[PYTHON] [Stärkung des Lernens] DQN mit Ihrer eigenen Bibliothek
TL;DR Ich habe DQN mithilfe meiner eigenen Replay Buffer-Bibliothek cpprb implementiert.
Empfohlen, weil es ein hohes Maß an Freiheit und Effizienz hat (ich beabsichtige).
1. Hintergrund und Hintergrund
Verbessertes Lernen wie Open AI / Baselines und Ray / RLlib In einer Reihe von Umgebungen können Sie mit ein wenig Code mit verschiedenen Algorithmen experimentieren.
In Open AI / Baselines heißt es beispielsweise in der offiziellen README, dass Sie nur den folgenden Befehl ausführen müssen, um Ataris Pong mit DQN zu trainieren.
python -m baselines.run --alg=deepq --env=PongNoFrameskip-v4 --num_timesteps=1e6
Auf der anderen Seite ist es einfach, vorhandene Algorithmen zu testen, aber wenn Forscher und Bibliotheksentwickler versuchen, neue proprietäre Algorithmen zu erstellen, denke ich, dass dies zunächst zu groß ist.
Einige meiner Freunde, die Verstärkungslernen studieren, verwenden auch Deep-Learning-Bibliotheken wie TensorFlow, aber andere Teile wurden unabhängig implementiert (wie es scheint).
Gegen Ende 2018 sagte ein Freund: "Interessieren Sie sich für Cython? Der in Python implementierte Wiederholungspuffer ist (je nach Situation) so langsam wie der Lernteil des Tiefenlernens, und ich möchte mit Cython beschleunigen." Es war cpprb, zu dessen Implementierung ich eingeladen wurde (Speicher).
(Der Freund veröffentlichte mit cpprb und TensorFlow 2.x eine erweiterte Lernbibliothek namens tf2rl, die ebenfalls sehr zu empfehlen ist!)
2. Funktionen
Vor diesem Hintergrund wurde mit der Implementierung von cpprb begonnen, daher entwickeln wir es mit dem Schwerpunkt auf einem hohen Maß an Freiheit und Effizienz.
2.1 Hoher Freiheitsgrad
Sie können den Namen, die Größe und den Typ der Variablen, die im Puffer gespeichert werden sollen, frei bestimmen, indem Sie sie im Format "dict" angeben.
Im Extremfall können Sie beispielsweise "next_next_obs", "previous_act", "primary_reward" speichern.
import numpy as np
from cpprb import ReplayBuffer
buffer_size = 1024
#Form und Typ können für jede Variable angegeben werden. Der Standardwert ist{"shape":1,"dtype": np.float32}
rb = ReplayBuffer(buffer_size,
{"obs": {"shape": (3,3)},
"act": {"shape": 3, "dtype": np.int},
"rew": {},
"done": {},
"next_obs": {"shape": (3,3)},
"next_next_obs": {"shape": (3,3)},
"previous_act": {"shape": 3, "dtype": np.int},
"secondary_reward": {}})
# Key-Geben Sie im Wertformat an (wenn die bei der Initialisierung angegebene Variable nicht ausreicht`KeyError`)
rb.add(obs=np.zeros(shape=(3,3)),
act=np.ones(3,dtype=np.int),
rew=0.5,
done=0,
next_obs=np.zeros(shape=(3,3)),
next_next_obs=np.ones(shape=(3,3)),
previous_act=np.ones(3,dtype=np.int),
secondary_reward=0.3)
2.2 Effizienz
Es ist ziemlich schnell, da der Segmentbaum, der die Ursache für die Langsamkeit der Priorized Experience Replay ist, über Cython in C ++ implementiert wird.
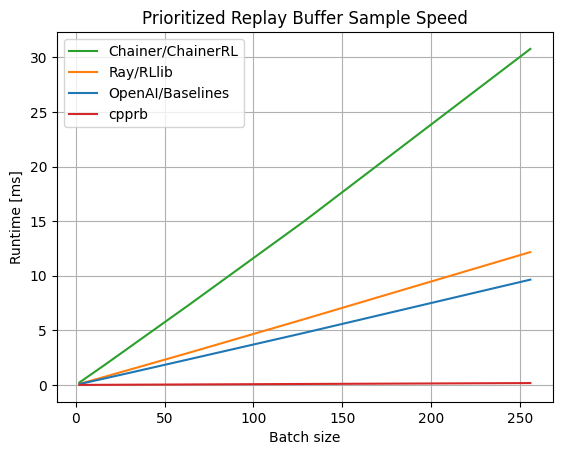
Was den Benchmark betrifft, ist er überwältigend schnell. (Stand April 2020. Die neueste Version finden Sie unter Project Site.)
Hinweis: Beim gesamten Verstärkungslernen sind nicht nur die Geschwindigkeit des Segmentbaums, sondern auch Maßnahmen wie die Parallelisierung der Suchbohrung wichtig
3. Installation
(Siehe auch die neueste [install] -Methode (https://ymd_h.gitlab.io/cpprb/installation/), da die Informationen möglicherweise veraltet sind.)
