[PYTHON] Rekursives neuronales Netzwerk: Eine Einführung in RNN
Rekursive Neuronale Netze (RNNs) waren auf dem Gebiet der Verarbeitung natürlicher Sprache sehr erfolgreich und sind derzeit einer der heißesten Algorithmen. Ich denke jedoch, dass es nur eine begrenzte Anzahl von Büchern gibt, die erklären, wie RNN tatsächlich funktioniert und wie man es baut, bevor es populär wird. Dieser Beitrag konzentrierte sich auf diesen Teil und wurde mit meinem Freund Denny (Autor von WildML Blog) geschrieben.
Jetzt möchte ich das RNN-basierte Sprachmodell erklären. Das Sprachmodell hat zwei Verwendungszwecke. Die erste ist zu bewerten, wie wahrscheinlich es ist, dass ein Satz tatsächlich erscheint. Diese Punktzahl ist ein Kriterium für die grammatikalische und semantische Korrektheit. Solche Modelle werden beispielsweise bei der maschinellen Übersetzung verwendet. Zweitens kann das Sprachmodell neuen Text generieren (ich persönlich denke übrigens, dass es eine coolere Verwendung ist). Auch wenn es auf Englisch ist, erklärt und entwickelt Andrej Karpathys Blog ein RNN-Sprachmodell auf Wortebene, daher braucht es Zeit. Wenn Sie eine haben, lesen Sie diese bitte.
Der Leser geht davon aus, dass die rudimentären Dinge über neuronale Netze unterdrückt werden. Wenn nicht, [Erstellen wir mit Python ein neuronales Netzwerk ohne Verwendung einer Bibliothek](http://blog.moji.ai/2015/12/python% e3% 81% a7% e3% 83% a9 % e3% 82% a4% e3% 83% 96% e3% 83% a9% e3% 83% aa% e3% 83% bc% e3% 82% 92% e4% bd% bf% e3% 82% 8f% e3 % 81% 9a% e3% 81% ab% e3% 80% 81% e3% 83% 8b% e3% 83% a5% e3% 83% bc% e3% 83% a9% e3% 83% ab% e3% 83 Bitte lesen Sie% 8d% e3% 83% 83% e3% 83% 88 /). In diesem Beitrag wird ein nicht rekursives Netzwerkmodell erläutert und erstellt.
Was ist RNN (Recurrent Neural Network)?
Der Vorteil von RNN besteht darin, dass Sie fortlaufende Informationen wie Sätze verwenden können. Die traditionelle Idee neuronaler Netze ist nicht so, vorausgesetzt, die Eingabedaten (und die Ausgabedaten) sind unabhängig voneinander. Diese Annahme ist jedoch oft falsch. Wenn Sie beispielsweise das nächste Wort vorhersagen möchten, sollten Sie wissen, was das vorherige Wort war, oder? R in RNN bedeutet Wiederkehrend, wodurch Sie unabhängig von der vorherigen Berechnung für jedes kontinuierliche Element dieselbe Arbeit ausführen können. Mit anderen Worten, RNN hat den Speicher, um sich zuvor berechnete Informationen zu merken. Theoretisch kann RNN sehr lange Textinformationen verwenden. Wenn ich es jedoch tatsächlich implementiere, kann ich mich nur an die Informationen von vor einigen Schritten erinnern (ich werde weiter unten näher auf diese Angelegenheit eingehen). Schauen wir uns nun eine allgemeine RNN in der folgenden Tabelle an.
 A recurrent neural network and the unfolding in time of the computation involved in its forward computation. Source: Nature
A recurrent neural network and the unfolding in time of the computation involved in its forward computation. Source: Nature
Das obige Diagramm wird innerhalb des RNN erweitert. Bereitstellen bedeutet einfach, ein bestelltes Netzwerk zu schreiben. Wenn Sie beispielsweise einen Satz aus 5 Wörtern haben, ist das erweiterte Netzwerk ein 5-Schicht-Neuronales Netzwerk mit 1 Schicht und 1 Wort. Die Formel zur Berechnung der RNN lautet wie folgt.
