[PYTHON] [Super Einführung in das maschinelle Lernen] Lernen Sie Pytorch-Tutorials
Dies ist eine Zusammenstellung dessen, was der Autor geschrieben hat, anstelle eines Memos, das der Autor noch nicht vollständig erfasst hat. Ich werde den Inhalt des Pytorch-Tutorials + den in α untersuchten Inhalt zusammenfassen. (Ich habe geschrieben ..., aber es entspricht kaum dem Tutorial.)
Mit dem Ziel, es frei nutzen zu können, nachdem Sie entschieden haben, was Sie verstehen können, Ich werde mit einer Politik der stetigen Umsetzung studieren.
Diesmal ist Kapitel 2. Zurück-> https://qiita.com/akaiteto/items/9ac0a84377600ed337a6
Einführung
Beim letzten Mal habe ich mir nur die Verarbeitung jeder Schicht des neutralen Netzwerks angesehen Dieses Mal werde ich mich auf die Optimierung konzentrieren.
Als Prämisse empfand ich es als etwas verwirrend, nur die MNIST-Beispielquelle zu verschieben Erstellen Sie so einfach wie möglich ein Beispiel aus der Position und verschieben Sie es dann tatsächlich Von dort aus werde ich mit dem Ziel studieren, verschiedene Methoden selbst zu implementieren.
Als nächstes werde ich versuchen, meine eigene Optimierungsmethode in das neutrale Netzwerk zu integrieren. Darüber hinaus wird nur die Methode mit dem steilsten Abstieg implementiert. Dies kann hilfreich sein, wenn Sie Ihre eigenen Optimierungstechniken in einem neutralen Netzwerk implementieren.
Das Netzwerk lernen
Letztes Missverständnis
Beim letzten Mal habe ich die folgenden Berechnungsergebnisse zur Erläuterung der Verlustfunktion vorgestellt.
Es ist sehr einfach zu tun. Geben Sie zuerst die entsprechenden Eingabedaten in das definierte Netzwerk ein und dann Ich habe den Ausgabewert erhalten (Daten, die die Funktionsinformationen enthalten).
Machen Sie danach dasselbe für verschiedene andere Eingabedaten. Der "Fehler" mit dem zuerst berechneten Ausgabeort wurde berechnet und als "Auswertung" ausgegeben.
#Ausführungsergebnis
*****Lernphase*****
Eingabedaten für das Netzwerklernen
tensor([[[[0., 1., 0., 1.],
[0., 0., 0., 0.],
[0., 1., 0., 1.],
[0., 0., 0., 0.]]]])
*****Bewertungsphase*****
Geben Sie die gleichen Daten ein
input:
tensor([[[[0., 1., 0., 1.],
[0., 0., 0., 0.],
[0., 1., 0., 1.],
[0., 0., 0., 0.]]]])
Bewertungstensor(0., grad_fn=<MseLossBackward>)
Geben Sie etwas andere Daten ein
input:
tensor([[[[0., 2., 0., 2.],
[0., 0., 0., 0.],
[0., 2., 0., 2.],
[0., 0., 0., 0.]]]])
Bewertungstensor(0.4581, grad_fn=<MseLossBackward>)
Geben Sie ganz andere Daten ein
input:
tensor([[[[ 10., 122., 10., 122.],
[1000., 200., 1000., 200.],
[ 10., 122., 10., 122.],
[1000., 200., 1000., 200.]]]])
Bewertungstensor(58437.6680, grad_fn=<MseLossBackward>)
"Ich bin sicher, dass dieser Bewertungswert anhand des Schwellenwerts beurteilt wird und ob er gleich ist oder nicht." Ich dachte damals. Werden Daten als unterschiedlich angesehen, wenn sie durch 0,5 oder mehr getrennt sind? Es geht um Anerkennung.
Der Ausgabewert ist sozusagen ein numerischer Wert, der aus den Eigenschaften der einzelnen Daten extrahiert wird. CNN ist also ein Weg, um zu sehen, wie nah die Funktionen sind! Wann.
... aber das reicht nicht. So wie es jetzt ist, ist es nur gefiltert. Ich habe das Lernen nicht richtig verstanden.
