[PYTHON] Ich habe versucht, die Hauptkomponenten mit Titanic-Daten zu analysieren!
Überblick
Verwenden der Titanic-Daten, die häufig zu Beginn von kaggle verwendet werden, Ich habe versucht, die Hauptkomponenten zu analysieren. Diesmal wurde dies jedoch nicht zum Zweck der Vorhersage durchgeführt. Der Zweck bestand einfach darin, die Eigenschaften der Daten unter Verwendung einer statistischen Analysemethode zu beobachten. Deshalb habe ich mich entschlossen, die Hauptkomponenten der Zug- / Testdaten gemeinsam zu analysieren.
Annahme
――Was ist die Hauptkomponentenanalyse?
Für Daten, die durch mehrere Achsen (Variablen) dargestellt werden
Eine Methode, um "Achse mit hoher Datenvariation" zu finden.
Wegen der Dimensionskomprimierung bei der Vorhersage
Bei der Analyse vorhandener Daten erfolgt dies häufig zur Zusammenfassung.
In der Abbildung unten (Bild)
Es gibt die rote Achse mit der höchsten Variation, gefolgt von der blauen Achse mit der höchsten Variation (senkrecht zur roten Achse).
Die Hauptkomponentenanalyse besteht darin, solche roten und blauen Achsen zu finden.
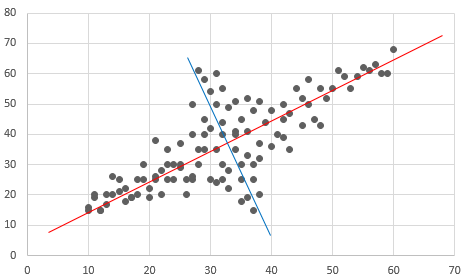
Analyseübersicht
--Analytische Daten Titanic-Daten (Zug + Test). Sie können es von folgenden herunterladen (kaggle). (Sie müssen sich jedoch anmelden, um zu kaggen.) https://www.kaggle.com/c/titanic/data
- Bestätigungspunkt
- Beitragsrate
- Einzigartiger Vektor
- Faktor laden --Variationen, die in der Analyse ausgeschlossen werden sollen Dieses Mal schließen wir zur einfachen Analyse die folgenden Variablen aus, die schwer vorverarbeiten können.
- Cabin
- Ticket
- Name
Analyse_Details
- Bibliotheksimport
import os
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import display
from sklearn.decomposition import PCA
- Definition der Variablen (CSV-Speicherziel für Titandaten usw.)
- Prämissencode, der Titanic-Daten csv (train.csv, test.csv) im Ordner "data" speichert.
#Aktueller Ordner
forlder_cur = os.getcwd()
print(" forlder_cur : {}".format(forlder_cur))
print(" isdir:{}".format(os.path.isdir(forlder_cur)))
#Datenspeicherort
folder_data = os.path.join(forlder_cur , "data")
print(" folder_data : {}".format(folder_data))
print(" isdir:{}".format(os.path.isdir(folder_data)))
#Datendatei
## train.csv
fpath_train = os.path.join(folder_data , "train.csv")
print(" fpath_train : {}".format(fpath_train))
print(" isdir:{}".format(os.path.isfile(fpath_train)))
## test.csv
fpath_test = os.path.join(folder_data , "test.csv")
print(" fpath_test : {}".format(fpath_test))
print(" isdir:{}".format(os.path.isfile(fpath_test)))
# id
id_col = "PassengerId"
#Objektive Variable
target_col = "Survived"
- Importieren Sie Titanic-Daten Die mit dem folgenden Code erstellten Daten "all_data" (train + test) werden später verwendet.
# train.csv
train_data = pd.read_csv(fpath_train)
print("train_data :")
print("n = {}".format(len(train_data)))
display(train_data.head())
# test.csv
test_data = pd.read_csv(fpath_test)
print("test_data :")
print("n = {}".format(len(test_data)))
display(test_data.head())
# train_and_test
col_list = list(train_data.columns)
tmp_test = test_data.assign(Survived=None)
tmp_test = tmp_test[col_list].copy()
print("tmp_test :")
print("n = {}".format(len(tmp_test)))
display(tmp_test.head())
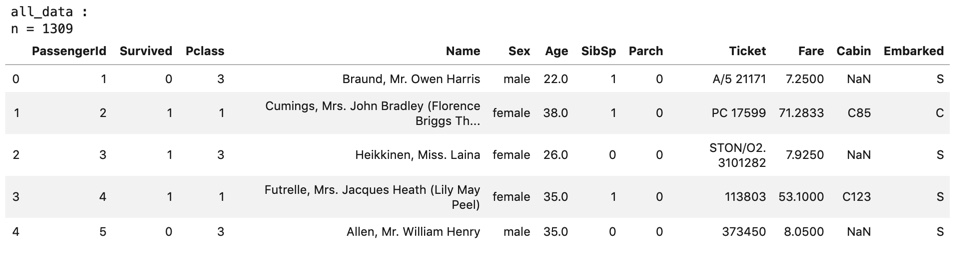
all_data = pd.concat([train_data , tmp_test] , axis=0)
print("all_data :")
print("n = {}".format(len(all_data)))
display(all_data.head())
- Vorbehandlung Die Konvertierung von Dummy-Variablen, die fehlende Vervollständigung und das Löschen von Variablen werden für jede Variable durchgeführt, und die erstellten Daten "proc_all_data" werden später verwendet.
