Implementieren Sie das Stacking-Lernen in Python [Kaggle]
TL;DR
Das Stapellernen ist eine häufig verwendete Methode, wenn die Genauigkeit eines einzelnen Vorhersagemodells beim maschinellen Lernen ein Plateau erreicht. In diesem Artikel verwenden wir Python als Stapelmodell, das auf dem früheren Kaggle-Wettbewerb ["Otto Group Product Classification Challenge"] basiert (https://www.kaggle.com/c/otto-group-product-classification-challenge). Implementieren und fordern Sie Klassifizierungsaufgaben für mehrere Klassen heraus.
Wettbewerbsübersicht
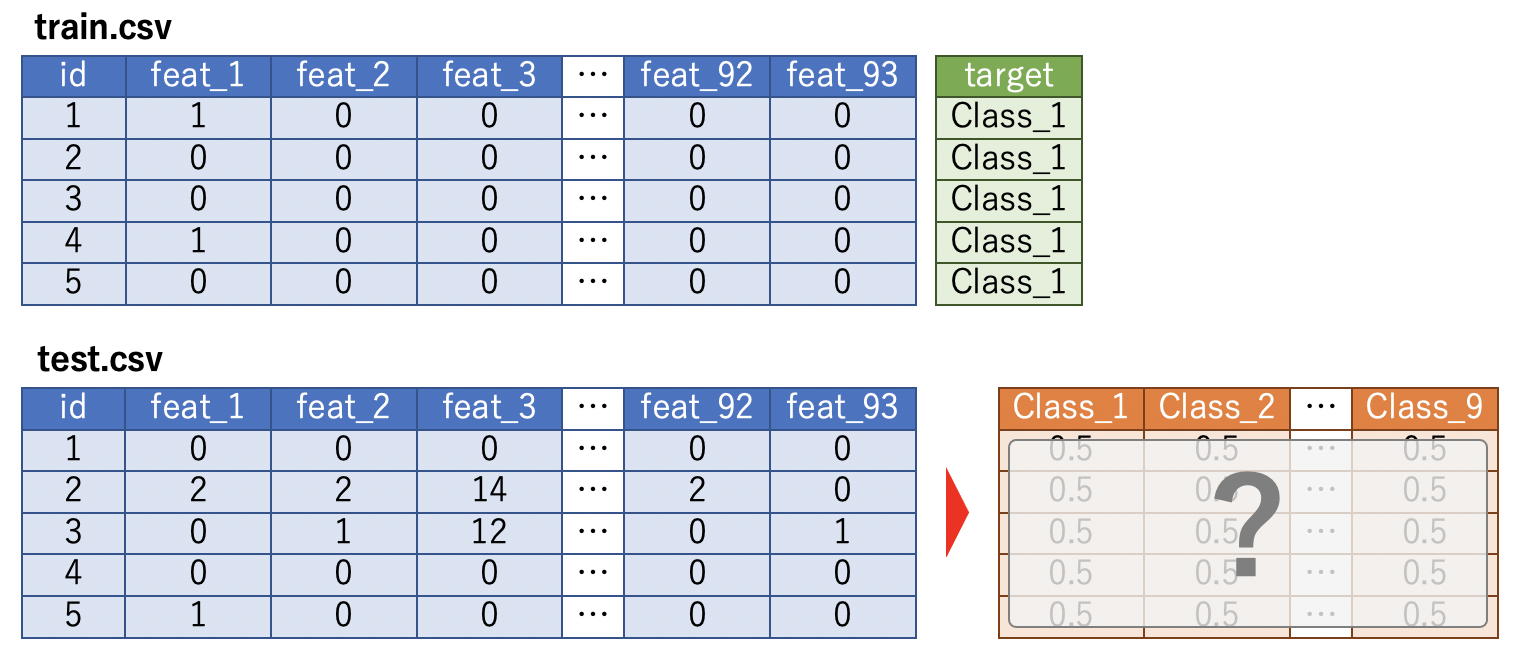
Es handelt sich um eine Mehrfachklassifizierungsaufgabe, die vorhersagt, welche der neun Klassen anhand von Produktdaten klassifiziert wird.
train.csv speichert 93 Merkmalsmengen und die Daten der Klasse, zu der es gehört, die die Zielvariable ist. Der Zweck besteht darin, die Klasse, zu der jedes Produkt gehört, mit Wahrscheinlichkeit aus der Merkmalsmenge von "test.csv" vorherzusagen. Multi-Class Log-Loss wird als Bewertungsindex verwendet.