Richtige Antwortdaten A.
tensor([[[[0., 2., 0., 2.],
[0., 0., 0., 0.],
[0., 2., 0., 2.],
[0., 0., 0., 0.]]]])
Eingabedaten B.
tensor([[[[0., 1., 0., 1.],
[0., 0., 0., 0.],
[0., 1., 0., 1.],
[0., 0., 0., 0.]]]])
Bewertungstensor(0.4581, grad_fn=<MseLossBackward>)
Das Wesentliche der Lernphase ist
"Eingabedaten A und B, die sich geringfügig unterscheiden, aber tatsächlich auf dasselbe verweisen, Lassen Sie es uns als dasselbe erkennen! !! "darüber.
Bewertungstensor(0.4581, grad_fn=<MseLossBackward>)
Diese Nummer wird als Fehler ausgegeben. Dieser numerische Wert zeigt an, um wie viel die Eingabedaten A und B nicht ausgerichtet sind.
Es gibt einen Fehler im numerischen Wert, aber in Wirklichkeit sind A und B gleich Der Fehler sollte idealerweise "0" sein.
Das heißt, was ist die Essenz des Lernens? Großer Fehler zwischen den Eingabedaten A und B, Ausgabe als "0,4581" Dies ist die Essenz des "Hinzufügens einer kleinen Hand", damit diese so weit wie möglich als "0" ausgegeben wird.
Indem Sie das "Gewicht" jeder Schicht des Netzwerks so einstellen, dass der Fehler als 0 ausgegeben wird, Die Essenz besteht darin, "zu lernen", dass "es keinen Fehler gibt - A und B sind gleich".
Versuchen Sie zu optimieren
Optimierung (aufhören zu denken)
Welche Formel wird verwendet, um das Gewicht anzupassen? Ich werde es beiseite legen und zuerst aufhören zu denken und es mit Pytorch lernen lassen.
Ich weiß nicht warum und ich mag es nicht, verschiedene coole Schichten im Beispiel von MNIST zu verwenden. Testen wir, soweit wir verstehen, mit einem einfacheren Beispiel.
Muster A.
tensor([[[[0., 1., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.]]]])
Muster B.
tensor([[[[1., 1., 1., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.],
[1., 1., 1., 1.]]]])
Lassen Sie uns die beiden oben genannten Muster lernen und testen.
Das ganze
test.py
import torch.nn as nn
import torch.nn.functional as F
import torch
from torch import optim
import matplotlib.pyplot as plt
import numpy as np
class DataType():
TypeA = "TypeA"
TypeA_idx = 0
TypeB = "TypeB"
TypeB_idx = 1
TypeOther_idx = 1
def outputData_TypeA(i):
npData = np.array([[0,i,0,i],
[0,i,0,i],
[0,i,0,i],
[0,i,0,i]])
tor_data = torch.from_numpy(np.array(npData).reshape(1, 1, 4, 4).astype(np.float32)).clone()
return tor_data
def outputData_TypeB(i):
npData = np.array([[i,i,i,i],
[0,i,0,i],
[0,i,0,i],
[i,i,i,i]])
tor_data = torch.from_numpy(np.array(npData).reshape(1, 1, 4, 4).astype(np.float32)).clone()
return tor_data
class Test_Conv(nn.Module):
kernel_filter = None
def __init__(self):
super(Test_Conv, self).__init__()
ksize = 4
self.conv = nn.Conv2d(
in_channels=1,
out_channels=4,
kernel_size=4,
bias=False)
def forward(self, x):
x = self.conv(x)
x = x.view(1,4)
return x
#Datenaufbereitung während des Tests
input_data = []
strData = "data"
strLabel = "type"
for i in range(20):
input_data.append({strData:outputData_TypeA(i),strLabel:DataType.TypeA})
for i in range(20):
input_data.append({strData:outputData_TypeB(i),strLabel:DataType.TypeB})
print("Bereiten Sie insgesamt 200 Testdaten der folgenden Muster vor")
print("Muster A.")
print(outputData_TypeA(1))
print("Muster B.")
print(outputData_TypeB(1))
print("Stellen Sie sicher, dass diese beiden Muster unterschieden werden können.")
print("\n\n")
#Netzwerkdefinition
Test_Conv = Test_Conv()
#Eingang
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(Test_Conv.parameters(), lr=0.001, momentum=0.9)
print("***Versuchen Sie es vor dem Lernen***")
##Versuchen Sie, mit dem trainierten Modell geeignete Daten einzugeben.
