[PYTHON] Herausforderung Blockbruch mit Actor-Critic-Modell zur Stärkung des Lernens
Einführung
Ich werde das Blockbrechen von OpenAI Gym herausfordern.
 Bild von OpenAI ausgeliehen
https://gym.openai.com/videos/2019-10-21--mqt8Qj1mwo/Breakout-v0/poster.jpg
Bild von OpenAI ausgeliehen
https://gym.openai.com/videos/2019-10-21--mqt8Qj1mwo/Breakout-v0/poster.jpg
Dieses Mal werden wir Keras verwenden, um ein Actor-Critic-Modell zu erstellen und zu trainieren. Keras ist eine API, die die Einführung von Deep Learning erleichtert, und ich denke, sie ist ein gutes Beispiel für Anfänger, da nur wenige Variablen und Funktionen von Ihnen selbst angepasst werden müssen.
Das Actor-Critic-Modell ist eines der erweiterten Lernmodelle. Eine ausführliche Erklärung finden Sie im Tensorflow-Blog. (https://www.tensorflow.org/tutorials/reinforcement_learning/actor_critic) Im Gegensatz zum CartPole-Beispiel des Links werden wir diesmal jedoch den Block aufheben. Ich benutze das CNN-Netzwerk, weil es weit mehr Blockbrüche gibt (84 x 84 Bilder pro Frame) als vier Variablen wie CartPole. Die detaillierte Konfiguration wird später erklärt.
Dieser Artikel basiert auf einem Artikel, der im Juli auf Github veröffentlicht wurde. https://github.com/leolui2004/atari_rl_ac
Ergebnis
Ich werde das Ergebnis zuerst veröffentlichen. 1 Training = 1 Spiel, 5000 Trainings über 8 Stunden (Folge). Das Ergebnis ergibt den Durchschnitt der letzten 50 Male. Das erste Blatt ist die Punktzahl und das zweite Blatt ist die Anzahl der Schritte (Zeitschritt).
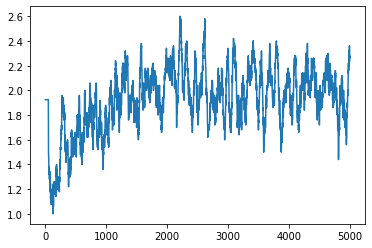
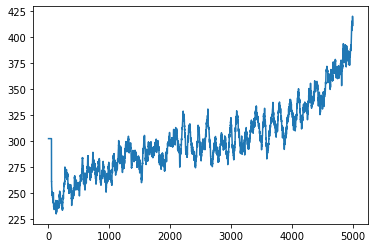
Die Punktzahl scheint sich etwas erhöht zu haben, aber die Anzahl der Schritte ergab ein erheblich besseres Ergebnis. Übrigens kann ich zunächst nicht durchschnittlich 50 Mal bekommen, also sieht es abnormal aus.
Weise
Das Gameplay und das verbesserte Lernen werden separat erklärt. Der Gameplay-Teil spielt das Spiel in der Gym-Umgebung von OpenAI. Der Verstärkungsteil trainiert die vom Spiel empfangenen Variablen und spiegelt die vorhergesagten Aktionen im Spiel wider.
Spielweise
import gym
import random
import numpy as np
env = gym.make('Breakout-v4')
episode_limit = 5000
random_step = 20
timestep_limit = 100000 #Für immer vom Spielen ausgeschlossen
model_train = 1 #Kein Training bei 0(Nur zufälliges Spiel)
log_save = 1 #Bei der Einstellung 0 wird das Protokoll nicht gespeichert
log_path = 'atari_ac_log.txt'
score_list = []
step_list = []
for episode in range(episode_limit):
#Setzen Sie die Umgebung zurück, bevor Sie jedes Mal spielen
observation = env.reset()
score = 0
#Machen Sie nichts mit der ersten zufälligen Anzahl von Schritten, um die Position des Balls zufällig zu bestimmen
for _ in range(random.randint(1, random_step)):
observation_last = observation
observation, _, _, _ = env.step(0)
#Codieren Sie die beobachteten Daten der Aktion(Ich werde es später erklären)
state = encode_initialize(observation, observation_last)
for timestep in range(timestep_limit):
observation_last = observation
#Holen Sie sich die Aktion aus dem Modell vorherzusagen(Ich werde es später erklären)
action = action_choose(state[np.newaxis, :], epsilon, episode, action_space)
#Aktion basierend auf vorhergesagter Aktion
observation, reward, done, _ = env.step(action)
#Codieren Sie die beobachteten Daten der Aktion(Ich werde es später erklären)
state_next = encode(observation, observation_last, state)
if model_train == 1:
#Senden Sie die Beobachtungsdaten des Verhaltens zum Lernen an das Modell(Ich werde es später erklären)
network_learn(state[np.newaxis, :], action, reward, state_next[np.newaxis, :], done)
state = state_next
score += reward
#Spielende oder Zeitschritt_Grenze erreichen(erzwungene Kündigung)
if done or timestep == timestep_limit - 1:
#Ergebnisse aufzeichnen
score_list.append(score)
step_list.append(timestep)
if log_save == 1:
log(log_path, episode, timestep, score)
print('Episode {} Timestep {} Score {}'.format(episode + 1, timestep, score))
break
#Eine Funktion, die Aktionen bis zu einem gewissen Grad randomisiert(Ich werde es später erklären)
epsilon = epsilon_reduce(epsilon, episode)
env.close()
Lernen stärken
Der codierte Teil ist die Graustufenkonvertierung, bei der die Größe von vier aufeinanderfolgenden 84x84-Bildern (Frames) geändert und synthetisiert wird. Dies bedeutet, dass Sie die Aktion des Balls besser aufzeichnen können und es einfacher ist, zu trainieren.