3.1 Binäre Installation
Da es auf PyPI veröffentlicht ist, kann es mit pip (oder ähnlichen Tools) installiert werden.
Für Windows / Linux verteilen wir Binärdateien im Radformat, sodass Sie sie in vielen Fällen mit dem folgenden Befehl installieren können, ohne an irgendetwas zu denken. (Hinweis: Es wird empfohlen, eine virtuelle Umgebung wie "venv" oder "Docker" zu verwenden.)
pip install cpprb
Hinweis: macOS ist Teil der Standard-Entwicklungs-Toolkette clang, jedoch anstelle des C ++ 17-Feature-Array-Typs "std :: shared_ptr" Da die Spezialisierung von nicht implementiert ist, kann sie nicht kompiliert und die Binärdatei nicht verteilt werden.
3.2 Von der Quelle installieren
Sie müssen selbst aus dem Quellcode erstellen. Zum Erstellen benötigen Sie Folgendes:
- GCC >= 7.2(?)
Sie müssen den Build mit "g ++" in den Umgebungsvariablen "CC" und "CXX" ausführen.
3. DQN-Implementierung
Ich habe einen DQN geschrieben, der auf Google Colab funktioniert
Installieren Sie zunächst die erforderlichen Bibliotheken
!apt update > /dev/null 2>&1
!apt install -y xvfb x11-utils python-opengl > /dev/null
!pip install gym cpprb["all"] tensorflow > /dev/null
%load_ext tensorboard
import os
import datetime
import io
import base64
import numpy as np
from google.colab import files, drive
import gym
import tensorflow as tf
from tensorflow.keras.models import Sequential,clone_model
from tensorflow.keras.layers import InputLayer,Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping,TensorBoard
from tensorflow.summary import create_file_writer
from scipy.special import softmax
from tqdm import tqdm_notebook as tqdm
from cpprb import create_buffer, ReplayBuffer,PrioritizedReplayBuffer
import cpprb.gym
JST = datetime.timezone(datetime.timedelta(hours=+9), 'JST')
a = cpprb.gym.NotebookAnimation()
%tensorboard --logdir logs
#DQN-Test:Modellieren
gamma = 0.99
batch_size = 1024
N_iteration = 101
N_show = 10
per_train = 100
prioritized = True
egreedy = True
loss = "huber_loss"
# loss = "mean_squared_error"
dir_name = datetime.datetime.now(JST).strftime("%Y%m%d-%H%M%S")
logdir = os.path.join("logs", dir_name)
writer = create_file_writer(logdir + "/metrics")
writer.set_as_default()
env = gym.make('CartPole-v0')
env = gym.wrappers.Monitor(env,logdir + "/video/", force=True,video_callable=(lambda ep: ep % 50 == 0))
observation = env.reset()
model = Sequential([InputLayer(input_shape=(observation.shape)), # 4 for CartPole
Dense(64,activation='relu'),
Dense(64,activation='relu'),
Dense(env.action_space.n)]) # 2 for CartPole
target_model = clone_model(model)
optimizer = Adam()