NG_data = outputData_TypeA(999999999)
answer_data = [DataType.TypeA_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
print("\n\n")
outputs = Test_Conv(NG_data)
_, predicted = torch.max(outputs.data, 1)
correct = (answer_data == predicted).sum().item()
print("Richtige Antwortrate: {} %".format(correct / len(predicted) * 100.0))
print("***Lernphase***")
epochs = 2
for i in range(epochs):
for dicData in input_data:
#Vorbereitung der Trainingsdaten
train_data = dicData[strData]
#Vorbereitung der richtigen Antwortdaten
answer_data = []
label = dicData[strLabel]
if label == DataType.TypeA:
answer_data = [DataType.TypeA_idx]
elif label == DataType.TypeB:
answer_data = [DataType.TypeB_idx]
else:
answer_data = [DataType.TypeOther_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
#Optimierungsprozess
optimizer.zero_grad()
outputs = Test_Conv(train_data)
loss = criterion(outputs, answer_data)
# print(train_data.shape)
# print(outputs.shape)
# print(answer_data.shape)
#
# exit()
loss.backward()
optimizer.step()
print("\t", i, " :Error= ",loss.item())
print("\n\n")
print("***Testphase***")
##Versuchen Sie, mit dem trainierten Modell geeignete Daten einzugeben.
input_data = outputData_TypeA(999999999)
answer_data = [DataType.TypeA_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
outputs = Test_Conv(input_data)
_, predicted = torch.max(outputs.data, 1)
correct = (answer_data == predicted).sum().item()
print("Richtige Antwortrate: {} %".format(correct / len(predicted) * 100.0))
exit()
Bereiten Sie insgesamt 200 Testdaten der folgenden Muster vor
Muster A.
tensor([[[[0., 1., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.]]]])
Muster B.
tensor([[[[1., 1., 1., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.],
[1., 1., 1., 1.]]]])
Stellen Sie sicher, dass diese beiden Muster unterschieden werden können.
***Versuchen Sie es vor dem Lernen***
Richtige Antwortrate: 0.0 %
***Lernphase***
0 :Error= 1.3862943649291992
0 :Error= 1.893149733543396
0 :Error= 2.4831488132476807
0 :Error= 3.0793371200561523
0 :Error= 3.550563335418701
0 :Error= 3.7199602127075195
0 :Error= 3.3844733238220215
0 :Error= 2.374782085418701
0 :Error= 0.8799697160720825
0 :Error= 0.09877146035432816
0 :Error= 0.006193255074322224
0 :Error= 0.00034528967808000743
0 :Error= 1.8000440832111053e-05
0 :Error= 8.344646857949556e-07
0 :Error= 0.0
0 :Error= 0.0
0 :Error= 0.0
0 :Error= 0.0
0 :Error= 0.0
0 :Error= 0.0
0 :Error= 0.0
0 :Error= 0.0
0 :Error= 0.0
.
.
.
***Testphase***
Richtige Antwortrate: 100.0 %
Es ist eine einfache Quelle, aber schauen wir sie uns einzeln an.
Netzwerkdefinition
test.py
class Test_Conv(nn.Module):
kernel_filter = None
def __init__(self):
super(Test_Conv, self).__init__()
ksize = 4
self.conv = nn.Conv2d(
in_channels=1,
out_channels=4,
kernel_size=4,
bias=False)
def forward(self, x):
x = self.conv(x)
x = x.view(1,4)
return x
In MNIST wurden alle Daten gleichzeitig als Eingabedaten eingegeben. Es schien jedoch schwierig zu sein, intuitiv zu verstehen, da der Maßstab zu groß war. Es ist so eingestellt, dass monochrome Bilder einzeln eingefügt werden.
Da die Faltungsschicht $ out_channels = 4 $ ist, werden 4 Merkmale mit einem Filter extrahiert. In $ x.view $ sind die Abmessungen zum Vergleich mit der richtigen Bezeichnung angeordnet.
