[PYTHON] [Einführung zur Minimierung] Datenanalyse mit SEIR-Modell ♬
In Vorbereitung auf die Datenanalyse von COVID-19 erklären wir, wie das folgende Diagramm ausgegeben wird.
Diese Abbildung ist eine Abbildung, in der das SEIR-Modell für Infektionskrankheiten unter Verwendung von minim @ scipy an die angegebenen Daten angepasst wird.
 Die Methode ist fast wie unten gezeigt. Beide waren in vielerlei Hinsicht hilfreich.
【Referenz】
① Beginn des mathematischen Modells für Infektionskrankheiten: Überblick über das SEIR-Modell von Python und Einführung in die Parameterschätzung
② Mathematisches Vorhersagemodell für Infektionskrankheiten (SIR-Modell): Fallstudie (1)
③ Ich habe versucht, das Verhalten des neuen Koronavirus mit dem SEIR-Modell vorherzusagen.
Die Methode ist fast wie unten gezeigt. Beide waren in vielerlei Hinsicht hilfreich.
【Referenz】
① Beginn des mathematischen Modells für Infektionskrankheiten: Überblick über das SEIR-Modell von Python und Einführung in die Parameterschätzung
② Mathematisches Vorhersagemodell für Infektionskrankheiten (SIR-Modell): Fallstudie (1)
③ Ich habe versucht, das Verhalten des neuen Koronavirus mit dem SEIR-Modell vorherzusagen.
Was ich getan habe
・ Codeerklärung ・ Versuchen Sie, mit dem SIR-Modell und dem SEIR-Modell zu passen · Andere Modelle
・ Codeerklärung
Der gesamte Code ist unten. ・ Collective_particles / minimieren_params.py Ich werde die Erklärung der obigen Referenz überlassen und hier den diesmal verwendeten Code erläutern. Die Daten wurden aus Referenz (2) verwendet. Für den Minimierungscode habe ich auch auf Referenz referred verwiesen. Die zu verwendende Bibliothek lautet wie folgt. Dieses Mal ist es in der keras-gpu-Umgebung der conda-Umgebung von Windows 10 implementiert, aber es ist zuvor einschließlich scipy installiert.
#include package
import numpy as np
from scipy.integrate import odeint
from scipy.optimize import minimize
import matplotlib.pyplot as plt
Die Differentialgleichung des SEIR-Modells ist unten definiert. Hier wird angemessen entschieden, was mit N zu tun ist, aber in diesem Vorschlag sind N = 763 Personen aus dem in Referenz (2) veröffentlichten Papier, das festgelegt wurde. Die Differentialgleichung des SEIR-Modells lautet wie folgt Hier wird in Referenz (1) N in die Variable Beta verschoben und nicht explizit ausgedrückt, aber die folgende Formel ist in Bezug auf Wan leichter zu verstehen. Das Folgende wird aus Referenz quoted zitiert.
{\begin{align}
\frac{dS}{dt} &= -\beta \frac{SI}{N} \\
\frac{dE}{dt} &= \beta \frac{SI}{N} -\epsilon E \\
\frac{dI}{dt} &= \epsilon E -\gamma I \\
\frac{dR}{dt} &= \gamma I \\
\end{align}
}
Wenn Sie sich das Folgende ansehen, während Sie sich das Obige ansehen, können Sie es verstehen, weil es genau richtig ist.
#define differencial equation of seir model
def seir_eq(v,t,beta,lp,ip):
N=763
a = -beta*v[0]*v[2]/N
b = beta*v[0]*v[2]/N-(1/lp)*v[1]
c = (1/lp)*v[1]-(1/ip)*v[2]
d = (1/ip)*v[2]
return [a,b,c,d]
Zunächst wird eine Lösung basierend auf dem Anfangswert als gewöhnliche Differentialgleichung erhalten.
#solve seir model
N,S0,E0,I0=762,0,1,0
ini_state=[N,S0,E0,I0]
beta,lp,ip=6.87636378, 1.21965986, 2.01373496 #2.493913 , 0.95107715, 1.55007883
t_max=14
dt=0.01
t=np.arange(0,t_max,dt)
plt.plot(t,odeint(seir_eq,ini_state,t,args=(beta,lp,ip))) #0.0001,1,3
plt.legend(['Susceptible','Exposed','Infected','Recovered'])
plt.pause(1)
plt.close()
Die Ergebnisse sind wie folgt: Wenn Sie die Parameter hier schätzen und ändern, können Sie sie grob anpassen, bei komplizierten ist dies jedoch schwierig.
