Lesehinweis: Einführung in die Datenanalyse mit Python
Dies ist ein Memo, das ich beim Lesen der Einführung in die Datenanalyse von Python erwischt habe. Ich laufe lieber mit Pycharm über IPython. Ich füge beim Lesen hinzu. Ich bin ein Anfänger in der Programmierung selbst und stecke an verschiedenen Stellen fest. Deshalb schreibe ich es als Referenz für diejenigen, die später auf die gleiche Weise lernen werden, und als Referenz, wenn ich es vergesse.
Umgebung ・ Windows 10 (64 Bit) ・ Python3.5 (Anaconda) ・ Pandas 0.18.1 ・ Datenanalyse von Python, erste Ausgabe, zweiter Druck Referenz ・ Englische Version der richtigen / falschen Tabelle * Es wäre schön, wenn O'Reilly Japan sie übersetzen und veröffentlichen würde. Also wirst du es niemals tun. ・ 11.06.2016 Ich habe festgestellt, dass https://github.com/wesm/pydata-book Ist es nicht am besten, es zu benutzen?
Kapitel 2
S.22, 23 usa.gov Datenerscheinung Top-Zeitzone
Ob Sie es in IPython oder in einer integrierten Entwicklungsumgebung ausführen,
import matplotlib.pyplot as plt
import pandas as pd
Implementiert. plt und pd sind persönliche Freiheit, aber es gibt eine Konvention, dass sie plt und pd sind. numpy ist np.
Bei der Anzeige von Grafiken in einer integrierten Entwicklungsumgebung
var=tz_counts[:10].plot(kind="barh", rot=0)
plt.show(var)
Ich habe das geschrieben und es hat funktioniert.
Separat
tz_counts[:10].plot(kind="barh", rot=0)
plt.show()
Aber es scheint okay zu sein. Wenn Sie mit mehreren Daten und dann "plt.show ()" zeichnen, werden mehrere Diagramme gleichzeitig angezeigt. Verwenden Sie Unterzeichnungen, um mehrere Diagramme nebeneinander anzuzeigen. Wenn es sich um ein Buch handelt, wird es auf Seite 45 angezeigt. Weitere Informationen zu matplotlib finden Sie unter hier.
P.37 pivot_table In pivot_table werden Zeilen und Spalten angezeigt, aber ab dem 28. Mai 2016 tritt ein Fehler (TypeError: pivot_table () hat ein unerwartetes Schlüsselwort argument'rows 'auf). Laut hier ・ Zu indizierende Zeilen, ・ Spalten zu Spalten, Es kann durch Ändern vermieden werden. Es löst es tatsächlich in meiner Umgebung. Eine ähnliche Bearbeitung ist erforderlich, wenn pivot_table nach S.37 (S.44 und S.49) angezeigt wird.
- Wie in der Antwort gegen Ende von hier angegeben, wurde es letztes Jahr geändert, um Index und Spalten zu verwenden. Zustand.
S.39 Beschreibung von get_top1000
Ab dem 04.06.2016 wird eine Warnung ausgegeben, in der Sie aufgefordert werden, "group.sort_index" in "group.sort_values" zu ändern. Ich habe es leise in Werte geändert.
S.40 Namensgrafikzeichnung
Ich verwende Pycharm anstelle von IPython, aber wie in dem Buch, in dem ich eine Teilmenge erstelle und sie gemäß dem Buch zeichne,
subset = total_births[['John', 'Harry', 'Mary', 'Marilyn']]
var = subset.plot(subplots=True, figsize=(12, 10), grid=False, title = "Number of births per year")
plt.show(var)
Dann ist "ValueError: Der Wahrheitswert eines Arrays mit mehr als einem Element nicht eindeutig. Verwenden Sie a.any () oder a.all ()". Es muss einen guten Grund geben, warum dies angezeigt wird, aber derzeit verstehe ich nicht.
Durch Ändern von "plt.show (var)" in "plt.show (var.all ())" konnte ich vorerst ein Diagramm zeichnen, das einem Buch ähnelt.
