[Python] Gewöhnen Sie sich an Keras, während Sie Enhanced Learning (DQN) implementieren.
Einführung
Dieser Artikel ist eine Erinnerung daran, dass ich süchtig danach war, Zielfunktionen anzupassen, Optimierer, mehrere Eingaben usw. hinzuzufügen, während ich versuchte, erweitertes Lernen (DQN) mit Keras zu implementieren. Das habe ich zurückgelassen. Daher handelt es sich eher um Keras-Tipps für Anfänger als um einen Kommentar zu DQN.
Ausführungsumgebung
Python3.5.2 Keras 1.2.1 tensorflow 0.12.1
Was ist DQN?
Es ist mehr als zwei Jahre her, seit DQN (DeepQ Network) von DeepMind angekündigt wurde. Daher gibt es überall Kommentarartikel und Implementierungsbeispiele. Daher halte ich hier keine detaillierten Erklärungen für notwendig. Ich werde. Grob gesagt handelt es sich jedoch um eine Lernmethode, die es ermöglicht, den Q-Wert direkt aus einem bewegten Bild zu schätzen, indem der Q-Funktionsteil der erweiterten Lernmethode namens Q-Learning durch tiefes Lernen angenähert wird. Als Theorie von DQN
- Stärkung des Lernens von Null auf Tiefe
- Stärkung des Lernens ab Python
- Ich habe versucht, künstliche Intelligenz mit all meiner Kraft zu konfrontieren (Theorie) [Niko Niko Video]
- Geschichte von DQN + Deep Q-Network in Chainer geschrieben
Die Kommentarartikel hier sind sehr höflich und leicht zu verstehen. Schauen Sie also bitte dort nach. Ähnlich wie bei anderen Deep-Learning-Studien. Die Forschung zum verstärkten Lernen hat in den letzten Jahren große Fortschritte gemacht, und DQN, das 2013 angekündigt wurde, ist nicht die neueste Methode. Da der Algorithmus jedoch einfach, leicht zu verstehen und leicht zu implementieren ist, werden wir uns diesmal damit befassen.
Was ist Keras?
Keras ist eine Deep-Learning-Wrapper-Bibliothek, die auf Theano und TensorFlow basiert. Dank Theano und TensorFlow ist es viel einfacher geworden, tief zu lernen, aber es ist immer noch schwierig, den Algorithmus zu schreiben. Keras ist also eine Bibliothek, die es ermöglicht, eine Netzwerkstruktur ziemlich einfach zu schreiben. Selbst Anfänger des maschinellen Lernens wie ich können relativ einfach Code schreiben. Für diejenigen, die Keras noch nicht kennen, habe ich den grundlegenden Teil weiter oben im Artikel Vorhersage von Sinuswellen mit RNN in der Deep Learning-Bibliothek Keras geschrieben. , Wenn es Ihnen nichts ausmacht, sehen Sie das bitte.
DQN-Implementierung in Keras (Tensorflow)
Es gibt viele Artikel, in denen die DQN-Implementierung in Keras und Tensorflow erläutert wird.
- Implementierung von DQN (vollständige Version) mit Tensorflow
- DQN mit TensorFlow-Insekt mit künstlicher Intelligenz im Garten
- DQN mit Keras, TensorFlow und OpenAI Gym implementieren
- Ultra-einfache Implementierung von DQN (Deep Q Network) mit TensorFlow ~ Einführung ~
- Reversi AI mit Keras + DQN schreiben
- Ich möchte, dass DQN Puniki einen Homerun macht
Wenn Sie sich mit Keras auskennen und die DQN-Implementierung sehen möchten, sollten Sie den obigen Artikel lesen.
Außerdem ist die Implementierung des Algorithmus gut und ich möchte schnell versuchen, mit Keras besser zu lernen! Für diejenigen, die sagen, gibt es eine spezielle Keras-Bibliothek für erweitertes Lernen namens keras-rl. Schauen Sie also bitte dort nach. Informationen zur Verwendung [Python] Einfaches Testen von Enhanced Learning (DQN) mit Keras-RL Ich denke, dass der Artikel von hilfreich ist.
