[PYTHON] Machen Sie ASCII-Kunst mit tiefem Lernen
Freut mich, dich kennenzulernen. Das Hauptgeschäft heißt Oscii Art, ein Handwerker der ASCII-Kunst (AA) (nicht das Hauptgeschäft). Als ich das Spiel zwischen AlphaGo und Lee Sedol sah, dachte ich: "** Ich möchte auch Gott AA-Handwerker mit tiefem Lernen besiegen! **", also werde ich Python installieren und die Ergebnisse von nur einem Jahr schreiben.
Der Code ist hier oben. https://github.com/OsciiArt/DeepAA
Was wird hier mit ASCII-Kunst behandelt?
Was wird hier AA verwendet?
Das ist ... ↓
 Nicht so ... ↓
Nicht so ... ↓
 Nicht so ... ↓
Nicht so ... ↓
 Es ist ein bisschen anders, so …… ↓
Es ist ein bisschen anders, so …… ↓
 Aber natürlich ist es so. ↓
Aber natürlich ist es so. ↓

Hier werden wir uns mit einem AA-Typ namens "** Trace AA **" befassen, der eine Strichzeichnung durch Erstellen von Zeichen reproduziert. Weitere Informationen finden Sie im Abschnitt "Proportionalschriftarten" auf der Seite "Ascii Art" auf Wikipedia.
[wikipedia: ASCII Art-Proportional Fonts](https://ja.wikipedia.org/wiki/%E3%82%A2%E3%82%B9%E3%82%AD%E3%83%BC%E3%82% A2% E3% 83% BC% E3% 83% 88 # .E3.83.97.E3.83.AD.E3.83.9D.E3.83.BC.E3.82.B7.E3.83.A7.E3. 83.8A.E3.83.AB.E3.83.95.E3.82.A9.E3.83.B3.E3.83.88.E3.81.AE.E3.82.82.E3.81.AE)
Bedingungen wie Schriftarten sind 2-Kanal-Spezifikationen,
- MS P Gothic
- Größe 16 Pixel
- 2 Pixel zwischen den Zeilen
Ist weit verbreitet.
Gut oder schlecht der ASCII-Kunst
Es gibt viele Missverständnisse, aber als Voraussetzung ist AA im Grunde genommen ** handgeschrieben **. (Ein Beispiel für ein Missverständnis: Yahoo Chiebukuro: Ich sehe AA ASCII-Kunst in zwei Kanälen. Wie mache ich das?)
Es gibt einige Software, die automatisch AA erstellt, aber die aktuelle Situation ist, dass es weit von menschlicher Handschrift entfernt ist. Eine Sache, die Sie bei der Entscheidung, ob AA gut oder schlecht ist, beachten sollten, ist die ** Größe **. Wenn Sie es unendlich groß machen, kann ein Zeichen ein Pixel darstellen und das Originalbild kann vollständig reproduziert werden (auch mit Software). Stattdessen ist AA, das mehr Zeilen mit einem Zeichen ausdrückt und die Größe klein hält, eine gute AA.
Mit anderen Worten, das Gute oder Schlechte von AA
** Reproduzierbarkeit des Originalbildes ÷ Größe **
Kann definiert werden als.
Trainingsdaten
Das Erlernen von Deep Learning erfordert eine große Anzahl von Originalbild- und AA-Paaren. AA wird jedoch grundsätzlich nicht als Paar mit dem Originalbild angekündigt. Daher ist die Datenerfassung schwierig. Darüber hinaus verformt AA häufig die Linien des Originalbilds erheblich, und selbst wenn ein Paar erhalten wird, wird erwartet, dass das Lernen schwierig sein wird. Daher haben wir dieses Mal das scheinbar ursprüngliche Bild von AA generiert und es als Trainingsdaten verwendet. Der Ansatz in diesem Bereich basierte auf der Forschung von Simocera Edgar et al. (Automatische Strichzeichnung einer groben Skizze). ..
Verfahren
- Bild AA.
 2. Dies ist weit von der eigentlichen Strichzeichnung entfernt. Verwenden Sie daher den Webdienst Automatische Strichzeichnung einer groben Skizze von Simocera Edgar et al. Lass es wie eine Strichzeichnung aussehen.
2. Dies ist weit von der eigentlichen Strichzeichnung entfernt. Verwenden Sie daher den Webdienst Automatische Strichzeichnung einer groben Skizze von Simocera Edgar et al. Lass es wie eine Strichzeichnung aussehen.
 3. Schneiden Sie das Bild in 64 x 64 Pixel aus und verwenden Sie die Zeichen, die dem zentralen 16 x 16-Bereich entsprechen, als korrekte Beschriftung.
3. Schneiden Sie das Bild in 64 x 64 Pixel aus und verwenden Sie die Zeichen, die dem zentralen 16 x 16-Bereich entsprechen, als korrekte Beschriftung.
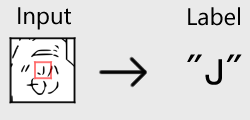 4. Dieser Prozess wurde an ungefähr 200 AAs durchgeführt und als Trainingsdaten verwendet.
