[Python] Probieren Sie mit Keras-RL ganz einfach erweitertes Lernen (DQN) aus
Einführung
Für diejenigen, die verstärktes Lernen ausprobieren möchten, aber den Algorithmus selbst implementieren möchten ... Wir werden die Umgebung des ursprünglichen Fachs vorbereiten und den Ablauf erklären, um das Lernen mit keras-rl zu stärken.
Laufzeitumgebung
- Python 3.5
- keras 1.2.0
- keras-rl 0.2.0rc1
- Jupyter notebook
Bibliothek zu verwenden
keras
https://github.com/fchollet/keras
pip install keras
Es ist ein Deep-Learning-Framework, von dem gesprochen wurde, dass es einfach ist, ein Netzwerk aufzubauen.
keras-rl https://github.com/matthiasplappert/keras-rl
Es ist eine Bibliothek, die Lernalgorithmen zur Tiefenverstärkung wie DQN unter Verwendung von Keras implementiert. Unterstützte Algorithmen finden Sie hier. Klonen und installieren Sie das Git-Repository.
git clone https://github.com/matthiasplappert/keras-rl.git
pip install ./keras-rl
OpenAI gym https://github.com/openai/gym
pip install gym
Eine Bibliothek mit verschiedenen Umgebungen für verbessertes Lernen. Installieren Sie keras-rl, da für die verbesserte Lernumgebung eine Fitness-Schnittstelle erforderlich ist. Im Beispiel von keras-rl gibt es einen Code zum Erlernen von CartPole im Fitnessstudio mit DQN. Probieren Sie es aus. Machen wir das.
Aufbau einer Umgebung für verbessertes Lernen
Die verbesserte Lernumgebung, die keras-rl lernt, implementiert Env of OpenAI Gym. In den Kommentaren von Env des zu implementierenden Fitnessstudios (https://github.com/openai/gym/blob/master/gym/core.py#L27)
When implementing an environment, override the following methods
in your subclass:
_step
_reset
_render
_close
_configure
_seed
And set the following attributes:
action_space: The Space object corresponding to valid actions
observation_space: The Space object corresponding to valid observations
reward_range: A tuple corresponding to the min and max possible rewards
Obwohl mindestens angegeben ist, ist es in Ordnung, wenn Sie Folgendes implementieren.
_step
_reset
action_space
observation_space
Nehmen wir dieses Mal ein einfaches Beispiel für einen Punkt, der sich auf einer geraden Linie bewegt, und nehmen wir das Beispiel, die Geschwindigkeit von einer zufälligen Anfangsposition aus zu manipulieren und den Ursprung zu erreichen.
import gym
import gym.spaces
import numpy as np
#Manipulieren Sie die Geschwindigkeit von Punkten, die sich auf einer geraden Linie zum Ziel bewegen(Ursprung)Umwelt, deren Ziel es ist, sich zu bewegen
class PointOnLine(gym.core.Env):
def __init__(self):
self.action_space = gym.spaces.Discrete(3) #Aktionsraum. Drei Arten: verlangsamen, Schritt halten
high = np.array([1.0, 1.0]) #Beobachtungsraum(state)Abmessungen(Zwei Dimensionen von Position und Geschwindigkeit)Und ihr Maximum
self.observation_space = gym.spaces.Box(low=-high, high=high) #Der Minimalwert ist minus dem Maximalwert
#Wird für jeden Schritt aufgerufen
#Implementiert, um eine Aktion zu erhalten und zurückzugeben, ob der nächste Status, die nächste Belohnung oder die nächste Episode beendet ist
def _step(self, action):
#Erhalten Sie eine Aktion und entscheiden Sie über den nächsten Status
dt = 0.1
acc = (action - 1) * 0.1
self._vel += acc * dt
self._vel = max(-1.0, min(self._vel, 1.0))
self._pos += self._vel * dt
self._pos = max(-1.0, min(self._pos, 1.0))
#Die Episode endet, wenn die absoluten Werte für Position und Geschwindigkeit klein genug sind
done = abs(self._pos) < 0.1 and abs(self._vel) < 0.1
if done:
#Positive Belohnung, wenn Sie fertig sind
reward = 1.0
else:
#Negative Belohnung im Laufe der Zeit
#Wenn Sie den absoluten Wert verringern, wenn sich die Entfernung nähert, damit Sie sich dem Ziel nähern, wird das Lernen schneller fortgesetzt.
