[PYTHON] Datenanalyse zur Verbesserung von POG 2 ~ Analyse mit Jupiter-Notebook ~
Rückblick bis zum letzten Mal
Die Datenanalyse zur Verbesserung des POG 1 ~ Web Scraping mit Python ~ zeigt das Profil von Pferden, die zwischen 2010 und 2013 geboren wurden (Geschlecht, Stammbaum, Stall). Usw.) und gewann Preise während der POG-Periode. Die erhaltenen Daten werden für jedes Geburtsjahr separat unter dem Dateinamen "Horse_TB / Horse_Prof_ (JJJJ) .csv" gespeichert.
Zweck dieser Zeit
Basierend auf diesen Daten möchte ich dieses Mal den Kausalzusammenhang zwischen dem Pferdeprofil und den während des POG-Zeitraums gewonnenen Preisen analysieren und das Gesetz des POG-Gewinns finden.
Leider bin ich kein Datenanalysespezialist. Daher wird es möglich sein, durch Versuch und Irrtum einige Schlussfolgerungen zu ziehen. Letztendlich wird erwartet, dass die multiple Regressionsanalyse und das maschinelle Lernen berücksichtigt werden, aber zuerst möchte ich die Eigenschaften jedes Faktors durch einfache Analyse verstehen.
Datenanalyse
Dieses Mal werden wir mit der Analyse auf einem Jupyter-Notebook fortfahren, das für die Datenanalyse einschließlich Versuch und Irrtum geeignet zu sein scheint. Zusätzlich wird das Pandas-Modul verwendet, um Statistiken (Mittelwert, Varianz usw.) für jeden Faktor zu berechnen.
Vorbereitung
Zunächst wird ein zu analysierender Datenrahmen erzeugt.
AnalyseUmaData_160105.ipynb
import os
import pandas as pd
year_l = range(2010, 2014)
masta_df = pd.DataFrame()
for year in year_l:
i_dname = './horse_db/'
i_fname = 'horse_prof_%d.csv' % year
i_fpath = os.path.join(i_dname, i_fname)
tmp_df = pd.read_csv(i_fpath,index_col=0, header=0, encoding='utf-8')
masta_df = pd.concat([masta_df, tmp_df])
masta_df[:10]
Ein Teil des generierten Datenrahmens ist unten dargestellt.
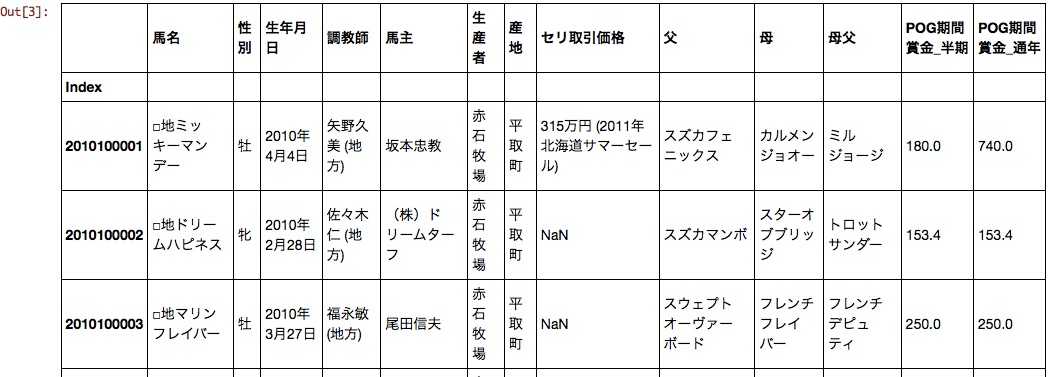
Geschlecht, Geburtsdatum, Trainer, Pferdebesitzer, Produzent, Seri-Transaktionspreis, Vater, Mutter und Vater beeinflussen wahrscheinlich den POG-Preis.
Da es so ist, sind das Geburtsdatum und der Seri-Transaktionspreis schwer zu handhaben, deshalb werde ich es ein wenig formen.