4. Dieser Prozess wurde an ungefähr 200 AAs durchgeführt und als Trainingsdaten verwendet.
Lernen
Das verwendete Framework war Keras (Backend: TensorFlow). Für das Netzwerk verwendeten wir ein Standard-Faltungs-Neuronales Netzwerk zur Klassifizierung. Der Code wird unten angezeigt.
def DeepAA(num_label=615, drop_out=0.5, weight_decay=0.001, input_shape = [64, 64]):
"""
Build Deep Neural Network.
:param num_label: int, number of classes, equal to candidates of characters
:param drop_out: float
:param weight_decay: float
:return:
"""
reg = l2(weight_decay)
imageInput = Input(shape=input_shape)
x = Reshape([input_shape[0], input_shape[1], 1])(imageInput)
x = GaussianNoise(0.1)(x)
x = Convolution2D(16, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Dropout(drop_out)(x)
x = Convolution2D(32, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Dropout(drop_out)(x)
x = Convolution2D(64, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Dropout(drop_out)(x)
x = Convolution2D(128, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Flatten()(x)
x = Dropout(drop_out)(x)
y = Dense(num_label, activation='softmax')(x)
model = Model(input=imageInput, output=y)
return model
Lernbedingungen
- Anzahl der Daten: 484654
- Stapelgröße: 128
- Anzahl der Lernvorgänge: 20.000 Chargen
- Verlustfunktion: Kreuzentropie
- Optimierungsfunktion: Adam
Mit den obigen Einstellungen habe ich ungefähr 2 Tage lang auf einem Computer ohne GPU trainiert.
Ergebnis
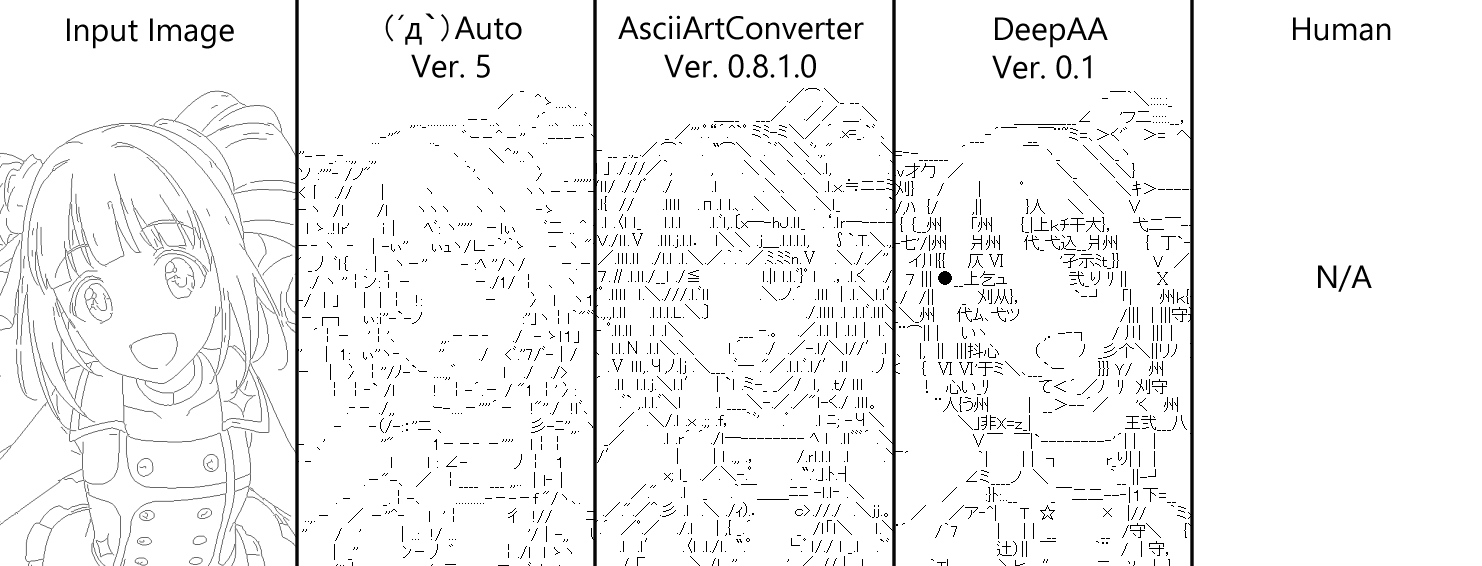
Hier ist ein Vergleich mit einer anderen automatischen AA-Erstellungssoftware ↓

- Eingabebild: Originalbild
- (´д `) Auto: Creator --kuronowish, wo man es bekommt - (´д `) Evakuierungszentrum des Saitama Sales Office bearbeiten --AsciiArtConverter: Creator --Mr. Uryu P, Bezugsquellen-- test --DeepAA: Vorgeschlagene Methode dieses Artikels (im Folgenden als DeepAA bezeichnet)
- Mensch: Handschriftliche AA
Die Größeneinstellung wird mit der zum Zeitpunkt der Handschrift ausgewählten Einstellung vereinheitlicht. Die Konvertierung ist die Standardeinstellung für alle Software. Alle Software ist standardmäßig ein wenig nebeneinander, da es eine Frage von Versuch und Irrtum ist, die Einstellungen zu verbessern. Ich denke, dass die vorgeschlagene Methode in der Fähigkeit, Zeichen auszuwählen, die perfekt in den Teil passen, in dem die Linie kompliziert ist, etwas überlegen ist.
