[PYTHON] Erstellen Sie DNN-CRF mit Chainer und erkennen Sie den Akkordfortschritt der Musik
Es ist der 11. Tag von Chainer Adventskalender.
Was ist Code-Fortschrittserkennung?
Wenn wir Musik machen, können wir einen satteren Klang erzielen, indem wir Klänge mit unterschiedlichen Tonhöhen überlagern. Dies nennt man einen Akkord. Durch Ändern (Entwickeln) der Akkorde im Laufe der Zeit wird das Rückgrat der Musik vervollständigt. Dies ist die Code-Progression. Die Akkordfolge ist wahrscheinlich der wichtigste Faktor beim Kopieren von Musik. Wenn Sie die Akkordfolge kennen, können Sie die Begleitung fast auf der Gitarre oder dem Keyboard reproduzieren. Kurz gesagt, im Text geht es darum, dass der Computer die Ohren automatisch kopiert. Wenn ich tatsächlich die Ohren kopiere, werde ich ein grobes Urteil fällen wie "Am klingelt in diesem Takt und C ist der nächste ...". Ich denke nicht an die Aufzählung von Noten oder den Rhythmus. Obwohl die Akkorde durch die konstituierenden Klänge klar definiert werden können, ist es nicht einfach, das tatsächliche Musiksignal zu unterscheiden, da die Tonhöhe unklar ist, die Harmonischen gemischt sind und die nicht konstituierenden Klänge normalerweise gemischt werden, wenn sie in den Frequenzbereich zerlegt werden. Daher ist die aktuelle Situation, dass wir uns eher auf datengesteuerte Methoden verlassen. Es ist eine der grundlegenden Aufgaben im Bereich der Musikinformationsverarbeitung (MIR) und eignet sich zur Genre-Diskriminierung, Emotionsanalyse und Erkennung von Coversongs. Es ist auch eine der Aufgaben des jährlichen Musikinformationswettbewerbs MIREX. MIREX 2016:Audio Chord Estimation Zusammenfassung der teilnehmenden Algorithmen Nun, es ist ein gewöhnliches Problem bei der Serienbeschriftung, das formal normal ist. Ich hoffe, es ist eine Referenz für die Implementierung verschiedener ähnlicher Aufgaben, nicht nur für die Erkennung des Codefortschritts. Die Implementierung von NN verwendet Chainer, librosa für die Vorverarbeitung und mir_eval für die Berechnung der richtigen Antwortrate.
Eingabevorverarbeitung
Die Eingabe von NN ist die Spektrumsreihe (oder das Spektrogramm) des Musiksignals. Wenn das Verfahren eine Vorverarbeitung umfasst,
- Trennen Sie die Komponenten des Schlaginstruments vom Musiksignal. Lassen Sie uns die Störgeräusche ausschalten. Es ist ein Schuss mit Librosa.
- Konstant-Q-Transformation. Apropos Spektrumumwandlung: Es handelt sich um eine Fourier-Transformation (STFT), aber die Fourier-Transformation hat das Problem, dass "der Frequenzbereich linear ist" und "die Auflösung für jede Frequenz unterschiedlich ist (weil das Fenster eine feste Länge hat)". Da Tonhöheninformationen für Musiksignale wichtig sind, ist es wünschenswert, sie im logarithmischen Frequenzbereich anzuzeigen. Es ist möglich, das FFT-Spektrum zu komprimieren und in den logarithmischen Frequenzbereich umzuwandeln. Hier verwenden wir jedoch CQT, das die Fensterlänge für jede Frequenz so ändert, dass sich die Auflösung nicht ändert. ~~ Wie auch immer, Librosa ist ein Schuss. ~~ 24 Dimensionen für jede Oktave (dh 1/2 Halbton für jede Dimension), und das Spektrum für 6 Oktaven wurde aus der Tonhöhe von C0 berechnet, so dass es sich um einen 144-dimensionalen Vektor handelt. Die Wahl der Zahlen ist eher angemessen.
- Logarithmische Komprimierung. Konvertiere in f (X) = log (1 + X). Dies ist eine Vorverarbeitung, die Rauschen unterdrückt, indem Vektorwerte in logarithmische Bereiche umgewandelt werden. Es scheint ein wenig robust zu sein.
