[Python] Erste Datenanalyse / maschinelles Lernen (Kaggle)
Einführung
Als ich kurz davor war, einen Job zu bekommen (Frühlingsferien in meinem 4. Studienjahr), wollte ich plötzlich Datenwissenschaftler werden, also begann ich vorerst mit der Arbeit an Kaggle.
Dieses Mal habe ich am Tutorial "** Titanic ** von ** Kaggle ** gearbeitet. Titanic / Übersicht) "Problem.
Ich habe Erfahrung in der statistischen Analyse in meiner Forschung, aber ich verstehe maschinelles Lernen überhaupt nicht, deshalb habe ich beschlossen, unter Bezugnahme auf den Code der wahnsinnig hervorragenden Person zu studieren!
Hier ist übrigens die Referenz ✔︎Introduction to Ensembling/Stacking in Python Dieser Code wurde in Notebook als "Meist gewählt" beschrieben. (Stand 10. März 2020)
Ich habe auch auf diesen Artikel verwiesen, der sich auf den obigen Code lol bezieht Tutorial zum Lernen von Ensembles (Stapeln) und maschinellem Lernen in Kaggle
Introduction Der Inhalt des Titanic-Wettbewerbs, an dem wir gerade arbeiten, enthält Daten zu Passagieren wie Alter, Geschlecht, Anzahl der Personen im Raum, Raumklasse, Leben und Tod.
Basierend auf diesen Daten ** Datenvorverarbeitung → Datenvisualisierung → Modellbau stapeln → Testdaten → Bewertung **
Schließlich prognostizieren wir Leben und Tod von Passagieren anhand eines Modells, das aus Testdaten erstellt wurde. Wie gut diese Vorhersage ist, ist auch ein Maß für die Punktzahl.
Da es viel Volumen gibt, konzentriert sich dieser Artikel auf ** "Vorverarbeitung" und "Datenvisualisierung" **!
Nachdem ich das Modell erstellt habe, werde ich es im nächsten Artikel veröffentlichen! Klicken Sie hier für den Folgeartikel ↓ ↓ ↓ [Python] Erste Datenanalyse / Maschinelles Lernen (Kaggle) ~ Part2 ~
Beginnen wir jetzt mit der Vorverarbeitung der Daten! !!
Datenvorverarbeitung
Bibliothek importieren
Etwa die Bibliothek nutzte diesmal
- Mathematische und statistische Verarbeitung: Numpy, Pundas
- Regelmäßige Ausdrucksoperationen (Suchen oder Ersetzen von Wörtern oder Zahlen in einer bestimmten Form): re
- Ich habe verschiedene Modelle ~: sklearn
- Algorithmus zur Verbesserung des Gradienten-Boosting-Entscheidungsbaums: XGboost
- Grafiken und Figuren: Matplotlib, Seaborn, Plotly
- Warnungen anzeigen / verbergen: Warnungen Fünf Grundmodelle
- Es ist Kfold, das diese fünf Modellbibliotheken gleichzeitig anwendet.
import_library.py
import pandas as pd
import numpy as np
import re
import sklearn
import xgboost as xgb
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
import warnings
warnings.filterwarnings('ignore')
#5 Modelle
from sklearn.ensemble import (RandomForestClassifier, AdaBoostClassifier,
GradientBoostingClassifier, ExtraTreesClassifier)
from sklearn.svm import SVC
#Wenden Sie mehrere Bibliotheken für maschinelles Lernen gleichzeitig an
from sklearn.cross_validation import KFold
Daten bekommen
import_data.py
train = pd.read_csv('../input/train.csv')
test = pd.read_csv('../input/test.csv')
#Lassen Sie den Passagierausweis den Passagierausweis behalten
PassengerId = test['PassengerId']
train.head(3)
Ausgabe

Daten Beschreibung
--PassengerId: Passagier-ID
- Überlebt: Lebens- und Todesflagge (wenn du überlebst: 1, wenn du stirbst: 0) --Klasse: Ticketklasse --Name: Name des Passagiers
- Sex: Geschlecht
- Alter: Alter --SibSp: Bruder / Ehepartner an Bord --Parch: Eltern / Kinder an Bord
- Tarif: Gebühr
- Kabine: Zimmernummer
- Eingeschifft: Hafen an Bord
Feature Quantity Engineering
Wir werden die erfassten Daten so verarbeiten, dass sie leicht analysiert werden können. Diese ** Vorverarbeitung scheint beim maschinellen Lernen ziemlich wichtig zu sein **, also werde ich lange mein Bestes geben! !!
