[PYTHON] Eine Einführung in OpenCV für maschinelles Lernen
Um maschinelles Lernen durchzuführen, möchten Sie häufig nur ein bestimmtes Objekt (einen bestimmten Bereich) aus einem Bild ausschneiden und erkennen oder Trainingsdaten erstellen. In diesem Artikel möchte ich die Verwendung von OpenCV vorstellen, das so viele Funktionen hat, wobei ich mich auf die Funktionen konzentriere, die für ein solches maschinelles Lernen verwendet werden. Insbesondere werden wir uns auf die folgenden Module konzentrieren.

Das grundlegende Schneidverfahren ist wie folgt. Im Folgenden werde ich nach diesem Verfahren erklären.
- Vorverarbeitung: Vorverarbeitung des Bildes, um das Erkennen von Objekten zu erleichtern
- Objekterkennung: Erkennt ein Objekt und schneidet es aus dem Bild aus.
- Konturerkennung: Erkennt ein Objekt, indem es den Bereich (die Kontur) auf dem Bild erkennt
- Objekterkennung: Verwendet das trainierte OpenCV-Modell, um das Zielobjekt zu erkennen und zu erkennen.
- Vorbereitung für maschinelles Lernen: Verwenden Sie das abgeschnittene Bild, um sich auf Vorhersage und Lernen vorzubereiten.
Darüber hinaus wird miniconda zum Erstellen der OpenCV-Umgebung verwendet. Installieren Sie dies und geben Sie den folgenden Befehl ein, um die Umgebungskonstruktion abzuschließen.
- conda create -n cv_env numpy jupyter matplotlib
- conda install -c https://conda.anaconda.org/menpo opencv3
- activate cv_env
(* Der Name der virtuellen Umgebung muss nicht "cv_env" sein. Wenn es sich um Mac / Linux handelt, wird die Aktivierung abgebrochen, sodass Unterstützung erforderlich ist. Weitere Informationen finden Sie hier.](Http://qiita.com/icoxfog417/items) / 950b8af9100b64c0d8f9))
Der diesmal eingeführte Code wird im folgenden Repository veröffentlicht. Ich hoffe, Sie können sich bei Bedarf darauf beziehen.
Vorverarbeitung
Bei der Erkennung eines Objekts ist es zweckmäßig, einen "klaren Umriss" und einen "kontinuierlichen" zu haben.

Effektive Methoden hierfür sind "Schwellenwertverarbeitung" und "Filterung (Unschärfe)". Dieser Abschnitt konzentriert sich auf diese beiden. Da die Bildverarbeitung normalerweise im Voraus grau skaliert wird, wird dies auch erwähnt.
Graustufen
Da Farbinformationen bei der Bildverarbeitung selten benötigt werden, ist es sehr üblich, Graustufen im Voraus zu erstellen. Beachten Sie jedoch, dass RGB-Informationen häufig für die endgültige Verwendung beim maschinellen Lernen erforderlich sind. Wenn Sie also aus einem Bild zuschneiden, muss zuerst die Farbe verwendet werden.
Graustufen-Farbbilder mit OpenCV sind sehr einfach. Geben Sie einfach "cv2.COLOR_BGR2GRAY" in "cv2.cvtColor" an.
import cv2
def to_grayscale(path):
img = cv2.imread(path)
grayed = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
return grayed
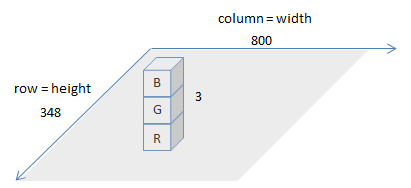
Wie der Name von "cv2.COLOR_BGR2GRAY" andeutet, werden die Farbinformationen des von "cv2.imread" geladenen Bildes in der Reihenfolge "BGR" (blau, grün, rot) geladen. Die Variable, die das Bild liest, ist eine Matrix (von numpy), aber wenn Sie ihre Größe überprüfen, ist es wie folgt.
img = cv2.imread(IMAGE_PATH)
img.shape
>>> (348, 800, 3)
Dies bedeutet, dass das geladene Bild durch eine 348x800x3-Matrix dargestellt wird. Das Bild sieht aus wie in der Abbildung unten.
Darüber hinaus erwartet matplotlib, das häufig zum Anzeigen von Bildern verwendet wird, dass Bilder in "RGB" eingehen. Wenn Sie das von OpenCV gelesene Bild so wie es ist in matplotlib einfügen, sieht es wie folgt aus (das Originalbild befindet sich links und das von OpenCV gelesene Bild wird von matplotlib so angezeigt, wie es ist).