- Verketten Sie benachbarte Vektoren zu einem größeren Vektor. Wenn beispielsweise ein Vektor der Zeit t vorhanden ist, werden insgesamt 7 Vektoren von t-3 bis t + 3 (Auffüllen, wenn nicht genug) verkettet und in einen 1008 (= 144 × 7) dimensionalen Eingabevektor umgewandelt. Die Eingabegröße schwillt ebenfalls siebenmal an, aber die Erkennung scheint stabiler zu sein. (* Siehe auch den Nachtrag am Ende des Satzes!) Lassen Sie uns nun diese eindimensionale Vektorserie (eine Menge anstelle einer Reihe für DNN) in DNN werfen.
DNN-CRF-Modell
Erstellen Sie eine NN, um die Kennzeichnung der Spektrumreihen zu lernen. Es ist eine Dimension, die jeden Frame nach DNN klassifiziert, an CRF sendet, den Kontext der Etikettenserie berücksichtigt, die Plausibilität der Serie ermittelt und die endgültige Etikettenserie ausgibt. Schreiben wir NN. Da die Chainer-Version CRF verwendet, sollte es kein Problem geben, wenn es 1.13 oder höher ist. Python ist eine 2.7-Serie. Da wir die Anzahl der ausgeblendeten Ebenen und die Anzahl der Einheiten einfach steuern möchten, verwenden wir ChainList, um DNN zu definieren. Nun, es ist nur ein normaler Stapel vollständig verbundener Schichten. Die Lernmethode ist dieselbe wie im MNIST-Beispiel, daher ist keine Erklärung erforderlich.
dnn.py
class DNN(ChainList):
def __init__(self,links):
super(DNN,self).__init__(*links)
self.train = True
def __call__(self,x):
links = self.children()
h = x
for i in xrange(self.__len__()-1):
li = links.next()
h = F.dropout((F.relu(li(h))),train=self.train)
y = links.next()(h)#Die letzte Stufe ist die lineare Umwandlung
return y
Und die Definition von CNI. Was in Chainer implementiert ist, ist ein Modell namens linear-chain CRF, das in der Verarbeitung natürlicher Sprache beliebt zu sein scheint, wobei nur das vorherige Etikett als Original verwendet wird. Nimmt die Ausgabe von DNN als Eingabe.
DNN.py
class CRF(Chain):
def __init__(self):
super(CRF,self).__init__(crf=L.CRF1d(N_CLASSES))
def __call__(self,list_x,list_t):
self.loss = self.crf(list_x,list_t)
return self.loss
def argmax(self,list_x):
~,path = self.crf.argmax(list_x)
return np.array(path,dtype="int32").flatten() #Da path ein Array von Stapeln ist, wird es transformiert
Wenn man es noch einmal betrachtet, macht es fast keinen Sinn, eine neue Klasse zu schaffen ... Ist das in Ordnung? Wenn Sie Eingaben an die CRF senden, müssen Sie die Variablen in einem Array zusammenfassen (das Dokument enthält eine Liste der Variablen). Beim Lernen können Sie beschleunigen, indem Sie sie in Stapel gruppieren. In meinem Fall habe ich es wie folgt geschrieben. Y ist die im Voraus berechnete Ausgabe von DNN, und es handelt sich um ein Array von shape = (seqsize, 25), da alles in einer Charge enthalten ist. T ist die richtige Etikettenserie.
DNN.py
#Teil der Lernschleife
startidx = np.random.randint(0,seqsize-256-1,size=16*100)#Bestimmen Sie zufällig den Startpunkt der Serie
for i in range(0,32*100,32):
x_batch_list = [Variable(cp.asarray(Y[startidx[i:i+32]+j,:])) for j in range(256)]
t_batch_list = [Variable(cp.asarray(T[startidx[i:i+32]+j])) for j in range(256)]
opt.update(crfmodel,x_batch_list,t_batch_list) #cp ist cupy
Kurz gesagt, der Fluss besteht darin, jedes Mal zufällig 32 Serien mit einer Länge von 256 zu nehmen, sie zu einer Charge zu kombinieren und sie dem CRF zu geben. In der neuesten Version scheint CRF1d in der Lage zu sein, Serien mit unterschiedlichen Längen im Batch zu verarbeiten, hier ist sie jedoch auf 256 Längen festgelegt. Einfach zu schreiben. Es ist möglich, DNN und CRF in einer Kette zusammenzufassen und zusammen zu trainieren, aber hier teilen wir es in zwei Schritte auf. Verwenden Sie zunächst die Trainingsdaten, um nur die DNN zu trainieren. Die Verlustfunktion ist softmax_cross_entropy. Korrigieren Sie danach die DNN-Parameter und trainieren Sie die CRF. Wenn Sie zum Zeitpunkt der Etikettenschätzung eine Reihe von DNN-Ausgaben angeben, gibt CRF1d.argmax () die wahrscheinlichste Route in der Viterbi-Suche zurück. Benly.