Versuchen Sie, sich vor dem Lernen zu bewerben
test.py
print("***Versuchen Sie es vor dem Lernen***")
##Versuchen Sie, mit dem trainierten Modell geeignete Daten einzugeben.
NG_data = outputData_TypeA(999999999)
answer_data = [DataType.TypeA_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
print("\n\n")
outputs = Test_Conv(NG_data)
_, predicted = torch.max(outputs.data, 1)
correct = (answer_data == predicted).sum().item()
print("Richtige Antwortrate: {} %".format(correct / len(predicted) * 100.0))
Ich werde es versuchen, bevor ich lerne. Der Code ist anders, aber es ist eine Reproduktion des "letzten Missverständnisses". Sicher genug, die richtige Antwortrate ist 0%.
Das Netzwerk lernen
test.py
#Vorbereitung der Trainingsdaten
train_data = dicData[strData]
#Vorbereitung der richtigen Antwortdaten
answer_data = []
label = dicData[strLabel]
if label == DataType.TypeA:
answer_data = [DataType.TypeA_idx]
elif label == DataType.TypeB:
answer_data = [DataType.TypeB_idx]
else:
answer_data = [DataType.TypeOther_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
#Optimierungsprozess
optimizer.zero_grad()
outputs = Test_Conv(train_data)
loss = criterion(outputs, answer_data)
loss.backward()
optimizer.step()
print("\t", i, " :Error= ",loss.item())
Im Abschnitt "Letztes Missverständnis" schrieb ich wie folgt
Großer Fehler zwischen den Eingabedaten A und B, "0.Was wird als "4581" ausgegeben?
Dies ist die Essenz des "Hinzufügens einer kleinen Hand", damit diese so weit wie möglich als "0" ausgegeben wird.
Network Learning macht das. Fügen Sie zu Beginn des Prozesses zunächst nur Daten von Muster A oder Muster B in $ train_data $ ein.
test.py
outputs = Test_Conv(train_data)
Innerhalb des Netzwerks werden 4 Funktionen durch Anwenden von 4 Filtern berechnet. Gibt Daten aus, die vier Funktionen pro "eine" Daten enthalten. In Bezug auf die Abmessungen sind es [1,4] Daten.
Bereiten Sie als Nächstes die richtigen Antwortdaten vor.
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
Stellen Sie die richtige Antwort für die Ausgabe "one data" ein. Da die Zeichenfolge nicht gesetzt werden kann, "0" für Muster A-Daten, Wenn es B von Muster B ist, setzen Sie es auf "1". Da es sich um die richtigen Antwortdaten für eine Daten handelt, sind die Daten der richtigen Antwortdaten die Daten von [1].
Maßbild
#Dieses Beispiel
[Ausgabedatenstruktur]
-Daten
-Erstes Feature
-Zweites Merkmal
-Drittes Merkmal
-Viertes Merkmal
[Struktur der richtigen Antwortdaten]
-Antworte auf die Daten(1?0?)
test.py
loss = criterion(outputs, answer_data)
Berechnen Sie dann den Fehler. Da das Gewicht für jedes richtige Antwortetikett angepasst wird, geben Sie auch das richtige Antwortetikett an.
optimizer.step()
Anschließend wird ein neuer Prozess namens Optimierung ausgeführt, der noch nicht angezeigt wurde. Geben Sie in der for-Schleife die Ausgabedaten für jeden Typ A und Typ B ein. Ich denke, dass das Gewicht so angepasst wird, dass sich der Fehler in jedem Typ 0 nähert. (Da es sich jetzt in der Denkstoppphase befindet, werde ich später untersuchen, welche Anpassungen vorgenommen werden!)
Was ist Optimierung? Wie bei Wikipedia wird das Finden des optimalen Status eines Programms als Optimierung bezeichnet. Hier wird die Optimierung durchgeführt, indem berechnet wird, wo der Fehler minimiert wird.
Ausführungsergebnis
Sehen wir uns das Ausführungsergebnis an.
***Testphase***
Richtige Antwortrate: 100.0 %
Ja, es ist 100%. Was 0% vor dem Lernen war, konnte sicher lernen.