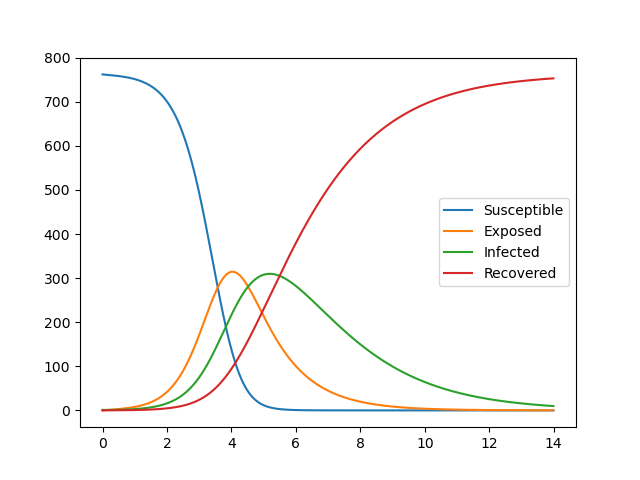 Ersetzen Sie die Daten, wie in Referenz (2) gezeigt, und geben Sie sie wie unten gezeigt in das Diagramm aus.
Ersetzen Sie die Daten, wie in Referenz (2) gezeigt, und geben Sie sie wie unten gezeigt in das Diagramm aus.
#show observed i
#obs_i=np.loadtxt('fitting.csv')
data_influ=[3,8,28,75,221,291,255,235,190,125,70,28,12,5]
data_day = [1,2,3,4,5,6,7,8,9,10,11,12,13,14]
obs_i = data_influ
plt.plot(obs_i,"o", color="red",label = "data")
plt.legend()
plt.pause(1)
plt.close()
Das Ergebnis ist wie folgt, und da dies eine Ausgabe zur Bestätigung des Weges ist, werden Überschriften usw. weggelassen.
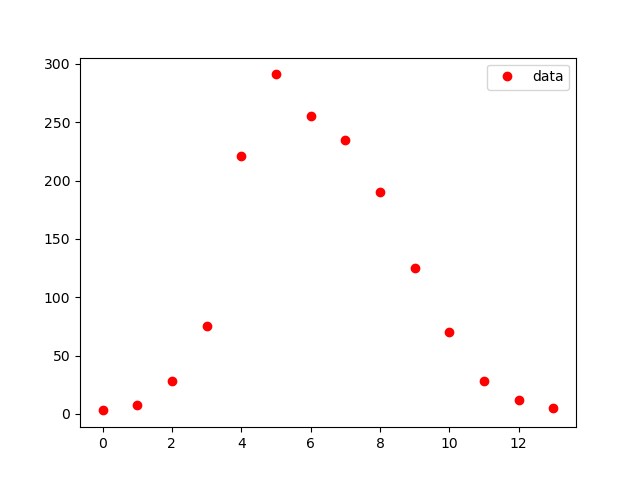 Der nächste ist der Schätzungsteil. Diese Bewertungsfunktion berechnet mit einer Differentialgleichung unter Verwendung des Wertes des Arguments und gibt das Bewertungsergebnis zurück.
Der nächste ist der Schätzungsteil. Diese Bewertungsfunktion berechnet mit einer Differentialgleichung unter Verwendung des Wertes des Arguments und gibt das Bewertungsergebnis zurück.
#function which estimate i from seir model func
def estimate_i(ini_state,beta,lp,ip):
v=odeint(seir_eq,ini_state,t,args=(beta,lp,ip))
est=v[0:int(t_max/dt):int(1/dt)]
return est[:,2]
Die logarithmische Wahrscheinlichkeitsfunktion ist wie folgt definiert.
- Siehe Referenz ① Grundsätzlich besteht das Problem darin, die Parameter zu ändern, um den Maximalwert dieser logarithmischen Wahrscheinlichkeitsfunktion zu ermitteln. (Eigentlich ist es ein Minimierungsproblem, wenn man ein Minus nimmt)
- Hier wird der Absolutwert verwendet, um zu verhindern, dass das Protokollargument negativ wird.