Vorbereitung
Importieren Sie die erforderlichen Bibliotheken.
In
import os, sys
import datetime
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.neighbors import KNeighborsClassifier
import xgboost as xgb
from xgboost import XGBClassifier
Lesen / Vorverarbeiten von Daten
In
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
sample = pd.read_csv('data/sampleSubmission.csv')
In
train.head()

Da der Wert der Zielvariablen eine Zeichenfolge ist, konvertieren Sie sie in einen numerischen Wert.
In
le = LabelEncoder()
le.fit(train['target'])
train['target'] = le.transform(train['target'])
Trennen Sie die erklärende Variable X und die Zielvariable y. Konvertieren Sie X in ein NumPy-Array.
In
X_train = train.drop(['id', 'target'], axis=1)
y_train = train['target'].copy()
X_test = test.drop(['id'], axis=1)
X_train = X_train.values
X_test = X_test.values
Behalten Sie das Feld "id" von "test" bei, um die Übermittlungsdatei zu erstellen.
testIds = test['id'].copy()
Da es vom Zweck abweicht, werde ich es hier weglassen, aber wenn man die Verteilung der Daten betrachtet, gibt es eine beträchtliche Verzerrung in den Werten. Ich dachte, dass Normalisierung eine gute Methode ist, aber als ich sie ausprobierte, gab es keine Verbesserung der endgültigen Genauigkeit, also entschied ich mich, mit Row Data so fortzufahren, wie es ist.
Definition des Modells der ersten Schicht
Gesamtmodellkonfiguration
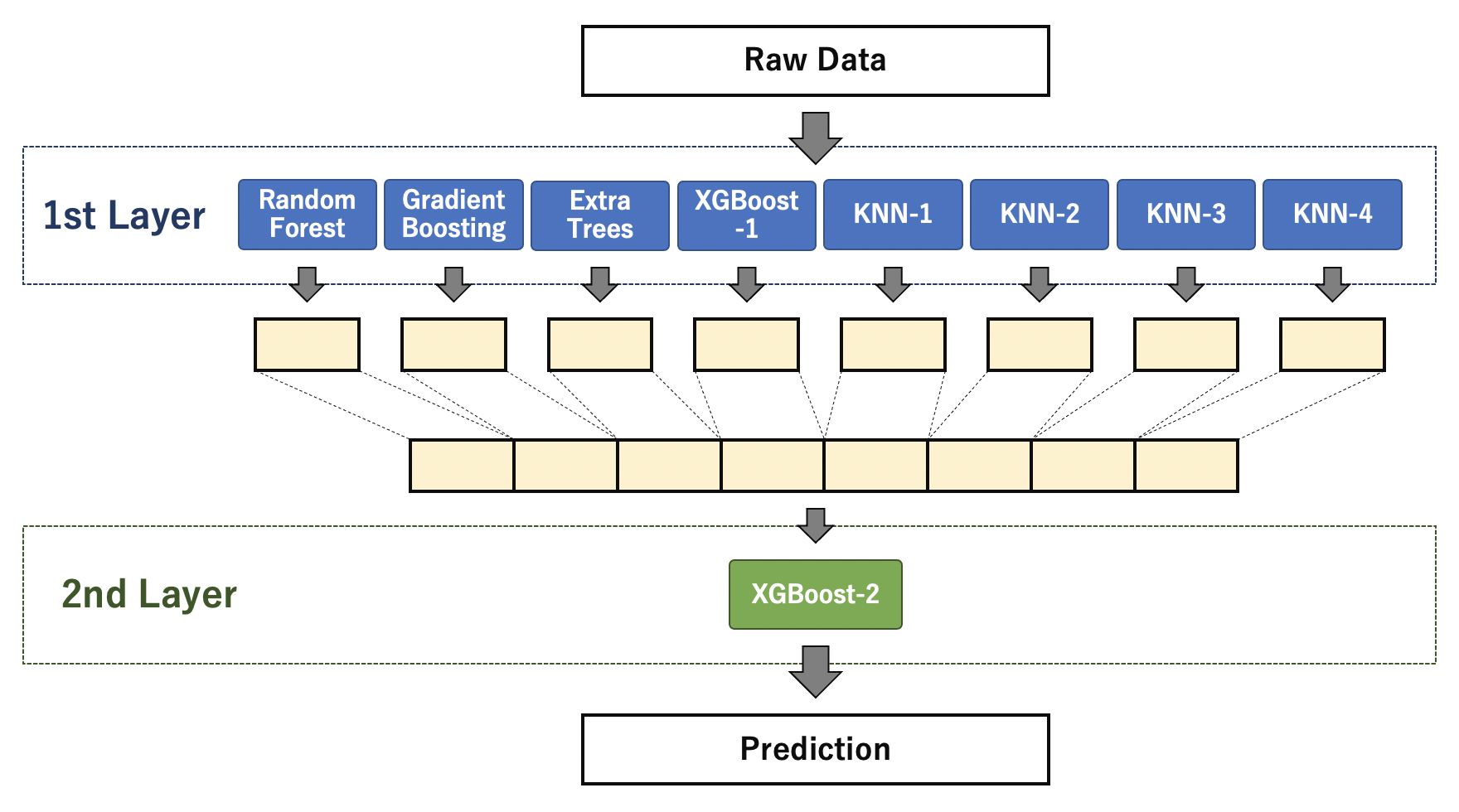
Definieren Sie als Gesamtkonfiguration in der ersten Ebene acht Modelle wie Random Forest, Gradient Boosting, KNN usw. Unter Verwendung der vorhergesagten Werte jedes Modells in der ersten Schicht wird die Vorhersage durch XGBoost in der zweiten Schicht als endgültiges Vorhersageergebnis verwendet.