Optimierung (von Ihnen selbst implementiert)
Das Herzstück des Prozesses ist der Optimierungsprozess, der von $ optimizer.step () $ ausgeführt wird. Es gibt viele Optimierungsmethoden, die mit Pytorch verwendet werden können, und dieses Mal habe ich SGD (Probabilistic Gradient Descent Method) gewählt.
Rückblick auf den bisher durchgeführten Optimierungsprozess Ich verwende nur eine Funktion, die bereits in pytorch implementiert ist, und mache nichts.
Wenn Sie eine Optimierungsmethode in Ihrem Papier implementieren möchten Was soll ich konkret tun?
... damit Zunächst werden wir als Beispiel eine einfache Optimierungsmethode namens "Sudden Descent Method (GD)" implementieren. Erstens ist die Methode des steilsten Abstiegs nicht praktikabel. Die Zeiten gehen von dem diesmal verwendeten SGD zurück. Ich bin jedoch der Meinung, dass es für das Studium geeignet ist Lassen Sie uns die Methode mit dem steilsten Abstieg implementieren.
Bild der Optimierung
Was ist Optimierung? Um ein intuitives Bild zu erhalten, drücken wir es in einer einfachen Formel aus. (Ich habe zum Zeitpunkt der Erstellung noch keine Artikel gelesen. Da es sich um ein Bild handelt, mache ich im engeren Sinne einen Fehler. Nur als Referenz ...)
y = f(x)
Als ich die Eingabedaten in das Netzwerk einfügte, kam der Merkmalswert als numerischer Wert zurück. Mit anderen Worten, wenn Sie die Eingabedaten $ x $ eingeben, wird $ y $ als Ausgabe zurückgegeben. Sei dies $ y = f (x) $.
gosa = |f(A)-f(B)|
Und wenn die Eingabedaten $ A $ und $ B $ für diese Formel angegeben werden, Ich möchte so einstellen, dass die Differenz der Mindestwert ist. Da A und B tatsächlich dieselben Daten sind, möchten wir dasselbe Ausgabeergebnis erhalten.
gosa(weight) = |g(A)-g(B)|\\
g(x) = weight * f(x)
Führen Sie nun den Parameter $ weight $ ein. Gewichten Sie die Netzwerkfunktion $ f (x) $. Das Problem, den Fehler durch Einführung dieser Formel minimieren zu wollen, ist Es ersetzt das Auffinden des Parameters $ weight $, der den Fehler minimieren kann.
Alles was Sie tun müssen, ist das $ weight $ zu finden, das $ gosa (weight) $ minimiert.
Optimieren Sie mit einem einfachen Diagramm
Lassen Sie uns mit einer einfachen Formel optimieren. Apropos Minimierungsproblem: Ich habe das Problem $ y = x ^ 2 $ gemacht, als ich in der Junior High School war. Zu diesem Zeitpunkt wurde der Mindestwert unter Verwendung einer sehr begrenzten Formel unter der Annahme einer manuellen Berechnung berechnet.
Unter der Annahme, dass $ y = x ^ 2 $ $ gosa (Gewicht) $ ist, Lösen wir es mit einer Optimierungsmethode, die als Methode mit dem steilsten Abstieg bezeichnet wird.
y = x^2\\
\frac{d}{dy}
=
2x
Das Differential $ \ frac {d} {dy} $ von $ y = x ^ 2 $ ist wie oben. Der Graph $ y = x ^ 2 $ ist ein Graph, der sich allmählich in der kleinsten Einheit von $ \ frac {d} {dy} $ ändert.
Die steilste Abstiegsmethode besteht darin, sich schrittweise durch eine kleine Änderung zu bewegen. Dies ist eine Methode, bei der der Punkt, an dem die Minutenänderung vollständig 0 ist, als Mindestwert betrachtet wird. (Als ich in der Junior High School war, gab es ein Problem, dass die Punkte, an denen die Neigung 0 wurde, das Minimum und Maximum waren.)
