[PYTHON] Erkennen Sie Ihren Chef mit Deep Learning und verbergen Sie den Bildschirm
Hintergrund
Wenn Sie bei der Arbeit sind, durchsuchen alle nicht geschäftliche Informationen, oder?
Zu dieser Zeit ist es mir unangenehm, dass sich der Chef hinter mich schleicht. Natürlich können Sie schnell den Bildschirm wechseln, aber diese Art von Verhalten kann verdächtig sein und Sie bemerken es möglicherweise nicht, wenn Sie sich konzentrieren. Um den Bildschirm zu wechseln, ohne misstrauisch zu sein, habe ich ein System erstellt, das automatisch erkennt, dass sich der Chef nähert, und den Bildschirm verbirgt.
Insbesondere wird Keras </ font> verwendet, um das Gesicht des Chefs maschinell zu lernen, und die Kamera wird verwendet, um zu erkennen, dass es sich nähert, und um den Bildschirm zu wechseln.
Mission
Die Mission ist es, die Bildschirme automatisch zu wechseln, wenn sich der Chef nähert.
Die Situation ist wie folgt.
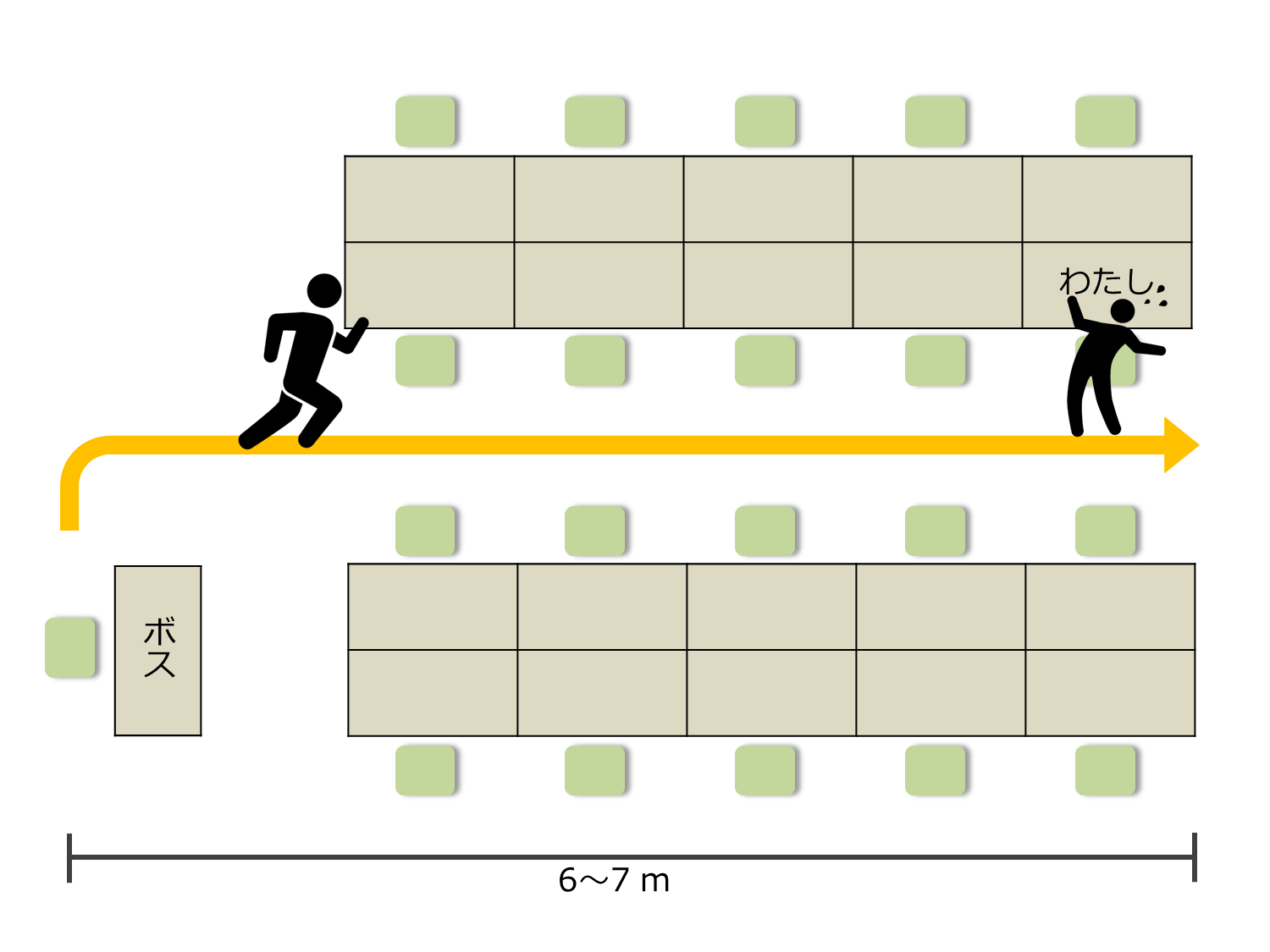
Die Entfernung vom Sitz des Chefs zu meinem Sitz beträgt ungefähr 6,7 m. Es dauert 4,5 Sekunden, nachdem der Chef meinen Sitz verlassen hat, um meinen Sitz zu erreichen. Daher ist es notwendig, den Bildschirm während dieser Zeit auszublenden. Ich habe nicht viel Zeit zu verlieren.
Strategie ~ Wie verstecke ich den Bildschirm? ~
Ich denke, es gibt viele mögliche Strategien, aber meine Idee ist diese.
Verwenden Sie zunächst maschinelles Lernen, damit der Computer das Gesicht des Chefs im Voraus lernt. Installieren Sie dann eine Webkamera in Ihrem Sitz und schalten Sie den Bildschirm um, wenn die Webkamera das Gesicht des Chefs erfasst. Es ist die perfekte Strategie. Nennen wir dieses wunderbare System "** Boss Sensor **".