Definition der Klassifikatorerweiterungsklasse
Definieren Sie eine Erweiterungsklasse für den Klassifizierer, um die Operationen (Definition, Training, Vorhersage) für jedes Modell der ersten Ebene zu vereinfachen.
In
class ClfBuilder(object):
def __init__(self, clf, params=None):
self.clf = clf(**params)
def fit(self, X, y):
self.clf.fit(X, y)
def predict(self, X):
return self.clf.predict(X)
def predict_proba(self, X):
return self.clf.predict_proba(X)
Definition der Out-of-Fold-Vorhersagefunktion
Beim Stapeln werden die vorhergesagten Werte des Modells der ersten Schicht für das Modell der zweiten Schicht verwendet. Um ein Übertraining bekannter Daten in der zweiten Schicht zu verhindern, wird der vorhergesagte Wert durch Out-of-Fold in der ersten Schicht berechnet und für das Training in der zweiten Schicht verwendet. In der folgenden Implementierung wird "Stratified KFold" für die 5-teilige Kreuzungsüberprüfung verwendet.
In
def get_base_model_preds(clf, X_train, y_train, X_test):
print(clf.clf)
N_SPLITS = 5
oof_valid = np.zeros((X_train.shape[0], 9))
oof_test = np.zeros((X_test.shape[0], 9))
oof_test_skf = np.zeros((N_SPLITS, X_test.shape[0], 9))
skf = StratifiedKFold(n_splits=N_SPLITS)
for i, (train_index, valid_index) in enumerate(skf.split(X_train, y_train)):
print('[CV] {}/{}'.format(i+1, N_SPLITS))
X_train_, X_valid_ = X_train[train_index], X_train[valid_index]
y_train_, y_valid_ = y_train[train_index], y_train[valid_index]
clf.fit(X_train_, y_train_)
oof_valid[valid_index] = clf.predict_proba(X_valid_)
oof_test_skf[i, :] = clf.predict_proba(X_test)
oof_test[:] = oof_test_skf.mean(axis=0)
return oof_valid, oof_test
Parametereinstellungen
Stellen Sie die Parameter ein, die mit dem Diktattyp an die Funktion ClfBuilder übergeben werden sollen.