Lassen Sie uns DQN mit Keras sehr einfach implementieren
Ich habe eine lange Einführung gemacht, aber das ist das Hauptthema. Dieses Mal, wenn ich mich an Keras gewöhne, ist es meiner Meinung nach einfacher zu verstehen, wenn ich das ändere, was ursprünglich in Tensorflow implementiert wurde. Daher werde ich das verwenden, das bereits in Tensorflow implementiert und veröffentlicht wurde. Der Kapiteltitel bleibt derselbe, aber ALGO GEEKSs Ultra-simple TensorFlow DQN (Deep) Versuchen Sie, Q Network zu implementieren.) ~ Einführung ~ Ich habe den in angegebenen Code ausgeliehen Machen. Es ist eine sehr kompakte und leicht verständliche Implementierung. Da die Lernzeit kurz ist und die Ergebnisse sofort sichtbar sind, werden wir diese in Keras konvertieren.
Der diesmal implementierte Code ist in [github] angegeben (https://github.com/yukiB/keras-dqn-test).
Spiel

(Zustand nach 1000 Epochen)
Die Lernumgebung ist sehr einfach und wie in der Abbildung gezeigt, ist es ein Spiel, bei dem Sie die fallenden Bälle nacheinander auf dem 8x8-Quadrat mit der Leiste unten fangen. Bei der Implementierung dieser Zeit wurden die Regeln gegenüber der ursprünglichen Site geringfügig geändert.
-
- 1 Belohnung für das Fangen des Balls
- Wenn Sie den Ball fallen lassen -1 Belohnung
- Drei Arten von Aktionen (1: nach rechts bewegen, 0: nicht bewegen, -1: nach links bewegen)
- Die Stelle, an der der Ball fällt, ist zufällig, das Intervall beträgt 4 Frames
- Das Spiel ist beendet, wenn Sie den Ball fallen lassen
Es ist.
Umschreiben
Im Tensorfluss
# input layer (8 x 8)
self.x = tf.placeholder(tf.float32, [None, 8, 8])
# flatten (64)
x_flat = tf.reshape(self.x, [-1, 64])
# fully connected layer (32)
W_fc1 = tf.Variable(tf.truncated_normal([64, 64], stddev=0.01))
b_fc1 = tf.Variable(tf.zeros([64]))
h_fc1 = tf.nn.relu(tf.matmul(x_flat, W_fc1) + b_fc1)
# output layer (n_actions)
W_out = tf.Variable(tf.truncated_normal([64, self.n_actions], stddev=0.01))
b_out = tf.Variable(tf.zeros([self.n_actions]))
self.y = tf.matmul(h_fc1, W_out) + b_out
# loss function
self.y_ = tf.placeholder(tf.float32, [None, self.n_actions])
self.loss = tf.reduce_mean(tf.square(self.y_ - self.y))
# train operation
optimizer = tf.train.RMSPropOptimizer(self.learning_rate)
self.training = optimizer.minimize(self.loss)
# saver
self.saver = tf.train.Saver()
# session
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
Es war.

Im ursprünglichen DQN wird Relu nach dem Sandwiching von 3 Conv-Ebenen durch vollständige Kopplung angewendet. Diesmal ist die Anzahl der Pixel bei 8 x 8 jedoch gering, und die Conv-Ebene benötigt Zeit zum Lernen Ich denke es ist geworden. Wenn Sie dies mit Keras umschreiben
self.model = Sequential()
self.model.add(InputLayer(input_shape=(8, 8)))
self.model.add(Flatten())
self.model.add(Dense(32, activation='relu'))
self.model.add(Dense(self.n_actions))
optimizer=RMSprop(lr=self.learning_rate)
self.model.compile(loss='mean_squared_error',
optimizer=optimizer,
metrics=['accuracy'])
Es sieht aus wie. Das Beste an Keras ist, dass der Code, aus dem das Netzwerk besteht, ziemlich einfach ist. Jetzt haben Sie ein Modell, das 3 Q-Werte für jede Aktion ausgibt, wenn Sie 8 x 8 Pixel auf dem Spielbildschirm eingeben.