Grundsätzlich werden alle fehlenden Werte (keine Werte) und Zeichendaten in numerische Daten umgewandelt.
FeatureEngineering.py
full_data = [train, test]
#Die Länge des Passagiernamens
train['name_length'] = train['name'].apply(len)
test['name_length'] = test['name'].apply(len)
#1, wenn Raumnummerndaten vorhanden sind, 0, wenn ein Wert fehlt
train['Has_Cabin'] = train['Cabin'].apply(lambda x: 0 if type(x) == float else 1)
test['Has_Cabin'] = test['Cabin'].apply(lambda x: 0 if type(x) == float else 1)
#Reiten Sie die Größe der Familie auf der Titanic"Bruder/Anzahl der Ehepartner"Wann"Elternteil/Anzahl der Kinder"Definieren aus
for dataset in full_data:
dataset ['FamilySize'] = dataset['Sibsp'] + dataset['Parch'] +1
#Wenn Sie keine Familie haben"IsAlone"Ist 1
for dataset in full_data:
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
#Die meisten fehlenden Werte im Abfahrtshafen'S'Behalten
for dataset in full_data:
dataset['Embarked'] = dataset['Embarked'].fillna('S')
#Stellen Sie den fehlenden Wert der Gebühr als Medianwert ein
#Teilen Sie die Gebühr in 4 Gruppen
for dataset in full_data:
dataset['Fare'] = dataset['Fare'].fillna(train['Fare'].median())
train['CategoricalFare'] = pd.qcut(train['Fare'], 4)
#Teilen Sie das Alter in 5 Gruppen ein
for dataset in full_data:
age_avg = dataset['Age'].mean()
age_std = dataset['Age'].std()
age_null_count = dataset['Age'].isnull().sum()
#Liste der Zufallswerte, die fehlende Werte eingeben sollen
#Verwenden Sie einen Wert, der um die Abweichung vom Durchschnittswert größer oder kleiner ist
age_null_random_list = np.random.randint(age_avg - age_std, age_avg + age_std, size = age_null_count)
dataset['Age'][np.isnan(dataset['Age'])] = age_null_random_list
#Konvertieren Sie Daten in den Typ int
dataset['Age'] = dataset['Age'].astype(int)
train['CategoricalAge'] = pd.qcut(train['Age'],5)
#Funktion zum Abrufen des Namens_Definition des Titels
def get_title(name):
title_search = re.search('([A-Za-z]+)\.',name)
#Wenn es einen Namen gibt, nehmen Sie ihn heraus und geben Sie ihn zurück
if title_search:
return title_search.group(1)
return ""
#Funktion bekommen_Verwenden Sie den Titel
for dataset in ftll_data:
dataset['Title'] = dataset['Name'].apply(get_title)
#Korrigieren Sie den fehlerhaften Teil des Namens
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
for dataset in full_data:
#0 für Frauen, 1 für Männer
dataset['Sex'] = dataset['Sex'].map( {'female': 0, 'male': 1} ).astype(int)
#Beschriftet für 5 Arten von Namen
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
#Beschriftet auf 3 Arten von Abfahrtspunkten
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
#Teilen Sie die Gebühr in 4 Gruppen
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
#Teilen Sie das Alter in 5 Gruppen ein
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age'] = 4 ;
#Entfernen Sie unnötige Funktionen
drop_elements = ['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp']
train = train.drop(drop_elements, axis = 1)
train = train.drop(['CategoricalAge', 'CategoricalFare'], axis = 1)
test = test.drop(drop_elements, axis = 1)
Codierung, die ich gelernt habe
- Verwendung der Lambda-Funktion
- fillna() --pandas qcut
- Kartenfunktion
- Geben Sie den Wert nur ein, wenn True in [] von loc [] ist, ohne die if-Anweisung zu verwenden.
- axis = 1
Datenvisualisierung
Endlich ist die Vorverarbeitung vorbei! !! Lassen Sie uns überprüfen, ob alle Daten numerische Daten sind!
visualize.py
train.head(3)

Ursachenkorrelations-Heatmap
Überprüfen Sie die Korrelation zwischen den Merkmalsgrößen auf der Wärmekarte.