Daher ist es bei der Anzeige mit matplotlib erforderlich, die Reihenfolge der Farben wie folgt zu ändern.
def to_matplotlib_format(img):
return cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
Schwellenwertverarbeitung
Die Schwellenwertverarbeitung ist eine Bildverarbeitung, die darauf basiert, ob ein bestimmter Schwellenwert überschritten wird oder nicht. Beispielsweise werden alle Stellen, an denen die Helligkeit einen bestimmten Wert nicht erreicht, auf 0 gesetzt. Auf diese Weise können Sie den Hintergrund löschen, den Umriss hervorheben und wie in der folgenden Abbildung gezeigt verarbeiten (die linke Seite ist das Originalbild, die rechte Seite ist die mit Schwellenwertverarbeitung).

Die Schwellenwertverarbeitung in OpenCV wird von [cv2.threshold] ausgeführt (http://docs.opencv.org/3.0-beta/modules/imgproc/doc/miscellaneous_transformations.html?highlight=cv2.threshold#cv2.threshold). können. Die Hauptparameter hier sind "Thresh", der der Schwellenwert ist, "Maxval", der die Obergrenze des Werts darstellt, und "Type", der die Art der Schwellenwertverarbeitung ist.
Die folgende Tabelle fasst die Arten von "Typ" für die Schwellenwertbehandlung zusammen und wie der Schwellenwert (Schwellenwert) / die Obergrenze (maxValue) zu diesem Zeitpunkt verwendet wird.
| Threshold Type | over thresh :arrow_up_small: | under thresh :arrow_down_small: |
|---|---|---|
THRESH_BINARY |
maxValue | 0 |
THRESH_BINARY_INV |
0 | maxValue |
THRESH_TRUNC |
threshold | (as is) |
THRESH_TOZERO |
(as is) | 0 |
THRESH_TOZERO_INV |
0 | (as is) |
"(wie es ist)" bedeutet, dass der Wert des Originalbildes unverändert verwendet wird. Wenn Sie mehr über die Schwellenwertverarbeitung erfahren möchten, sind die folgenden Materialien hilfreich.
OpenCV Threshold ( Python , C++ )
In dem diesmal verwendeten Vogelbild wird zusätzlich zum Entfernen des blauen Hintergrunds die Grenze (hell) der Flügel des Vogels deutlich gemacht.
- Löschen Sie den Hintergrund-> THRESH_BINARY
- Bereich größer als der Schwellenwert (= hell = hell = Hintergrund): maxValue (255 = weiß = löschen)
- Unterhalb der Schwelle: 0 (schwarz = hervorgehoben)
- Klärung der Grenzen-> THRESH_BINARY_INV
- Bereiche größer als der Schwellenwert (= hell = Vogelknochen = Grenze): 0 (schwarz = hervorgehoben)
- Unterhalb des Schwellenwerts: maxValue (255 = weiß = löschen)
Und schließlich werden diese beiden Verarbeitungsergebnisse zusammengeführt.
def binary_threshold(path):
img = cv2.imread(path)
grayed = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
under_thresh = 105
upper_thresh = 145
maxValue = 255
th, drop_back = cv2.threshold(grayed, under_thresh, maxValue, cv2.THRESH_BINARY)
th, clarify_born = cv2.threshold(grayed, upper_thresh, maxValue, cv2.THRESH_BINARY_INV)
merged = np.minimum(drop_back, clarify_born)
return merged
Wenn Sie sich nicht sicher sind, wie hoch der Wert von "dresch" sein soll, können Sie die Helligkeit mit einem Malwerkzeug überprüfen. Unter Windows können Sie dies mit der Standard-Malwerkzeug-Pipette überprüfen.