#Kopieren
proc_all_data = all_data.copy()
# Sex -------------------------------------------------------------------------
col = "Sex"
def app_sex(x):
if x == "male":
return 1
elif x == 'female':
return 0
#Vermisst
else:
return 0.5
proc_all_data[col] = proc_all_data[col].apply(app_sex)
print("columns:{}".format(col) , "-" * 40)
display(all_data[col].value_counts())
display(proc_all_data[col].value_counts())
print("n of missing :" , len(proc_all_data.query("{0} != {0}".format(col))))
# Age -------------------------------------------------------------------------
col = "Age"
medi = proc_all_data[col].median()
proc_all_data[col] = proc_all_data[col].fillna(medi)
print("columns:{}".format(col) , "-" * 40)
display(all_data[col].value_counts())
display(proc_all_data[col].value_counts())
print("n of missing :" , len(proc_all_data.query("{0} != {0}".format(col))))
print("median :" , medi)
# Fare -------------------------------------------------------------------------
col = "Fare"
medi = proc_all_data[col].median()
proc_all_data[col] = proc_all_data[col].fillna(medi)
print("columns:{}".format(col) , "-" * 40)
display(all_data[col].value_counts())
display(proc_all_data[col].value_counts())
print("n of missing :" , len(proc_all_data.query("{0} != {0}".format(col))))
print("median :" , medi)
# Embarked -------------------------------------------------------------------------
col = "Embarked"
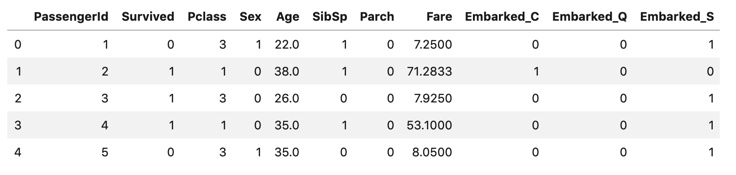
proc_all_data = pd.get_dummies(proc_all_data , columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
# Cabin -------------------------------------------------------------------------
col = "Cabin"
proc_all_data = proc_all_data.drop(columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
# Ticket -------------------------------------------------------------------------
col = "Ticket"
proc_all_data = proc_all_data.drop(columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
# Name -------------------------------------------------------------------------
col = "Name"
proc_all_data = proc_all_data.drop(columns=[col])
print("columns:{}".format(col) , "-" * 40)
display(all_data.head())
display(proc_all_data.head())
proc_all_data :
- Hauptkomponentenanalyse (Berechnung des Beitragssatzes)
#Erklärende Variable
feature_cols = list(set(proc_all_data.columns) - set([target_col]) - set([id_col]))
print("feature_cols :" , feature_cols)
print("len of feature_cols :" , len(feature_cols))
features = proc_all_data[feature_cols]
pca = PCA()
pca.fit(features)
print("Anzahl der Hauptkomponenten: " , pca.n_components_)
print("Beitragssatz: " , ["{:.2f}".format(ratio) for ratio in pca.explained_variance_ratio_])
Wie in den folgenden Ergebnissen gezeigt, ist die erste Hauptkomponente überwiegend sehr variabel.
Im Folgenden werden der Eigenvektor der ersten Hauptkomponente und die Faktorbelastung bestätigt.