AnalyseUmaData_160105.ipynb
import datetime
#Geburtstag=>Geburtsjahr, Geburtsmonat
birth_y = masta_df[u'Geburtstag'].dropna().map(lambda x: datetime.datetime.strptime(x.encode('utf-8'), '%Y Jahr%m Monat%d Tag').strftime('%Y'))
birth_y.name = u'Geburtsjahr'
birth_m = masta_df[u'Geburtstag'].dropna().map(lambda x: datetime.datetime.strptime(x.encode('utf-8'), '%Y Jahr%m Monat%d Tag').strftime('%m'))
birth_m.name = u'Geburtsmonat'
df = pd.concat([masta_df, birth_y, birth_m], axis=1)
#Seri Transaktionspreis Zeichenfolge=>Quantifizieren
df[u'Seri Transaktionspreis'] = masta_df[u'Seri Transaktionspreis'].fillna('-1')
df[u'Seri Transaktionspreis'] = df[u'Seri Transaktionspreis'].dropna().map(lambda x: x.replace(',', ''))
df[u'Seri Transaktionspreis'] = df[u'Seri Transaktionspreis'].dropna().map(lambda x: int(x.split(u'Zehntausend Yen')[0]))
df[:10]
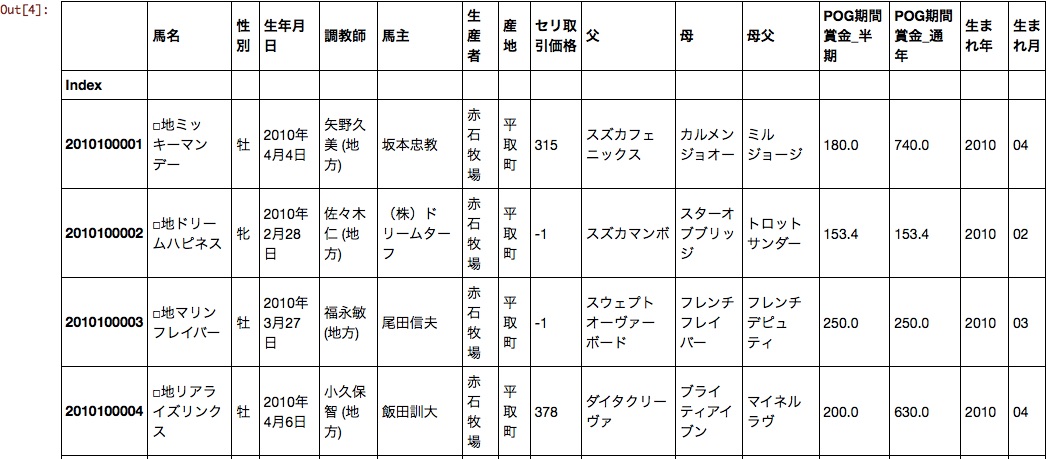
Das Geburtsdatum wurde in das Geburtsjahr und den Geburtsmonat unterteilt. Jetzt können Sie den Transaktionspreis, das Geburtsjahr und den Geburtsmonat als numerische Daten behandeln.
Analyse
Beginnen wir sofort mit der Analyse. Aufgrund von Versuch und Irrtum wurde das Datenaggregationsskript in der folgenden Form festgelegt.