heatmap.py
colormap = plt.cm.RdBu
plt.figure(figsize = (14,12))
plt.title('Peason Correlation of Features', y = 1.05, size = 15)
sns.heatmap(train.astype(float).corr(), linewidths=0.1, vmax=1.0, square = True, cmap=colormap, linecolor='white', annot=True)
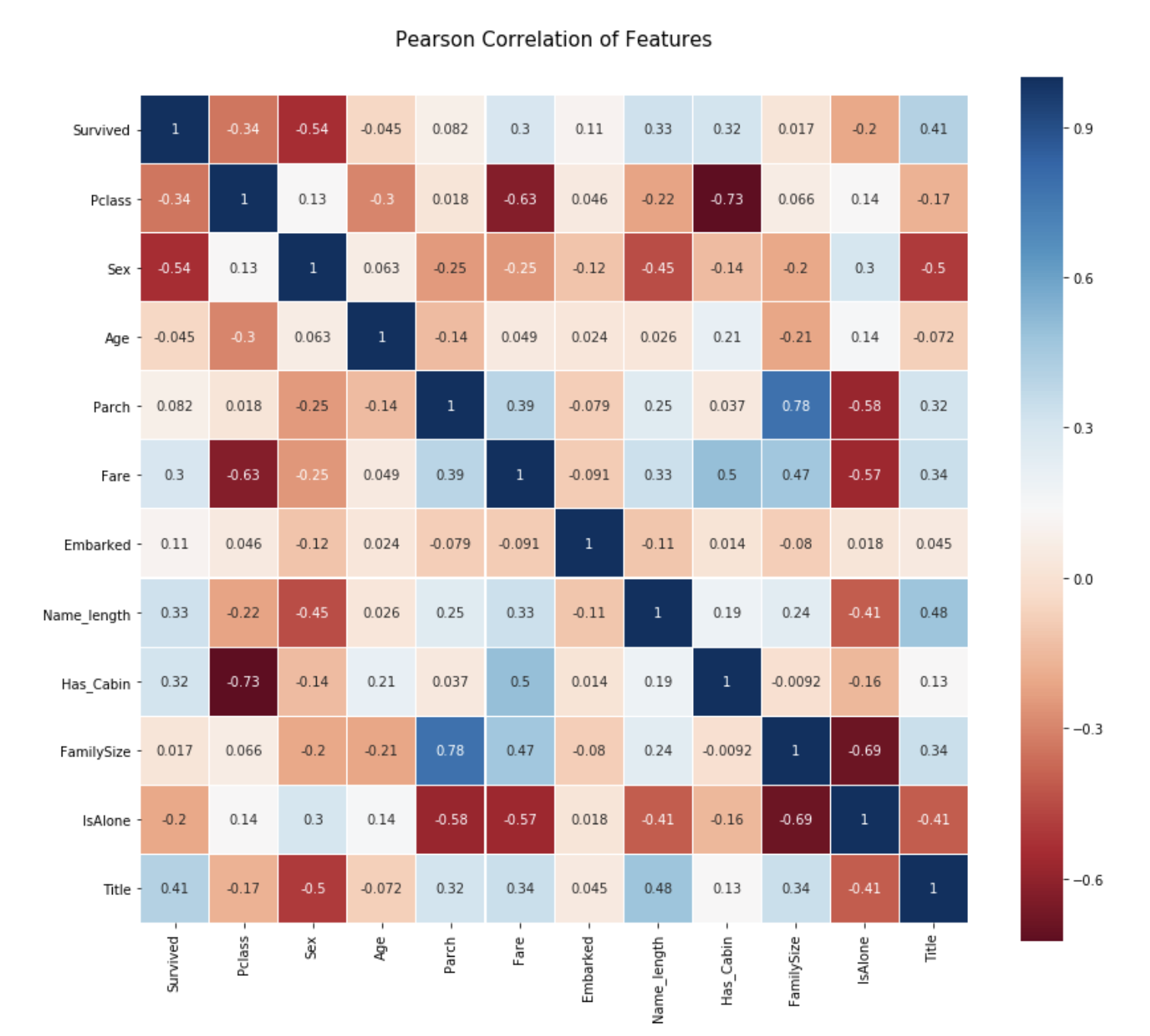
Aus dieser Darstellung können wir ersehen, dass die Merkmale nicht so stark miteinander korreliert sind.
Funktionen sind unabhängig voneinander → Keine nutzlosen Funktionen → Wichtig für die Erstellung eines Lernmodells (Parch und Familiengröße haben eine relativ starke Korrelation, lassen sie aber so, wie sie sind.)