Wenn Sie "adaptiveThreshold" verwenden, wird beim Betrachten der umgebenden Pixel ein geeigneter Schwellenwert festgelegt. Versuchen Sie dies daher möglicherweise einmal. Weitere Informationen finden Sie im folgenden Dokument.
Schwellenwertverarbeitung nach Farbe
Bestimmte Farben mit cv2.inRange Es ist auch möglich, den Teil von zu extrahieren. Im Folgenden wird der blaue Teil des Hintergrunds erkannt und maskiert.

def mask_blue(path):
img = cv2.imread(path)
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
blue_min = np.array([100, 170, 200], np.uint8)
blue_max = np.array([120, 180, 255], np.uint8)
blue_region = cv2.inRange(hsv, blue_min, blue_max)
white = np.full(img.shape, 255, dtype=img.dtype)
background = cv2.bitwise_and(white, white, mask=blue_region) # detected blue area becomes white
inv_mask = cv2.bitwise_not(blue_region) # make mask for not-blue area
extracted = cv2.bitwise_and(img, img, mask=inv_mask)
masked = cv2.add(extracted, background)
return masked
Die von "cv2.inRange" erhaltene "blue_region" ist die angegebene Farbregion. Beachten Sie, dass blue_region in Graustufen dargestellt wird, mit höheren Werten (255 = näher an Weiß), wo es gefunden wird. Wenn Sie "cv2.inRange" verwenden, müssen Sie außerdem das Bild in die HSV-Darstellung ändern und den Farbbereich entsprechend angeben. Was ist der HSV-Ausdruck? Es ist leicht zu verstehen, wenn man sich die folgende Abbildung ansieht.

Der von OpenCV angegebene HSV-Wert ist jedoch etwas eigenartig, so dass es ziemlich schwierig ist, den Wert vom Malwerkzeug wie oben beschrieben abzuschätzen.
| Allgemeiner Wertebereich | OpenCV | |
|---|---|---|
| H | 0 - 360 | 0 - 180 |
| S | 0 - 100 | 0 - 255 |
| V | 0 - 100 | 0 - 255 |
Daher ist es schneller, die Werte in der Matrix tatsächlich zu betrachten, wenn die Spezifikation nicht sehr gut zu funktionieren scheint. Sie können den Matrixwert (Farbwert) des angegebenen Bereichs mit dem Gefühl von "img [10:20, 10:20]" ausschneiden. Wenn Sie ihn also überprüfen, können Sie ihn genau angeben (diesmal ist der Farbwert tatsächlich Es hat überhaupt nicht geholfen, also habe ich es so spezifiziert.
Danach wird das Bild durch Hinzufügen von "Hintergrund" erstellt, wodurch alle Bereiche von "blue_region" weiß werden, und "extrahiert", wodurch die anderen Bereiche als "blue_region" extrahiert werden. bitwise_and / bitwise_not ist eine nützliche Funktion für diese Art der Maskierung.
Das Obige ist die Erklärung der Schwellenwertverarbeitung.
Glätten
Wenn der Umriss des Bildes nicht klar oder der Hintergrund dunkel ist, wird der Umriss möglicherweise nicht entfernt oder der Hintergrund bleibt auch dann erhalten, wenn die Schwellenwertverarbeitung angewendet wird. Im folgenden Beispiel bleibt der Kies zu Ihren Füßen in Ordnung und der Umriss ist gezackt.
 Piping plover chick with band at two weeks
Piping plover chick with band at two weeks
In solchen Fällen ist es eine gute Idee, einen Filter zum Glätten zu verwenden. Einfach ausgedrückt ist der Filterprozess ein Prozess, der das Bild verwischt. Durch Verwischen des Bildes können jedoch nur "Punkte erkannt werden, die auch bei Unschärfe deutlich sichtbar sind" und Punkte ignorieren, die bei Unschärfe verschwinden. Ich kann es schaffen Das Folgende ist ein Beispiel für das Anwenden des Gaußschen Filters unter Verwendung von "Gaußscher Unschärfe" (linke Abbildung) und anschließende Schwellenwertverarbeitung (rechte Abbildung).
def blur(img):
filtered = cv2.GaussianBlur(img, (11, 11), 0)
return filtered