$ x_t $ ist die Eingabe für den Schritt $ t $. Zum Beispiel ist $ x_1 $ ein Vektor, der den folgenden Wörtern zugeordnet ist: $ s_t $ ist ein verstecktes Element während des $ t $ -Schritts. Dies ist der Speicher des Netzwerks. $ s_t $ wird basierend auf dem vorherigen versteckten Element berechnet. Und die Eingabe in diesem Schritt ist $ s_t = f (U x_x + W s_ {t-1}) $. Zu den $ f $ -Funktionen gehören tanh und ReLU Nichtlinearer Typ ist üblich. Das $ s_ {-1} $, das zur Berechnung des ersten versteckten Elements benötigt wird, beginnt normalerweise bei 0. $ o_t $ ist die Ausgabe im Schritt $ t $. Wenn Sie beispielsweise die folgenden Wörter vorhersagen möchten, ist $ o_t $ ein Vektor von Vorhersagewahrscheinlichkeiten ($ o_t = softmax (V s_t) $).
Was RNN kann
RNN hat bereits viele Erfolgsgeschichten auf dem Gebiet der Verarbeitung natürlicher Sprache hinter sich. Nachdem wir ein wenig über RNNs verstanden haben, werden wir eine der am häufigsten verwendeten RNNs vorstellen, LSTM. LSTM kann entfernte Schrittbeziehungen besser lernen als RNN. Keine Sorge, LSTM hat im Grunde die gleiche Algorithmusstruktur wie das diesmal zu erstellende RNN. Der einzige Unterschied besteht in der Art und Weise, wie die verborgenen Elemente berechnet werden. Wir planen, LSTM in Zukunft zu behandeln. Wenn Sie interessiert sind, registrieren Sie sich bitte für den E-Mail-Newsletter.
Sprachmodell und Satzgenerierung
Das Sprachmodell kann die Erscheinungswahrscheinlichkeit des nächsten Wortes vorhersagen, indem das vorherige Wort in einer Reihe von Wörtern verwendet wird. Es wird für die maschinelle Übersetzung verwendet, da es messen kann, wie oft Sätze erscheinen. Eine weitere gute Sache, um das nächste Wort vorhersagen zu können, ist, dass Sie ein generatives Modell erhalten können, das neue Sätze durch Stichproben aus der Wahrscheinlichkeit der Ausgabe generieren kann. Daher ist es möglich, abhängig von den Trainingsdaten verschiedene Dinge zu generieren. Im Sprachmodell sind die Eingabedaten eine kontinuierliche Folge von Wörtern. Und die Ausgabe wird eine Folge von vorhergesagten Wörtern sein. Wenn wir das Netzwerk trainieren, möchten wir, dass die Ausgabe des $ t $ -Schritts die folgenden Wörter enthält, also setzen wir $ o_t = x_ {t + 1} $.
Obwohl es auf Englisch sein wird, ist das Folgende eine Referenz für Artikel über Sprachmodelle und Texterzeugung.
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
Maschinenübersetzung
Die maschinelle Übersetzung ähnelt dem Sprachmodell dahingehend, dass Sätze in der Ausgangssprache (z. B. Japanisch) als Eingabe verwendet werden. Und die Ausgabe sind zum Beispiel englische Sätze. Der Unterschied zum Sprachmodell besteht darin, dass die Ausgabedaten nach dem Lesen der vollständigen Eingabedaten mit der Verarbeitung beginnen. Daher benötigt das erste Wort des übersetzten Satzes die Information des vollständigen Eingabesatzes.
 RNN for Machine Translation. Image Source: http://cs224d.stanford.edu/lectures/CS224d-Lecture8.pdf
RNN for Machine Translation. Image Source: http://cs224d.stanford.edu/lectures/CS224d-Lecture8.pdf
Obwohl es auf Englisch ist, ist das Folgende eine Referenz für Artikel zur maschinellen Übersetzung.
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
Spracherkennung
Unter Verwendung eines kontinuierlichen akustischen Signals von einer Schallquelle als Eingabe wird ein kontinuierliches Sprachsegment wahrscheinlich vorhergesagt.
Obwohl es auf Englisch sein wird, ist das Folgende eine Referenz für Artikel zur Spracherkennung.
Generierung von Bildzusammenfassungen
Sie können Convolutional Neural Networks und RNN verwenden, um eine Übersicht über ein unbeschriftetes Bild zu erstellen. Wie Sie aus dem Bild unten sehen können, ist es möglich, eine Zusammenfassung mit einer ziemlich hohen Wahrscheinlichkeit zu erstellen.
