Verbessertes Lernen ab Python
Einführung
Stärkt ihr das Lernen? Reinforcement Learning ist eine unterhaltsame Technologie, die auf Roboter, Spiele wie Go und Shogi sowie Dialogsysteme angewendet werden kann.
Intensiviertes Lernen ist ein Lernkontrollrahmen, der sich durch Ausprobieren an die Umgebung anpasst. Beim überwachten Lernen wurde der Eingabe für das Lernen die richtige Ausgabe gegeben. Beim verstärkten Lernen wird anstelle der korrekten Ausgabe für die Eingabe ein skalarer Bewertungswert namens "Belohnung" angegeben, der das Gute oder Schlechte einer Reihe von Aktionen bewertet, und das Lernen wird anhand dieses Hinweises durchgeführt. Der Rahmen des verstärkenden Lernens ist unten dargestellt.
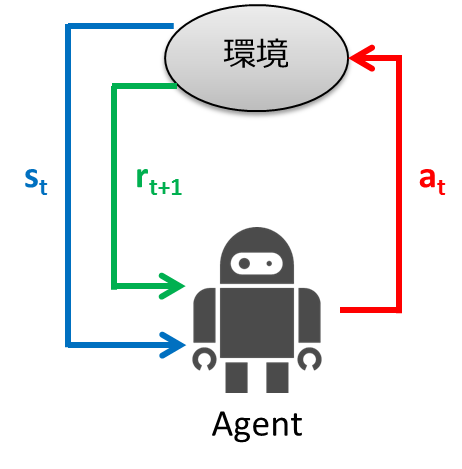
- Der Agent beobachtet den Umgebungszustand $ s_t $ zum Zeitpunkt $ t $
- Bestimmen Sie die Aktion $ a_t $ aus dem beobachteten Zustand
- Der Agent ergreift Maßnahmen
- Die Umgebung wechselt in den neuen Zustand $ s_ {t + 1} $
- Verdiene $ r_ {t + 1} $ entsprechend dem Übergang
- Lernen
- Wiederholen Sie ab Schritt 1
Der Zweck des intensiven Lernens besteht darin, ein State-to-Action-Mapping (Richtlinie) zu erhalten, das die Gewinne (kumulierten Belohnungen) maximiert, die Agenten erhalten.
Beim verstärkten Lernen wird das obige Framework durch Markov-Entscheidungsprozesse (MDP) modelliert und der Lernalgorithmus berücksichtigt. In diesem Artikel erklären wir die Stärkung des Lernens in Theorie und Praxis getrennt. Im theoretischen Teil werden wir MDP und Lernalgorithmen erklären, und im praktischen Teil werden wir implementieren, was im theoretischen Teil unter Verwendung der Programmiersprache Python erklärt wurde. Wir empfehlen, dass Sie sie der Reihe nach lesen. Wenn Sie jedoch "Komake Kota ist gut!" Sagen, überspringen Sie den theoretischen Teil und lesen Sie den praktischen Teil.
Theorie
Zunächst werde ich die Theorie des verstärkenden Lernens anhand von Beispielen erläutern. Nach Erläuterung der Problemstellung des Beispiels wird hier der Markov-Entscheidungsprozess erläutert. Nachdem Sie den Markov-Entscheidungsprozess verstanden haben, sprechen wir darüber, wie Sie ihn lernen können.
Problemstellung
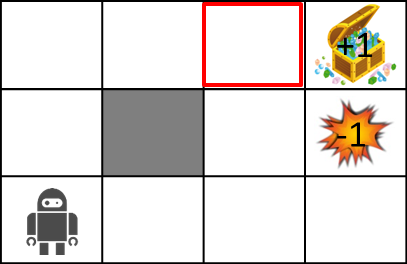
Betrachten Sie nun bei der Erklärung von MDP die folgende Labyrinthwelt.
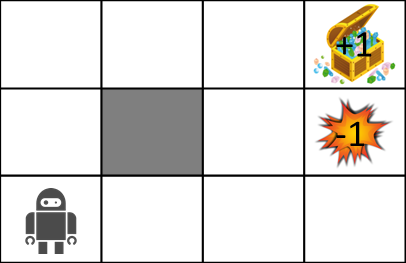
Die Regeln der Labyrinthwelt lauten wie folgt:
- Agent befindet sich in einem Raster
- Agent kann die Wand nicht überqueren (grau)
- Agenten arbeiten möglicherweise nicht immer so, wie sie es möchten
- 80% Chance, sich richtig zu bewegen, 10% Chance, sich in der von Ihnen beabsichtigten Richtung nach links zu bewegen, 10% Chance, sich nach rechts zu bewegen
- Wenn es eine Wand gibt, an die Sie sich bewegen möchten, bleiben Sie dort
- Der Agent erhält jedes Mal eine Belohnung
- Wenn Sie das Ziel (Schatzkiste) oder die Falle (Explosion) erreichen, endet das Spiel und Sie kehren zur Startposition zurück.