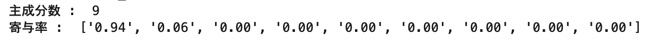
- Eindeutiger Vektor der ersten Hauptkomponente
6-1. Datentransformation
#Einzigartiger Vektor(Erste Hauptkomponente)
components_df = pd.DataFrame({
"feature":feature_cols
, "component":pca.components_[0]
})
components_df["abs_component"] = components_df["component"].abs()
components_df["rank_component"] = components_df["abs_component"].rank(ascending=False)
#Absteigende Sortierung nach Absolutwert des Vektorwerts
components_df.sort_values(by="abs_component" , ascending=False , inplace=True)
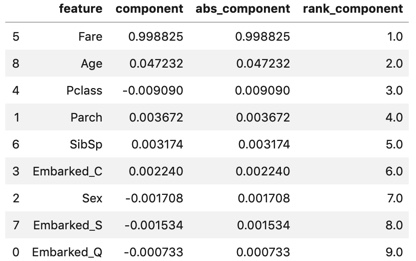
display(components_df)
components_df :
6-2. Grafik
#Diagrammerstellung
max_abs_component = max(components_df["abs_component"])
min_component = min(components_df["component"])
x_ticks_num = list(i for i in range(len(components_df)))
fig = plt.figure(figsize=(15,8))
plt.grid()
plt.title("Components of First Principal Component")
plt.xlabel("feature")
plt.ylabel("component")
plt.xticks(ticks=x_ticks_num , labels=components_df["feature"])
plt.bar(x_ticks_num , components_df["component"] , color="c" , label="components")
plt.plot(x_ticks_num , components_df["abs_component"] , color="r" , marker="o" , label="[abs] components")
plt.legend()
plt.show()
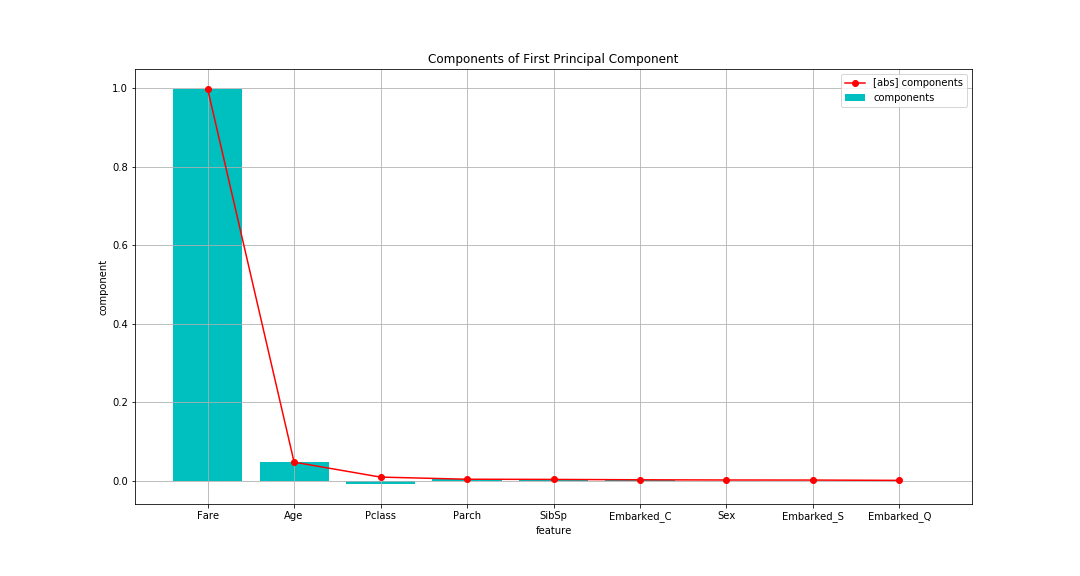
Der Tarif (Boarding-Gebühr) ist überwältigend hoch, gefolgt von Alter (Alter). Es gibt nur wenige andere.
Betrachtet man nur die Eigenvektoren, so scheint dies die Hauptkomponente zu sein, die von Fare zusammengefasst wird.
Da sich der Wert des Eigenvektors jedoch in Abhängigkeit von der Größe der Dispersion der Zielvariablen ändert,
Schauen wir uns die Faktorbelastung an, die später berechnet wird.