Etikettentyp
Gehen wir mit der einfachsten MajMin-Regel. Wenn man den siebten usw. ignoriert, gibt es neben 12 Dur-Triaden und 12 Moll-Triaden insgesamt 25 Typen, einschließlich eines speziellen Labels namens No Chord (Stille, Einzelton, nur Percuss-Abschnitt usw.).
Hyperparameter
Die Parameter von DNN werden unter Bezugnahme auf die Papiere entsprechend ausgewählt.
- Optimierungsalgorithmus: AdaDelta
- Anzahl der Eingabeabmessungen: 1008 (= 144x7)
- Anzahl der versteckten Ebenen: 4
- Anzahl der versteckten Ebeneneinheiten: 512
- Austrittsrate: 0,5 CRF-Optimierung ist auch AdaDelta.
Datensatz
Für den Datensatz werden die von isophonics.net veröffentlichten Anmerkungen zur Codeprogression verwendet. Alle Beatles-Alben, die besten Editionen von Queen und einige der Kalore King-Alben, ungefähr 200 Songs. Die Notation der Annotation sieht so aus.
06_-_Let_It_Be.lab
0.000000 0.175157 N
0.175157 1.852358 C
1.852358 3.454535 G
3.434535 4.720022 A:min
...
...
Wenn das Erkennungsergebnis von DNN auch in dieser Notation ausgegeben wird, kann die richtige Antwortrate von mir_eval berechnet und das Erkennungsergebnis visualisiert werden. Der Datensatz wird zufällig in einen Zugsatz und einen Testsatz unterteilt. Ich mache keine Kreuzvalidierung, weil es problematisch ist. Es gibt keinen Validierungssatz. Da es sich um ein Klassifizierungsproblem handelt, ist der Bewertungsstandard die richtige Antwortrate = (Gesamtzeit, wenn das geschätzte Etikett richtig geantwortet hat) / (Gesamtlänge der Musik). Nachdem ich das Schätzergebnis im gleichen Textformat wie das Isophonics-Dataset ausgegeben hatte, bat ich die mir_eval-Bibliothek, die richtige Antwortrate zu berechnen.
Leistungsbeurteilung
Wir haben die Klassifizierungsgenauigkeit des trainierten DNN-Testsatzes und des Zugsatzes sowie die endgültige Erkennungsgenauigkeit in Kombination mit dem trainierten CRF gemessen.
| DNN(train set) | DNN(test set) | DNN-CRF(train set) | DNN-CRF(test set) |
|---|---|---|---|
| 77.0% | 68.4% | 84.7% | 76.6% |
Sie können sehen, dass CRF wesentlich zur Genauigkeit der Serienkennzeichnung beiträgt. Es sieht so aus, wenn Audacity das Erkennungsergebnis visualisiert. Dies ist ein Teil der Akkordfolge von Here Comes The Sun of the Beatles. Das untere ist das Erkennungsergebnis und das obere ist die richtige manuelle Antwort. Ich kann die kleinen Änderungen im Code nicht erfassen, aber ich kann sehen, dass es meistens funktioniert.

Versuchen Sie zu bleiben
Lassen Sie uns DNN wie ResNet umgestalten, weil es eine gute Idee ist. Die Änderung des ResNet-Stils durch Chainer ist sehr einfach. Daher ist Chainer der Stärkste.
