Praktische Übung zur Datenanalyse mit Python ~ 2016 New Coder Survey Edition ~
Einführung
Üben Sie das Arbeiten mit Daten mithilfe von Bibliotheken wie Python und Numpy, Pandas und Seaborn. Die Daten verwenden die Daten von kaggle. Dieses Mal werden wir die Daten aus 2016 New Coder Survey verwenden. Der Inhalt der Daten ist wie folgt. Einfach ausgedrückt, es sind Daten darüber, wer das Codieren lernt.
Free Code Camp is an open source community where you learn to code and build projects for nonprofits.
CodeNewbie.org is the most supportive community of people learning to code.
Together, we surveyed more than 15,000 people who are actively learning to code. We reached them through the twitter accounts and email lists of various organizations that help people learn to code.
Our goal was to understand these people's motivations in learning to code, how they're learning to code, their demographics, and their socioeconomic background.
Als Voraussetzung wird es auch auf einem ipython-Notebook ausgeführt. Die Version ist pyenv: anaconda3-2.4.0 (Python 3.5.2 :: Anaconda 2.4.0) ist.
Wenn Sie mit diesem Bereich vertraut sind, würden wir uns freuen, wenn Sie sich den Inhalt genau ansehen und uns Ratschläge geben könnten, wenn Sie etwas bemerken. Ich wäre Ihnen dankbar, wenn Sie etwas wie "Ich würde diese Art von Analyse durchführen, wenn ich diese Daten verwenden würde" kommentieren könnten! (Es ist hilfreich, wenn Sie die Codebasis verwenden können!)
Bibliotheksimport
Lesen Sie diejenigen, von denen Sie glauben, dass Sie sie verwenden werden.
import numpy as np
from numpy.random import randn
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Daten lesen
Ich habe die Daten von 2016 New Coder Survey heruntergeladen und in denselben Ordner mit dem Namen "code_survey.csv" gestellt.
survey_df = pd.read_csv('corder_survey.csv')
Datenübersicht
shape
survey_df.shape
(15620, 113)
Das war's. Es gibt einige Artikel. Die Anzahl der Zeilen beträgt 15620 (die Anzahl der Personen, auf die Daten abzielen) und die Anzahl der Spalten (Antwortelemente) beträgt 113.
info Möglicherweise möchten Sie auch Informationen verwenden.
survey_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 15620 entries, 0 to 15619
Columns: 113 entries, Age to StudentDebtOwe
dtypes: float64(85), object(28)
memory usage: 13.5+ MB
describe
survey_df.describe()
In jeder Spalte werden Informationen wie "Anzahl", "Mittelwert", "Standard", "Min", "25%", "50%", "75%" und "Max" angezeigt. Daten werden weggelassen, weil zu viele Daten vorhanden sind.
Spaltenprüfung
for col in survey_df.columns:
print(col)
Jetzt habe ich alle 113 Artikel angezeigt. Da dies eine Übung ist, werde ich die Spalten verwenden, die zuerst verwendet werden sollen.
Gender:Sex
HasChildren:Mit oder ohne Kinder
EmploymentStatus:Aktuelle Beschäftigungsform
Age:Alter
Income:Einkommen
HoursLearning:Lernzeit
SchoolMajor:Haupt
Übersicht über jeden Artikel
Gender
countplot
Beginnen wir mit den Geschlechtsdaten. Lassen Sie uns ein Histogramm machen. Seaborn Count Plot ist nützlich.
sns.countplot('Gender', data=survey_df)

In Japan scheinen Männer und Frauen geteilt zu sein, aber es gibt Vielfalt und es scheint in Übersee zu sein.
Für ein einfaches Histogramm gibt es übrigens "plt.hist" in matplotlib. (Es gibt auch "plt.bar", das ein Balkendiagramm erstellt, aber "plt.hist" ist einfach, wenn ein Histogramm aus der Häufigkeitsverteilung von Daten erstellt wird.
dataset = randn(100)
plt.hist(dataset)
(Randn generiert Zufallszahlen gemäß der Normalverteilung)