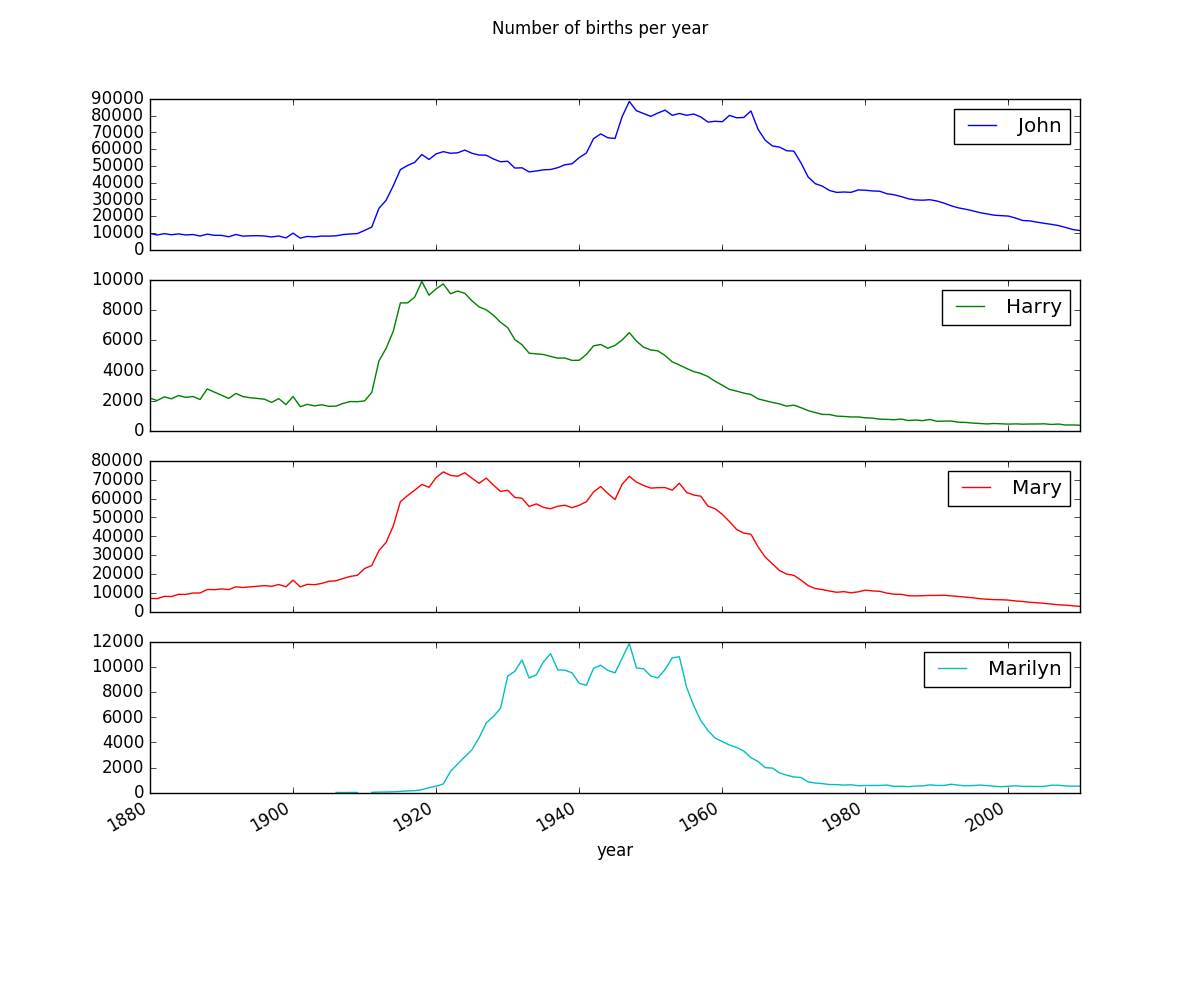
Als ich das Paket am 03.06.2016 einzeln aktualisiert habe, um dieses Diagramm anzuzeigen und erneut auszuführen, ist ein Fehler aufgetreten. Also, da es beim Ausführen von conda update --all herabgestuft wird
・ Hdf5 1.8.16-> 1.8.15.1
・ Numexpr 2.6.0-> 2.5.2
・ Numpy 1.11.0-> 1.10.4
Danach konnte ich das Diagramm wieder anzeigen. Es spielt keine Rolle, ob Sie numpy und numexpr separat aktualisieren, aber wenn Sie numpy auf 1.11.0 und dann numexpr auf 2.6.0 setzen, kann der Syntax "SyntaxError: (Unicode-Fehler)" unicodeescape "keine Bytes an Position dekodieren. 2-3: Ein Fehler wird als abgeschnittenes \ UXXXXXXXX-Escape angezeigt`, daher scheint mit dieser Kombination etwas nicht zu stimmen.