Konfiguration des Boss-Sensorsystems
Die supereinfache Systemkonfiguration des Boss-Sensors ist wie folgt.

- Holen Sie sich Bilder in Echtzeit mit einer Webkamera.
- Die Gesichtserkennung und Gesichtserkennung wird für das erfasste Bild mithilfe des Lernmodells durchgeführt.
- Wenn das Erkennungsergebnis der Chef ist, wechseln Sie den Bildschirm.
Die folgenden Techniken sind erforderlich, um dies zu tun:
- Holen Sie sich Gesichtsbild
- Gesichtsbilderkennung
- Bildschirmumschaltung
Lassen Sie uns sie einzeln untersuchen und schließlich integrieren.
Holen Sie sich Gesichtsbild
Holen Sie sich zuerst das Bild von der Webkamera.
Die diesmal verwendete Webkamera ist [BUFFALO BSW20KM11BK](https://www.amazon.co.jp/%E3%83%90%E3%83%83%E3%83%95%E3%82%A1%E3 % 83% AD% E3% 83% BC-BSW20KM11BK-iBUFFALO-% E3% 83% 9E% E3% 82% A4% E3% 82% AF% E5% 86% 85% E8% 94% B5200% E4% B8% 87% E7% 94% BB% E7% B4% A0WEB% E3% 82% AB% E3% 83% A1% E3% 83% A9-120% C2% B0% E5% BA% 83% E8% A7% 92% E3% 82% AC% E3% 83% A9% E3% 82% B9% E3% 83% AC% E3% 83% B3% E3% 82% BA% E6% 90% AD% E8% BC% 89% E3% 83% A2% E3% 83% 87% E3% 83% AB / dp / B008AO4KXQ).