Wir werden den stochastischen Übergang anhand der folgenden Abbildung etwas detaillierter erläutern.
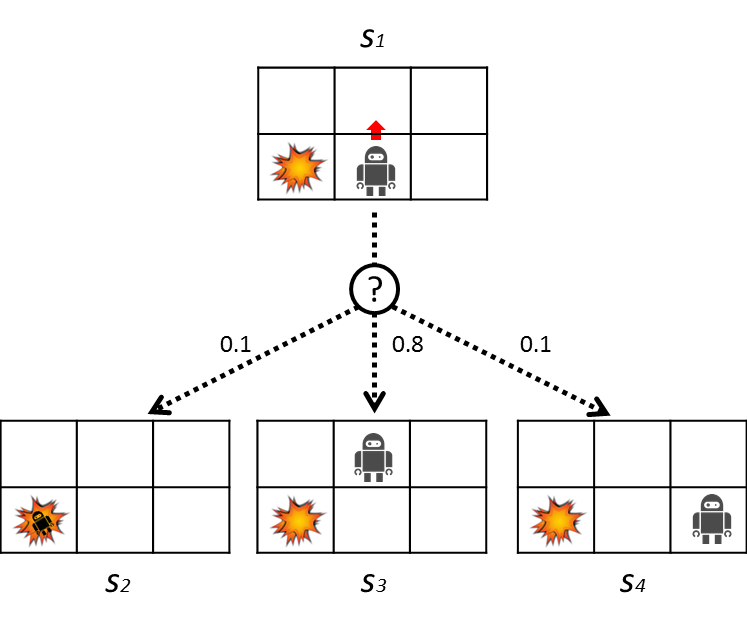
Hier versucht der Roboter aufzusteigen. Zu diesem Zeitpunkt besteht eine 80% ige Chance, sich nach oben zu bewegen, aber eine 10% ige Chance, sich nach links zu bewegen, und die restlichen 10%, sich nach rechts zu bewegen. Die Übergangswahrscheinlichkeiten sind in der folgenden Tabelle aufgeführt.
| 0.1 | |
| 0.8 | |
| 0.1 |
Markov-Entscheidungsprozesse (MDP)
Haben Sie die Problemstellung verstanden? Jetzt, da wir wissen, werden wir das Problem mit MDP modellieren.
MDP wird durch den folgenden 4-Term-Satz definiert
M = (S, A, T, R)
Was ist jeder?
- Zustandssatz: $ s \ in S $
- Aktionssatz: $ a \ in A $
- Übergangsfunktion: $ T (s, a, s ') \ sim P (s' \ mid s, a) $
- Belohnungsfunktion: $ R (s) $, $ R (s, a) $, $ R (s, a, s ') $
Wenden wir sie jeweils auf die oben erläuterten Problemeinstellungen an.
- Der Statussatz repräsentiert den Satz von Zuständen, die die Umgebung annehmen kann, und im Fall des Beispiels repräsentiert er alle Zellen des Gitters.
- Ein Aktionssatz ist eine Art von Aktion, die ein Agent ausführen kann. Im Fall des Beispiels gibt es vier Arten von Agenten, da sie sich nach oben, unten, links und rechts bewegen können.
- Die Übergangsfunktion ist die Wahrscheinlichkeit des Übergangs zum nächsten Zustand $ s '$, wenn die Aktion $ a $ in einem Zustand $ s $ ausgeführt wird. Wie in der obigen Abbildung erläutert.
- Belohnung ist der Wert, der von der Umgebung als Ergebnis eines neuen Übergangs erhalten wird, der die Aktion bestimmt, die aus dem beobachteten Zustand heraus ausgeführt werden soll. Ich werde später im Detail erklären.
Der Zweck dieses MDP ist es, Aktionsstrategien zu lernen, die den Gewinn maximieren (= kumulative Belohnungen). Diese Aktionsstrategie wird als ** Richtlinie ** bezeichnet.