S.41 Abbildung 2-6 Zeichnung der Summe von table1000.prop nach Jahr und Geschlecht
Da "np.linspace (0, 1.2, 13)" beschrieben wird, ist es notwendig, "numpy as np" zu importieren. Es scheint auch, dass die Tendenz des Verhältnisses zur Abnahme beim Zeichnen der Top 100 bemerkenswerter ist als beim Zeichnen der Top 1000. Import ist vorerst
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
Ist es ein gutes Gefühl, es zu behalten?
P.43 get_quantile_count() Aufgrund von Änderungen in den API-Spezifikationen muss Folgendes beschrieben werden.
def get_quantile_count(group, q=0.5):
group = group.sort_values(by='prop', ascending=False)
return group.prop.cumsum().values.searchsorted(q) + 1
Group.prop.cumsum (). Values.searchsorted (q) ist der geänderte Teil.
Kapitel 3
Um P.52 randn ()
Importieren Sie, wenn Sie andere als IPython wie Pycharm ausführen
import numpy as np
import pandas as pb
import matplotlib.pyplot as plt
Dann wird "randn ()" als "np.random.randn ()" beschrieben. Auf S.61 wird np.random.randn () verwendet, daher muss es hier möglicherweise geändert werden. Es ist auch in der Korrektheitstabelle auf der englischen Website beschrieben.
- In dem Jupyter-Notizbuch, das von github heruntergeladen werden kann, wird import numpy.random als randn importiert. Es ist ein bisschen verwirrend, weil die Notation nicht einheitlich ist, aber ich frage mich, ob es in diesem Buch nicht darum geht, Python selbst zu lernen.
S.58 IPython HTML-Notizbuch
Jetzt heißt es Jupyter.
S.59 Verwenden von IPython von Editoren und IDEs
Mit Pycharm können Sie auch Jupyter-Notizbücher erstellen und ausführen. Es kann auf die gleiche Weise wie eine .py-Datei erstellt werden. Ich habe bisher keine Bedeutung in Pycharm gefunden. Gibt es eine nützliche Funktion? Ab dem 04.06.2016 können Sie das Ergebnis von "% magic" oder "% reset" nicht sehen? Auch wenn Sie es von Pycharm aus ausführen.
Bei Pycharm ist die kostenpflichtige Version (Professional Edition) erforderlich, um die Verarbeitungsgeschwindigkeit zu berechnen.
Kapitel 4
P.90 data Da Daten plötzlich erscheinen,
data = np.random.randn(2, 3)
Ich interpretierte es als und bestätigte den Prozess des Multiplizierens mit 10 und des Hinzufügens. Unnötig zu erwähnen, dass es auf Pycharm läuft
def main():
data = np.random.randn(2, 3)
print('data is\n', data)
print('data*10 is\n', data * 10)
print('data+data is\n', data + data)
if __name__ == '__main__':
main()
Es wird beschrieben als. Es kann hier einfacher sein, IPython gehorsam zu verwenden.
S.95 Definition von numerischen Zeichenfolgen
numeric_strings = np.array (['1.25', '- 9.6', '42'], dtype = np.string_), aber numeric_strings = np.array (['1.25', '- 9.6', '42']) Ist es nicht nutzlos?
Ich bin mir nicht sicher, warum ich es wage, es hier anzugeben. Das Ergebnis von numeric_strings.dtype ändert sich.