Paar Plot
Verteilung von Daten von einem Feature zum anderen
PairPlot.py
g = sns.pairplot(train[[u'Survived', u'Pclass', u'Sex', u'Age', u'Parch', u'Fare', u'Embarked',
u'FamilySize', u'Title']], hue='Survived', palette = 'seismic',size=1.2,diag_kind = 'kde',diag_kws=dict(shade=True),plot_kws=dict(s=10) )
g.set(xticklabels=[])
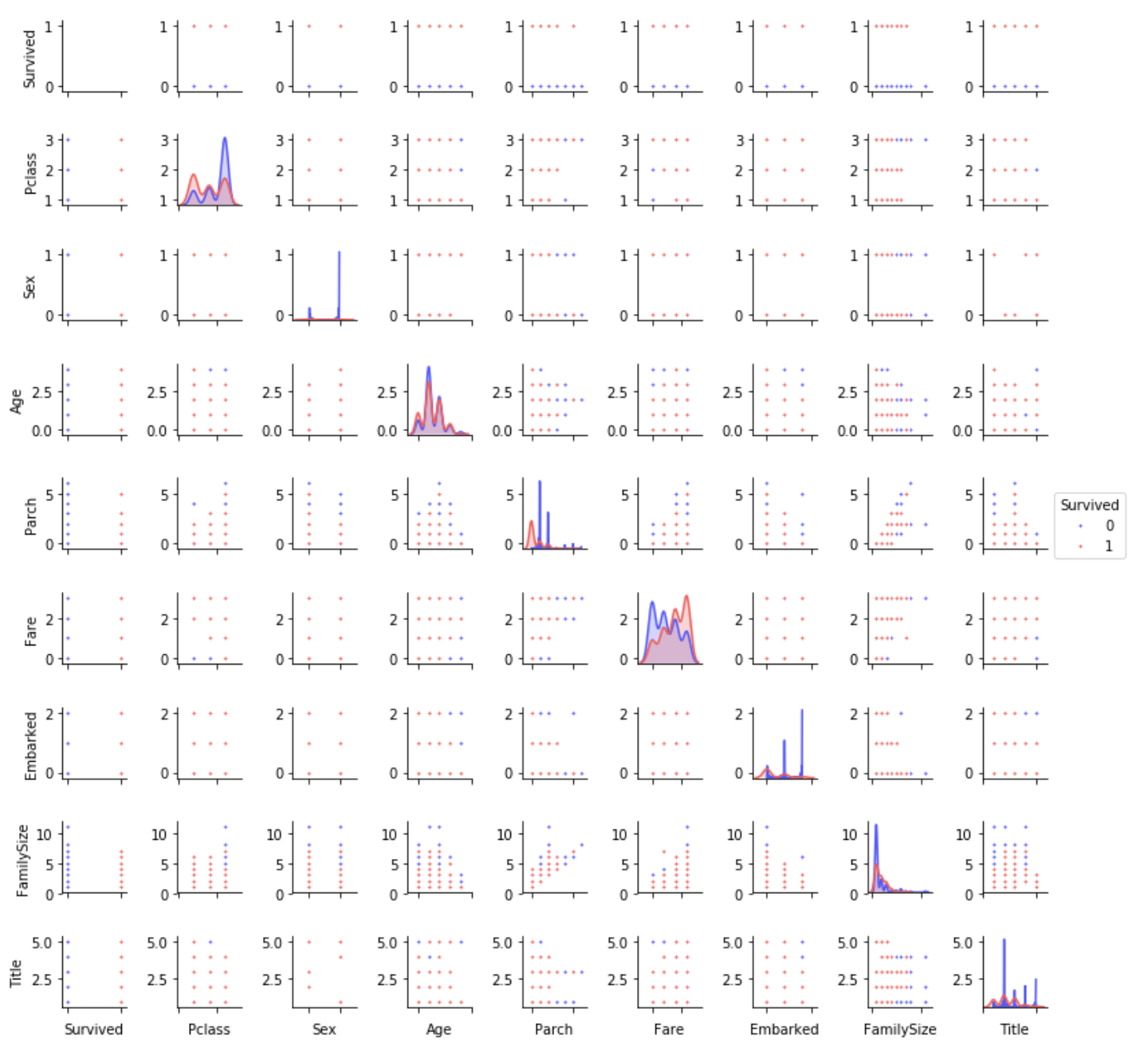
Zusammenfassung
In diesem Artikel habe ich an Kaggles Tutorial "Titanic" gearbeitet. Als Fluss,
- Bibliothek importieren
- Datenerfassung
- Datenvorverarbeitung
- Fehlende Werte beseitigen (zufällige Werte in der Nähe des Durchschnittswerts einfügen usw.)
- Gleiche Aufteilung der Daten
- Konvertieren Sie Kategoriedaten in Zahlen
- Datenvisualisierung
- Pearson Correlation Heat Map
- Paar Grundstück
Bisher war es ziemlich schwierig, aber ich werde weiterhin mein Bestes geben, da es sich um den eigentlichen Modellbau von hier handelt! !!
Recommended Posts