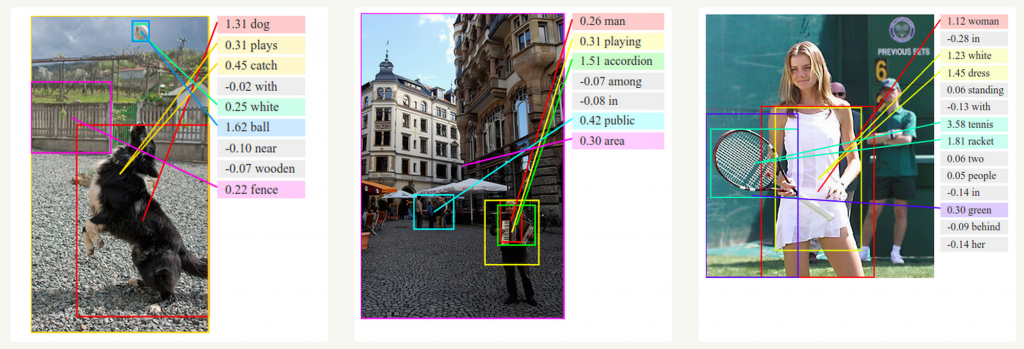
Deep Visual-Semantic Alignments for Generating Image Descriptions. Source: http://cs.stanford.edu/people/karpathy/deepimagesent/
Zug RNN
Das Erlernen von RNN ähnelt dem Trainieren eines herkömmlichen neuronalen Netzwerks, für RNN verwenden wir jedoch einen etwas anderen Backpropagation-Algorithmus. Da die RNN-Parameter in jedem Schritt im Netzwerk verwendet werden, verwendet der schrittweise Gradient die Berechnung des vorherigen Schritts sowie die Berechnung des aktuellen Schritts. Um beispielsweise den Gradienten von $ t = 4 $ zu berechnen, müssen Sie 3 Schritte zurückgehen und die Gradienten hinzufügen. Dies wird als Back Propagation Through Time (BPTT) bezeichnet. Wenn Sie nicht verstehen, was es bedeutet, machen Sie sich keine Sorgen. Ich werde die Details in einem späteren Beitrag schreiben. Denken Sie vorerst daran, dass RNNs, die mit BPTT trainiert wurden, umso schwieriger zu trainieren sind, je weiter sie entfernt sind. Ein LSTM-ähnlicher Algorithmus (eine Art RNN) wurde entwickelt, um dieses Problem zu lösen.
Anwendung von RNN
Jüngste Forschungsanstrengungen haben zur Entwicklung komplexerer RNN-Modelle geführt, mit denen die Mängel traditioneller RNNs beseitigt werden können. Ich werde das in einem zukünftigen Beitrag erklären, aber in diesem Beitrag werde ich Ihnen eine kurze Einführung geben.
Bidirectional RNN In Bidirectional RNN wird die Ausgabe von $ t $ nicht nur basierend auf dem unmittelbar vorhergehenden Element, sondern auch basierend auf dem nachfolgenden Element berechnet. Wenn Sie beispielsweise Wörter vorhersagen, die im vorherigen Teil nicht vorkommen, sollte die Wahrscheinlichkeit einschließlich der letzteren Wörter berechnet werden. Stellen Sie sich ein bidirektionales RNN als eine Überlappung zweier RNNs vor. Die Ausgabe wird aus zwei versteckten Elementen berechnet.

Deep (Bidirectional) RNN Deep RNN ähnelt Bidirectional RNN, hat jedoch mehrere Schichten pro Schritt. Wenn Sie versuchen, es zu implementieren, erhalten Sie eine höhere Lernfähigkeit (obwohl Sie immer noch viele Lerndaten benötigen).
LSTM-Netzwerk
Wie ich bereits erwähnt habe, ist das LSTM-Netzwerk heutzutage eines der beliebtesten RNNs. LSTM hat im Grunde die gleiche Struktur wie RNN, führt jedoch eine andere Funktion zur Berechnung versteckter Elemente durch. Der LSTM-Speicher heißt Cell und kann als Black Box mit dem vorherigen Element $ h_ {t-1} $ und dem aktuellen Element $ x_t $ als Eingaben betrachtet werden. Wählen Sie in der Blackbox die Zelle aus, die im Speicher gespeichert werden soll. Kombinieren Sie dann das vorherige Element, das aktuelle Element und die Eingabe. Infolgedessen ist es möglich, die Beziehungen zwischen weit voneinander entfernten Wörtern erfolgreich zu extrahieren. LSTM ist etwas schwer zu verstehen, aber wenn Sie interessiert sind, ist es auf Englisch, aber die Erklärung von hier ist leicht zu verstehen. schauen Sie bitte.
Recommended Posts