[PYTHON] Datensatz für maschinelles Lernen
What Dies ist ein Artikel, der den Datensatz für die Implementierung des Perceptron-Modells visualisiert, das ein rudimentäres Modell des maschinellen Lernens ist.
Content
Datensatzvisualisierung mit Numpy Pandas Matplot
Was ist das Perceptron-Modell? Wird hier nicht erwähnt. Es ist ein berühmtes Modell. Wenn Sie also nachschlagen, werden Sie viel finden. Dies ist das erste Modell, das ich codiert habe, seit ich angefangen habe, maschinelles Lernen zu studieren.
Ist der diesmal verwendete Datensatz eine Institution namens ** UCI Machine Learning Repository **? Oder oder eine Art Open-Source-Blumendatensatz Iris wird als Beispiel verwendet.
Überprüfen Sie zunächst den Datensatz. Holen Sie sich den Datensatz online und zeigen Sie seinen Inhalt mit dem OS-Modul und der Pandas-Bibliothek an.
import os
import pandas as pd
s = os.path.join('https://archive.ics.uci.edu', 'ml', 'machine-learning-databases', 'iris', 'iris.data')
df = pd.read_csv(s, header=None, encoding='utf-8')
print(df)
Das Ergebnis der Ausführung des obigen Codes ist
0 1 2 3 4
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 Iris-virginica
146 6.3 2.5 5.0 1.9 Iris-virginica
147 6.5 3.0 5.2 2.0 Iris-virginica
148 6.2 3.4 5.4 2.3 Iris-virginica
149 5.9 3.0 5.1 1.8 Iris-virginica
[150 rows x 5 columns]
Und so speichert die Spalte die folgenden Informationen. Es ist ein Datensatz von 150 Blumen. Übrigens gibt es in diesem Datensatz zwei Arten von Blumen, "Iris-setona" und "Iris-virginica".
0 Spalte: Sepal length, #Die Länge des Schwertes
1 Reihe: Separl width, #Breite des Schwertes
2 Reihen: Petak length, #Blütenblattlänge
3 Reihen: Petal width, #Blütenblattbreite
4 Reihen: Class laber #Blumenname
Schauen wir uns als nächstes den Inhalt mit einem zweidimensionalen Diagramm an, das sich auf die Länge des Schwertes und die Länge des Schwertes konzentriert. Übrigens werde ich die Handlung für jeden Blumentyp aufteilen. Zeichnen Sie das Diagramm mit der Matplot-Bibliothek. Importieren Sie zunächst die Bibliothek. Verwenden Sie Numpy zur Datenmanipulation
import matplotlib.pyplot as plt
import Numpy as np
Dann erhalten Sie die 0. Spalte: die Länge des Schwertes und die 2. Spalte: die Länge der Blütenblätter. Verwenden Sie "iloc", um die Werte der 0. und 2. Spalte der 0-100. Zeile abzurufen. Eine eindimensionale Liste mit zwei Elementen von [Werten in Spalte 0, Werten in Spalte 2] wird zurückgegeben. Interessenten werden von print (X) empfohlen.
X = df.iloc[0:100, [0, 2]].values #1 rechts,Nur die dritte Reihe wird herausgenommen
Dieses Mal schauen wir uns den Inhalt des Datensatzes im Voraus an, und die ersten 50 sind die Daten von Iris-setona. Zeichnen Sie Setosa-Daten mit roten Kreisen und versicolor mit blauem x. Um den Wert auf der rechten Seite der beiden Elemente auf der x-Achse und den Wert auf der linken Seite auf der y-Achse zu übernehmen, schreiben Sie wie folgt.