Ein weiterer Vergleichspunkt ↓
 Dies wird mit der Größe vereinheitlicht, die mit dem vorgeschlagenen Verfahren gut ausgegeben wurde. Daher ist es ein Vergleich der Schirmherrschaft.
DeepAA ist jedoch besonders gut darin, Augen zu machen, und ich denke, dass es möglich ist, Charaktere auszuwählen, die so gut sind wie Menschen.
Dies wird mit der Größe vereinheitlicht, die mit dem vorgeschlagenen Verfahren gut ausgegeben wurde. Daher ist es ein Vergleich der Schirmherrschaft.
DeepAA ist jedoch besonders gut darin, Augen zu machen, und ich denke, dass es möglich ist, Charaktere auszuwählen, die so gut sind wie Menschen.
Ich werde unten einige Beispiele veröffentlichen.
 Als Faustregel gilt, dass es einfacher ist, bessere Ergebnisse zu erzielen, wenn die Strichzeichnung dünner gemacht wird.
Als Faustregel gilt, dass es einfacher ist, bessere Ergebnisse zu erzielen, wenn die Strichzeichnung dünner gemacht wird.
 Selbst wenn Sie es wagen, den Feststoff so auszugeben, wie er ist, ohne ihn zu verdünnen, erhalten Sie interessante Ergebnisse.
Selbst wenn Sie es wagen, den Feststoff so auszugeben, wie er ist, ohne ihn zu verdünnen, erhalten Sie interessante Ergebnisse.
 Was denken Sie.
Was denken Sie.
Aufgabe
Ich denke, dass die Genauigkeit höher war als die der vorhandenen automatischen AA-Erstellungssoftware, aber das Ergebnis war immer noch weit von der Genauigkeit handgeschriebener AA entfernt. Die Probleme zur Verbesserung werden unten beschrieben.
Fehlausrichtung
Derzeit denke ich, dass die größte Schwäche von DeepAA im Vergleich zur Handschrift die Lücke ist. Im Gegensatz zu Isobreiten-Schriftarten, die eine konstante Zeichenbreite haben, handelt es sich um proportionale Schriftarten, bei denen die Zeichenbreite für jedes Zeichen unterschiedlich ist. Bei Schriftarten gleicher Breite, bei denen die Zeichen in das Bild passen, wird eindeutig festgelegt, bei proportionalen Schriftarten kann die Position jedoch durch die Kombination von Zeichen angepasst werden.
Im Beispiel von ↓ klappert beispielsweise die DeepAA-Linie in dem von Blau umgebenen Teil. Wenn eine Person sie ändert, kann sie wie rechts gezeigt ausgerichtet werden. (Passen Sie durch eine Kombination aus Raum voller Breite (Breite 11 Pixel), Raum halber Breite (Breite 5 Pixel) und Punkt (Breite 3 Pixel) an.)
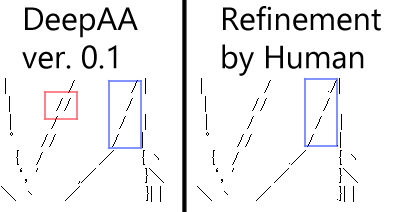 In dem von Rot umgebenen Bereich wird das "/" zweimal angewendet, aber die richtige Antwort besteht eindeutig darin, ein "/" an der Position zwischen den beiden "/" anzuwenden.
Das Problem ist, dass in der Phase der Trainingsdaten entschieden wird, wo die Zeichen auf "** wo " angewendet werden sollen, und dann nur die Zeichen, die auf " was **" angewendet werden sollen, trainiert werden. Ich kann mir jedoch ehrlich gesagt nicht vorstellen, wie ich "wo" lernen soll.
In dem von Rot umgebenen Bereich wird das "/" zweimal angewendet, aber die richtige Antwort besteht eindeutig darin, ein "/" an der Position zwischen den beiden "/" anzuwenden.
Das Problem ist, dass in der Phase der Trainingsdaten entschieden wird, wo die Zeichen auf "** wo " angewendet werden sollen, und dann nur die Zeichen, die auf " was **" angewendet werden sollen, trainiert werden. Ich kann mir jedoch ehrlich gesagt nicht vorstellen, wie ich "wo" lernen soll.
Strichzeichnung
Da ich einen Webdienst zum Erstellen von Strichzeichnungen von AA-Bildern verwende, ist dies ein Engpass bei der Erhöhung der Datenanzahl. Daher möchte ich eine Alternative in Betracht ziehen.
Anzahl des Lernens
Bisher habe ich nur mit der CPU trainiert, aber da ich kürzlich eine GPU-Umgebung vorbereitet habe, möchte ich mehrmals versuchen, mit einem komplizierteren Modell zu trainieren.
Recommended Posts