AnalyseUmaData_160105.ipynb
import numpy as np
#Erklärende Variable
param_l = [u'Sex', u'Geburtsmonat', u'Trainer', u'Pferdebesitzer', u'Produzent', u'Vater', u'母Vater']
#Objektive Variable
prize_l = [u'POG-Preis_halbe Periode',u'POG-Preis_Das ganze Jahr']
#Aufbau
param = param_l[0]
prize = prize_l[1]
pts_filter = 5
prize_filter = 1000 #Preisfilter
#Aggregat
ser_ave = df.groupby(param).mean()[prize]
ser_ave.name = u'prize>=0_ave'
ser_std = df.groupby(param).std()[prize]
ser_std.name = u'prize>=0_std'
ser_pts = df.groupby(param).size()
ser_pts.name = u'prize>=0_pts'
ser_fave = df[df[prize]>=prize_filter].groupby(param).mean()[prize]
ser_fave.name = u'prize>=%d_ave' % prize_filter
ser_fstd = df[df[prize]>=prize_filter].groupby(param).std()[prize]
ser_fstd.name = u'prize>=%d_std' % prize_filter
ser_fpts = df[df[prize]>=prize_filter].groupby(param).size()
ser_fpts.name = u'prize>=%d_pts' % prize_filter
ser_fper = (df[df[prize]>=prize_filter].groupby(param).size()/df.groupby(param).size()).map(lambda x: float(x)*100)
ser_fper.name = u'prize>=%d_pts / prize>=0_pts [%%]' % prize_filter
result = pd.concat([ser_ave, ser_std, ser_pts, ser_fave, ser_fstd, ser_fpts, ser_fper],axis=1)
result.index.name = '%s_%s' % (param, prize)
result = np.round(result.sort_values(by=ser_fper.name, ascending=0),2)
result[result[ser_fpts.name] >= pts_filter][:10]
In jeder Spalte beträgt der Preis 0 oder mehr, dh der Durchschnittswert, die Streuung und die Punktzahl, wenn alle Pferde die Population sind. Durchschnittswert, Varianz, Punktzahl, wenn der Preis 10 Millionen oder mehr Pferde als Population beträgt Es zeigt auch den Prozentsatz der Pferde mit Preisen von 10 Millionen oder mehr.
Sex
Das Ergebnis war Senmas Vorteil, aber es ist ungewiss, ob er während der POG-Zeit Senma war. Zumindest das weibliche Pferd erweist sich als benachteiligt.

Geburtsmonat
Je früher du geboren bist, desto besser.
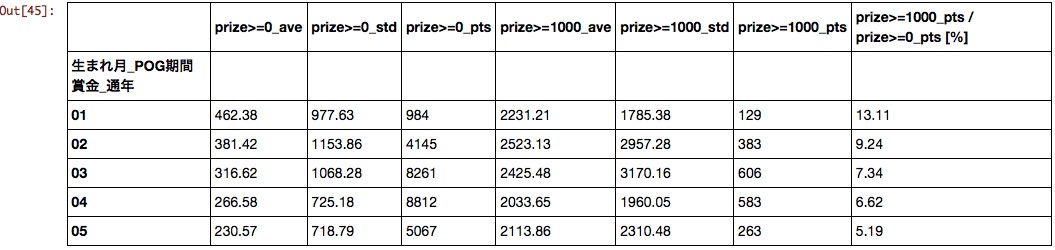
Trainer
Ich bin der Meinung, dass sich das Ranking je nach Einstellung des Preisfilters so weit wie möglich ändern wird. Bei einer Sortierung von 10 Millionen oder mehr wurden jedoch die folgenden Ergebnisse erzielt.
Es ist schade, dass die Matsupaku-Ställe, die im Februar 2016 in den Ruhestand gehen sollen, an erster Stelle standen.