Ein bisschen mehr über Politik
Das Ziel von MDP ist es, die beste Richtlinie $ \ pi ^ *: S \ rightarrow A $ zu erhalten. Eine Richtlinie kann als eine Funktion betrachtet werden, die Zustände Aktionen zuordnet. Die Richtlinie sagt Ihnen, was in jeder Situation zu tun ist. Optimale Richtlinien maximieren auch die erwarteten Gewinne.
Werfen wir einen Blick auf die optimale Richtlinienänderung, wenn Sie die zum Zeitpunkt des Übergangs erzielten Belohnungen ändern.
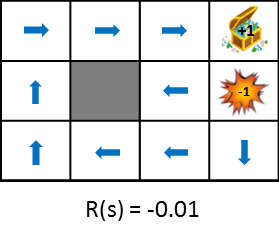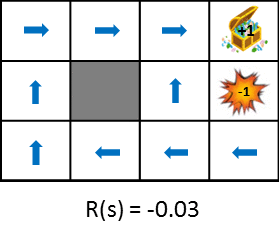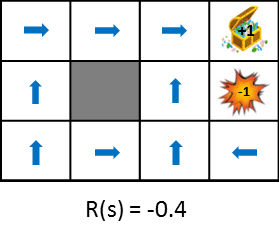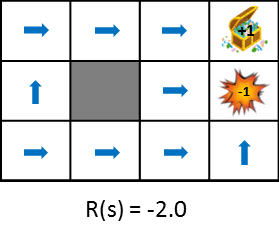 Diese Abbildung zeigt die Änderung der Politik, wenn die durch den Staatsübergang erhaltene Belohnung schrittweise verringert wird (die Strafe wird erhöht). Die Politik lernt aus der Idee, die erwarteten Gewinne zu maximieren, die erzielt werden können. Wenn die Strafe aufgrund des Zustandsübergangs gering ist, wird versucht, auf das Ziel zu zielen, auch wenn es Umwege gibt, und wenn die Strafe groß ist, wird eine Strategie erforderlich sein, um das Spiel sofort zu beenden. Zum einfachen Vergleich stehen auch Standbilder zur Verfügung.
Diese Abbildung zeigt die Änderung der Politik, wenn die durch den Staatsübergang erhaltene Belohnung schrittweise verringert wird (die Strafe wird erhöht). Die Politik lernt aus der Idee, die erwarteten Gewinne zu maximieren, die erzielt werden können. Wenn die Strafe aufgrund des Zustandsübergangs gering ist, wird versucht, auf das Ziel zu zielen, auch wenn es Umwege gibt, und wenn die Strafe groß ist, wird eine Strategie erforderlich sein, um das Spiel sofort zu beenden. Zum einfachen Vergleich stehen auch Standbilder zur Verfügung.
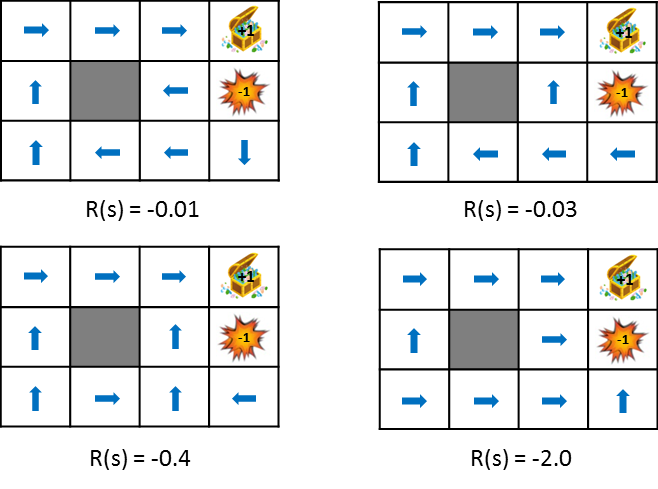
Ein bisschen mehr über Belohnungen
Bisher habe ich gesagt, dass ich die kumulierten Belohnungen maximieren werde, um die Politik zu lernen. Da Sie die Belohnung $ R (s_t) $ jederzeit erhalten können, kann die kumulative Belohnung wie folgt ausgedrückt werden.