#define logscale likelihood function
def y(params):
est_i=estimate_i(ini_state,params[0],params[1],params[2])
return np.sum(est_i-obs_i*np.log(np.abs(est_i)))
Verwenden Sie die Minimierungsfunktion von Scipy unten, um den Maximalwert zu ermitteln.
#optimize logscale likelihood function
mnmz=minimize(y,[beta,lp,ip],method="nelder-mead")
print(mnmz)
Die Ausgabe ist wie folgt
>python minimize_params.py
final_simplex: (array([[6.87640764, 1.21966435, 2.01373196],
[6.87636378, 1.21965986, 2.01373496],
[6.87638203, 1.2196629 , 2.01372646],
[6.87631916, 1.21964456, 2.0137297 ]]), array([-6429.40676091, -6429.40676091, -6429.40676091, -6429.4067609 ]))
fun: -6429.406760912483
message: 'Optimization terminated successfully.'
nfev: 91
nit: 49
status: 0
success: True
x: array([6.87640764, 1.21966435, 2.01373196])
Nehmen Sie beta_const, lp, gamma_const wie folgt aus dem Berechnungsergebnis heraus und berechnen Sie R0 unten. Dies ist die Grundanzahl der Reproduktionen, die eine Richtlinie für die Ausbreitung der Infektion darstellt. Wenn R0 <1 ist, breitet sie sich nicht aus, aber wenn R0> 1, breitet sie sich aus und ist ein Index, der den Grad anzeigt.
#R0
beta_const,lp,gamma_const = mnmz.x[0],mnmz.x[1],mnmz.x[2] #Infektionsrate, Wartezeit der Infektion, Entfernungsrate (Wiederherstellungsrate)
print(beta_const,lp,gamma_const)
R0 = beta_const*(1/gamma_const)
print(R0)
Diesmal ist es wie folgt und da R0 = 3,41 ist, hat sich die Infektion ausgebreitet.
6.876407637532918 1.2196643491443309 2.0137319643699927
3.4147581501415165
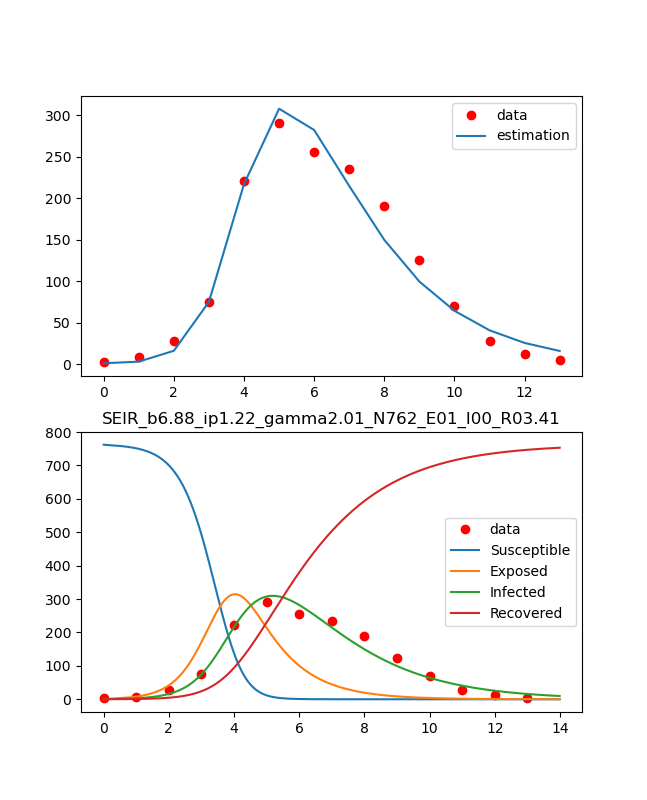
Das auf diese Weise erhaltene Ergebnis wird in der Grafik angezeigt.