Verwenden Sie die Vorhersagefunktion, um den Q-Wert zu erhalten
def Q_values(self, states):
res = self.model.predict(np.array([states]))
return res[0]
Es ist okay und der Teil des Erfahrungsgedächtnisses ist
# training
self.model.fit(np.array(state_minibatch), np.array(y_minibatch), batch_size=minibatch_size,nb_epoch=1,verbose=0)
Es wird. Das Speichern und Laden des Modells sind
def load_model(self, model_path=None):
yaml_string = open(os.path.join(f_model, model_filename)).read()
self.model = model_from_yaml(yaml_string)
self.model.load_weights(os.path.join(f_model, weights_filename))
self.model.compile(loss='mean_squared_error',
optimizer=RMSProp(lr=self.learning_rate),
metrics=['accuracy'])
def save_model(self, num=None):
yaml_string = self.model.to_yaml()
model_name = 'dqn_model{0}.yaml'.format((str(num) if num else ''))
weight_name = 'dqn_model_weights{0}.hdf5'.format((str(num) if num else ''))
open(os.path.join(f_model, model_name), 'w').write(yaml_string)
self.model.save_weights(os.path.join(f_model, weight_name))
Es sieht aus wie. Es ist kompakt.
Da diese Implementierung auf Klarheit und Kompaktheit ausgerichtet war, gibt es einige Unterschiede zum ursprünglichen DQN.
- Es gibt kein Zielnetzwerk
- Kein Clipping mit Verlustfunktion
- Verwenden Sie keine Faltung im Netzwerk
- Ich verwende normales RMS Prop als Optimierer, nicht von DQN empfohlene RMS Prop Graves
- (Lernen Sie nach dem Auffüllen des Wiedergabespeichers)
- (Verringern Sie das Verhältnis der Aktionsauswahl zufällig von 1, unabhängig vom Q-Wert.)
Dieses Mal werde ich diese Punkte und die Punkte erklären, die ich bei der Implementierung mit Keras nicht mehr hatte.
Tipps1: Kopieren Sie das Modell
In DQN wird eine Maßnahme ergriffen, um das Modell, das bei der Durchführung des Erfahrungsspeichers (Auswertung der Aktion) und bei der Auswahl der Aktionsauswahl verwendet wird, zu trennen, um die ausgewählte Aktion nicht zu überschätzen. In der Originalarbeit [1] verwendeten beide dasselbe Modell, und in der in der Natur veröffentlichten Arbeit von 2015 [2] wurden beide getrennt und ein neues Zielnetzwerk eingeführt. Dadurch wird ein Lehrersignal unter Verwendung der alten Parameter erstellt. Die Erklärung hier ist
introduction to double deep Q-learning
Es wird auf sehr leicht verständliche Weise erklärt, schauen Sie also bitte dort nach.
Auf der Implementierungsseite müssen Sie alle paar Frames das für die Aktionsauswahl verwendete Modell kopieren und an das Zielmodell übergeben. Was tun mit Keras?
from keras.models import model_from_config
def clone_model(model, custom_objects={}):
config = {
'class_name': model.__class__.__name__,
'config': model.get_config(),
}
clone = model_from_config(config, custom_objects=custom_objects)
clone.set_weights(model.get_weights())
return clone
self.target_model = clone_model(self.model)
Sie können kopieren, indem Sie das Modell und das Gewicht an das neue Modell übergeben.
Jedoch,
import copy
self.target_model = copy.copy(self.model)
##Deepcopy führt zu einem Fehler
# self.target_model = copy.deepcopy(self.model)
Es scheint, dass das Modell und die Parameter sogar mit der Standardkopierfunktion kopiert werden (ich konnte sie offiziell nicht finden), aber das Verhalten ist ein wenig beängstigend, daher ist die vorherige Methode besser.