S.99 Dreidimensionales Array
Ich steckte fest, dass arr3d [0] eine 2x3-Matrix ist. Unter Berücksichtigung der x-Richtung (Zeile) y (Spalte) z-Richtung, Ich habe verstanden, dass es "arr3d [z] [x] [y] = arr3d [z, x, y]" war. Das Ergebnis von "np.shape (arr3d)" könnte auch durch Interpretation als (z, Zeile, Spalte) verstanden werden.
Ist es natürlich, dass die Reihenfolge nicht x, y, z ist? Ist es natürlich, eine andere Sprache zu sprechen? Ich bin verwirrt, weil ich zum ersten Mal ein 3D-Array in Python ernst genommen habe.
S.101 Definition von Namen
Wie im Buch beschrieben
names = np.array(['Bob','Joe', 'Will', "Bob", "Will", "Joe", "Joe"], dtype='|S4')
Dann funktioniert es nicht. Ich verstehe überhaupt nicht, was ich tue.
Vorerst,
names = np.array(['Bob','Joe', 'Will', "Bob", "Will", "Joe", "Joe"])
Es funktioniert normal, also mache ich es. Die Definition von "Daten" enthält eine korrekte Übersetzung. Ich bin mir nicht sicher, warum es hier ist und es gibt nichts anderes.
P.106 arr = np.arange(16).reshape((2,2,4)) 2 = z-Richtung 2 = x Richtung = Reihe 4 = y Richtung = Spalte Ich konnte es verstehen
arr.transpose ((1,0,2) ändert das, was ursprünglich in der Größenordnung von 0,1,2 bis 1,0,2 lag, dh wenn Sie es als Austausch der z-Achse und der x-Achse betrachten, Die Ansicht von "arr.transpose (1,0,2)" ist
array([[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]],
[[ 4, 5, 6, 7],
[12, 13, 14, 15]]])
Ich habe das verstanden.
p.107 swapaxes Ich könnte arr.swapaxes (1,2) verstehen, wenn ich dachte, dass die z-Achse = 0, die x-Achse = 1, die y-Achse = 2 und die x-Achse und die y-Achse vertauscht sind.
Es ist seltsam, dass "arr.swapaxes (2,1)" nicht dasselbe ist, und wenn man bedenkt, dass arr 2x2x3 ist, wäre beispielsweise "arr.swapaxes (2,3)" ein Fehler und "arr.swapaxes" Ich dachte, dass (2,2) `nichts ändert, aber keinen Fehler verursachen sollte, und als ich es versuchte, war es so, dass ich es nicht irgendwo bestätigen konnte. Ich tat.
P.108 randn Ich bin auf der vorherigen Seite darauf gestoßen, und es gab eine Übersetzung im vorherigen Erscheinungsbild, daher denke ich, dass es kein Problem gibt. Wenn Sie "numpy als np importieren" ausführen, wird eine Fehlermeldung angezeigt, es sei denn, Sie schreiben "np.random.randn (8)".
S.111 Diagramm möglicher Werte der Funktion sqrt (x ^ 2 + y ^ 2)
Anfangs hatte ich vor, es mit Pycharm auszuführen, aber es wurde immer problematischer, und ich blieb stecken, weil ich es mit IPython (Juypter Notebook) ausführte.
Ich hatte Angst, dass das Diagramm nicht angezeigt wird, selbst wenn ich es gemäß dem Buch eingegeben habe, aber es war gerecht Alles was ich tun musste war "plt.show ()".
Ich dachte jedoch, dass das Diagramm wie bei mathematica inline angezeigt wird, sodass das Verhalten unerwartet war (⇒ Wenn Sie% matplotlib inline eingeben, wird es inline angezeigt). Es ist auch ein wenig überraschend, Formeln im TeX-Format in den Titel des Diagramms einfügen zu können.
Am Ende sieht es so aus, als würde es auf dem Jupyter Notebook gut angezeigt.
