[PYTHON] Deep Learning mit Shogi AI auf Mac und Google Colab Kapitel 11
Lerntechnik
Gewöhnliches Lernen
Lernergebnisse des Wertschöpfungsnetzwerks in Kapitel 10.
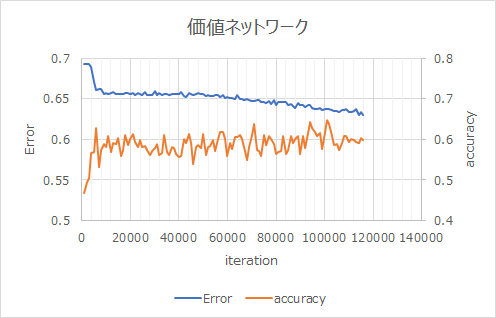
Lernen übertragen
Lernen durch Übertragung der Lernergebnisse des politischen Netzwerks. Der Fehler war gering und die Genauigkeit hoch.
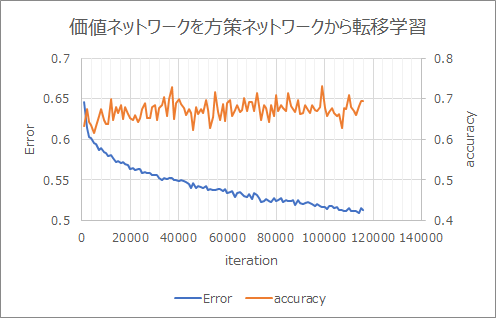
Multitasking lernen
Die obere Zeile ist Kapitel 7 Policy Network
Die unterste Zeile ist Kapitel 10 Value Network
Die Idee des Multitasking-Lernens besteht darin, es allgemein zu machen, da die hellblauen Teile gleich sind.
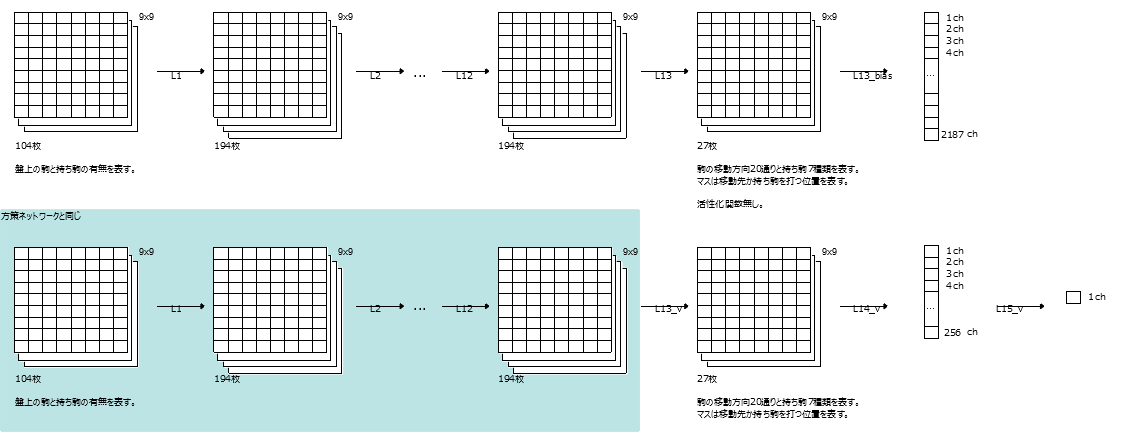 Dies passiert, wenn das Hellblau standardisiert ist.
Dies passiert, wenn das Hellblau standardisiert ist.
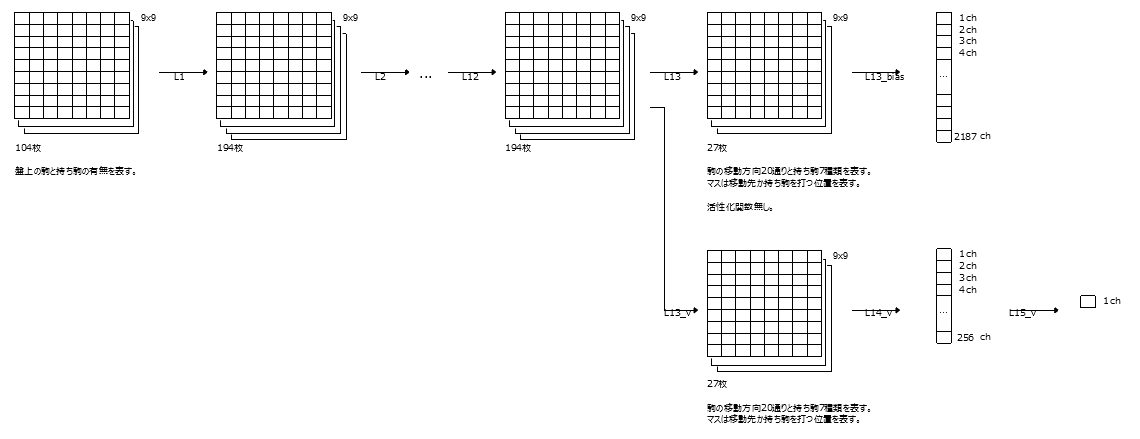
Sie können gleichzeitig Richtlinien und Werte lernen. Die Genauigkeit ist auch gut.