Dieses Mal wird clone_model verwendet, um das aktuelle Modell regelmäßig nach target_model zu kopieren, und target_model wird zum Auswerten und Aktualisieren des Q-Werts verwendet. (Abgesehen davon entspricht in der verbesserten Version von DQN, DDQN, der Q-Wert, der durch Einfügen des Zustands in das Zielmodell erhalten wird, A auf der Suche nach "Aktion, die den maximalen Q-Wert annimmt, der durch Einfügen des Zustands in das aktuelle Modell erhalten wird" (A). Ich benutze was ich tue)
def Q_values(self, states, isTarget=False):
model = self.target_model if isTarget else self.model
res = model.predict(np.array([states]))
return res[0]
def store_experience(self, states, action, reward, states_1, terminal):
self.D.append((states, action, reward, states_1, terminal))
return (len(self.D) >= self.replay_memory_size)
def experience_replay(self):
state_minibatch = []
y_minibatch = []
action_minibatch = []
# sample random minibatch
minibatch_size = min(len(self.D), self.minibatch_size)
minibatch_indexes = np.random.randint(0, len(self.D), minibatch_size)
for j in minibatch_indexes:
state_j, action_j, reward_j, state_j_1, terminal = self.D[j]
action_j_index = self.enable_actions.index(action_j)
y_j = self.Q_values(state_j)
if terminal:
y_j[action_j_index] = reward_j
else:
if not self.use_ddqn:
v = np.max(self.Q_values(state_j_1, isTarget=True))
else: # for DDQN
v = self.Q_values(state_j_1, isTarget=True)[action_j_index]
y_j[action_j_index] = reward_j + self.discount_factor * v
state_minibatch.append(state_j)
y_minibatch.append(y_j)
action_minibatch.append(action_j_index)
# training
self.model.fit(np.array(state_minibatch), np.array(y_minibatch), verbose=0)
Tipps2: Anpassung der Verlustfunktion
Im vorherigen Beispiel haben wir einfach "mean_squared_error" verwendet, aber in DQN wird der Wert des Fehlers "target - Q (s, a; θ)" von -1 auf 1 geändert, um die Lernstabilität zu verbessern. Clip im Bereich von. Dieser Bereich
Implementieren Sie DQN mit Keras, TensorFlow und OpenAI Gym
Es wird auf sehr leicht verständliche Weise erklärt, schauen Sie also bitte dort nach.
Keras bietet standardmäßig verschiedene Arten von Verlustfunktionen. Sie können diese verwenden, indem Sie einfach einen Namen wie "mean_squared_error" schreiben. Es gibt jedoch Situationen, in denen Sie die Verlustfunktion wie diese selbst definieren möchten.
Natürlich hat Keras eine Möglichkeit, dies zu tun (obwohl es etwas schwierig ist).
def loss_func(y_true, y_pred):
error = tf.abs(y_pred - y_true)
quadratic_part = tf.clip_by_value(error, 0.0, 1.0)
linear_part = error - quadratic_part
loss = tf.reduce_sum(0.5 * tf.square(quadratic_part) + linear_part)
return loss
self.model.compile(loss=loss_func, optimizer='rmsprops', metrics=['accuracy'])
Sie können Ihre eigene Verlustfunktion wie folgt definieren (y_true sind die Lehrerdaten und y_pred ist die Modellausgabe). Diese Funktion wird beim Aufruf von model.fit oder model.evaluate verwendet.
[Referenz] Wie verwende ich eine benutzerdefinierte Zielfunktion für ein Modell? # 369
Es ist etwas schwierig, weil es sehr schwierig ist, andere externe Parameter als y_true und y_pred in die Verlustfunktion einzuführen.
In diesem Beispiel wird die Q-Werteliste der Ausgabe des aktuellen Modells unverändert (nur der Teil mit Aktualisierung wird aktualisiert) als der Wert zugewiesen, der y_true im Erfahrungsspeicher zugewiesen werden soll ([1.2, 0.5, 0.1] -> [1.3"). , 0.5, 0.1] ), Die Absolutwertdifferenz aus der Q-Werteliste des aktuellen Modells wird in der Verlustfunktion berücksichtigt. Daher bleibt in "Fehler" der Wert nur im aktualisierten Teil und die anderen sind 0 ("[1,3, 0,5, 0,1] - [1,2, 0,5, 0,1] = [0,1, 0, 0]". ). Am Ende wirkt sich nur der aktualisierte Teil auf den Verlustwert aus, und es werden keine weiteren externen Variablen benötigt.