Die feinen Details des Bildes sind verloren gegangen, aber Sie können sehen, dass die charakteristischen Teile zusammen bleiben und das Rauschen, das oft im Hintergrund war, verschwunden ist. Weitere Filter außer "Gaußscher Weichzeichner" finden Sie im folgenden offiziellen OpenCV-Dokument.
Eine andere Technik zum Glätten von Bildern ist die Morphologie. Dies ist eine Methode zum Entfernen von Rauschen und Hervorheben von Konturen mithilfe der Bildausdehnungs- / Kontraktionsverarbeitung. Das Folgende ist ein Bild einer typischen Methode in der Morphologie.

- Wählen: Erweitert den Grenzbereich
- Erosion: Erodiert den Grenzbereich
- Öffnung: Ähnlich wie Erosion, Erosion der Grenze, jedoch langsamer als Erosion.
- Schließen: Ähnlich wie beim Wählen, Erweitern von Grenzen und Verkleinern des Hintergrunds, jedoch langsamer als beim Wählen
Die theoretischen Details werden hier weggelassen, aber Sie können sich das als eine Art Filter vorstellen. OpenCV verfügt über "cv2.dilate" und "cv2.erode", die die obige Morphologieverarbeitung ausführen können, und über "cv2.morphologyEx", mit dem das Öffnen / Schließen kontinuierlich angewendet werden kann. Dieses Mal werde ich versuchen, mit cv2.morphologyEx zu glätten.
def morph(img):
kernel = np.ones((3, 3),np.uint8)
opened = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel, iterations=2)
return opened

Dieses Mal war es wahrscheinlich, weil die Hintergrundfarbe dunkel ist, schwierig, den Bereich mit CLOSE zu verdicken. Deshalb habe ich versucht, ihn so zu verarbeiten, dass der Abstand zwischen den Bereichen durch OPEN so groß wie möglich ist. Da jedoch weiterhin Rauschen auftritt, wird es in Kombination mit dem Filter verarbeitet.
def morph_and_blur(img):
kernel = np.ones((3, 3),np.uint8)
m = cv2.GaussianBlur(img, (3, 3), 0)
m = cv2.morphologyEx(m, cv2.MORPH_OPEN, kernel, iterations=2)
m = cv2.GaussianBlur(m, (5, 5), 0)
return m

Es ist eher so, als ob Informationen bleiben als nur gefiltert werden. Außerdem können Sie durch Anwenden von Öffnen sehen, dass die zuvor verbundenen Bereiche jetzt fest unabhängig sind. Im Folgenden wird die Morphologieverarbeitung detailliert beschrieben. Bitte beziehen Sie sich darauf.
- Simple and effective coin segmentation using Python and OpenCV
- Image Segmentation with Watershed Algorithm
In der Tat ist es ziemlich schwierig, den Bereich von dort aus zu klären, wenn der Hintergrund dunkel ist und die Graustufen verwendet werden. Wenn der Hintergrund eine Farbe hat, die Sie erkennen können, ist es daher besser, ihn mit einer Farbe zu maskieren und dann zu verarbeiten.
Das Obige ist die Erklärung der Vorverarbeitung. Von hier aus möchte ich das Objekt nach der Vorverarbeitung endlich aus dem Bild erkennen.
Objekterkennung
Konturerkennung
Bis zu diesem Punkt denke ich, dass das zu erkennende Objekt durch Vorverarbeitung geklärt wurde, daher werden wir es verwenden, um die Kontur zu erkennen.