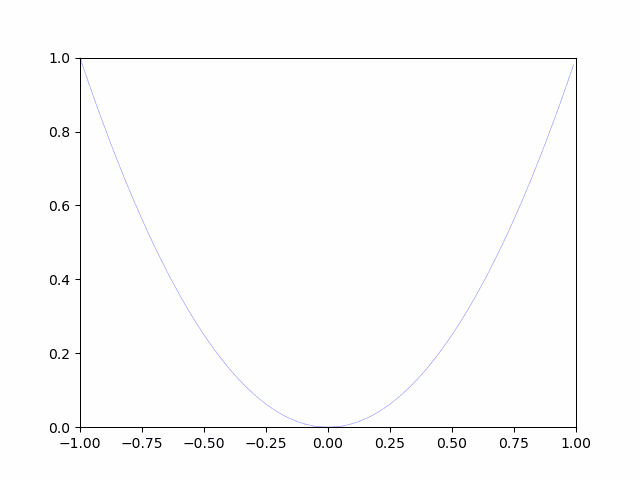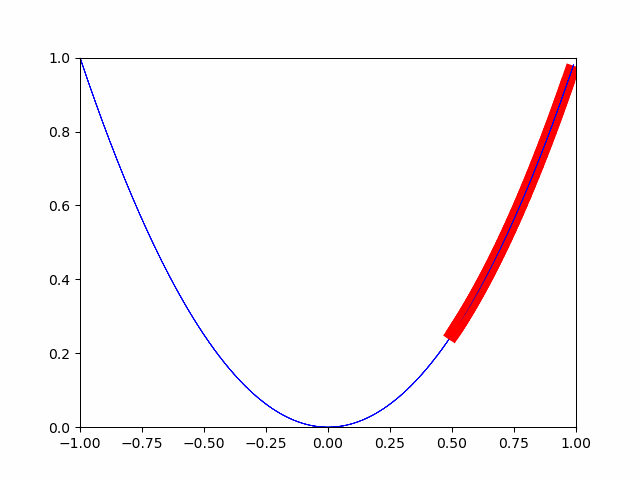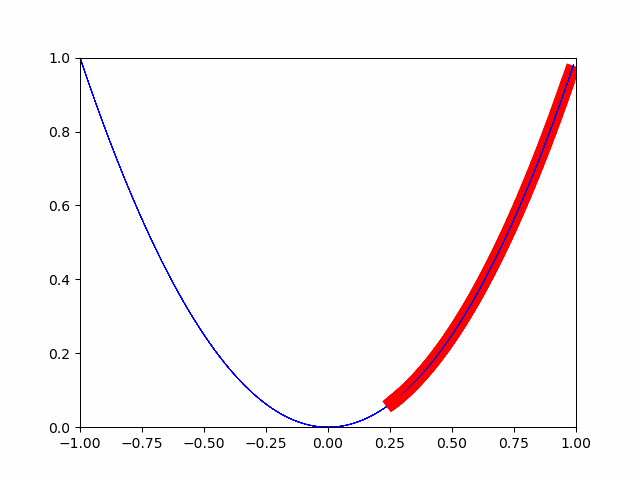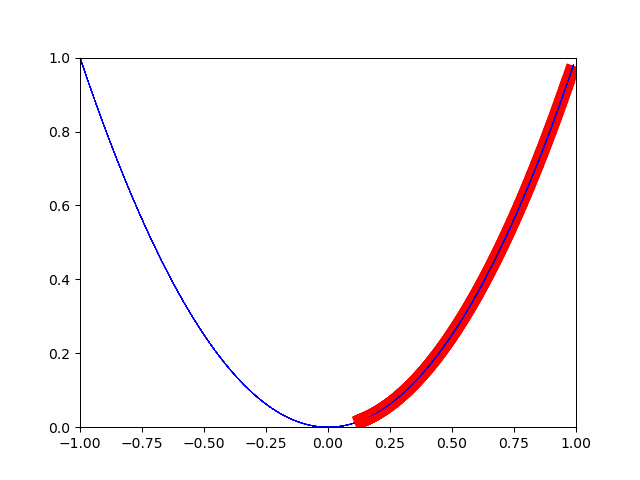
Versuchen wir also, die automatische Differenzierungsfunktion von pytorch zu verwenden.