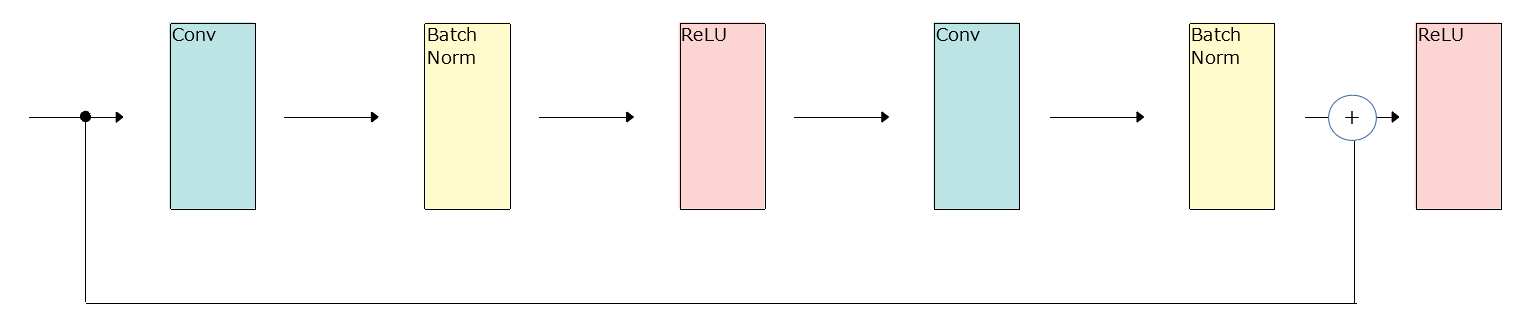
Residual Network Es scheint, dass die Konfiguration namens ResNet gut ist. Ich verstehe nicht, warum ResNet gut ist, aber es scheint, dass die Forschung Fortschritte macht.
1 Block ResNet
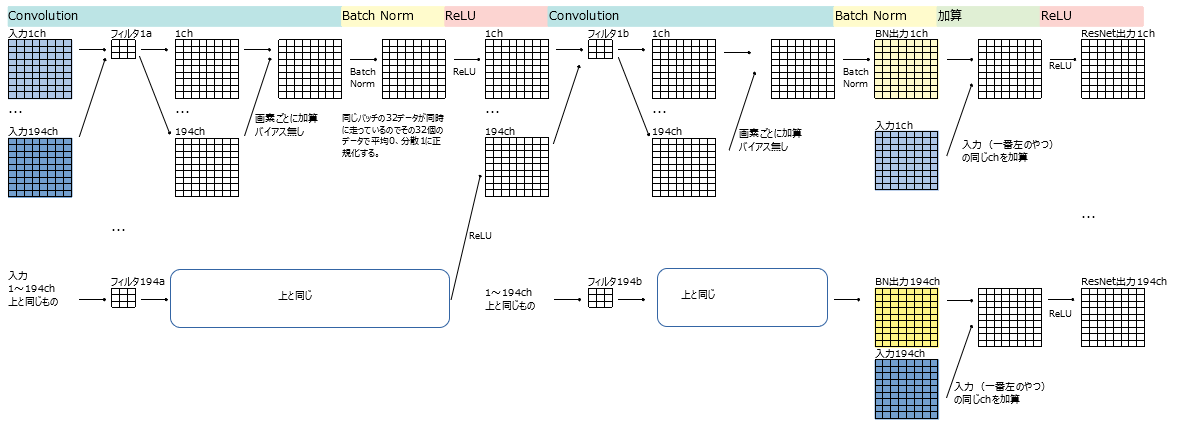
Details eines ResNet-Blocks
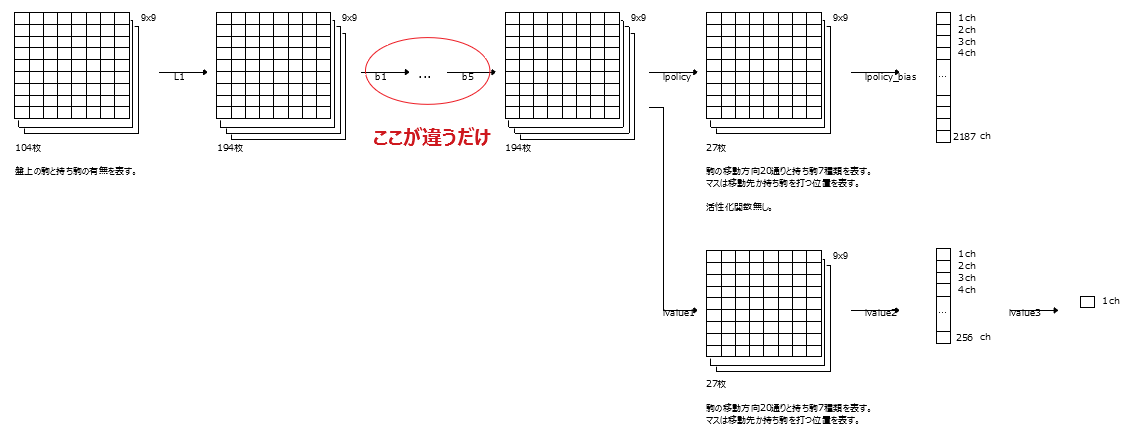
Verbinden Sie 5 ResNet-Blöcke und ersetzen Sie sie für Multitasking-Lernen durch L2 bis L12.