Übergeben Sie jedoch das Lehrersignal (nur Aktualisierungswert) (1.3), die Modellausgabe ([1.2, 0.5, 0.1]) und die Auswahlaktion ( 0) an die Verlustfunktion und berechnen Sie den Verlustwert daraus im Modell. Sobald Sie versuchen zu berechnen, wird es problematisch. In Tensorflow
state = tf.placeholder(tf.float32, [None, 8, 8]) #Status
a = tf.placeholder(tf.int64, [None]) #Aktion
supervisor = tf.placeholder(tf.float32, [None]) #Lehrersignal
output = self.inference(state)
loss = lossfunc(output, supervisor)
...
loss_val = sess.run(loss, feed_dict={
self.state: np.float32(np.array(state_batch),
self.action: action_batch,
self.super_visor: y_batch
})
def lossfunc(self, a, output, supervisor)
a_one_hot = tf.one_hot(a, self.num_actions, 1.0, 0.0) #Konvertieren Sie das Verhalten in einen heißen Vektor
q_value = tf.reduce_sum(tf.mul(output, a_one_hot), reduction_indices=1) #Berechnung des Q-Wertes des Verhaltens
#Fehlerclip
error = tf.abs(supervisor - q_value)
quadratic_part = tf.clip_by_value(error, 0.0, 1.0)
linear_part = error - quadratic_part
loss = tf.reduce_mean(0.5 * tf.square(quadratic_part) + linear_part) #Fehlerfunktion
Es ist sehr einfach, funktioniert aber in Keras nicht. Sie müssen ein Modell erstellen, das y_true, y_pred und andere externe Funktionen als Eingabe und Ausgabe des Verlustwerts verwendet.
Tipps3: Mehrere Eingänge, mehrere Ausgänge
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers import Lambda, Input
losses = {'loss': lambda y_true, y_pred: y_pred, #dummy loss func
'main_output': lambda y_true, y_pred: K.zeros_like(y_pred)}
def customized_loss(args):
import tensorflow as tf
y_true, y_pred, action = args
a_one_hot = tf.one_hot(action, K.shape(y_pred)[1], 1.0, 0.0)
q_value = tf.reduce_sum(tf.mul(y_pred, a_one_hot), reduction_indices=1)
error = tf.abs(q_value - y_true)
quadratic_part = tf.clip_by_value(error, 0.0, 1.0)
linear_part = error - quadratic_part
loss = tf.reduce_sum(0.5 * tf.square(quadratic_part) + linear_part)
return loss
...
def init_model(self):
state_input = Input(shape=(1, 8, 8), name='state')
action_input = Input(shape=[None], name='action', dtype='int32')
x = Flatten()(state_input)
x = Dense(32, activation='relu')(x)
y_pred = Dense(3, activation='linear', name='main_output')(x)
y_true = Input(shape=(1, ), name='y_true')
loss_out = Lambda(customized_loss, output_shape=(1, ), name='loss')([y_true, y_pred, action_input])
self.model = Model(input=[state_input, action_input, y_true], output=[loss_out, y_pred])
self.model.compile(loss=losses,
optimizer=RMSprop(lr=self.learning_rate),
metrics=['accuracy'])
slef.init_model()
...
res = model.predict({'state': np.array([states]),
'action': np.array([0]), #dummy
'y_true': np.array([[0] * self.n_actions]) #dummy
})
return res[1][0]
...
self.model.fit({'action': np.array(action_minibatch),
'state': np.array(state_minibatch),
'y_true': np.array(y_minibatch)},
[np.zeros([minibatch_size]),
np.array(y_minibatch)],
batch_size=minibatch_size,
nb_epoch=1,
verbose=0)
... überwältigend lästig. Keras hat standardmäßig einen ziemlich einfachen Mechanismus, aber wenn Sie versuchen, etwas zu tun, das davon abweicht, wird es sofort problematisch.