\begin{align}
U([s_0, s_1, s_2,\ldots]) &= R(s_0) + R(s_1) + R(s_2) + \cdots \\
&= \sum_{t=0}^{\infty}R(s_t)
\end{align}
Sie können diese einfache kumulative Belohnung verwenden, aber aus mehreren Gründen können Sie die zukünftige Belohnung um den Rabattfaktor $ \ gamma (0 \ leq \ gamma <1) $ diskontieren, wie in der folgenden Formel gezeigt. Kumulative Belohnungen werden verwendet. Dadurch werden die Belohnungen, die Sie jetzt erhalten, stärker betont als die Belohnungen, die Sie in Zukunft erhalten.
\begin{align}
U([s_0, s_1, s_2,\ldots]) &= R(s_0) + \gamma R(s_1) + \gamma^2 R(s_2) + \cdots \\
&= \sum_{t=0}^{\infty}\gamma^t R(s_t)
\end{align}
Die Gründe für die Verwendung solcher Rabattprämien sind folgende.
- Der Wert weicht rechnerisch nicht ab
- In einer realen Umgebung ist es nicht sinnvoll, alle Belohnungen in der Zeitreihe mit demselben Gewicht zu berücksichtigen, da sich die Umgebung im Laufe der Zeit ändern kann.
So finden Sie die beste Richtlinie
Bisher kennen wir das Modell MDP. Die verbleibende Frage ist, wie man die beste Politik findet. Im Folgenden werden die Wertiterationsmethode und Q-Learning als Algorithmen zum Finden der optimalen Richtlinie erläutert.
Wertiteration
Die Wertiterationsmethode berechnet den erwarteten Gewinn aus dem Status $ s $, wenn Sie weiterhin optimale Maßnahmen ergreifen. Der Grund für die Berücksichtigung des erwarteten Wertes des erhaltenen Gewinns besteht darin, dass ein probabilistischer Übergang durchgeführt wird.
Sobald Sie diesen erwarteten Gewinn kennen, kennen Sie den Wert, den Sie in Zukunft aus dem aktuellen Status von $ s $ erhalten werden, und Sie sollten in der Lage sein, Aktionen auszuwählen, die diesen Wert maximieren. Der Wert wird durch die folgende Zustandswertfunktion berechnet. Es sieht kompliziert aus, aber kurz gesagt, es berechnet nur die (erwartete) kumulative Rabattprämie.
U(s) = R(s) + \gamma \max_a\sum_{s'} P(s' \mid s,a) U(s')
In dieser Gleichung gibt es eine nichtlineare Berechnung namens max, und es ist schwierig, sie mit einer Matrix oder dergleichen zu lösen. Daher werden iterative Berechnungen durchgeführt, um den Wert schrittweise zu aktualisieren. Dies ist der Grund für den Namen der Wertiterationsmethode. Der Wertiterationsalgorithmus ist unten gezeigt. Der Rechenaufwand beträgt
- Initialisieren Sie $ U (s) $ auf einen geeigneten Wert (z. B. Null) für alle Zustände $ s $
- Berechnen Sie die folgende Formel für alle $ U (s) $ und aktualisieren Sie die Werte
U(s) \leftarrow R(s) + \gamma \max_a\sum_{s'} P(s' \mid s,a) U(s')
> 3. Wiederholen Sie Schritt 2, bis die Werte konvergieren
In der obigen Formel gibt es einen Teil zur Berechnung des Maximums, es ist jedoch erforderlich, die Aktion a aufzuzeichnen, deren Wert der Maximalwert ist. Daher gibt es das Problem, dass es schwierig ist, die optimale Richtlinie (Verhalten) nur mit $ U (s) $ zu verstehen. Daher wird die folgende Q-Funktion eingeführt. Wird auch als Aktionswertfunktion bezeichnet.
```math
Q^*(s,a) = R(s) + \gamma \sum_{s'} P(s' \mid s,a) \max_{a'}Q^*(s', a')
** $ Q ^ * (s, a) $ ** stellt den erwarteten Wert der kumulierten abgezinsten Belohnung dar, wenn Sie nach Auswahl der Aktion a in ** state $ s $ weiterhin die optimale Richtlinie anwenden.
Es gibt einen Unterschied zwischen $ U (s) $ und $ Q ^ * (s, a) $, ob sie nur den Maximalwert in jedem Zustand oder den Wert für jede Aktion enthalten. Daher ist der maximale Q-Wert im Zustand s gleich $ U (s) $, und die Aktion a mit diesem Q-Wert ist die optimale Aktion. Die Abbildung unten zeigt das Bild.