reward = -0.01 * abs(self._pos)
#Gibt den nächsten Status zurück, Belohnung, ob fertig, zusätzliche Informationen
#Leeres Diktat, da keine zusätzlichen Informationen vorhanden sind
return np.array([self._pos, self._vel]), reward, done, {}
#Wird zu Beginn jeder Episode aufgerufen und implementiert, um den Ausgangszustand zurückzugeben
def _reset(self):
#Der Ausgangszustand ist zufällige Position, Geschwindigkeit Null
self._pos = np.random.rand()*2 - 1
self._vel = 0.0
return np.array([self._pos, self._vel])
Aufbau und Lernen von DQN
In keras-rl Beispiel dqn_cartpole.py finden Sie den Code zum Erstellen und Lernen von DQN. schreiben.
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
from keras.optimizers import Adam
from rl.agents.dqn import DQNAgent
from rl.policy import EpsGreedyQPolicy
from rl.memory import SequentialMemory
env = PointOnLine()
nb_actions = env.action_space.n
#DQN-Netzwerkdefinition
model = Sequential()
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(nb_actions))
model.add(Activation('linear'))
print(model.summary())
#Speicher für Erfahrungswiedergabe
memory = SequentialMemory(limit=50000, window_length=1)
#Die Aktionspolitik ist orthodoxes Epsilon-gierig. Zusätzlich ist Boltzmann QPolicy verfügbar, das die Wahrscheinlichkeit anhand des Q-Werts jeder Aktion bestimmt
policy = EpsGreedyQPolicy(eps=0.1)
dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=100,
target_model_update=1e-2, policy=policy)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])
history = dqn.fit(env, nb_steps=50000, visualize=False, verbose=2, nb_max_episode_steps=300)
#Wenn Sie den Lernstatus zeichnen möchten, finden Sie in Env_render()Implementieren und visualisieren=Wahr,
Zeichnungstests und Ergebnisse
Testen Sie den erlernten Agenten und versuchen Sie, die Ergebnisse zu zeichnen. Implementieren Sie Callback, um Informationen für jeden Schritt zu speichern (nicht in keras-rl?) Führen Sie den Test aus und zeichnen Sie die in Callback gespeicherten Ergebnisse auf.
import rl.callbacks
class EpisodeLogger(rl.callbacks.Callback):
def __init__(self):
self.observations = {}
self.rewards = {}
self.actions = {}
def on_episode_begin(self, episode, logs):
self.observations[episode] = []
self.rewards[episode] = []
self.actions[episode] = []
def on_step_end(self, step, logs):
episode = logs['episode']
self.observations[episode].append(logs['observation'])
self.rewards[episode].append(logs['reward'])
self.actions[episode].append(logs['action'])
cb_ep = EpisodeLogger()
dqn.test(env, nb_episodes=10, visualize=False, callbacks=[cb_ep])
%matplotlib inline
import matplotlib.pyplot as plt
for obs in cb_ep.observations.values():
plt.plot([o[0] for o in obs])
plt.xlabel("step")
plt.ylabel("pos")
Testing for 10 episodes ...
Episode 1: reward: 0.972, steps: 17
Episode 2: reward: 0.975, steps: 16
Episode 3: reward: 0.832, steps: 44
Episode 4: reward: 0.973, steps: 17
Episode 5: reward: 0.799, steps: 51
Episode 6: reward: 1.000, steps: 1
Episode 7: reward: 0.704, steps: 56
Episode 8: reward: 0.846, steps: 45
Episode 9: reward: 0.667, steps: 63
Episode 10: reward: 0.944, steps: 29
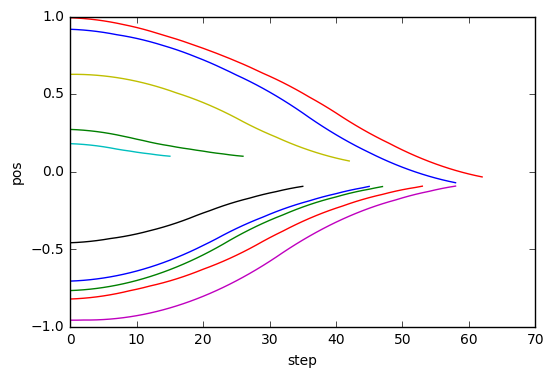
Ich konnte lernen, reibungslos auf Position 0 zu kommen.
Recommended Posts