- Faktorbelastung der ersten Hauptkomponente
7-1. Datentransformation
#Hauptkomponentenbewertung(Erste Hauptkomponente)
score = pca.transform(features)[: , 0]
#Faktor laden
dict_fact_load = dict()
for col in feature_cols:
data = features[col]
factor_loading = data.corr(pd.Series(score))
dict_fact_load[col] = factor_loading
fact_load_df = pd.DataFrame({
"feature":feature_cols
, "factor_loading":[dict_fact_load[col] for col in feature_cols]
})
fact_load_df["abs_factor_loading"] = fact_load_df["factor_loading"].abs()
fact_load_df["rank_factor_loading"] = fact_load_df["abs_factor_loading"].rank(ascending=False)
#Absteigende Sortierung nach Absolutwert des Vektorwerts
fact_load_df.sort_values(by="abs_factor_loading" , ascending=False , inplace=True)
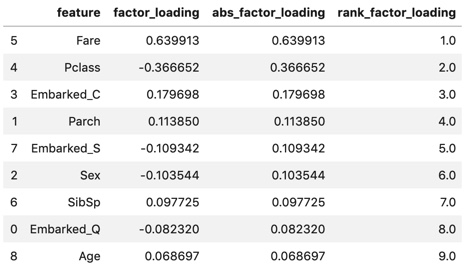
display(fact_load_df)
7-2. Grafik
#Diagrammerstellung
max_abs_factor_loading = max(fact_load_df["abs_factor_loading"])
min_factor_loading = min(fact_load_df["factor_loading"])
x_ticks_num = list(i for i in range(len(fact_load_df)))
plt.figure(figsize=(15,8))
plt.grid()
plt.title("Factor Lodings of First Principal Component")
plt.xlabel("feature")
plt.ylabel("factor loading")
plt.xticks(ticks=x_ticks_num , labels=fact_load_df["feature"])
plt.bar(x_ticks_num , fact_load_df["factor_loading"] , color="c" , label="factor loadings")
plt.plot(x_ticks_num , fact_load_df["abs_factor_loading"] , color="r" , marker="o" , label="[abs] factor loadings")
plt.legend()
plt.show()
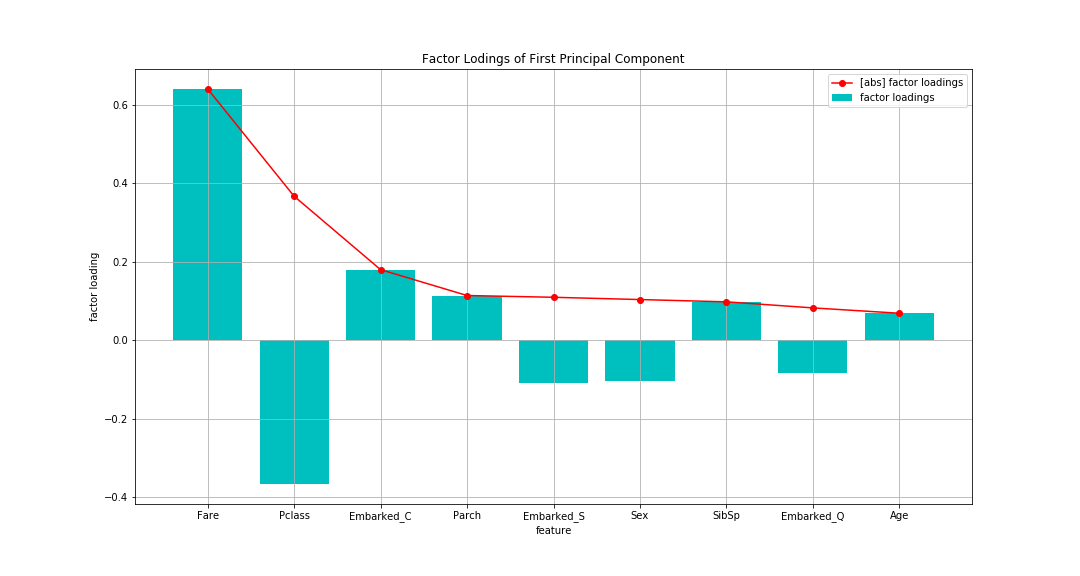
Betrachtet man den Faktor Laden, Als absoluter Wert (Bruchlinie) ist der Tarif (Boarding-Gebühr) am höchsten, gefolgt von Pclass (Passagierklasse). Mit einem Unterschied in Pclass sind die anderen ungefähr so klein. Die erste Hauptkomponente ist "Indikator zur Bewertung des Wohlstands" Es scheint, dass Sie daran denken können.
Im Vergleich zu dem oben bestätigten Eigenvektor In Bezug auf den Tarif war der Eigenvektor überwiegend der größte, aber die Faktorbelastung machte keinen solchen Unterschied. In Bezug auf das Alter war es das zweitgrößte im Eigenvektor, aber das niedrigste in der Faktorbelastung. Tarif und Alter scheinen stark verteilt zu sein.
Wenn Sie versuchen, die Korrelation zwischen der Hauptkomponentenbewertung und jeder Variablen anhand des Eigenvektors zu beurteilen,
Ich wollte gerade einen Fehler machen.
Die Faktorbelastung sollte berechnet und bestätigt werden.
Zusammenfassung
Als Ergebnis der Hauptkomponentenanalyse Der Index "Vermögen bewerten" wird erhalten. Der Index war derjenige, den die meisten Kunden (alle Daten) teilen (variieren) konnten.
Wir haben auch festgestellt, dass sich die Trends zwischen dem Eigenvektor und der Faktorbelastung unterscheiden. das ist, "(Um den Inhalt der Hauptkomponente zu überprüfen) Wenn Sie die Korrelation zwischen den Hauptkomponenten und jeder Variablen betrachten, betrachten Sie die Faktorbelastung. Nur nach dem Eigenvektor zu urteilen (Weil es von der Größe der Dispersion beeinflusst wird) Kann irreführend sein " Es gibt eine Einschränkung.
Recommended Posts