#Streudiagrammplot der roten Kreisanzeige von Setosa
plt.scatter(X[:50,0], X[:50, 1], color='red', marker='o', label='setosa')
#versicolor plot blue x display
plt.scatter(X[50:100, 0], X[50:100, 1], color='blue', marker='x', label='versicolor')
#Einstellungen für die Achsenbeschriftung
plt.xlabel('sepal length [cm]') #Die Länge des Schwertes
plt.ylabel('petal length [cm]') #Hanabira Länge
#Legendeneinstellungen(Oben links platziert)
plt.legend(loc='upper left')
plt.show()
Das Ausführungsergebnis ist unten
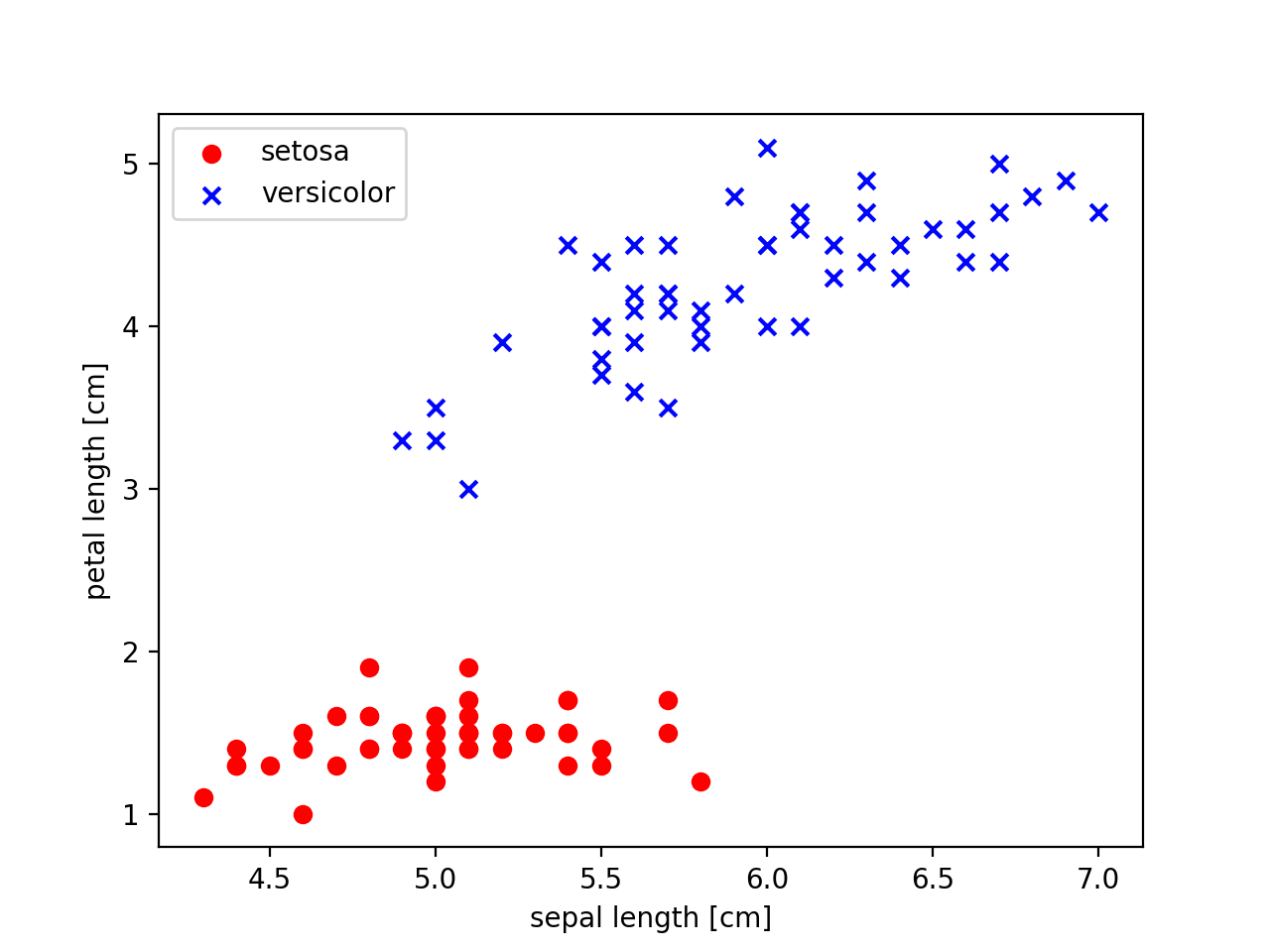 Wenn man sich die Ergebnisse ansieht, scheint es ein Gesetz zu geben. .. ..
Wenn man sich die Ergebnisse ansieht, scheint es ein Gesetz zu geben. .. ..
Wir werden dies verwenden, um einen Algorithmus für maschinelles Lernen zu erstellen, aber der Ablauf ist ungefähr wie folgt (da es nicht möglich ist, das gesamte Nachschlagewerk zu kopieren ...)
Schritt .1 Definieren Sie die Lernrate w_1 für die Länge der Klaue und die Lernrate w_2 für die Länge der Blume (verwenden Sie Zufallszahlen). Schritt .2 Nehmen Sie das innere Produkt mit dem Datensatz und speichern Sie jedes Berechnungsergebnis des inneren Produkts in einem Array oder etwas anderem. Schritt .3 Klassifizieren Sie in Setosa oder Versicolor mit einem bestimmten Wert (z. B. 0) als Grenze des Ergebnisses der Berechnung des inneren Produkts. Schritt .4 Überprüfen Sie, ob die tatsächlichen Daten mit dem Klassifizierungsergebnis übereinstimmen. Wenn Sie einen Fehler machen, aktualisieren Sie die Parameter entsprechend der Lernrate (implementiert für alle Datensätze mit for-Schleife usw.). Schritt .5 Mit Flags verwalten, wenn die Klassifizierung falsch ist Schritt .6 Fahren Sie fort, bis keine Fehlklassifizierungen mehr vorliegen
Wenn Sie den obigen Vorgang ausführen, wird das maschinelle Lernen erfolgreich abgeschlossen. Ich werde die Implementierung hier nicht veröffentlichen (da sie wahrscheinlich vom Urheberrecht der Nachschlagewerke erfasst wird).
Comment Wenn man die Anzahl der Fehlklassifizierungen in jedem Lernzyklus zählt, gibt es Szenen, in denen sie nicht monoton abnimmt, sondern zunimmt. Es ist auch wichtig zu überwachen, ob Sie in die richtige Richtung lernen ...
Recommended Posts