Es gibt auch verschiedene Möglichkeiten.
# normed:Normalisierung, alpha:Transparenz, color:Farbe, bins:Anzahl der Behälter
plt.hist(dataset, normed=True, alpha=0.8, color='indianred', bins=15)
HasChildren
Versuchen Sie in ähnlicher Weise, mit oder ohne Kinder mit dem Zählplot zu zeichnen.
sns.countplot('HasChildren', data=survey_df)
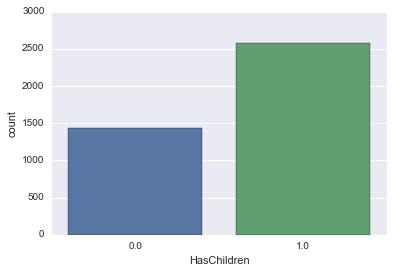
Wenn es 0 oder 1 ist, ist es schwer zu verstehen, also sagen wir "Nein" ohne Kinder und "Ja" mit Kindern.
survey_df['HasChildren'].loc[survey_df['HasChildren'] == 0] = 'No'
survey_df['HasChildren'].loc[survey_df['HasChildren'] == 1] = 'Yes'
Sie können jetzt konvertieren.
df.map
Die Konvertierung mit Karte scheint gut zu sein.
survey_df['HasChildren'] = survey_df['HasChildren'].map({0: 'No', 1: 'Yes'})
sns.countplot('HasChildren', data=survey_df)
sns.countplot('HasChildren', data=survey_df)

Es ist etwas einfacher zu verstehen!
EmploymentStatus
Ich werde auch das aktuelle Beschäftigungsformular mit "Zählplot" ausdrücken.
sns.countplot('EmploymentStatus', data=survey_df)

Es ist irgendwie chaotisch und schwer zu verstehen. ..
Ändern wir also die Achse.
Countplot Achsenwechsel
sns.countplot(y='EmploymentStatus', data=survey_df)
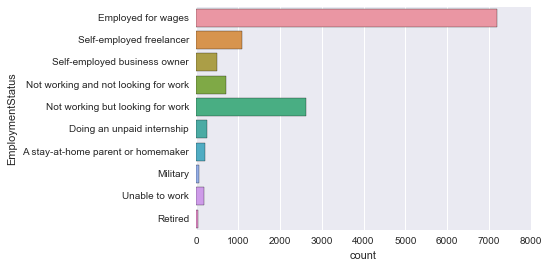
Einfach zu sehen!
Age
Versuchen Sie es erneut mit "count plot".
sns.countplot('Age', data=survey_df)

Es ist bunt und schön, aber als Grafik schwer zu erkennen.
Glätten wir also das Diagramm.
kde plot
Verwenden Sie die Kernel-Dichteschätzung (kde: Kernel-Dichtediagramm). Die Methode selbst ist einfach.
sns.kdeplot(survey_df['Age'])

Es gibt viele Menschen in ihren 20ern und 30ern. Ist es genau so, wie Sie es erwarten würden? Der Saum verbreitert sich jedoch auch dann, wenn Sie etwas älter werden.
Schätzung der Kerneldichte
Betrachten wir nun eine kleine Schätzung der Kerneldichte. (Wenn Sie sich Wikipedia und andere Websites ansehen, sehen Sie eine angemessene Erklärung.) [Schätzung der Kerneldichte](https://ja.wikipedia.org/wiki/%E3%82%AB%E3%83%BC%E3%83%8D%E3%83%AB%E5%AF%86%E5 % BA% A6% E6% 8E% A8% E5% AE% 9A)
dataset = randn(30)
plt.hist(dataset, alpha=0.5)
sns.rugplot(dataset)
Das Teppichplot zeigt jeden Probenpunkt mit einem Balken.

Dies ist ein Bild der Erstellung einer Kernelfunktion (die leicht zu verstehen ist, wenn Sie eine Normalverteilung als Beispiel betrachten) für jeden Beispielpunkt in diesem Diagramm und deren Addition.
sns.kdeplot(dataset)
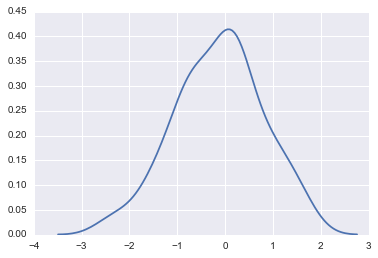
Bei der Schätzung der Kerneldichte
- Kernelfunktion: So verteilen Sie den Einfluss jedes Stichprobenpunkts --Bandwidth: Breite der Verbreitung von Kernelfunktionen
Sie müssen sich für zwei Dinge entscheiden.
Kernelfunktion
Sie können auch verschiedene Kernelfunktionen verwenden. Der Standardwert ist Gau (Gaußsche Verteilung, Normalverteilung).
kernel_options = ["gau", "biw", "cos", "epa", "tri", "triw"]
for kernel in kernel_options:
sns.kdeplot(dataset, kernel=kernel, label=kernel)