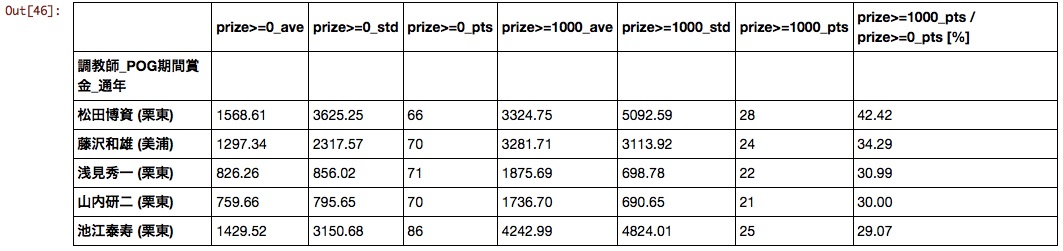
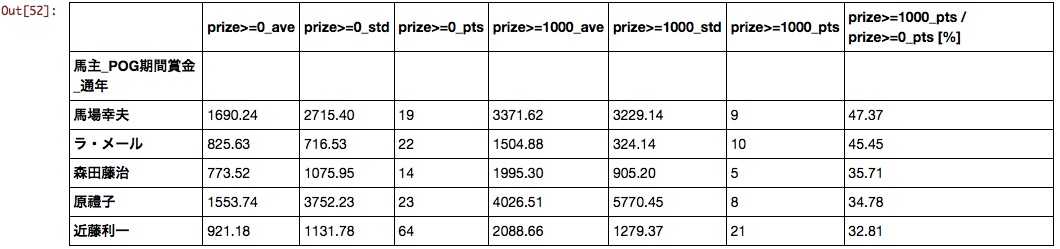
Pferdebesitzer
Überraschenderweise sind Vereine, die in G1 aktive Pferde produzieren, nicht an die Spitze gekommen. Gibt es einen großen Unterschied zwischen Hit und Miss bei Clubpferden?
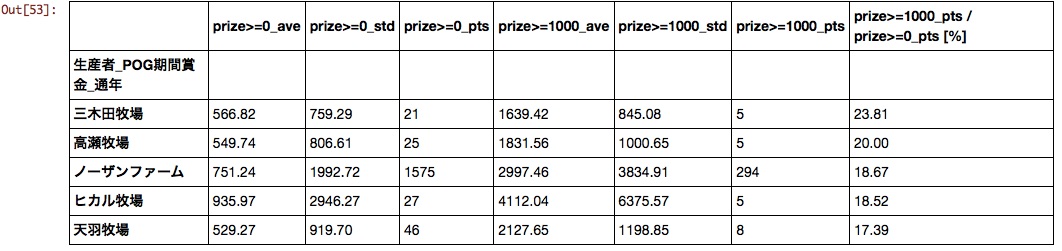
Produzent
Bis jetzt hatte ich Pferde mit der Idee "Northern Farm vorerst, wenn ich mich verlaufen habe" ausgewählt, aber ich habe Daten erhalten, die bestätigen, dass es eine vernünftige Idee ist.
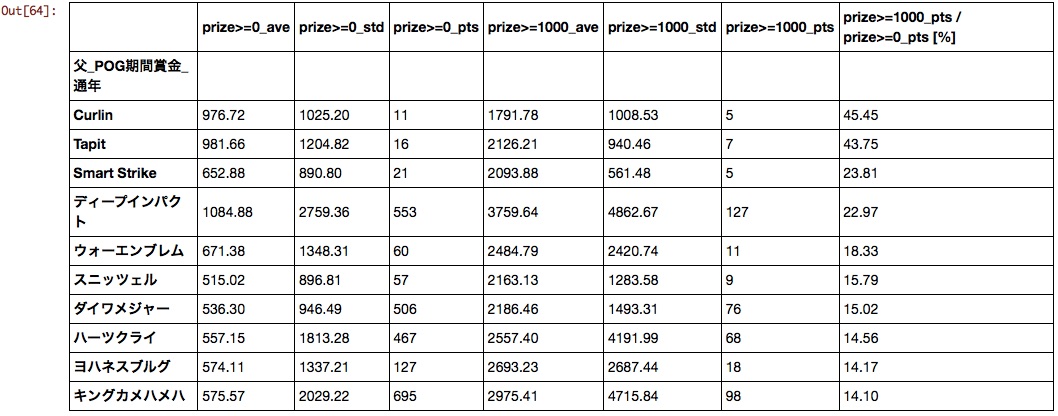
Vater
Unbekannte Pferde aus Übersee kamen an die Spitze. In Anbetracht der Bevölkerung und der Durchschnittswerte kann gesagt werden, dass Deep, Da Major, Hearts und Kinkame für POG sind.