In OpenCV können Konturen mithilfe von "cv2.findContours" leicht erkannt werden.
def detect_contour(path, min_size):
contoured = cv2.imread(path)
forcrop = cv2.imread(path)
# make binary image
birds = binary_threshold_for_birds(path)
birds = cv2.bitwise_not(birds)
# detect contour
im2, contours, hierarchy = cv2.findContours(birds, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
crops = []
# draw contour
for c in contours:
if cv2.contourArea(c) < min_size:
continue
# rectangle area
x, y, w, h = cv2.boundingRect(c)
x, y, w, h = padding_position(x, y, w, h, 5)
# crop the image
cropped = forcrop[y:(y + h), x:(x + w)]
cropped = resize_image(cropped, (210, 210))
crops.append(cropped)
# draw contour
cv2.drawContours(contoured, c, -1, (0, 0, 255), 3) # contour
cv2.rectangle(contoured, (x, y), (x + w, y + h), (0, 255, 0), 3) #rectangle contour
return contoured, crops
def padding_position(x, y, w, h, p):
return x - p, y - p, w + p * 2, h + p * 2
binary_threshold_for_birds ist eine Funktion zur Schwellenwertverarbeitung des diesmal verwendeten Vogelbildes (= Vorverarbeitung). Die Ausgabe ist das zuvor eingeführte weiße Hintergrundbild. Invertieren Sie es also und verwenden Sie es zur Flächenerkennung. Es ist schwer zu verstehen, aber im Fall von Schwarzweiß hat "Weiß" einen höheren Wert (255). Wenn Sie also eine Konturerkennung durchführen, müssen Sie ein Bild mit der in Weiß gezeichneten Kontur als Eingabe erstellen.
- Bitte beachten Sie, dass Konturen nur erkannt werden, wenn das Bild in Schwarzweiß ziemlich klar ist.
Jetzt müssen Sie nur noch "cv2.findContours" ausführen. Die dadurch erkannten Konturen können mit cv2.drawContours einfach auf das Bild gezeichnet werden. Sie können auch die Koordinaten eines Rechtecks ermitteln, das zur Kontur passt, indem Sie "cv2.boundingRect" verwenden. Dies ist jedoch ein enger Kampf, daher verwende ich dieses Mal "padding_position", um der Umgebung etwas Raum zu geben.
Informationen zu "cv2.findContours" finden Sie auch im offiziellen Dokument.
Wenn der Benutzer nicht automatisch arbeitet, ist es außerdem möglich, das Objekt im geschlossenen Bereich mithilfe einer als Diagrammschnitt bezeichneten Technik zu erkennen. Ich werde nicht auf Details eingehen, aber ich denke, es ist nützlich, wenn Sie Tools für Anmerkungen erstellen. Wenn Sie also interessiert sind, lesen Sie bitte die folgenden Informationen.
Interactive Foreground Extraction using GrabCut Algorithm
Konturnäherung
OpenCV bietet verschiedene Funktionen, die sich der erkannten Kontur annähern. Zum Beispiel approximiert "approxPolyDP" linear die erkannte Kontur, und wenn die Kontur gerade ist, wird empfohlen, diese zum Ausschneiden zu verwenden. Unten ist die Kontur durch die rot gepunktete Linie erkannt, und die grüne Linie ist eine lineare Annäherung.

