda) \times \dots \times p(y_50 | \lambda)\\
&=& \prod_{i}p(y_i | \lambda) = \prod_{i} \frac{\lambda^{y_i} \exp (-\lambda)}{y_i !}
\end{eqnarray*}
Es wird. Das Produkt wird verwendet, um die Wahrscheinlichkeit zu berechnen, dass 50 Personen der Beobachtung entsprechen (= die Wahrscheinlichkeit, dass 50 Ereignisse wahr sind).
Da es schwierig ist, die Wahrscheinlichkeitsfunktion $ L (\ lambda) $ so wie sie ist zu verwenden, wird im Allgemeinen die ** log-Wahrscheinlichkeitsfunktion ** verwendet.
\begin{eqnarray*}
\log L(\lambda) &=& \log \left( \prod_{i} \frac{\lambda^{y_i} \exp (-\lambda)}{y_i !} \right) \\
&=& \sum_i \log \left( \frac{\lambda^{y_i} \exp (-\lambda)}{y_i !} \right) \\
&=& \sum_i \left( \log(\lambda^{y_i} \exp (-\lambda)) - \log y_i ! \right)\\
&=& \sum_i \left( y_i \log \lambda - \lambda - \sum^{y_i}_{k} \log k \right)
\end{eqnarray*}
Stellen Sie die Beziehung zwischen dieser logarithmischen Wahrscheinlichkeit $ \ log L (\ lambda) $ und $ \ lambda $ grafisch dar.
# logL <- function(m) sum(dpois(data, m, log=TRUE))
# lambda <- seq(2, 5, 0.1)
# plot(lambda, sapply(lambda, logL), type="l")
>>> logL = lambda m: sum(sct.poisson.logpmf(data, m))
>>> lmd = [i / 10. for i in range(20, 50)]
>>> plt.plot(lmd, [logL(m) for m in lmd])
>>> plt.show()
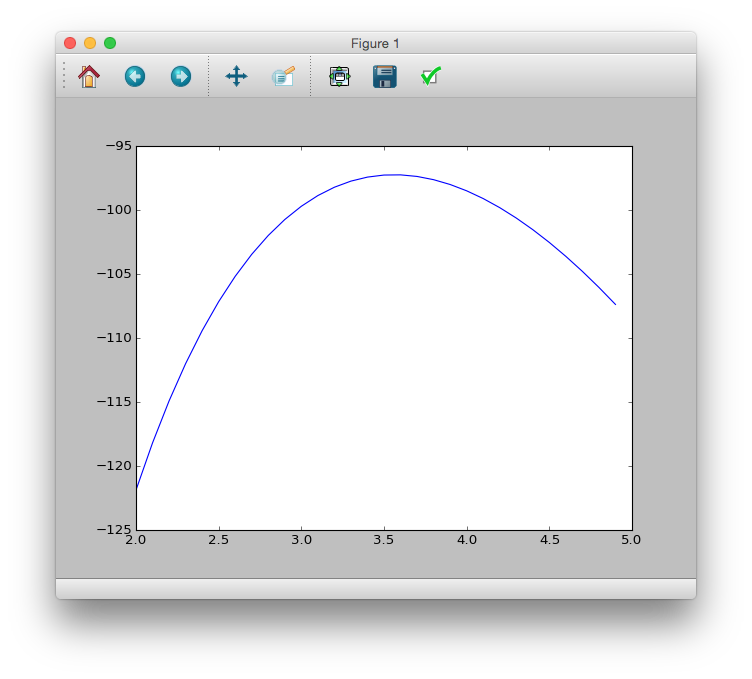
Die logarithmische Wahrscheinlichkeit $ \ log L (\ lambda) $ ist eine monoton ansteigende Funktion der Wahrscheinlichkeit $ L (\ lambda) $ Wenn die logarithmische Wahrscheinlichkeit maximal ist, ist auch die Wahrscheinlichkeit maximal.
Wenn Sie sich die Grafik ansehen, sehen Sie, dass die höchste Wahrscheinlichkeit bei $ \ lambda = 3,5 $ liegt.
Der spezifische Maximalwert kann der Maximalwert der logarithmischen Wahrscheinlichkeit sein (= wenn die Steigung 0 wird).
Mit anderen Worten
\begin{eqnarray*}
\frac{\partial \log L(\lambda)}{\partial \lambda} = \sum_i \left\{ \frac{y_i}{\lambda} - 1 \right\} = \frac{1}{\lambda} \sum_i y_i - 50 &=& 0 \\
\lambda &=& \frac{1}{50}\sum_i y_i \\
&=& \frac{Alle y_Ich summiere}{Die Anzahl der Daten}(=Beispieldurchschnitt der Daten) \\
&=& 3.56
\end{eqnarray*}
Das $ Lambda $, das die logarithmische Wahrscheinlichkeit und die Wahrscheinlichkeit maximiert, wird als ** wahrscheinlichste Schätzung ** bezeichnet, und das von dem spezifischen $ y_i $ bewertete $ \ lambda $ wird als ** wahrscheinlichste Schätzung ** bezeichnet. ..
Verallgemeinerung
Sei $ p (y_i | \ theta) $ die Wahrscheinlichkeit, dass Beobachtungsdaten $ y_i $ aus der Wahrscheinlichkeitsverteilung mit $ \ theta $ als Parameter erzeugt werden. Wahrscheinlichkeit, logarithmische Wahrscheinlichkeit
\begin{eqnarray*}
L(\theta | Y) &=& \prod_i p(y_i | \theta) \\
\log L(\theta | Y) &=& \sum_i \log p(y_i | \theta)
\end{eqnarray*}
Es wird.
So wählen Sie eine Wahrscheinlichkeitsverteilung
Betrachten Sie die folgenden Punkte.
――Ist die Menge, die Sie erklären möchten, diskret oder kontinuierlich? ――Was ist der Bereich des Betrags, den Sie erklären möchten? ――Wie ist die Beziehung zwischen dem Stichprobenmittelwert und der Stichprobenvarianz des Betrags, den Sie erklären möchten?
Als Beispiel für die Verteilung, die im statistischen Modell der Zähldaten verwendet wird:
- ** Poisson-Verteilung **: Daten sind diskrete Werte, Bereich über Null, keine Obergrenze, durchschnittliche $ \ ca. $ -Verteilung
- ** Binäre Verteilung **: Daten sind diskrete Werte, endlicher Bereich $ \ {0, 1, 2, \ Punkte, N } $ über Null, Varianz ist eine Funktion des Durchschnitts
Zur kontinuierlichen Verteilung
- ** Normalverteilung **: Daten sind kontinuierlich, Bereich ist $ [- \ infty, + \ infty] $, Varianz wird unabhängig vom Mittelwert bestimmt
- ** Gammaverteilung **: Daten sind kontinuierliche Werte, Bereich ist $ [0, + \ infty] $, Varianz ist eine Funktion des Durchschnitts
- ** Gleichmäßige Verteilung **: Daten sind kontinuierliche Werte, begrenzt
Als nächstes folgt Generalized Linear Model (GLM).
Recommended Posts