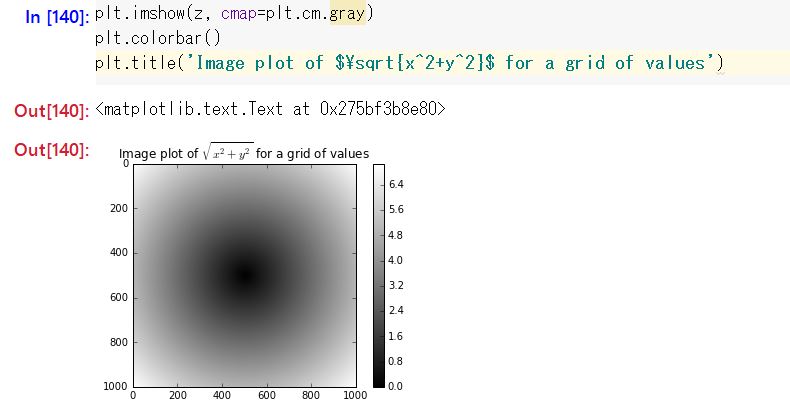
Außerdem ist das graue Diagramm nicht interessant, daher habe ich versucht, "plt.imshow (z, cmap = plt.cm.magma)" auszuführen. Wenn Sie eine nicht akzeptable Farbspezifikation eingeben, wird eine Liste akzeptabler Farbspezifikationen angezeigt, daher habe ich versucht, diese in Bezug darauf entsprechend einzugeben.
P.112 np.where Es gibt einen Ort, an dem es als np.whare falsch gedruckt wird.
S.116 Sortieren
Der Anfangswert der Achse der Sortierfunktion ist -1. Aus Offiziellen Dokumenten. Daher wird im Fall eines zweidimensionalen Arrays die Spaltenrichtung sortiert, wenn nichts angegeben ist.
P.121 mat.dot(inv(mat))
Das Ausführungsergebnis von "mat.dot (inv (mat))" stimmt nicht mit dem Buch überein.
Zuerst dachte ich, dass mat.dot (inv (mat)). Astype (np.float32) verwendet werden könnte, um den Datentyp des NumPy-Arrays zu konvertieren, aber es schien nicht so, also multiplizieren Sie es mit 1000. Auf eine ganze Zahl (Rint) gerundet und dann durch 1000 geteilt. Bitte sag mir den richtigen Weg.
np.rint(mat.dot(inv(mat)) *1000) /1000
array([[ 1., 0., 0., 0., -0.],
[ 0., 1., 0., -0., -0.],
[ 0., 0., 1., 0., 0.],
[ 0., 0., -0., 1., 0.],
[-0., -0., 0., -0., 1.]])
S.121 Produkt von Matrizen
Im Kommentar des Buches gibt es eine Beschreibung, dass die Notation nicht np.dot ist, aber jetzt scheint es @ zu sein. Ich denke, Sie können mit X.T @ X rechnen.
P.126 crossing_times = (np.abs(walks[hit30])>=30).argmax(1)
crossing_times = (np.abs (Walks [hit30])> = 30) .argmax (1), zum Beispiel Crossing_times = (np.abs (Walks [hit30])) .argmax (1) , Oder crossing_times = walk [hit30] .argmax (1) Ich habe mich gefragt, ob es nicht gut ist, aber
・ Der Absolutwert beträgt 30 oder mehr
・ Ich möchte den ersten Index von 30 oder mehr, nicht den Index mit der maximalen Entfernung.
Es ist also der Inhalt des Buches, nicht wahr?
Ich denke, der Punkt des Verständnisses ist, dass "im Fall eines Arrays von Booleschen Werten der Index, der ganz am Anfang True ist, zurückgegeben wird" auf Seite 124.
Kapitel 5
S.128 obj.index Ergebnis
Bei Büchern ist es Int64Index ([0, 1, 2, 3]), aber wenn ich es zur Hand versuche,
RangeIndex(start=0, stop=4, step=1)
Wird sein.
P.129 np.exp(obj2) Sieht das Ergebnis von index = d seltsam aus? Es geht um 54,6, richtig?
S.134 Extrahieren von Zeilen und Extrahieren von Spalten
frame2.ix ['three'] ist das Abrufen von Zeilen. Verwenden Sie beim Abrufen der Zeile ix,
Wenn Sie ix nicht verwenden, wie z. B. 'frame2 [' Schulden ']', handelt es sich um einen Spaltenabruf.