(* Hyperparameter-Tuning wird hier nicht durchgeführt)
In
rfc_params = {
'n_estimators': 100,
'max_depth': 10,
'random_state': 0,
}
gbc_params = {
'n_estimators': 50,
'max_depth': 10,
'random_state': 0,
}
etc_params = {
'n_estimators': 100,
'max_depth': 10,
'random_state': 0,
}
xgbc1_params = {
'n_estimators': 100,
'max_depth': 10,
'random_state': 0,
}
knn1_params = {'n_neighbors': 4}
knn2_params = {'n_neighbors': 8}
knn3_params = {'n_neighbors': 16}
knn4_params = {'n_neighbors': 32}
Erstellen Sie eine Instanz des Modells der ersten Ebene.
In
rfc = ClfBuilder(clf=RandomForestClassifier, params=rfc_params)
gbc = ClfBuilder(clf=GradientBoostingClassifier, params=gbc_params)
etc = ClfBuilder(clf=ExtraTreesClassifier, params=etc_params)
xgbc1 = ClfBuilder(clf=XGBClassifier, params=xgbc1_params)
knn1 = ClfBuilder(clf=KNeighborsClassifier, params=knn1_params)
knn2 = ClfBuilder(clf=KNeighborsClassifier, params=knn2_params)
knn3 = ClfBuilder(clf=KNeighborsClassifier, params=knn3_params)
knn4 = ClfBuilder(clf=KNeighborsClassifier, params=knn4_params)
Das Modell der ersten Schicht lernen
Unter Verwendung der zuvor definierten "get_base_model_preds" wird jedes Modell der ersten Schicht trainiert und der vorhergesagte Wert, der für das Training und die Vorhersage des Modells der zweiten Schicht verwendet wird, berechnet.
In
oof_valid_rfc, oof_test_rfc = get_base_model_preds(rfc, X_train, y_train, X_test)
oof_valid_gbc, oof_test_gbc = get_base_model_preds(gbc, X_train, y_train, X_test)
oof_valid_etc, oof_test_etc = get_base_model_preds(etc, X_train, y_train, X_test)
oof_valid_xgbc1, oof_test_xgbc1 = get_base_model_preds(xgbc1, X_train, y_train, X_test)
oof_valid_knn1, oof_test_knn1 = get_base_model_preds(knn1, X_train, y_train, X_test)
oof_valid_knn2, oof_test_knn2 = get_base_model_preds(knn2, X_train, y_train, X_test)
oof_valid_knn3, oof_test_knn3 = get_base_model_preds(knn3, X_train, y_train, X_test)
oof_valid_knn4, oof_test_knn4 = get_base_model_preds(knn4, X_train, y_train, X_test)
Out
RandomForestClassifier(max_depth=10, random_state=0)
[CV] 1/5
[CV] 2/5
[CV] 3/5
[CV] 4/5
[CV] 5/5
GradientBoostingClassifier(max_depth=10, n_estimators=50, random_state=0)
[CV] 1/5
(...Abkürzung...)
[CV] 5/5
KNeighborsClassifier(n_neighbors=32)
[CV] 1/5
[CV] 2/5
[CV] 3/5
[CV] 4/5
[CV] 5/5
Der Vorhersagewert, der in die zweite Schicht eingegeben werden soll, ist die Kombination der Vorhersageergebnisse jedes Klassifikators nebeneinander.