Bandbreite
Die Bandbreite kann ebenfalls geändert werden.
for bw in np.arange(0.5, 2, 0.25):
sns.kdeplot(dataset, bw=bw, label=bw)

Bisher wird die Erklärung der Kernel-Dichteschätzung getrennt, und dann werden wir fortfahren.
Income
Verwenden Sie wieder kdeplot.
sns.kdeplot(survey_df['Income'])

Die Einheit ist Dollar, es ist also ein Jahreseinkommen.
Schauen wir uns die Daten genauer an.
describe
survey_df['Income'].describe()
RuntimeWarning: Invalid value encountered in median
count 7329.000000
mean 44930.010506
std 35582.783216
min 6000.000000
25% NaN
50% NaN
75% NaN
max 200000.000000
Name: Income, dtype: float64
Es scheint, dass das Problem, dass der Quadrant zu NaN wird, zum Zeitpunkt des Schreibens des Artikels bereits gelöst ist, aber es scheint auf die Zusammenführung zu warten. Warten Sie auf das Versions-Upgrade, ohne sich darum zu kümmern. describe() returns RuntimeWarning: Invalid value encountered in median RuntimeWarning #13146
boxplot
Ich möchte ein Boxplot (Boxplot) erstellen.
sns.boxplot(survey['Income'])

In der vertikalen Linie links werden die minimalen Box-Whisker, der erste Quadrant (Q1), der Medianwert, der dritte Quadrant (Q3) und die maximalen Box-Whisker angezeigt. Wenn IQR = Q3-Q1 ist und von (Minimalwert --IQR1.5) ~ (Maximalwert + IQR1.5) abweicht, wird dies durch einen schwarzen Punkt als abweichender Wert von den Box-Whiskern dargestellt.
Es ist auch möglich, ohne Ausreißer auszudrücken.
sns.boxplot(survey['Income'], whips=np.inf)

violinplot
Es gibt auch ein Vaviolin-Diagramm mit kde-Informationen im Box-Diagramm.
sns.violinplot(survey_df['Income'])

Die Verteilung ist leichter zu verstehen!
HoursLearning
Werfen wir einen Blick auf die Lernzeit. Lassen Sie uns zuerst einen kde-Plot machen.
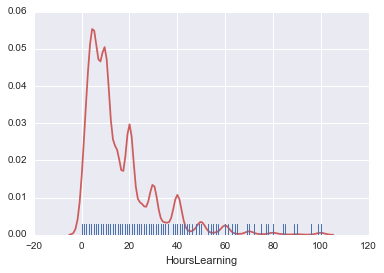
sns.kdeplot(survey_df['HoursLearning'])

Es ist die Menge an Lernen pro Woche in Bezug auf die Zeit. Die Extreme sind auch spürbar, aber dies geschieht mit guten Zahlen. Normalerweise beantworte ich den Fragebogen mit einer guten Nummer, also passiert dies.
Ich habe auch eine Geigenhandlung.
sns.violinplot(survey_df['HoursLearning'])