def various_contours(path):
color = cv2.imread(path)
grayed = cv2.cvtColor(color, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(grayed, 218, 255, cv2.THRESH_BINARY)
inv = cv2.bitwise_not(binary)
_, contours, _ = cv2.findContours(inv, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
if cv2.contourArea(c) < 90:
continue
epsilon = 0.01 * cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, epsilon, True)
cv2.drawContours(color, c, -1, (0, 0, 255), 3)
cv2.drawContours(color, [approx], -1, (0, 255, 0), 3)
plt.imshow(cv2.cvtColor(color, cv2.COLOR_BGR2RGB))
various_contours(IMG_FOR_CONTOUR)
cv2.arcLength ist die Länge der Kontur, mit der die minimale Länge der geraden Linie epsilon berechnet wird. Jetzt können Sie einstellen, wie fein die geraden Linien sind.
Weitere Funktionen und deren Erläuterungen finden Sie im folgenden Tutorial.
Erkennungsbereich ausschneiden
Nachdem wir den Bereich kennen, müssen wir ihn auf die vom Modell erwartete Größe zuschneiden, um ihn auf ein Modell für maschinelles Lernen anzuwenden. Zu diesem Zweck habe ich dieses Mal eine Funktion namens "resize_image" erstellt.
def resize_image(img, size):
# size is enough to img
img_size = img.shape[:2]
if img_size[0] > size[1] or img_size[1] > size[0]:
raise Exception("img is larger than size")
# centering
row = (size[1] - img_size[0]) // 2
col = (size[0] - img_size[1]) // 2
resized = np.zeros(list(size) + [img.shape[2]], dtype=np.uint8)
resized[row:(row + img.shape[0]), col:(col + img.shape[1])] = img
# filling
mask = np.full(size, 255, dtype=np.uint8)
mask[row:(row + img.shape[0]), col:(col + img.shape[1])] = 0
filled = cv2.inpaint(resized, mask, 3, cv2.INPAINT_TELEA)
return filled
Diese Funktion wird durch die folgenden Schritte gebildet.
- Größe ändern: Bereiten Sie eine Leinwand ("Größe geändert") der angegebenen Größe vor (Größe des Bildes der Trainingsdaten oder etwas größer, damit es später ausgeschnitten wird)
- Zentrierung: Stellen Sie das ausgeschnittene Bild in die Mitte der vorbereiteten Leinwand
- Füllen: Füllt den Bereich um das eingestellte Bild mit den Informationen des Originalbilds.
OpenCV hat auch eine Funktion zum Ändern der Größe. Wenn Sie diese verwenden, wird das abgeschnittene Bild zwangsweise auf die angegebene Größe angepasst und das Bild wird verzerrt. Daher bereiten wir diesmal eine Leinwand mit einer Größe vor, die zum ausgeschnittenen Bild passt, platzieren das ausgeschnittene Bild in der Mitte und füllen die Umgebung. Das zum Ausfüllen der Lücken verwendete cv2.inpaint ist ursprünglich eine Funktion zum Wiederherstellen von Bildfehlern. Dieses Mal benutze ich es jedoch, um die Umgebung zu füllen.
Das tatsächlich ausgeschnittene Bild ist wie folgt. Ich denke, dass es fast genau ergänzt wird, aber die Farbe der Biene auf dem zweiten Stück hat sich leicht erweitert. In diesen Fällen müssen Sie die Polsterung so anpassen, dass sie nur mit der Hintergrundfarbe gefüllt ist.