Über, woran Sie sich erinnern sollten.
P.141 ffill, bfill ffill = vorne ausfüllen bfill = fülle die Rückseite aus Es steht geschrieben, dass es sich um Füllwerte vorwärts und Füllwerte rückwärts in Englisch handelt, also mag es passiert sein, aber es scheint missverstanden zu werden.
Es scheint, dass das englische Wörterbuch als "Look Ahead (Verb)" mit Verb + Forward interpretiert werden kann, so dass es einfacher ist, sich Ausdrücke wie das Ausfüllen der Löcher mit der Vorderseite und das Ausfüllen der Löcher mit der Rückseite zu merken, wenn es gefüllt ist. Die Suche nach vorne wird auch als Suche nach vorne interpretiert, nicht wahr?
S.144, 145 Bei Verwendung von Slicing für DataFrame
Wenn Sie Slicing wie "obj ['b': 'c']" verwenden, gilt dies für die Zeile. Gleiches gilt für die Indexwertreferenz data [: 2].
Wenn Sie nur Daten ['zwei'] sagen, funktioniert dies für Spalten. Wenn es um das Schneiden geht, wirkt es auf den Index. Ich bin ein wenig verwirrt.
Andere Dinge, die ich beim Berühren des Jupyter-Notizbuchs überprüft habe.
-Data [: 3] ist gleichdata.ix [: 3].
-Wenn Sie Slicing in Spaltenrichtung verwenden möchten, verwenden Sie data.ix [:,: 3]. Dies wird als eine der Darstellungsmethoden von "obj.ix [:, val]" zum Extrahieren von Spalten angesehen, wie in Tabelle 5-6 gezeigt.
P.154 obj.order() Bestellung scheint jetzt veraltet zu sein. Eine Meldung zur Verwendung von sort_values () wurde angezeigt. Wird es in Zukunft ein Fehler sein?
P.155 frame.sort_index(by='b')
Dies scheint derzeit ebenfalls veraltet zu sein. Sicher verwirrend. Aus Python
frame.sort_values (by = 'b') wird empfohlen.
p.155 frame.sort_index(by=['a', 'b']) Sie werden auch hier aufgefordert, die Werte zu sortieren. Dies bedeutet, dass nach dem Sortieren in Spalte a dieselben Werte in Spalte b sortiert werden. Ich möchte etwas mehr Erklärung in dem Buch.
P.158 df.sum(axis=1) Das Hinzufügen von nur np.nan ist in dem Buch so geschrieben, dass es zu np.nan wird, aber soweit ich es ab dem 06.07.2016 versuche, wird es zu 0.0. Das Verhalten ist das gleiche, wenn skipna = False ist. Wird es 0 sein, wenn nichts hinzuzufügen ist? Wenn ich jedoch das neueste Handbuch von Pandas überprüfe, heißt es "NA / Null-Werte ausschließen. Wenn eine ganze Zeile / Spalte NA ist, ist das Ergebnis NA". Ist es also ein Fehler?
S.159 Ergebnis von df.describe ()
In dem Buch haben alle Artikel Nummern, aber wenn Sie es zur Hand versuchen,
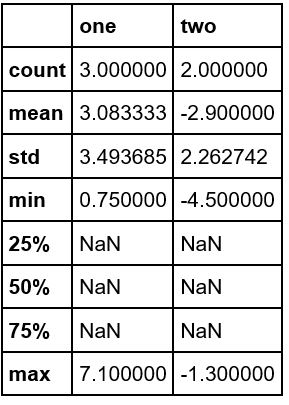 ist. Haben sich die Spezifikationen irgendwann geändert? Selbst wenn Sie sich das [Handbuch] ansehen (http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.describe.html), bin ich mir nicht sicher.
ist. Haben sich die Spezifikationen irgendwann geändert? Selbst wenn Sie sich das [Handbuch] ansehen (http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.describe.html), bin ich mir nicht sicher.
pp.160 import pandas.io.data as web Wenn Sie dies tun,
The pandas.io.data module is moved to a separate package (pandas-datareader) and will be removed from pandas in a future version.