Ich denke, dass jede Webkamera funktioniert, solange sie eine gewisse Leistung hat.
Sie können das Bild mit der angeschlossenen Software von der Kamera abrufen. Angesichts der späteren Verarbeitung ist es jedoch besser, es vom Programm abzurufen. Da die Gesichtserkennung bei der nachfolgenden Verarbeitung durchgeführt wird, muss nur das Gesichtsbild ausgeschnitten werden. Lassen Sie uns das Gesichtsbild mit Python und OpenCV erstellen. Hier ist der Code dafür:
Ich konnte ein besseres Gesichtsbild bekommen als ich erwartet hatte.

Das Gesicht des Chefs lernen und erkennen
Verwenden Sie dann maschinelles Lernen, damit der Computer das Gesicht des Chefs erkennt. Die folgenden drei Punkte sind eine grobe Prozedur:
- Sammlung von Bildern
- Bildverarbeitung
- Erstellen Sie ein Modell für maschinelles Lernen
Schauen wir uns diese einzeln an.
Sammlung von Bildern
Zunächst müssen Sie sich ein Bild zum Lernen machen. Ich habe die folgende Erfassungsmethode verwendet:
- Google Bildsuche
- Sammle Bilder auf Facebook
- Mit einer Kamera aufgenommen
Zuerst habe ich Bilder von der Websuche und von Facebook gesammelt, aber ich habe nicht genug Bilder bekommen. Daher habe ich eine Videokamera verwendet, um ein Video aufzunehmen und das Video in Bilder zu zerlegen.
Bildverarbeitung
Übrigens konnte ich eine große Anzahl von Bildern mit Gesichtern erhalten, aber ich kann sie nicht so auf das Lerngerät setzen, wie sie sind. Dies liegt daran, dass der Teil, der nichts mit dem Gesicht zu tun hat, einen großen Teil des Bildes einnimmt. Daher werde ich nur das Gesichtsbild ausschneiden.
Ich habe hauptsächlich ImageMagick zum Ausschneiden verwendet. Sie können nur das Gesichtsbild erhalten, indem Sie es mit ImageMagick ausschneiden.
Viele Gesichtsbilder wurden so gesammelt:

Vielleicht bin ich die Person, die das Gesichtsbild des Chefs der Welt hat. Muss mehr als Eltern haben.
Jetzt bist du bereit zu lernen.
Erstellen eines Modells für maschinelles Lernen
Das Lernen erfolgt durch Aufbau eines Faltungs-Neuronalen Netzwerks (CNN) mit Keras. TensorFlow wird für das Backend von Keras verwendet. Wenn Sie nur das Gesicht erkennen möchten, können Sie die Web-API zur Bilderkennung verwenden. Dieses Mal habe ich mich jedoch entschlossen, es unter Berücksichtigung der Echtzeitleistung selbst zu erstellen.
Das Netzwerk hat die folgende Konfiguration. Keras ist praktisch, da Sie die Konfiguration einfach ausgeben können.
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
convolution2d_1 (Convolution2D) (None, 32, 64, 64) 896 convolution2d_input_1[0][0]
____________________________________________________________________________________________________
activation_1 (Activation) (None, 32, 64, 64) 0 convolution2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_2 (Convolution2D) (None, 32, 62, 62) 9248 activation_1[0][0]
____________________________________________________________________________________________________
activation_2 (Activation) (None, 32, 62, 62) 0 convolution2d_2[0][0]
____________________________________________________________________________________________________
maxpooling2d_1 (MaxPooling2D) (None, 32, 31, 31) 0 activation_2[0][0]
____________________________________________________________________________________________________
dropout_1 (Dropout) (None, 32, 31, 31) 0 maxpooling2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_3 (Convolution2D) (None, 64, 31, 31) 18496 dropout_1[0][0]
____________________________________________________________________________________________________
activation_3 (Activation) (None, 64, 31, 31) 0 convolution2d_3[0][0]
____________________________________________________________________________________________________
convolution2d_4 (Convolution2D) (None, 64, 29, 29) 36928 activation_3[0][0]
____________________________________________________________________________________________________
activation_4 (Activation) (None, 64, 29, 29) 0 convolution2d_4[0][0]
____________________________________________________________________________________________________
maxpooling2d_2 (MaxPooling2D) (None, 64, 14, 14) 0 activation_4[0][0]
____________________________________________________________________________________________________
dropout_2 (Dropout) (None, 64, 14, 14) 0 maxpooling2d_2[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 12544) 0 dropout_2[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 512) 6423040 flatten_1[0][0]
____________________________________________________________________________________________________
activation_5 (Activation) (None, 512) 0 dense_1[0][0]
____________________________________________________________________________________________________
dropout_3 (Dropout) (None, 512) 0 activation_5[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 2) 1026 dropout_3[0][0]
____________________________________________________________________________________________________
activation_6 (Activation) (None, 2) 0 dense_2[0][0]
====================================================================================================
Total params: 6489634
Der Code ist hier:
Wenn Sie dies bisher tun können, können Sie es als Chef erkennen, wenn der Chef auf der Kamera erscheint.
Bildschirmumschaltung
Nachdem wir nun das Gesicht des Chefs anhand des trainierten Modells erkannt haben, müssen wir den Bildschirm wechseln. Dieses Mal bereiten wir einfach ein Bild des Arbeitsstils vor und zeigen es an. Da ich Programmierer bin, habe ich die folgenden Bilder vorbereitet.