from skimage.color import rgb2gray
from skimage.transform import resize
frame_length = 4
frame_width = 84
frame_height = 84
def encode_initialize(observation, last_observation):
processed_observation = np.maximum(observation, last_observation)
processed_observation_resize = np.uint8(resize(rgb2gray(processed_observation), (frame_width, frame_height)) * 255)
state = [processed_observation_resize for _ in range(frame_length)]
state_encode = np.stack(state, axis=0)
return state_encode
def encode(observation, last_observation, state):
processed_observation = np.maximum(observation, last_observation)
processed_observation_resize = np.uint8(resize(rgb2gray(processed_observation), (frame_width, frame_height)) * 255)
state_next_return = np.reshape(processed_observation_resize, (1, frame_width, frame_height))
state_encode = np.append(state[1:, :, :], state_next_return, axis=0)
return state_encode
Der Netzwerk- und Trainingsteil ist am schwierigsten, aber es sieht so aus, wenn es zuerst in einem Diagramm dargestellt wird.
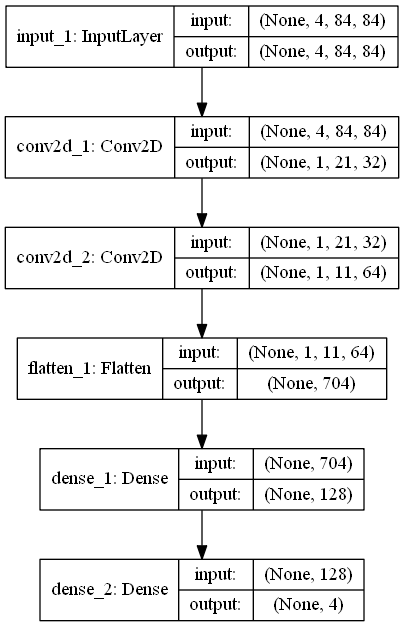
Senden Sie die vorcodierten Daten an die Conv2D-Schicht mit zwei Schichten. Dann glätten Sie es und senden Sie es an die beiden dichten Schichten. Schließlich gibt es vier Ausgänge (NOPE, FIRE, LEFT, RIGHT gemäß den Spezifikationen von OpenAI Gym Breakout-v4). Übrigens ist die Aktivierungsfunktion relu, die Verlustfunktion entspricht dem Papier und die Lernrate beträgt 0,001 für Schauspieler und Kritiker.