Es wird angezeigt. Also habe ich vorerst "conda install pandas-datareader" gemacht.
Import ist
import pandas.io.data as web
Zu
import pandas_datareader.data as web
Wie es funktioniert hat. Im Handbuch habe ich geschrieben, dass "pandas_datareader als pdr importieren" und "pdr.get_data_yahoo" funktionieren würden, aber es scheint anders zu sein.
all_data.iteritems() Die Beschreibung hier scheint auf der Python2-Serie zu basieren. In Python3 wurde die Spezifikation von (dict) .items geändert, daher lautet die Beschreibung hier
price = DataFrame({tic : data['Adj Close']
for tic, data in all_data.items()})
volume = DataFrame({tic: data['Volume']
for tic, data in all_data.items()})
Es sieht gut aus. Vielleicht ist die Antwort hier http://stackoverflow.com/questions/13998492/iteritems-in-python Es scheint enthalten zu sein, aber ich verstehe Englisch nicht sehr gut.
S.162 Definition von obj
Weil es mühsam ist, nachzuahmen und einzugeben
obj=Series(list('cadaabbcc'))
Ich möchte, dass du schreibst.
P.163 pd.value_counts(obj.values) Da es den Wert zählt, frage ich mich, ob ich nur "pd.value_counts (obj)" schreiben soll. Kein Fehler.
P.167 .dropna(thresh=3) Die Idee des Schwellenwerts hat mich ein wenig verwirrt, aber das bedeutet, dass der Wert auf eine andere Zahl als NaN eingestellt ist. Wenn ich oft S.166 lese, steht es auf jeden Fall so. Im Gegenteil, ich war ein wenig verwirrt, weil ich dachte, es sei die Anzahl der NaN. Übrigens ist es besser, die Funktionsweise von df.dropna (Thresh = 3) zu verstehen, indem Sie sie auf 2 setzen.
P.167 df.fillna({1:0.5, 3:-1}) Dies ist nicht in Zeile 3, aber was machst du? 2 Fehler?
P.168 df.fillna(0,inplace=True) Es heißt "_ = df.fillna (0, replace = True)", aber ist "_ =" ein Bearbeitungsfehler? Du brauchst es nicht.
S.169 Definition von Daten
Es ist mühsam, "a", "a" einzugeben ...
data = Series(np.random.randn(10),index=[list('aaabbbccdd'),[1,2,3,1,2,3,1,2,2,3]])
Ich möchte, dass Sie eine Probe machen.
Ergebnisse von P.170 data.index
Verfügbar
MultiIndex(levels=[['a', 'b', 'c', 'd'], [1, 2, 3]],
labels=[[0, 0, 0, 1, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 1, 2, 0, 1, 1, 2]])
wurde. Ist es eine leichte Spezifikationsänderung?
P.172 MultiIndex Dies hängt vom Import ab. Wenn Sie jedoch wie in diesem Buch beschrieben importieren,
pd.MultiIndex.from_arrays([['Ohio','Ohio','Colorado'],['Green','Red','Green']],
names=['state','color'])
Wenn Sie also kein pd schreiben, ist es nutzlos. Ich frage mich, ob ich den Inhalt bei der Übersetzung nicht überprüft habe.
P.176 pdata.swapaxes('items', 'minor') Das Ergebnis kurz davor ist
<class 'pandas.core.panel.Panel'>
Dimensions: 4 (items) x 868 (major_axis) x 6 (minor_axis)
Items axis: AAPL to MSMT
Major_axis axis: 2009-01-02 00:00:00 to 2012-06-01 00:00:00
Minor_axis axis: Open to Adj Close
Also habe ich `pdata = pdata.swapaxes ('items', 'minor_axis') 'ausprobiert, aber es scheint egal zu sein, ob _axis vorhanden ist oder nicht. In beiden Fällen tritt kein Fehler auf.
Auch im vorherigen Teil ist der Import
import pandas_datareader.data as web
ist.