Die Wertiterationsmethode bei Verwendung der Q-Funktion lautet wie folgt.
- Initialisieren Sie $ Q ^ * (s, a) $ auf einen geeigneten Wert (z. B. Null) für alle Zustände $ s $
- Berechnen Sie die folgende Formel für alle $ Q ^ * (s, a) $ und aktualisieren Sie die Werte
Q^(s,a) \leftarrow R(s) + \gamma \sum_{s'} P(s' \mid s,a) \max_{a'}Q^(s', a')
> 3. Wiederholen Sie Schritt 2, bis die Werte konvergieren
Zu diesem Zeitpunkt ist es einfach, die beste Richtlinie $ \ pi ^ * (s) $ zu finden. Es wird unten berechnet.
```math
\pi^*(s) = arg\max_{a}Q^*(s,a)
Berechnungsbeispiel
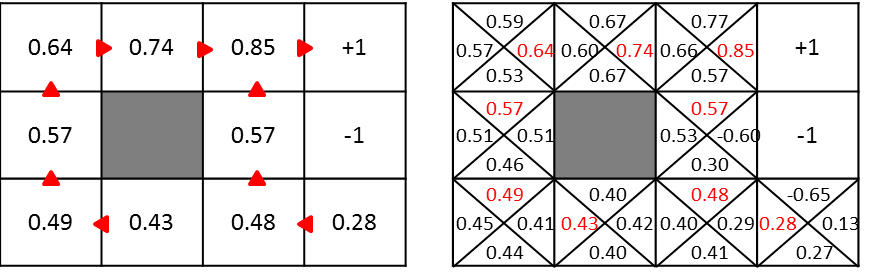
Da es eine große Sache ist, versuchen wir, den Wert der roten Stelle unten zu berechnen.
 Verwenden Sie für die Berechnung die folgende Formel.
Verwenden Sie für die Berechnung die folgende Formel.
U(s) \leftarrow R(s) + \gamma \max_a\sum_{s'} P(s' \mid s,a) U(s')
$ \ Gamma = 0,5 $, $ R (s) = -0,04 $, die Übergangswahrscheinlichkeit beträgt 0,8 in der Richtung, in die Sie gehen möchten, und 0,1 auf jeder Seite.
Unter den oben genannten Bedingungen beträgt der Wert im roten Bereich ...
\begin{align}
U(s) &= -0.04 + 0.5 \cdot (0.8 \cdot 1 + 0.1 \cdot 0 + 0.1 \cdot 0)\\
&= -0.04 + 0.4\\
&= 0.36
\end{align}
Wird benötigt.
Q-Learning Jetzt bin ich erleichtert, dass die Wertwiederholungsmethode die optimale Richtlinie erfordert. Das ist nicht der Großhändler. Was ist los?
Bisher wussten wir über Zustandsübergangswahrscheinlichkeiten Bescheid. In Anbetracht des tatsächlichen Problems ist es jedoch selten, dass die Zustandsübergangswahrscheinlichkeit bekannt ist. Stellen Sie sich Schach oder Shogi vor. Ist die Wahrscheinlichkeit eines Übergangs von einer Karte (Staat) zu einer anderen (anderer Staat) im Voraus angegeben? Du hast es nicht bekommen, oder? In solchen Fällen kann die Wertiterationsmethode nicht verwendet werden.
Hier kommt Q-Learning heraus, das als verbesserte Lernversion der Wertwiederholungsmethode bezeichnet werden kann. Im Q-Learning Berechnen Sie die geschätzten $ \ hat {Q} ^ {\ *} (s_t, a_t) $ für $ \ hat {Q} ^ {\ *} (s, a) $. Mit Q-Learning können Sie die optimale Richtlinie auch in Situationen erlernen, in denen Sie die Übergangswahrscheinlichkeit nicht kennen. Der Q-Learning-Algorithmus ist wie folgt.
- Initialisieren Sie $ \ hat Q ^ * (s_t, a_t) $ mit einem geeigneten Wert
- Die Aktionswertschätzung wurde mit der folgenden Formel aktualisiert. $ \ Alpha $ ist jedoch die Lernrate von $ 0 \ leq \ alpha \ leq 1 $.