Was sich geändert hat, ist das
- Der Eingabe wurde ein neuer action_input hinzugefügt --y_true wird auch als Eingabe behandelt (drei Eingaben)
- Lambda, das für die Definition der ursprünglichen Ebene verwendet wird, wird zur Berechnung des Verlusts verwendet
- Der Verlustwert und der Q-Wert werden als Ausgabe ausgegeben.
Es ist ein Punkt. Es ist schwer. Dies ist unvermeidlich, solange keine größeren Anpassungen vorgenommen werden können, z. B. das Ändern der Argumente der Verlustfunktion. Diese Methode wird übrigens im offiziellen Keras-Beispiel beschrieben (https://github.com/fchollet/keras/blob/master/examples/image_ocr.py).
Als Punkt
- Mit Lambda können Sie die Eingabe, die Verarbeitung in der Ebene und die Form der Ausgabe frei gestalten.
- Die Eingabe und Ausgabe werden mit dem Namen benannt und dienen zur Vorhersage und Anpassung. --Wenn es mehrere Ausgänge gibt, kann die Verlustfunktion auf jeden angewendet werden.
- Da der Verlustwert in der Ausgabe des Modells enthalten ist, kann die unter model.compile angegebene Verlustfunktion ein Dummy sein. Die auf den Verlustwert anzuwendende Funktion gibt den Wert unverändert aus und die auf den Q-Wert anzuwendende Funktion gibt immer 0 aus. Es ist geworden.
- Geben Sie einen Dummy-Wert für die Eingabe an, die beim Aufruf von Predict nicht verwendet wird (nicht erforderlich?), Und behandeln Sie das Lehrersignal als Eingabe, wenn Sie Fit aufrufen.
Was für ein Ort wie. Um ehrlich zu sein, gibt es eine Theorie, dass es besser ist, Tensorflow zu verwenden, als so zu schreiben, aber wenn Sie nur mit Keras schreiben, wird es dann so sein? Sie können auch Keras für den Modellsatz und Tensorflow für den Rest verwenden.
Tipps4: Optimierer ändern
Da der Artikel länger geworden ist als erwartet, werde ich eine ausführliche Erklärung weglassen (vielleicht werde ich ihn später hinzufügen?). In DQN wird jedoch gesagt, dass die Leistung wahrscheinlich beeinträchtigt wird, wenn RMSPropGraves anstelle des üblichen RMSProp als Optimierer verwendet wird. Ich bin ein Anfänger im maschinellen Lernen, daher bin ich mir nicht sicher, warum es schneller ist, selbst wenn ich mir die Formel ansehe (bitte sagen Sie mir ...), aber wenn es schneller zu lernen ist, möchte ich es definitiv verwenden (außer für DQN + RNN-Papiere usw.). Es scheint, dass Sie den Optimierer von) verwenden. Obwohl dieses RMS PopsGraves standardmäßig in Chainer enthalten ist, ist es nicht in Tensorflow und Keras enthalten (ich habe es nicht ausprobiert, aber es kann möglicherweise mit Keras im Chainer-Hintergrund verwendet werden). Daher müssen Sie den Optimierer selbst implementieren. Tensorflow-Version
Implementierung von DQN (vollständige Version) mit Tensorflow
Bitte beachten Sie die ausführliche Erklärung hier. Es kann implementiert werden, indem man sich die Formel in der Arbeit ansieht [3].
Der Unterschied im Übergang des Verlustwertes bei Wiederholung der Epoche ist wie folgt.