from keras import backend as K
from keras.layers import Dense, Input, Flatten, Conv2D
from keras.models import Model, load_model
from keras.optimizers import Adam
from keras.utils import plot_model
verbose = 0
action_dim = env.action_space.n
action_space = [i for i in range(action_dim)] # ['NOOP', 'FIRE', 'RIGHT', 'LEFT']
discount = 0.97
actor_lr = 0.001 #Lernrate des Schauspielers
critic_lr = 0.001 #Kritiker Lernrate
pretrain_use = 0 #Auf 1 setzen, um das trainierte Modell zu verwenden
actor_h5_path = 'atari_ac_actor.h5'
critic_h5_path = 'atari_ac_critic.h5'
#Modellbau
input = Input(shape=(frame_length, frame_width, frame_height))
delta = Input(shape=[1])
con1 = Conv2D(32, (8, 8), strides=(4, 4), padding='same', activation='relu')(input)
con2 = Conv2D(64, (4, 4), strides=(2, 2), padding='same', activation='relu')(con1)
fla1 = Flatten()(con2)
dense = Dense(128, activation='relu')(fla1) #prob,Aktienwert
prob = Dense(action_dim, activation='softmax')(dense) #Schauspieler Teil
value = Dense(1, activation='linear')(dense) #kritischer Teil
#Definition der Verlustfunktion
def custom_loss(y_true, y_pred):
out = K.clip(y_pred, 1e-8, 1-1e-8) #Grenzen setzen
log_lik = y_true * K.log(out) #Richtlinienverlauf
return K.sum(-log_lik * delta)
if pretrain_use == 1:
#Verwenden Sie ein geschultes Modell
actor = load_model(actor_h5_path, custom_objects={'custom_loss': custom_loss}, compile=False)
critic = load_model(critic_h5_path)
actor = Model(inputs=[input, delta], outputs=[prob])
critic = Model(inputs=[input], outputs=[value])
policy = Model(inputs=[input], outputs=[prob])
actor.compile(optimizer=Adam(lr=actor_lr), loss=custom_loss)
critic.compile(optimizer=Adam(lr=critic_lr), loss='mean_squared_error')
#Aktion vorhersagen
def action_choose(state, epsilon, episode, action_space):
#Epsilon zuerst auf 1 gesetzt und allmählich abnehmen
#Im Vergleich zu Zufallszahlen bei jedem Handeln
#Ergreifen Sie zufällige Maßnahmen, wenn Epsilon größer ist
if epsilon >= random.random() or episode < initial_replay:
action = random.randrange(action_dim)
else:
probabiliy = policy.predict(state)[0]
#Die vorhergesagten Ergebnisse haben Wahrscheinlichkeiten für jede der vier Aktionen
#Wählen Sie eine Aktion entsprechend dieser Wahrscheinlichkeit
action = np.random.choice(action_space, p=probabiliy)
return action
#Daten lernen
def network_learn(state, action, reward, state_next, done):
reward_clip = np.sign(reward)
critic_value = critic.predict(state)
critic_value_next = critic.predict(state_next)
target = reward_clip + discount * critic_value_next * (1 - int(done))
delta = target - critic_value
actions = np.zeros([1, action_dim])
actions[np.arange(1), action] = 1
actor.fit([state, delta], actions, verbose=verbose)
critic.fit(state, target, verbose=verbose)
Dieser Teil steht nicht in direktem Zusammenhang mit verbessertem Lernen als einer anderen Funktion, aber ich werde ihn zusammen schreiben.
import matplotlib.pyplot as plt
model_save = 1 #0 speichert das Modell nicht
score_avg_freq = 50
epsilon_start = 1.0 #Wahrscheinlichkeit zu Beginn von Epsilon
epsilon_end = 0.1 #epsilon niedrigste Wahrscheinlichkeit(Mindestens 10%Zufällige Aktion mit)
epsilon_step = episode_limit
epsilon = 1.0
epsilon_reduce_step = (epsilon_start - epsilon_end) / epsilon_step
initial_replay = 200
actor_graph_path = 'atari_ac_actor.png'
critic_graph_path = 'atari_ac_critic.png'
policy_graph_path = 'atari_ac_policy.png'
#Epsilon-Absenkfunktion
def epsilon_reduce(epsilon, episode):
if epsilon > epsilon_end and episode >= initial_replay:
epsilon -= epsilon_reduce_step
return epsilon
#Schreiben Sie ein Protokoll
def log(log_path, episode, timestep, score):
logger = open(log_path, 'a')
if episode == 0:
logger.write('Episode Timestep Score\n')
logger.write('{} {} {}\n'.format(episode + 1, timestep, score))
logger.close()
if pretrain_use == 1:
if model_save == 1:
actor.save(actor_h5_path)
critic.save(critic_h5_path)
else:
if model_save == 1:
actor.save(actor_h5_path)
critic.save(critic_h5_path)
#Konfiguration des Ausgabemodells in Abbildung
plot_model(actor, show_shapes=True, to_file=actor_graph_path)
plot_model(critic, show_shapes=True, to_file=critic_graph_path)
plot_model(policy, show_shapes=True, to_file=policy_graph_path)
#Geben Sie das Ergebnis in die Abbildung ein
xaxis = []
score_avg_list = []
step_avg_list = []
for i in range(1, episode_limit + 1):
xaxis.append(i)
if i < score_avg_freq:
score_avg_list.append(np.mean(score_list[:]))
step_avg_list.append(np.mean(step_list[:]))
else:
score_avg_list.append(np.mean(score_list[i - score_avg_freq:i]))
step_avg_list.append(np.mean(step_list[i - score_avg_freq:i]))
plt.plot(xaxis, score_avg_list)
plt.show()
plt.plot(xaxis, step_avg_list)
plt.show()
Recommended Posts