Es spiegelt die Eigenschaften des kde-Diagramms wider.
Es gibt auch einen "Distplot", der sowohl "Countplot" als auch "Kdeplot" zusammen erzeugen kann.
nan wird gelöscht und verwendet.
hours_learning = survey_df['HoursLearning']
hours_learning = hours_learning.dropna()
sns.distplot(hours_learning)
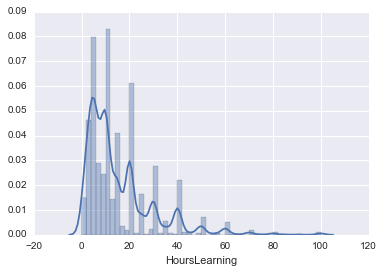
Sie können das Histogramm in ein Verzögerungsdiagramm umwandeln und Optionen hinzufügen. Praktisch!
sns.distplot(hours_learning, rug=True, hist=False, kde_kws={'color':'indianred'})
SchoolMajor
Wenn es sich um einen kontinuierlichen Wert handelt, ist "kdeplot" nützlich. Da es sich jedoch um eine Kategorisierung handelt, verwenden Sie "countplot".
sns.countplot(y='SchoolMajor' , data=survey_df)
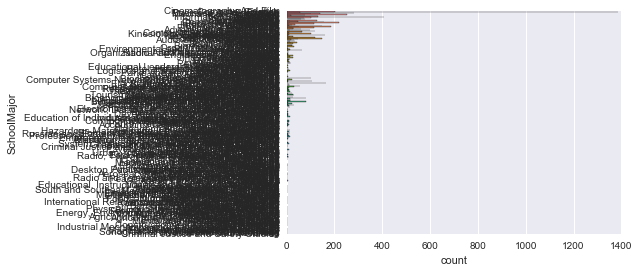
Es ist schwer zu sehen. .. Es gibt zu viele Kategorien. Ich möchte die Top 10 oder so sehen.
collections.Counter
from collections import Counter
major_count = Counter(survey_df['SchoolMajor'])
major_count.most_common(10)
Zählen Sie mit der Standardbibliothek Sammlungen.
Wenn Sie "most_common (10)" setzen, erhalten Sie außerdem die Top 10 davon.
[(nan, 7170),
('Computer Science', 1387),
('Information Technology', 408),
('Business Administration', 284),
('Economics', 252),
('Electrical Engineering', 220),
('English', 204),
('Psychology', 187),
('Electrical and Electronics Engineering', 164),
('Software Engineering', 159)]
Lassen Sie es uns in der Grafik anzeigen.
X = []
Y = []
major_count_top10 = major_count.most_common(10)
for record in major_count_top10:
X.append(record[0])
Y.append(record[1])
# [nan, 'Computer Science', 'Information Technology', 'Business Administration', 'Economics', 'Electrical Engineering', 'English', 'Psychology', 'Electrical and Electronics Engineering', 'Software Engineering']
# [7170, 1387, 408, 284, 252, 220, 204, 187, 164, 159]
plt.barh(np.arange(10), Y)
plt.yticks(np.arange(10), X)
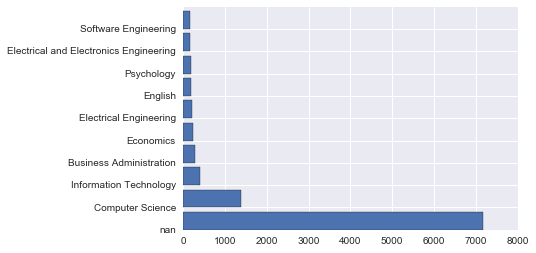
Ich habe hier darauf hingewiesen. Balkendiagramm - Einführung in matplotlib
Sie können plt.barh verwenden, um die Achse von plt.bar zu ändern. Ich habe es auch mit "yticks" beschriftet.
Nun, ich möchte nan nicht anzeigen und ich möchte es in umgekehrter Reihenfolge sortieren.
X = []
Y = []
major_count_top10 = major_count.most_common(10)
major_count_top10.reverse()
for record in major_count_top10:
# record[0] == record[0]Es gibt eine Ergänzung unten
if record[0] == record[0]:
X.append(record[0])
Y.append(record[1])
# ['Software Engineering', 'Electrical and Electronics Engineering', 'Psychology', 'English', 'Electrical Engineering', 'Economics', 'Business Administration', 'Information Technology', 'Computer Science']
# [159, 164, 187, 204, 220, 252, 284, 408, 1387]
plt.barh(np.arange(9), Y)
plt.yticks(np.arange(9), X)

Das Diagramm, an das ich dachte, wurde erstellt!
[Ergänzung] über if record [0] == record [0]:
Hier haben wir dies implementiert, da "False" nur beim Vergleich von "NaN" zurückgegeben wird. (Siehe auch die URL unten)
Wie man Python beurteilt, Nan.
Es ist jedoch schwer zu verstehen Die von @shiracamus eingeführte Implementierungsmethode ist leichter zu verstehen. Ich werde dies auch in Zukunft nutzen.
if record[0] == record[0]:
Das Teil wurde wie folgt geändert.
if pd.notnull(record[0]):
Datenassoziation
Geschlecht und HasChildren
Erstens ist das Geschlecht nur der Einfachheit halber für Männer und Frauen.
male_female_df = survey_df.where((survey_df['Gender'] == 'male') + (survey_df['Gender'] == 'female') )
Sie können nach Ebenen zählen, indem Sie den Farbton des Zählplots verwenden.
countplot(hue)
sns.countplot('Gender', data=male_female_df, hue='HasChildren')
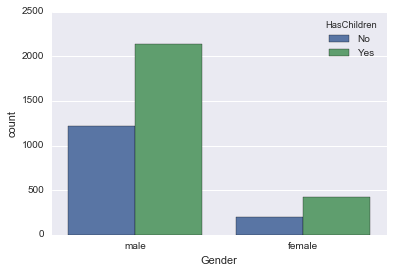
Es scheint, dass sowohl Männer als auch Frauen den gleichen Anteil an Kindern haben.
Geschlecht und Alter
Andere Diagramme als "Zähldiagramm" können auch durch Ebenen dargestellt werden. Verwenden Sie "FacetGrid".
sns.FacetGrid
fig = sns.FacetGrid(male_female_df, hue='Gender', aspect=4)
fig.map(sns.kdeplot, 'Age', shade=True)
oldest = male_female_df['Age'].max()
fig.set(xlim=(0, oldest))
fig.add_legend()