tensorboard_callback = TensorBoard(logdir, histogram_freq=1)
model.compile(loss = loss,
optimizer = optimizer,
metrics=['accuracy'])
a.clear()
rb = create_buffer(1e6,
{"obs":{"shape": observation.shape},
"act":{"shape": 1,"dtype": np.ubyte},
"rew": {},
"next_obs": {"shape": observation.shape},
"done": {}},
prioritized = prioritized)
action_index = np.arange(env.action_space.n).reshape(1,-1)
#Zufällige erste Suche
for n_episode in range (1000):
observation = env.reset()
sum_reward = 0
for t in range(500):
action = env.action_space.sample() #Zufällige Auswahl von Aktionen
next_observation, reward, done, info = env.step(action)
rb.add(obs=observation,act=action,rew=reward,next_obs=next_observation,done=done)
observation = next_observation
if done:
break
for n_episode in tqdm(range (N_iteration)):
observation = env.reset()
for t in range(500):
if n_episode % (N_iteration // N_show)== 0:
a.add(env)
actions = softmax(np.ravel(model.predict(observation.reshape(1,-1),batch_size=1)))
actions = actions / actions.sum()
if egreedy:
if np.random.rand() < 0.9:
action = np.argmax(actions)
else:
action = env.action_space.sample()
else:
action = np.random.choice(actions.shape[0],p=actions)
next_observation, reward, done, info = env.step(action)
sum_reward += reward
rb.add(obs=observation,
act=action,
rew=reward,
next_obs=next_observation,
done=done)
observation = next_observation
sample = rb.sample(batch_size)
Q_pred = model.predict(sample["obs"])
Q_true = target_model.predict(sample['next_obs']).max(axis=1,keepdims=True)*gamma*(1.0 - sample["done"]) + sample['rew']
target = tf.where(tf.one_hot(tf.cast(tf.reshape(sample["act"],[-1]),dtype=tf.int32),env.action_space.n,True,False),
tf.broadcast_to(Q_true,[batch_size,env.action_space.n]),
Q_pred)
if prioritized:
TD = np.square(target - Q_pred).sum(axis=1)
rb.update_priorities(sample["indexes"],TD)
model.fit(x=sample['obs'],
y=target,
batch_size=batch_size,
verbose = 0)
if done:
break
if n_episode % 10 == 0:
target_model.set_weights(model.get_weights())
tf.summary.scalar("reward",data=sum_reward,step=n_episode)
rb.clear()
a.display()
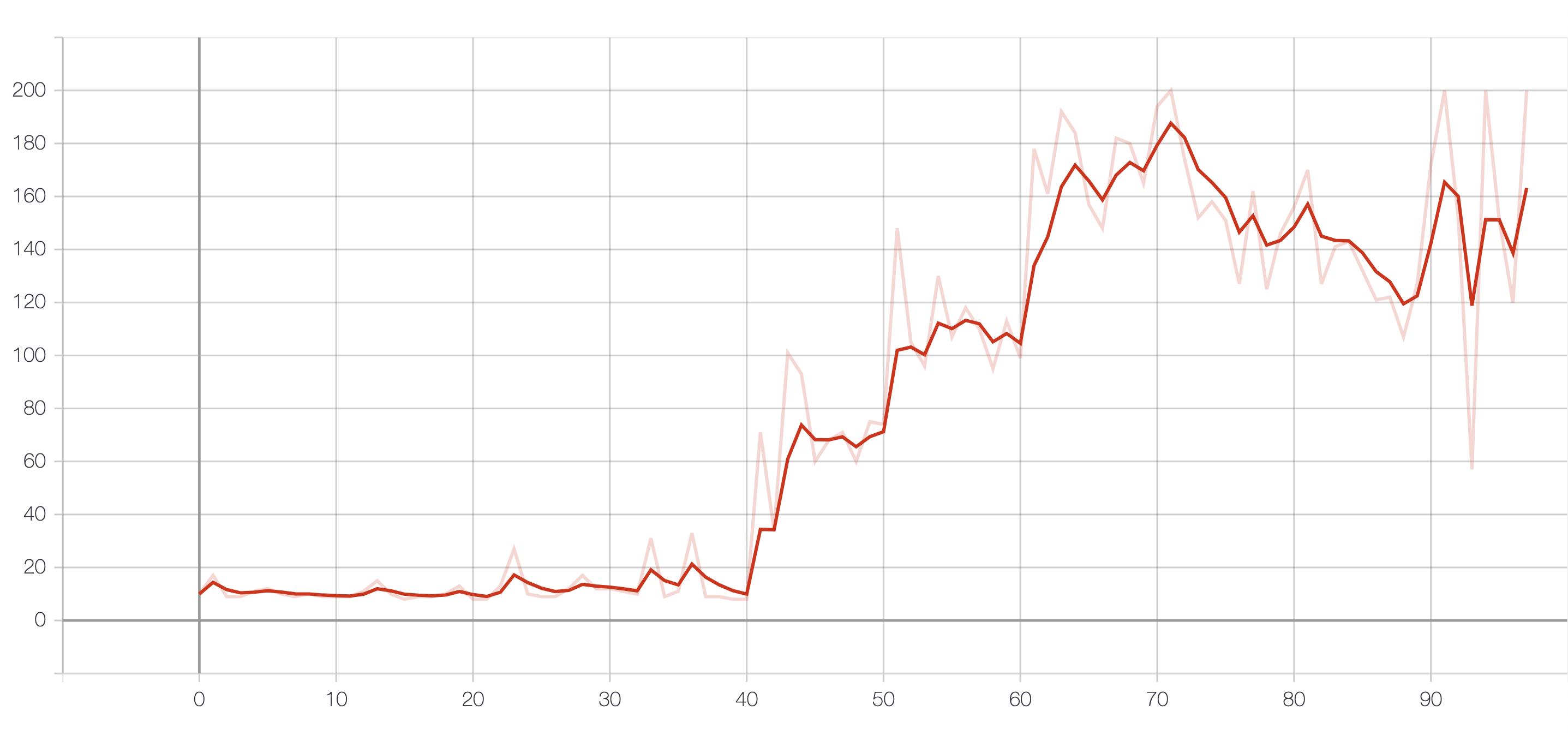
4. Ergebnis
Das Ergebnis der Belohnung.
6. Zusammenfassung
DQN wurde mithilfe einer selbst erstellten Bibliothek cpprb implementiert, die einen Wiedergabepuffer für erweitertes Lernen bereitstellt.
cpprb wird mit einem hohen Maß an Freiheit und Effizienz entwickelt.
Wenn Sie interessiert sind, probieren Sie es bitte aus und stellen Sie ein Problem oder eine Zusammenführungsanforderung. (Englisch ist vorzuziehen, aber Japanisch ist auch in Ordnung)
Referenzlink
Recommended Posts