Wie Sie auf dem Bild sehen können, nähert es sich allmählich dem Mindestwert. Auf diese Weise erfolgt die Optimierung für den Minimalwert.
Unten die Quelle.
test.py
if __name__ == '__main__':
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
def func(x):
return x[0] ** 2
fig, ax = plt.subplots()
artists = []
im, = ax.plot([], [])
#Grafikbereich
ax.set_xlim(-1.0, 1.0)
ax.set_ylim(0.0, 1.0)
# f = x*Zum Definieren von x
F_main = np.arange(-1.0, 1.0, 0.01)
n_epoch = 800 #Anzahl des Lernens
eta = 0.01 #Schrittweite
x_arr = []
f_arr = []
x_tor = torch.tensor([1.0], requires_grad=True)
for epoch in range(n_epoch):
#Definition der zu optimierenden Funktion
f = func(x_tor)
# x_Berechnen Sie die Steigung am Torpunkt
f.backward()
with torch.no_grad():
# 1.Gradientenmethode
# x_Subtrahieren Sie die winzigen Änderungen nach und nach vom Tor.
#Nähern Sie sich allmählich dem Mindestwert
x_tor = x_tor - eta * x_tor.grad
# 2.Dies ist die Verarbeitung für die Animation
f = x_tor[0] ** 2
x_arr.append(float(x_tor[0]))
f_arr.append(float(f))
x_tor.requires_grad = True
def update_anim(frame):
#Verfahren zum Speichern von GIF
#Nach der Ausführung von FuncAnimation wird es automatisch und wiederholt ausgeführt.(frame =Anzahl der Frames)
ims = []
if frame == 0:
y = f_arr[frame]
x = x_arr[frame]
else:
y = [f_arr[frame-1],f_arr[frame]]
x = [x_arr[frame-1],x_arr[frame]]
ims.append(ax.plot(F_main ,F_main*F_main,color="b",alpha=0.2,lw=0.5))
ims.append(ax.plot(x ,y,lw=10,color="r"))
# im.set_data(x, y)
return ims
anim = FuncAnimation(fig, update_anim, blit=False,interval=50)
anim.save('GD_Muster 1.gif', writer="pillow")
exit()
Implementierung der Optimierung (Methode mit dem steilsten Abstieg)
Ich werde versuchen, es umzusetzen. Der Zweck dieses Abschnitts besteht nicht darin, die Methode mit dem steilsten Abstieg selbst zu implementieren. Dies ist eine Bestätigung, um zu bestätigen, dass "auf diese Weise Ihre eigene Optimierungsfunktion implementiert wird".
Auch was lange geschrieben steht, so werde ich nur die Hauptpunkte schreiben.
test.py
optimizer = optim.SGD(Test_Conv.parameters(), lr=0.001, momentum=0.9)
In pytorch können Sie verschiedene Optimierungsmethoden aus optim auswählen. Implementierungen jeder Technik werden erstellt, indem eine Klasse namens $ torch.optim.Optimizer $ geerbt wird. Auf der anderen Seite können Sie ganz einfach Ihre eigene geerbte Klasse für $ torch.optim.Optimizer $ erstellen. Optimieren Sie also wie zuvor für $ y = x ^ 2 $.
In diesem Beispiel wird kein neutrales Netzwerk verwendet. Wenn ich $ SimpleGD $ auf die gleiche Weise definiere, kann es weiterhin in einem neutralen Netzwerk verwendet werden.