Bildausrichtung
Die Position auf dem Bild, an der sich das Objekt bewegt hat, ist ein wichtiger Erkennungspunkt. Das kürzlich verwendete CNN macht die Arbeit auch dann gut, wenn es aufgrund von Falten leicht falsch ausgerichtet ist. Wenn Sie es jedoch korrigieren, erhöht sich die Genauigkeit dramatisch. Daher erklären wir hier die Positionskorrektur des Bildes nach dem Ausschneiden.
Die folgende Abbildung zeigt ein Beispiel für die Ausrichtung der Bilder. Die erste Zeile ist das Basisbild, und die zweite und die nachfolgenden Zeilen werden korrigiert, um mit dem Bild der ersten Zeile übereinzustimmen (die linke Seite befindet sich vor der Korrektur, die rechte Seite befindet sich nach der Korrektur).
 Bildquelle: Bild 1, [Bild 2](http://www.publicdomainpictures.net/view- image.php? image = 51893 & picture = & jazyk = JP), image 3
Bildquelle: Bild 1, [Bild 2](http://www.publicdomainpictures.net/view- image.php? image = 51893 & picture = & jazyk = JP), image 3
Nach der Korrektur denke ich, dass die Positionen der Vögel fast gleich sind. Dies wird mithilfe von findTransformECC unter Bezugnahme auf die folgende Site korrigiert.
Image Alignment (ECC) in OpenCV ( C++ / Python )
def align(base_img, target_img, warp_mode=cv2.MOTION_TRANSLATION, number_of_iterations=5000, termination_eps=1e-10):
base_gray = cv2.cvtColor(base_img, cv2.COLOR_BGR2GRAY)
target_gray = cv2.cvtColor(target_img, cv2.COLOR_BGR2GRAY)
# prepare transformation matrix
if warp_mode == cv2.MOTION_HOMOGRAPHY:
warp_matrix = np.eye(3, 3, dtype=np.float32)
else :
warp_matrix = np.eye(2, 3, dtype=np.float32)
criteria = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, number_of_iterations, termination_eps)
sz = base_img.shape
# estimate transformation
try:
(cc, warp_matrix) = cv2.findTransformECC(base_gray, target_gray, warp_matrix, warp_mode, criteria)
# execute transform
if warp_mode == cv2.MOTION_HOMOGRAPHY :
# Use warpPerspective for Homography
aligned = cv2.warpPerspective(target_img, warp_matrix, (sz[1], sz[0]), flags=cv2.INTER_LINEAR + cv2.WARP_INVERSE_MAP)
else :
# Use warpAffine for Translation, Euclidean and Affine
aligned = cv2.warpAffine(target_img, warp_matrix, (sz[1],sz[0]), flags=cv2.INTER_LINEAR + cv2.WARP_INVERSE_MAP)
return aligned
except Exception as ex:
print("can not align the image")
return target_img
Kurz gesagt, findTransformECC ist eine Funktion, die in zwei Bildern nach ähnlichen Punkten sucht und das Schätzergebnis darüber liefert, welche Art von Bewegung in warp_matrix ausgeführt wurde. Ursprünglich diente es der Analyse, welche Art von Bewegung in einem fortlaufenden Bild wie einem Film auftrat, sodass die Positionen möglicherweise nicht ausgerichtet werden, es sei denn, die Bilder sind ganz gleich. Das Obige scheint auch beiläufig ausgerichtet zu sein, aber es war schwierig, ein Foto auszuwählen, das korreliert werden könnte (die Ausnahme ist, dass es nicht konvergiert, wenn es keine Korrelation gibt). .. ..
Wenn Merkmalspunkte (Augen, Nase, Mund usw.) vorhanden sind, die allen Bildern wie dem Gesicht gemeinsam sind, kann die Konvertierung basierend auf der Position jedes Merkmalspunkts angewendet werden. Hierfür kann EstimationRigidTransform verwendet werden.
def face_align(base, base_position, target, target_position):
sz = base.shape
fsize = min(len(base_position), len(target_position)) # adjust feature size
tform = cv2.estimateRigidTransform(target_position[:fsize], base_position[:fsize], False)
aligned = cv2.warpAffine(target, tform, (sz[1], sz[0]))
return aligned
Abhängig vom Foto gibt es Fälle, in denen die Augen nicht erkannt werden können. Daher wird oben die Konvertierung gemäß der mit dem geringeren Erkennungsmerkmal durchgeführt. Beachten Sie jedoch in diesem Fall, dass die Reihenfolge, in der das Merkmal eingefügt wird, ausgerichtet werden muss. ).

Nach der Konvertierung können Sie sehen, dass die Positionen der Gesichter gut ausgerichtet sind. Im Folgenden finden Sie eine ausführliche Einführung zur Gesichtsausrichtung. Weitere Informationen finden Sie hier.
Average Face : OpenCV ( C++ / Python ) Tutorial
Objekterkennung
Oben wurde die Konturerkennung selbst durchgeführt, OpenCV verfügt jedoch über ein geschultes Modell für Objekte, die häufig Objekte wie Gesichter und Körper erkennen, und die Objekterkennung kann mithilfe dieses Modells durchgeführt werden. Diese trainierte Modelldatei heißt Cascade Classifier, und Sie können auch Ihre eigene erstellen. Es gibt einige, die für die Öffentlichkeit zugänglich sind. Wenn Sie also interessiert sind, beziehen Sie sich bitte auf sie, wie sie unten zusammengefasst sind.
Der Cascade Classifier befindet sich bei der Installation mit pip in (Ordner für virtuelle Umgebungen) \ Library \ etc \ haarcascades (für Windows / Miniconda. Ich denke, das hängt von der Umgebung ab). Vielleicht möchten Sie experimentieren, um festzustellen, ob es etwas gibt, das Ihrem Zweck entspricht. Dieses Mal möchte ich dem offiziellen Tutorial unten folgen, um Gesichter zu erkennen.
Face Detection using Haar Cascades
Das Ergebnis der tatsächlichen Erkennung ist wie folgt. Die Erkennung des rechten Auges ist wahrscheinlich fehlgeschlagen, weil es von den Haaren verdeckt wird. .. ..