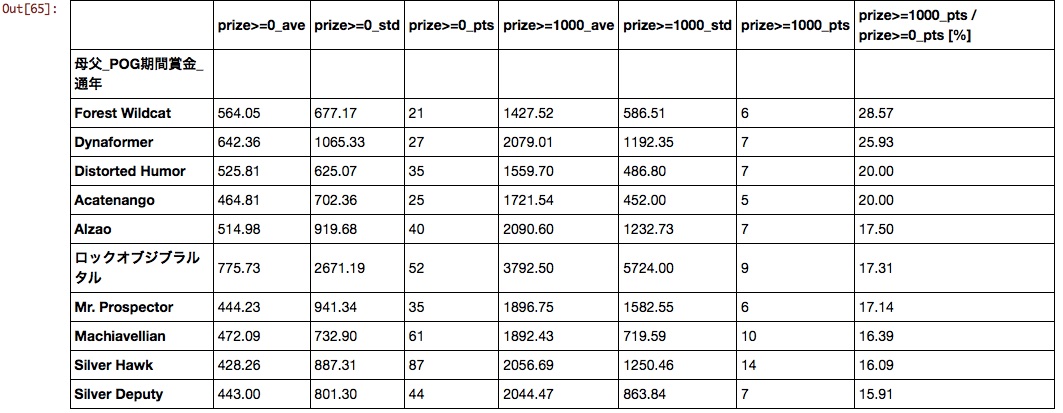
Mutter Vater
Ich weiß nicht mehr was es ist. In den letzten Jahren scheint es notwendig, die Kombination von Vater und Mutter neu zu bewerten, da die guten Ergebnisse von Pferden, die aus der Kombination von "Stay Gold" x "Mejiro McQueen" und "Deep Impact" x "Storm Cat" geboren wurden, zu einem heißen Thema geworden sind.
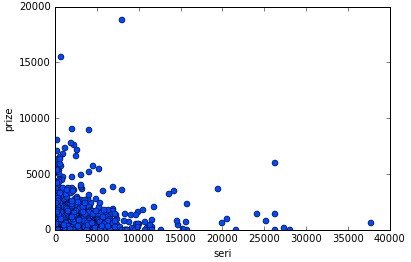
Seri Transaktionspreis
Horizontale Achse: Seri-Transaktionspreis, vertikale Achse: Preisstreudiagramm für den POG-Zeitraum wurde erstellt. Es scheint, dass Sie sich keine Sorgen um den Seri-Transaktionspreis in POG machen müssen, da keine signifikante Korrelation gefunden werden kann.
AnalyseUmaData_160105.ipynb
%matplotlib inline
import matplotlib.pyplot as plt
#Erklärende Variable
param = u'Seri Transaktionspreis'
#Objektive Variable
prize_l = [u'POG-Preis_halbe Periode',u'POG-Preis_Das ganze Jahr']
prize = prize_l[1]
#Streudiagramm
x = df[df[param]>0][param]
y = df[df[param]>0][prize]
plt.plot(x, y, linestyle='None', marker='o')
plt.xlabel('seri')
plt.ylabel('prize')
plt.show()
Diese Zusammenfassung
Zusammenfassend lässt sich sagen, dass Sie ein Pferd auswählen können, das mit einer angemessenen Wahrscheinlichkeit gewinnt, wenn Sie ein Pferd auswählen, das ein frühgeborener Hengst ist und ein Produktionsstück von Deep Impact, Daiwa Major, Hearts Cry oder King Kamehameha ist und einem einzelnen Besitzer gehört. Es stellt sich heraus, dass es ist.
In dieser Analyse gibt es jedoch noch Verbesserungspotenzial, beispielsweise die Tatsache, dass die Preisschwelle auf 10 Millionen festgelegt wurde und die Auswirkung der Kombination der einzelnen Faktoren nicht überprüft werden konnte, sodass keine einfache Schlussfolgerung gezogen werden kann. Basierend auf diesem Ergebnis erscheint es notwendig, die Analysemethode selbst zu überprüfen.
von jetzt an
Arbeiten Sie an Datenvisualisierung, multipler Regressionsanalyse, maschinellem Lernen usw.
Recommended Posts