Männer sind etwas jünger, nicht wahr?
Beschäftigungsstatus und Geschlecht
Da es mehrere Beschäftigungsstatus gibt, möchte ich nur die obersten verwenden.
# male_female_df ist Umfrage_df Das Geschlecht wurde auf Männer und Frauen eingegrenzt
#Holen Sie sich die Top 5 Beschäftigungsstatus
from collections import Counter
employ_count = Counter(male_female_df['EmploymentStatus'])
employ_count_top = employ_count.most_common(5)
print(employ_count_top)
employ_list =[]
for record in employ_count_top:
if record[0] == record[0]:
employ_list.append(record[0])
def top_employ(status):
return status in employ_list
#bewerben mit anwenden_Holen Sie sich nur die Zeilen der Elemente in der Liste
new_survey_df = male_female_df.loc[male_female_df['EmploymentStatus'].apply(top_employ)]
sns.countplot(y='EmploymentStatus', data=new_survey_df)

Jetzt gibt es nur noch die Top 3 Artikel.
Betrachten wir die geschlechtsspezifische Schichtung anhand des Farbtons "Count Plot".
sns.countplot(y='EmploymentStatus', data=employ_df, hue='Gender')
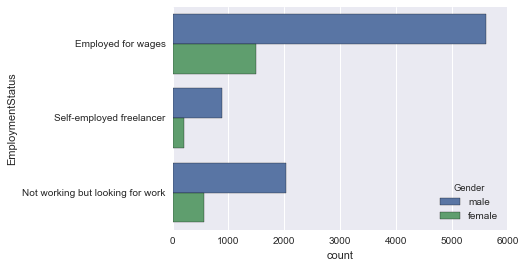
EmploymentStatus und HasChildren
Konvertieren Sie zuerst HasChildren in "Nein-> 0, Ja-> 1".
new_survey_df['HasChildren'] = new_survey_df['HasChildren'].map({'No': 0, 'Yes': 1})
Verwenden Sie hier "Faktorplot". Mal sehen, wie der Beschäftigungsstatus mit der Anwesenheit oder Abwesenheit von Kindern zusammenhängt.
factorplot
sns.factorplot('EmploymentStatus', 'HasChildren', data=new_survey_df, aspect=2)

Der Wert von "Für Löhne beschäftigt" ist etwas hoch. Das überzeugt.
Sie können die Faktordiagramme auch nach Ebenen anzeigen. Lassen Sie uns also sehen, ob es einen Unterschied zwischen Männern und Frauen gibt.
sns.factorplot('EmploymentStatus', 'HasChildren', data=new_survey_df, aspect=2, hue='Gender')

Das ist ziemlich interessant. Tatsächlich war es für Männer und Frauen völlig unterschiedlich. Es scheint, dass es verschiedene Dinge gibt, die angesichts der Beschäftigungssituation berücksichtigt werden können.
Alter und HasChildren
lmplot
Ich würde gerne die Beziehung zu einer Regressionslinie sehen. Verwenden Sie "lmplot" für die Regressionslinie.
sns.lmplot('Age', 'HasChildren', data=new_survey_df)

Übrigens kann lmplot auch schichtweise gesehen werden, also würde ich es gerne ausprobieren.
Zuerst Ebene nach "Beschäftigungsstatus".
sns.lmplot('Age', 'HasChildren', data=new_survey_df, hue='EmploymentStatus')
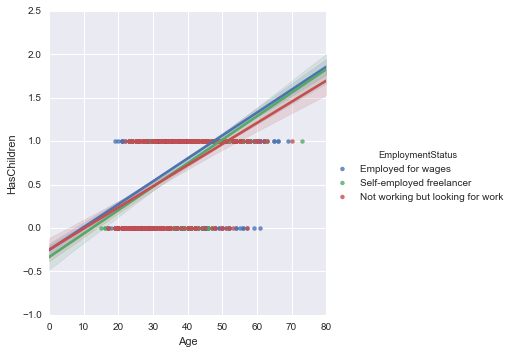
Im Allgemeinen ist der Wert von "Für Löhne beschäftigt" etwas hoch, aber wie Sie im vorherigen Abschnitt gesehen haben, scheint es etwas klarer zu sein, wenn Sie ihn nach Geschlecht aufteilen.
Übrigens ist sogar "Geschlecht" geschichtet.
sns.lmplot('Age', 'HasChildren', data=new_survey_df, hue='Gender')