.JPG){kind=link}
{kind=link}
Der Code entspricht fast dem Tutorial. Bitte beachten Sie, dass der Speicherort der Kaskadendatei von der oben beschriebenen Umgebung abhängt (wenn der Pfad nicht ordnungsgemäß übergeben wird, wird ein Fehler wie "Fehler: (-215)! Leer () in Funktion" angezeigt).
def face_detection(path):
face_cascade = cv2.CascadeClassifier(CASCADE_DIR + "/haarcascade_frontalface_default.xml")
eye_cascade = cv2.CascadeClassifier(CASCADE_DIR + "/haarcascade_eye.xml")
img = cv2.imread(path)
grayed = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(grayed, 1.3, 5)
for (x, y, w, h) in faces:
img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
roi_gray = grayed[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex, ey, ew, eh) in eyes:
cv2.rectangle(roi_color, (ex,ey), (ex + ew, ey + eh), (0, 255, 0), 2)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
face_detection(IMG_FACE)
Der grundlegende Ablauf besteht darin, die Datei mit "cv2.CascadeClassifier" zu lesen, "Classifier" zu erstellen und mit "detectMultiScale" zu erkennen. Dieses Mal ist es nur grau skaliert, aber ich denke, dass es durch Ausführen der oben genannten Schwellenwertverarbeitung besser erkannt werden kann. Informationen zum Ausschneiden des erkannten Teils finden Sie im vorherigen Abschnitt unter "Ausschneiden des Erkennungsbereichs".
Wenn das Gesicht geneigt ist, wird es nicht richtig erkannt. Es gibt zwei Möglichkeiten, dies zu tun: den Ansatz, zuerst die Augen / den Mund zu erkennen, um die Neigung zu bestimmen, oder das Bild einfach allmählich zu drehen, um zu versuchen, es zu erkennen. Der Nachteil ist, dass ersteres weniger rechenintensiv, aber umständlich ist, und letzteres einfacher, aber rechenintensiver ist. Im Folgenden wird die Methode zum Erkennen beim Drehen des Bilds ausführlich beschrieben.
Vorbereitung auf das Lernen
Zu diesem Zeitpunkt konnten Sie ein Bild des Zielobjekts aus dem Bild ausschneiden. Jetzt müssen Sie nur noch die gesammelten Bilder in ein Modell für maschinelles Lernen einfügen. Bei der Eingabe von Bildern in das Trainingsmodell sind jedoch verschiedene Vorverarbeitungen erforderlich. Dieser Punkt ist unten zusammengefasst.
[Implementieren von Faltungs-Neuronalen Netzen / Vorverarbeitungsdaten](http://qiita.com/icoxfog417/items/5aa1b3f87bb294f84bac#%E3%83%87%E3%83%BC%E3%82%BF%E3%81] % AE% E5% 89% 8D% E5% 87% A6% E7% 90% 86)
Um die Punkte zu extrahieren, ist die folgende Verarbeitung erforderlich.
- Matrixtransformation: In das vom Trainingsmodell angenommene Matrixformat konvertieren (normalerweise K (Tiefe = Farbe) x H (Höhe) x B (Breite))
- Tiefenanpassung: In den vom Trainingsmodell angenommenen Farbkanal konvertieren (Graustufen oder RGB)
- Normalisierung von Bilddaten: Erstellen Sie ein Durchschnittsbild, indem Sie alle Bilder mitteln und das Bild normalisieren.
- Skalierung: Konvertiert die Preisspanne von 0 bis 255 bis 0 bis 1.
Das ist alles für die Erklärung. Bitte benutze OpenCV gut und lass uns verschiedene Dinge lernen.
Verweise
- Was ist OpenCV? Neueste 3.0-Funktionsübersicht und Modulkonfiguration
- Einführung in die Bildverarbeitung: Bildverarbeitung ab OpenCV und Python
- Learn OpenCV
Recommended Posts