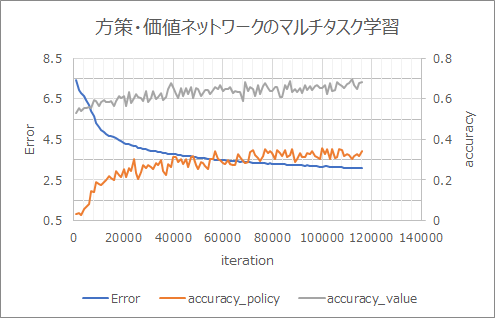
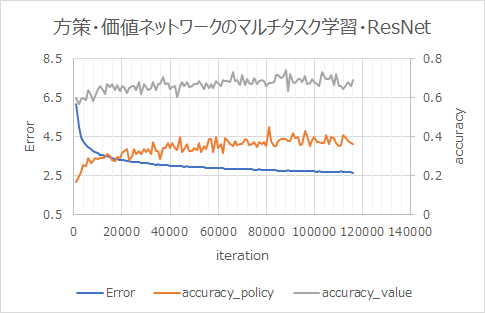
Lernergebnis
Das Lernen schreitet schneller voran als ohne ResNet.
policy_value_resnet.py
x + h2 x + h2 ist die Operation des Hinzufügens von x und h2 "Element für Element". (Als ich den Wert tatsächlich druckte, war es so)
def __call__(self, x):
h1 = F.relu(self.bn1(self.conv1(x)))
h2 = self.bn2(self.conv2(h1))
return F.relu(x + h2)
h = self['b{}'.format(i)](h) Diese Schreibweise bedeutet self.bi (h).
for i in range(1, self.blocks + 1):
h = self['b{}'.format(i)](h)
pydlshogi/network/policy_value_resnet.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from chainer import Chain
import chainer.functions as F
import chainer.links as L
from pydlshogi.common import *
ch = 192
fcl = 256
class Block(Chain):
def __init__(self):
super(Block, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1, nobias=True)
self.bn1 = L.BatchNormalization(ch)
self.conv2 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1, nobias=True)
self.bn2 = L.BatchNormalization(ch)
def __call__(self, x):
h1 = F.relu(self.bn1(self.conv1(x)))
h2 = self.bn2(self.conv2(h1))
return F.relu(x + h2)
# x +Als h2 den Wert druckte und bestätigte, wurden x und h2 Element für Element hinzugefügt. Mit anderen Worten sind x, h2 und x + h2 194 Elemente.
#Ich war besorgt, dass das erste Gefühl 388 Elemente sein würde, also überprüfte ich es, aber F..Bedeutet das, dass jedes Element in relu hinzugefügt wird?
class PolicyValueResnet(Chain):
def __init__(self, blocks):
super(PolicyValueResnet, self).__init__()
self.blocks = blocks
with self.init_scope():
self.l1 = L.Convolution2D(in_channels = 104, out_channels = ch, ksize = 3, pad = 1)
for i in range(1, blocks + 1):
self.add_link('b{}'.format(i), Block()) #Das erste Argument ist der Name und das zweite Argument ist die Klasse
# policy network
self.lpolicy = L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1, nobias = True)
self.lpolicy_bias = L.Bias(shape=(9*9*MOVE_DIRECTION_LABEL_NUM))
# value network
self.lvalue1 = L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1)
self.lvalue2 = L.Linear(9*9*MOVE_DIRECTION_LABEL_NUM, fcl)
self.lvalue3 = L.Linear(fcl, 1)
def __call__(self, x):
h = F.relu(self.l1(x))
for i in range(1, self.blocks + 1):
h = self['b{}'.format(i)](h) #Diese Art, sich selbst zu schreiben.b Wie viele.
# policy network
h_policy = self.lpolicy(h)
policy = self.lpolicy_bias(F.reshape(h_policy, (-1, 9*9*MOVE_DIRECTION_LABEL_NUM)))
# value network
h_value = F.relu(self.lvalue1(h))
h_value = F.relu(self.lvalue2(h_value))
value = self.lvalue3(h_value)
return policy, value
Recommended Posts