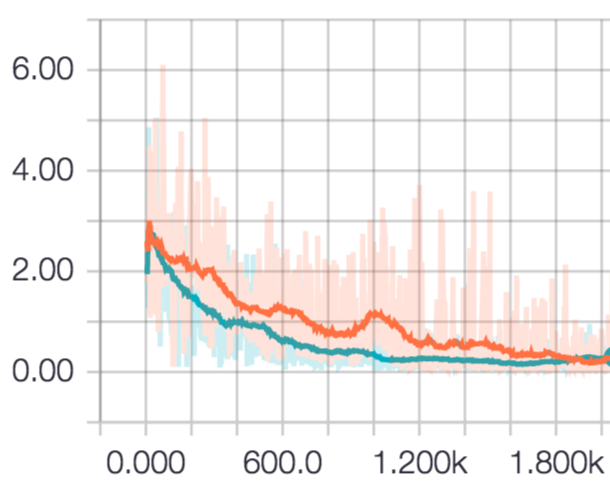
Rot ist RMSProp und Blau ist RMSPropGraves. Anfangs schien RMS PopGraves überlegen zu sein, aber nach 2000-maligem Drehen setzten sich beide auf das gleiche Niveau. Es kann sein, dass die Aufgabe einfach war.
In Keras befindet sich die Definition des Optimierers ausschließlich in https://github.com/yukiB/keras/blob/master/keras/optimizers.py. Es scheint also gut, sie neu zu schreiben. In Bezug auf WIP werde ich den Code an [github] weitergeben (https://github.com/yukiB/keras).
Versuchen Sie es in einem etwas komplizierteren Spiel
Da sich die Leistung des Oita-Modells bisher verbessert haben sollte, erhöhen wir die Anzahl der Pixel und fügen vor der vollständigen Kopplung drei Conv-Ebenen hinzu.

Das Ergebnis des 1000-fachen Drehens ist wie folgt.

Als nächstes machen wir ein etwas komplizierteres Spiel und verwenden dasselbe Modell zum Lernen. Ich habe mit matplotlib leicht ein Spiel namens CAVE implementiert, das ich in der Garakei-Ära sehr oft gespielt habe. Dies ist ein Spiel, in dem der Typ, der beim Drücken des Knopfes nach oben und beim Loslassen des Knopfes nach unten geht, vorgerückt wird, um nicht so weit wie möglich gegen die Wand zu schlagen.
Der Spielbildschirm ist 48x48 groß und verwendet das zuvor erstellte Netzwerk (Conv3-Schicht + vollständig verbundenes Relu).
--Eingabe: Die letzten 4 Frames wurden heruntergesampelt
- Ausgabe: Tasteneingabe (EIN, AUS)
Ich habe es so gemacht.
Infolgedessen habe ich selten die oberen und unteren Wände getroffen, aber ich habe nicht viel darüber gelernt, wie man Blöcke auf dem Weg vermeidet, und meine Punktzahl hat sich nicht verbessert. Derzeit werden 4 Frames als Eingabedaten verwendet, aber es ist möglich, dass rückwirkendere Frame-Daten abhängig von der Positionsbeziehung zwischen Blöcken wirksam sind. Daher ist es möglicherweise besser, DQN usw. in Kombination mit LSTM zu berücksichtigen. nicht. Ich werde das nächste Mal wieder darüber sprechen

(Es ist gefährlich, weil die Zeit auf unbestimmte Zeit vergangen ist, wenn man sich nur die Lernergebnisse ansieht.)
abschließend
Dieses Mal habe ich beim Erstellen eines DQN mit Keras die Stellen aufgegriffen, an denen Anfänger wahrscheinlich stolpern. Dieses Mal habe ich mich mit DQN befasst, weil es mein erstes stärkeres Lernen war, aber ich bin ziemlich hinter der Zeit zurück (die Kombination aus DDQN und LSTM ist immer noch aktiv), also würde ich das nächste Mal gerne A3C usw. verwenden. Ich denke.
Den Code für diese Zeit finden Sie unter hier.
Verweise
[1] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves I. Antonoglou, D. Wierstra, M. Riedmiller. “Playing Atari with Deep Reinforcement Learning” arXiv:1312.5602, 2013. [2] V. Mnih, et al. “Human-level control through deep reinforcement learning” nature, 2015. [3] Alex Graves, “Generating Sequences With Recurrent Neural Networks” arXiv preprint arXiv http://arxiv.org/abs/1308.0850
Recommended Posts