↓ ↓ ↓ Gesamtquelle ↓ ↓ ↓
test.py
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
class SimpleGD(torch.optim.Optimizer):
def __init__(self, params, lr):
defaults = dict(lr=lr)
super(SimpleGD, self).__init__(params, defaults)
@torch.no_grad()
def step(self, closure=None):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad
#Zugabe von Tensor
# p = p - d/dp(Kleine Veränderungen) * lr
# (lr wird multipliziert, weil der Änderungsbereich zu klein ist, wenn es sich nur um eine kleine Änderung handelt)
p.add_(d_p*-group['lr'])
return loss
def func(x):
return x[0] ** 2
fig, ax = plt.subplots()
artists = []
im, = ax.plot([], [])
#Grafikbereich
ax.set_xlim(-1.0, 1.0)
ax.set_ylim(0.0, 1.0)
# f = x*Zum Definieren von x
F_main = np.arange(-1.0, 1.0, 0.01)
n_epoch = 50 #Anzahl des Lernens
eta = 0.01 #Schrittweite
x_tor = torch.tensor([1.0], requires_grad=True)
param=[x_tor]
optimizer = SimpleGD(param, lr=0.1)
for epoch in range(n_epoch):
optimizer.zero_grad()
#Definition der zu optimierenden Funktion
f = func(x_tor)
# x_Berechnen Sie die Steigung am Torpunkt
f.backward()
optimizer.step()
x_tor.requires_grad = True
#Allmählich y=x*Mindestwert von x=0.Auf 0 gehen
# print(x_tor)
exit()
Von diesen das wichtigste Dies ist der Teil "class Simple GD", der Ihre eigene Optimierungsfunktion deklariert.
test.py
class SimpleGD(torch.optim.Optimizer):
def __init__(self, params, lr):
defaults = dict(lr=lr)
super(SimpleGD, self).__init__(params, defaults)
@torch.no_grad()
def step(self, closure=None):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad
#Zugabe von Tensor
# p = p - d/dp(Kleine Veränderungen) * lr
# (lr wird multipliziert, weil der Änderungsbereich zu klein ist, wenn es sich nur um eine kleine Änderung handelt)
p.add_(d_p*-group['lr'])
return loss
Lass uns genauer hinschauen. Zuerst über den Init-Teil.
test.py
def __init__(self, params, lr):
defaults = dict(lr=lr)
super(SimpleGD, self).__init__(params, defaults)
lr ist beim Subtrahieren von Minutenänderungen Wenn es sich nur um eine kleine Änderung handelt, ist der Änderungsbereich zu klein oder zu groß Die Parameter, die auf Minutenänderungen angewendet werden sollen, werden angegeben.
SimpleGD benötigt lr, also habe ich es hier deklariert. Wenn Sie andere Dinge benötigen, fügen Sie sie dem init-Argument hinzu und fügen Sie die Deklaration fest in das Diktat ein.
test.py
@torch.no_grad()
def step(self, closure=None):
Dies ist eine Funktion, die beim Erben der Klasse torch.optim.Optimizer deklariert werden muss. Die Optimierung erfolgt durch Aufrufen dieser Funktion während des Trainings.
self.param_groups sind die Parameter, die Sie beim Erstellen der SimpleGD-Instanz übergeben haben. Wenn der Gradient (kleine Änderung) bereits mit backward () berechnet wurde, können Sie den Gradienten auch von hier abrufen.
test.py
d_p = p.grad
#Zugabe von Tensor
# p = p - d/dp(Kleine Veränderungen) * lr
# (lr wird multipliziert, weil der Änderungsbereich zu klein ist, wenn es sich nur um eine kleine Änderung handelt)
p.add_(d_p*-group['lr'])
Holen Sie sich p.grad, das heißt, winzige Änderungen, Die Minutenänderung spiegelt sich in p = Tensor wider. Durch diesen Vorgang bewegen sich die Parameter allmählich in Richtung des Minimalwerts.
・ ・ ・ ・ Da die Methode mit dem steilsten Abstieg nur eine winzige Menge abzieht, fällt sie leicht in eine lokale Lösung. Lokale Lösung. Stellen Sie sich ein Diagramm mit vielen Unebenheiten wie $ y = x ^ 2 $ vor. Da bei der Methode mit dem steilsten Abstieg der Ort, an dem die Neigung 0 wird, als Mindestwert betrachtet wird, Immer wenn es eine der Spitzen dieser konvexen erreicht, wird es als extremer Wert angesehen.
Daraus lässt sich ableiten, dass diese Methode für keine Daten robust ist.
abschließend
In den Kapiteln 1 und 2 habe ich einen kleinen Überblick über das Netzwerk bekommen.
Wie für den Zeitplan nach dem nächsten Mal, Studieren des maschinellen Lernens des Punktgruppensystems, das ich am meisten studieren wollte, Studieren Sie besonders PointNet.
Danach werde ich RNN, Auto Encoder, GAN und DQN studieren.
Recommended Posts