\hat Q^(s_t, a_t) \leftarrow \hat Q^(s_t, a_t) + \alpha \Bigl[ r_{t+1} + \gamma \max_{a \in A}\hat Q^(s_{t+1}, a) - \hat Q^(s_t, a_t) \Bigr]
> 3. Stellen Sie den Zeitschritt $ t $ auf $ t + 1 $ und zurück auf 2 vor
Sie können das optimale $ Q ^ * (s, a) $ erhalten, indem Sie diese Berechnung wiederholen.
<!--
Beim Vergleich der Aktualisierungsformel der Wertiterationsmethode (Q-Funktionsversion) und der Aktualisierungsformel von Q-Learning wird die Übergangswahrscheinlichkeit $ P (s '\ mid s, a) $ für die Q-Funktion in der Wertiterationsmethode berechnet. Obwohl es verwendet wird, wird es nicht verwendet, da es in der Situation, in der Q-Learning verwendet wird, unbekannt ist. Durch iterative Berechnungen
-->
# Praktische Ausgabe
Mal sehen, was passiert, wenn wir das tun, was wir oben in Python erklärt haben.
## Wertwiederholungsmethode
Die erste ist die Wertiterationsmethode.
Die Wertiterationsmethode basiert auf dem sauberen Code (mdp.py) in [UC Berkeley](https://github.com/aimacode/aima-python).
### MDP-Klasse
Zunächst von MDP, der Basisklasse. Erben Sie dies und erstellen Sie eine GridMDP-Klasse.
```python
class MDP:
def __init__(self, init, actlist, terminals, gamma=.9):
self.init = init
self.actlist = actlist
self.terminals = terminals
if not (0 <= gamma < 1):
raise ValueError("An MDP must have 0 <= gamma < 1")
self.gamma = gamma
self.states = set()
self.reward = {}
def R(self, state):
return self.reward[state]
def T(self, state, action):
raise NotImplementedError
def actions(self, state):
if state in self.terminals:
return [None]
else:
return self.actlist
Die Methode \ _ \ _ init \ _ \ _ empfängt die folgenden Parameter:
- init: Ausgangszustand.
- actlist: Aktionen, die in jedem Zustand ausgeführt werden können.
- Terminals: Liste der terminierten Zustände
- Gamma: Rabattfaktor
Die ** R ** -Methode gibt die Belohnung für jeden Zustand zurück. Die ** T ** -Methode ist ein Übergangsmodell. Obwohl es sich hier um eine abstrakte Methode handelt, gibt die Aktion $ a $ im Zustand $ s $ eine Liste der Übergangswahrscheinlichkeiten zum nächsten Zustand und ein Tupel (Wahrscheinlichkeit s ') des nächsten Zustands zurück. Wir werden es mit Grid MDP implementieren. Die Methode ** Aktionen ** gibt eine Liste der Aktionen zurück, die in jedem Status ausgeführt werden können.
GridMDP-Klasse
Die GridMDP-Klasse ist eine konkrete Klasse der Basisklasse MDP. Diese Klasse dient dazu, die im Beispiel erläuterte Welt des Labyrinths auszudrücken.
class GridMDP(MDP):
def __init__(self, grid, terminals, init=(0, 0), gamma=.9):
grid.reverse() # because we want row 0 on bottom, not on top
MDP.__init__(self, init, actlist=orientations,
terminals=terminals, gamma=gamma)
self.grid = grid
self.rows = len(grid)
self.cols = len(grid[0])
for x in range(self.cols):
for y in range(self.rows):
self.reward[x, y] = grid[y][x]
if grid[y][x] is not None:
self.states.add((x, y))
def T(self, state, action):
if action is None:
return [(0.0, state)]
else:
return [(0.8, self.go(state, action)),
(0.1, self.go(state, turn_right(action))),
(0.1, self.go(state, turn_left(action)))]
def go(self, state, direction):
state1 = vector_add(state, direction)
return state1 if state1 in self.states else state
def to_grid(self, mapping):
return list(reversed([[mapping.get((x, y), None)
for x in range(self.cols)]
for y in range(self.rows)]))
def to_arrows(self, policy):
chars = {(1, 0): '>', (0, 1): '^', (-1, 0): '<', (0, -1): 'v', None: '.'}
return self.to_grid({s: chars[a] for (s, a) in policy.items()})
Die Methode \ _ \ _ init \ _ \ _ empfängt fast dieselben Argumente wie die MDP-Klasse, außer dass sie das Rasterargument empfängt. Das Raster speichert die Belohnungen für jeden Zustand. Übergeben Sie es wie folgt. Keiner repräsentiert eine Wand.