In
X_train_base = np.concatenate([oof_valid_rfc,
oof_valid_gbc,
oof_valid_etc,
oof_valid_xgbc1,
oof_valid_knn1,
oof_valid_knn2,
oof_valid_knn3,
oof_valid_knn4,
], axis=1)
X_test_base = np.concatenate([oof_test_rfc,
oof_test_gbc,
oof_test_etc,
oof_test_xgbc1,
oof_test_knn1,
oof_test_knn2,
oof_test_knn3,
oof_test_knn4,
], axis=1)
Definition / Lernen des Second-Layer-Modells
XGBoost wird als Modell der zweiten Ebene verwendet. Legen Sie die Parameter fest und erstellen Sie eine Instanz des Modells.
In
xgbc2_params = {
'n_eetimators': 100,
'max_depth': 5,
'random_state': 42,
}
xgbc2 = XGBClassifier(**xgbc2_params)
Wir werden das Modell der zweiten Schicht trainieren.
In
xgbc2.fit(X_train_base, y_train)
Vorhersage durch Testdaten
Die Vorhersage erfolgt anhand von Testdaten unter Verwendung des trainierten Modells der zweiten Schicht.
In
prediction = xgbc2.predict_proba(X_test_base)
Speichern Sie die Vorhersageergebnisse im Datenrahmen für die Übermittlungsdatei. Ausgabe im CSV-Format und Übermittlung.
In
columns = ['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9']
df_prediction = pd.DataFrame(prediction, columns=columns)
df_submission = pd.concat([testIds, df_prediction], axis=1)
In
now = datetime.datetime.now()
timestamp = now.strftime('%Y%m%d-%H%M%S')
df_submission.to_csv('output/ensemble_{}.csv'.format(timestamp), index=False)
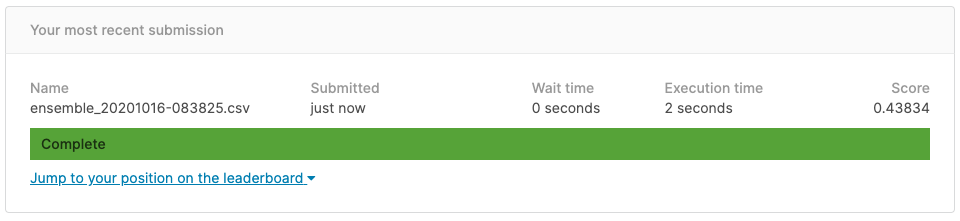
Das Ergebnis ist "Score = 0,443834". Da es sich um eine verspätete Einreichung handelt, wird sie nicht in der Rangliste aufgeführt. Wenn sie jedoch aufgeführt ist, wurde sie mit 462/3507 bewertet, was den besten 14% entspricht.
Genauigkeitsvergleich mit jedem Modell der ersten Schicht
Um den Effekt des Stapelns zu sehen, vergleichen wir ihn mit der vorhergesagten Punktzahl für die Testdaten, die von jedem Modell in der ersten Schicht berechnet wurden.
| Classifier | Score |
|---|---|
| Random Forest | 0.95957 |
| Gradient Boosting | 0.49276 |
| Extra Trees | 1.34781 |
| XGBoost-1 | 0.47799 |
| KNN-1 | 1.94937 |
| KNN-2 | 1.28614 |
| KNN-3 | 0.93161 |
| KNN-4 | 0.75685 |
Wir haben bestätigt, dass die Stapelvorhersage besser ist als jeder einzelne Klassifikator! Dieses Mal haben wir die Eingabedaten nicht verarbeitet oder die Hyperparameter nicht angepasst, dies kann jedoch die Genauigkeit weiter verbessern. Ebenso wie das Gewinnermodell scheint es möglich zu sein, die zweite Ebene mit mehreren Klassifizierern zu konfigurieren.
Referenzen / URL
- "Datenanalysetechnologie, die mit Kaggle gewinnt"
- Lernprogramm für Ensemble (Stapeln) und maschinelles Lernen in Kaggle
- KAGGLE ENSEMBLING GUIDE
Recommended Posts