Kapitel 6
read_csv(), read_table() Obwohl read_csv () und read_table () separat geschrieben werden, ist es möglich, eine Datei zu lesen, indem sep = für read_csv und read_table auf dieselbe Weise angegeben wird.
P.186 tot.order() tot.sort_values () wird empfohlen.
P.186 tot.add(piece['key'].value_counts(), fill_value=0)
for piece in chunker:
tot = tot.add(piece['key'].value_counts(), fill_value=0)
Das Lesen des Handbuchs zum Hinzufügen von Serien vertieft jedoch Ihr Verständnis. http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.add.html
Wenn fill_values = 0 ist und der NA-Wert nicht verarbeitet wird, ist das Ergebnis der Addition von Serien einschließlich NA NA, und .add wird verwendet, um zu verhindern, dass das Aggregationsergebnis voll von NA ist.
P.187 sys.stdout
Vorweg,
import sys
Wenn Sie dies nicht tun, wird es nicht passieren. Ist dies nicht unter der Annahme geschrieben, dass Sie mit der Python-Sprache vertraut sind?
P.188 data.to_csv(sys.stdout, index=False, cols=['a','b','c'])
Handbuch
http://pandas.pydata.org/pandas-docs/version/0.18.1/generated/pandas.DataFrame.to_csv.html
Wie in
data.to_csv(sys.stdout, index=False, columns=['a','b','c'])
Wenn Sie es nicht einstellen, funktioniert es nicht.
Eine Sache, über die Sie sich Sorgen machen müssen, ist, dass wenn Sie "cols" sagen, dies keinen Fehler verursacht, sondern nur andere als die gewünschte Spalte aufnimmt und ausschreibt. Soll ich einen Fehler bekommen? Fehler?
Inhalt von S.188 tseries.csv
In der vorliegenden Umgebung gibt es im Gegensatz zu den Ergebnissen des Buches keine Zeitinformationen.
.csv
2000-01-01,0
2000-01-02,1
2000-01-03,2
2000-01-04,3
2000-01-05,4
2000-01-06,5
2000-01-07,6
ist geworden.
P.189 print line In Python3 ist es print (Zeile).
P.192 to_json, from_json Es gibt eine Aussage, dass versucht wird, to_json und from_json zu implementieren. Laut Handbuch scheint to_json ab dem 08. Juni 2016 implementiert zu sein. Da from_json im Handbuch nicht beschrieben ist, ist es möglicherweise noch nicht implementiert.
P.192 urlib2 Es scheint, dass die Pakete in Python3 integriert sind und nur urllib verfügbar ist. Sie können es auch nicht einfach in "von urllib import urlopen" ändern, sondern müssen es mit "von urllib.request import urlopen" tun. Dies wird auch durch den Wechsel von Python 2 zu 3 beeinflusst. Referenz: http://diveintopython3-ja.rdy.jp/porting-code-to-python-3-with-2to3.html
- Der Unterschied zwischen Python 2 und 3 hat zur Folge, dass nach Verwendung eines Programms, das die Quelle automatisch konvertiert, der Unterschied ausgewertet und als korrekte / falsche Tabelle veröffentlicht werden sollte.
S.198 Binärdaten lesen (Pickle-Daten?)
pd.load()
In den neuesten Pandas jedoch
pd.read_pickle('ch06/frame_pickle')
Es ist geworden.
Referenz: http://pandas.pydata.org/pandas-docs/stable/io.html#io-pickle
Kapitel 7
P.206 Pd.merge(df1, df2) Wenn ich es zur Hand versuche, unterscheidet sich die Reihenfolge der Ergebnisse geringfügig von der im Buch beschriebenen. In dem Buch ist die Reihenfolge so, als ob sie nach Schlüsseln sortiert wäre, aber das Ergebnis ist, dass sie nach df1 (Daten1) sortiert ist.
S.208 Kartesisches Produkt
Es ist wie ein direktes Produktset. Ich habe es zum ersten Mal gehört.
Referenz: https://ja.wikipedia.org/wiki/%E7%9B%B4%E7%A9%8D%E9%9B%86%E5%90%88
Recommended Posts