#plot reult with observed data
fig, (ax1,ax2) = plt.subplots(2,1,figsize=(1.6180 * 4, 4*2))
lns1=ax1.plot(obs_i,"o", color="red",label = "data")
lns2=ax1.plot(estimate_i(ini_state,mnmz.x[0],mnmz.x[1],mnmz.x[2]), label = "estimation")
lns_ax1 = lns1+lns2
labs_ax1 = [l.get_label() for l in lns_ax1]
ax1.legend(lns_ax1, labs_ax1, loc=0)
lns3=ax2.plot(obs_i,"o", color="red",label = "data")
lns4=ax2.plot(t,odeint(seir_eq,ini_state,t,args=(mnmz.x[0],mnmz.x[1],mnmz.x[2])))
ax2.legend(['data','Susceptible','Exposed','Infected','Recovered'], loc=0)
ax2.set_title('SEIR_b{:.2f}_ip{:.2f}_gamma{:.2f}_N{:d}_E0{:d}_I0{:d}_R0{:.2f}'.format(beta_const,lp,gamma_const,N,E0,I0,R0))
plt.savefig('./fig/SEIR_b{:.2f}_ip{:.2f}_gamma{:.2f}_N{:d}_E0{:d}_I0{:d}_R0{:.2f}_.png'.format(beta_const,lp,gamma_const,N,E0,I0,R0))
plt.show()
plt.close()
Das Ergebnis ist wie oben.
· Andere Modelle
Als ich diese Berechnung durchführte, fand ich ein etwas einfacheres SIR-Modell und ein etwas komplizierteres Modell, daher werde ich sie zusammenfassen. Das SIR-Modell ist wie folgt, da es ein Modell ist, das Exposed from S-E-I-R ignoriert.
{\begin{align}
\frac{dS}{dt} &= -\beta \frac{SI}{N} \\
\frac{dI}{dt} &= \beta \frac{SI}{N} -\gamma I \\
\frac{dR}{dt} &= \gamma I \\
\end{align}
}
Sie können die Bedeutung von $ R_0 $ verstehen, indem Sie wie folgt umschreiben.
{\begin{align}
\frac{dS}{dt} &= -R_0 \frac{S}{N} \frac{dR}{dt} \\
R_0 &= \frac{\beta}{\gamma}\\
\frac{dI}{dt} &= 0 \Infizierte Person Höhepunkt bei\\
R_0 &= \frac{\beta}{\gamma}= \frac{N}{S_0} \\
\end{align}
}
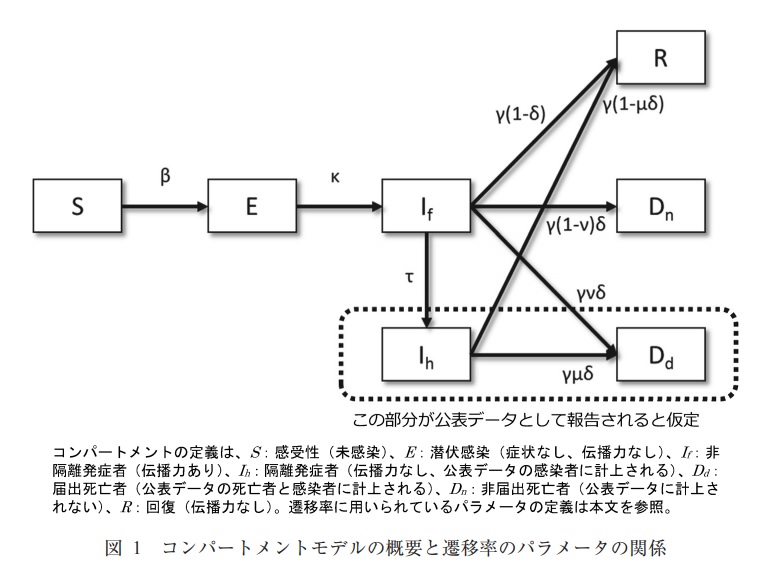
Andererseits wird es in einer komplizierten Situation wie einem Übergang von Tod und Tod ohne Benachrichtigung wie folgt sein. Es wird angenommen, dass die Toten nicht zur Infektion beitragen.
- COVID-19 könnte so aussehen
Die Abbildung stammt aus dem folgenden Dokument in Referenz ①
・ Analyse von Epidemien der Ebola-Virus-Infektion unter Verwendung eines mathematischen Modells

Zusammenfassung
-Datenanpassung kann jetzt automatisch durch Minimieren von @ scipy durchgeführt werden. ・ Ich konnte die tatsächlichen Daten mit dem SEIR-Modell abgleichen
・ Beim nächsten Mal möchte ich die Daten jedes Landes von COVID-19 analysieren.
Recommended Posts