Zeigen Sie mehrere Diagramme nebeneinander an
Sie können auch mehrere Diagramme nebeneinander anzeigen. Ich habe zwei Graphen mit Unterplots gezeichnet.
fig, (axis1, axis2) = plt.subplots(1, 2, sharey=True)
sns.regplot('HasChildren', 'Age', data=new_survey_df, ax=axis1)
sns.violinplot(y='Age', x='HasChildren', data=new_survey_df, ax=axis2)

regplot ist eine Low-Level-Version von lmplot, die auch für einfache Regressionen verwendet wird.
Ich habe "Regplots" verwendet, da die Funktionen, die mit "Subplots" verwendet werden können, auf diejenigen beschränkt zu sein scheinen, die ein "matplotlib Axes" -Objekt zurückgeben, und "lmplot" nicht verwendet werden konnte.
Ausführliche Erklärung Plotting with seaborn using the matplotlib object-oriented interface War leicht zu verstehen.
Es scheint, dass die in diesem Artikel erwähnte Funktion "Achsenebene" verwendet werden kann. (regplot, boxplot, kdeplot, and many others)
Andererseits wird auch die Funktion "Figurenebene" eingeführt, und es gibt auch "lmplot" darin. (lmplot, factorplot, jointplot and one or two others)
Es ist fast "Achse" und teilweise "Figur".
Es scheint also, dass "FacetGrid" gut für Zahlen ist. Plotting on data-aware grids
Sie können mit "FacetGrid" auch mehrere Diagramme anordnen. Ich habe versucht, die Verteilung des Alters neben EmploymentStatus anzuzeigen.
fig = sns.FacetGrid(new_survey_df, col='EmploymentStatus', aspect=1.5)
fig.map(sns.distplot, 'Age')
oldest = new_survey_df['Age'].max()
fig.set(xlim=(0, oldest))
fig.add_legend()

abschließend
Organisieren Sie, was herauskommt
- df.shape
- df.info()
- df.describe()
- df.read_csv
- sns.countplot
- plt.hist
- plt.bar
- sns.kdeplot
- df.loc
- df.map
- sns.rugplot
- sns.boxplot
- sns.violinplot
- sns.distplot
- collections.Counter
- collections.Counter.most_common
- plt.barh
- pd.where
- sns.countplot(hue)
- sns.FacetGrid
- df.apply
- sns.lmplot
- sns.lmplot(hue)
- plt.subplots
Referenziert in der Verwendung von Python
Besseres Schreiben, das ich wissen wollte, seit ich Python gestartet habe Python Pandas Datenauswahlprozess etwas detaillierter <Teil 2>
Referenz
[20.000 Menschen auf der Welt] Praktische Python-Datenwissenschaft Dies ist ein empfohlener Videokurs, der mit detaillierten Erklärungen leicht zu verstehen ist. Der Punkt ist, dass selbst wenn Sie eine Frage stellen, die Antwort am nächsten Tag zurückgegeben wird.
[Einführung in die Datenanalyse durch Python-Datenverarbeitung mit NumPy und Pandas](https://www.amazon.co.jp/Python%E3%81%AB%E3%82%88%E3%82%8B%E3 % 83% 87% E3% 83% BC% E3% 82% BF% E5% 88% 86% E6% 9E% 90% E5% 85% A5% E9% 96% 80-% E2% 80% 95NumPy% E3% 80% 81 Pandas% E3% 82% 92% E4% BD% BF% E3% 81% A3% E3% 81% 9F% E3% 83% 87% E3% 83% BC% E3% 82% BF% E5% 87% A6% E7% 90% 86-Wes-McKinney / dp / 4873116554) O'Reillys Datenanalysebuch. Es ist gut organisiert.
Start Python Club Die Python-Community. Ich bin nicht auf Datenanalyse spezialisiert, aber ich bin in einer Vielzahl von Python aktiv. Wenn Sie also Python verwenden, macht es meiner Meinung nach Spaß, loszulegen.
Recommended Posts