Es ist wie arbeiten. Alles was Sie tun müssen, ist dieses Bild anzuzeigen.
Ich möchte das Bild im Vollbildmodus anzeigen, daher werde ich es mit PyQt anzeigen. Hier ist der Code dafür:
Jetzt ist alles fertig.
Komplett
Es ist abgeschlossen, wenn die bisher verifizierten Technologien kombiniert werden. Ich habe es tatsächlich versucht.
"Der Chef hat seinen Platz verlassen. Er nähert sich meinem Platz."

"OpenCV hat das Gesicht erkannt. Es wirft das Bild in das Lernmodell."

"Sicherlich habe ich erkannt, dass ich der Boss bin und der Bildschirm hat sich geändert. ヽ ('∇') No wai"

Betrachtung
Mit Selbstdisziplin.
Obwohl die Genauigkeit des Testsatzbildes hoch war, war das von der Webkamera aufgenommene Bild manchmal schwer zu erkennen. Es scheint, dass es mit dem Grad des Lichteinschlags und der Unschärfe des Bildes zusammenhängt. Ich muss die Bildnormalisierung richtig machen.
Die Klassifizierung war eine binäre Klassifizierung des Chefs oder einer anderen Person, aber wenn ein anderes Bild als das Gesichtsbild eingegeben wurde, wurde es manchmal als Chef klassifiziert. Wenn überhaupt, war es ein Chef. Es wäre vielleicht besser gewesen, die Wahrscheinlichkeit zu erkennen, ein Boss zu sein, als eine binäre Klassifizierung.
Die Bildverarbeitung ist schwierig.
Quellcode
Sie können den Quellcode aus den folgenden Repositorys herunterladen.
abschließend
Dieses Mal habe ich versucht, den Chef zu erkennen und den Bildschirm auszublenden, indem ich die Echtzeit-Bilderfassung von der Webkamera und die Gesichtserkennung mit Keras kombiniert habe.
Derzeit verwende ich OpenCV für die Gesichtserkennung, aber ich bin der Meinung, dass die Genauigkeit der Gesichtserkennung mit OpenCV nicht gut ist. Daher möchte ich diesen Bereich mithilfe von Dlib verbessern. Ich möchte ein Gesichtserkennungsmodell verwenden, das ich selbst trainiert habe.
Früher habe ich PyQt verwendet, um das Windbild anzuzeigen, an dem ich gearbeitet habe, aber es dauert lange vom Befehl bis zur Anzeige, daher muss ich diesen Bereich verbessern.
Die Erkennungsgenauigkeit der von der Webkamera aufgenommenen Bilder ist nicht gut genug, daher möchte ich sie von Zeit zu Zeit verbessern.
Die Realität war nicht süß
Recommended Posts