GridMDP([[-0.04, -0.04, -0.04, +1],
[-0.04, None, -0.04, -1],
[-0.04, -0.04, -0.04, -0.04]],
terminals=[(3, 2), (3, 1)])
Die Methode ** go ** gibt den Status zurück, wenn Sie sich in die angegebene Richtung bewegen. Die ** T ** -Methode ist wie in MDP beschrieben. Es ist tatsächlich hier implementiert. Die Methoden ** to_grid ** und ** to_arrows ** sind Anzeigemethoden.
Implementierung der Wertiterationsmethode
def value_iteration(mdp, epsilon=0.001):
U1 = {s: 0 for s in mdp.states}
R, T, gamma = mdp.R, mdp.T, mdp.gamma
while True:
U = U1.copy()
delta = 0
for s in mdp.states:
U1[s] = R(s) + gamma * max([sum([p * U[s1] for (p, s1) in T(s, a)])
for a in mdp.actions(s)])
delta = max(delta, abs(U1[s] - U[s]))
if delta < epsilon * (1 - gamma) / gamma:
return U
def best_policy(mdp, U):
pi = {}
for s in mdp.states:
pi[s] = argmax(mdp.actions(s), key=lambda a: expected_utility(a, s, U, mdp))
return pi
def expected_utility(a, s, U, mdp):
return sum([p * U[s1] for (p, s1) in mdp.T(s, a)])
Die Funktion ** value_iteration ** verwendet eine Instanz von GridMDP als Eingabe und ein Epsilon mit kleinem Wert und gibt U (s) in jedem Zustand als Ausgabe zurück. Es sieht wie folgt aus.
>> value_iteration(sequential_decision_environment)
{(0, 0): 0.2962883154554812,
(0, 1): 0.3984432178350045,
(0, 2): 0.5093943765842497,
(1, 0): 0.25386699846479516,
(1, 2): 0.649585681261095,
(2, 0): 0.3447542300124158,
(2, 1): 0.48644001739269643,
(2, 2): 0.7953620878466678,
(3, 0): 0.12987274656746342,
(3, 1): -1.0,
(3, 2): 1.0}
Durch Übergeben des von der Funktion value_iteration berechneten Ergebnisses an die Funktion ** best_policy ** wird dann die optimale Richtlinie erhalten.
Lauf
Unten ist der Code zum Ausprobieren. Es funktioniert jedoch nicht so, wie es ist, da einige erforderliche Module nicht importiert wurden. Wenn Sie es tatsächlich ausführen möchten, klonen Sie das Repository hier und führen Sie es aus.
sequential_decision_environment = GridMDP([[-0.04, -0.04, -0.04, +1],
[-0.04, None, -0.04, -1],
[-0.04, -0.04, -0.04, -0.04]],
terminals=[(3, 2), (3, 1)])
pi = best_policy(sequential_decision_environment, value_iteration(sequential_decision_environment, .01))
print_table(sequential_decision_environment.to_arrows(pi))
Als Ergebnis der Implementierung können die folgenden Richtlinien abgerufen werden.
> > > .
^ None ^ .
^ > ^ <
Q-Learning Es gibt keine Beule, es ist wie eine Feder
Bitte schreiben Sie Q-Learning, wenn Sie körperliche Stärke haben.
Referenzmaterial
Udacity Vorlesungsvideo. Die Briefe sind schwer zu lesen, aber die Geschichte ist leicht zu verstehen.
Japanische Materialien
- Stärkung des Lernens
- Grundlagen des erweiterten Lernens
- Grundlagen des erweiterten Lernens
- Ich habe etwas über das Lernen der Verstärkung gelernt.
- Informationssemantik (12) Stärkung des Lernens
- Emergent Computation
- Lernen auf kürzestem Weg durch Q-Lernen
Englisches Material
- Reinforcement Learning: A User’s Guide
- Introduction to Reinforcement Learning
- Introduction Reinforcement Learning
Material, das die Wertiteration auf leicht verständliche Weise anhand von Zahlen erklärt
- Markov Decision Processes and Exact Solution Methods:
- Markov Decision Processes Value Iteration
- Markov Decision Processes
Referenzmaterialien bei der Implementierung von Value Iteration
- Artificial Intelligence: Markov Decision Process
- Artificial Intelligence: A Modern Approach
- Value Iteration
- Pythonic Markov Decision Process (MDP)
Höfliche Formelerweiterung der Wertefunktion
Recommended Posts