DNN.py
class DNNRes(ChainList):
def __init__(self,links):
super(DNNRes,self).__init__(*links)
self.train = True
def __call__(self,x):
links = self.children()
li = links.next()
h = F.relu(li(x)) #Nicht von der Eingabeebene in Res konvertieren
for i in xrange(self.__len__()-2):
li = links.next()
h = F.dropout(F.relu(li(h)),train=self.train)+h #Hier+Fügen Sie einfach h hinzu
y = links.next()(h)
return y
Es scheint, dass das ursprüngliche ResNet zwei versteckte Ebenen und einen Restblock hat, aber ~~ Es ist ärgerlich ~~ Wir legen Wert auf Verständlichkeit und machen jede Ebene Residual. Bei mehreren Ebenen ist es besser, einen Restblock in einer separaten Klasse (Kette) zu erstellen. Die Anzahl der ausgeblendeten Ebenen wurde auf 20 erhöht. Da die Überanpassung schrecklich war, habe ich zusätzlich zu Dropout einen etwas stärkeren Gewichtsverlust hinzugefügt. Faktor 0,001.
Ergebnis!
| DNN(train set) | DNN(test set) | DNN-CRF(train set) | DNN-CRF(test set) |
|---|---|---|---|
| 78.8% | 74.0% | 85.5% | 80.5% |
Die Genauigkeit des Testsatzes hat sich erheblich verbessert. Ich ging zur 80% -Marke.
Ergebnisse des diesjährigen MIREX liegt bei bis zu 86%, es ist also noch ein langer Weg, aber ich bin im Vergleich zu anderen ziemlich gut darin. (Ich kann nicht genau vergleichen, weil es keine Kreuzvalidierung ist).
Informationen zur CRF-Implementierung
Informationen zu CRF (mit linearer Kette) finden Sie unter Dieser Artikel und Dieser Artikel (Englisch). 03 / Einführung in bedingte Zufallsfelder /) wird empfohlen. CRF ist
P(Y|X)=\frac{\exp{E(X,Y)}}{\sum_{Y'}{\exp{E(X,Y)}}}
Die bedingte Wahrscheinlichkeit der Etikettenreihe Y wird wie folgt berechnet (Multiplikation mit -log ergibt eine Verlustfunktion), es gibt jedoch verschiedene Definitionen der Elementfunktion E (X, Y). Im Fall von Chainer (aus der Dokumentation erraten),
E(X,Y)=\sum_i{(x_{iy_i}+c_{y_{i-1}y_i})}
Fügen Sie einfach den Frame-Klassenverlust x (berechnet durch DNN usw.) und die Etikettenübergangskosten c hinzu. In diesem Fall muss nur die Etikettenübergangskostenmatrix c gelernt werden.
Einbeziehung des oberen DNN in dieses (unter der Annahme, dass X eine Spektralreihe ist),
E(X,Y)=\sum_i{(f_{dnn}(x_{iy_i})+c_{y_{i-1}y_i})}
Man kann sagen, dass es sich in erster Linie um ein einziges großes CNI handelte. Im Gegenteil, die Etikettenübergangskosten wurden ebenfalls nichtlinear gemacht.
E(X,Y)=\sum_i{(f_{dnn_1}(x_{iy_i})+f_{dnn_2}(c_{y_{i-1}y_i}))}
Es kann eine Ameise sein. Ich habe das Gefühl, dass ich mich allmählich RNN nähere. Andere Papiere betrachten,
E(X,Y)=\sum_i{(x_{iy_i}+c_{y_{i-1}y_i}+b_{y_i})}+\pi_{y_0}+\gamma_{y_N}
Auf diese Weise können Sie sehen, dass die Vorspannung b angehängt ist und das Potenzial (globales Merkmal) am Anfang und Ende der Etikettenserie berücksichtigt wird. Ist dies mit einer kleinen Änderung der Chainer-Implementierung möglich? Wenn es um Teilwort-Tagging-Aufgaben geht, scheint es auch eine Fall-zu-Fall-Funktion für Suffixe (wie -ly) zu sein. Auf diese Weise wird es häufig in derselben Aufgabe verwendet, in der es sich um ein Diskriminanzmodell handelt (die bedingte Wahrscheinlichkeit wird direkt berechnet), die Elementfunktion ist flexibel (globale Merkmale und heuristische Regeln können integriert werden) und es gibt keine Einschränkungen für Parameterwerte. Unterschied zum HMM. Vor allem, wenn die Parameter unterschieden werden können, können sie durch Gradientenabstieg gelernt werden, so dass sie mit NN kompatibel sind! am stärksten! Daher scheint die Anwendung die Aufgabe der Serienkennzeichnung zu erweitern. Chainer wird voraussichtlich auch in Zukunft weitere Variationen aufweisen.
- Ergänzung: Ich habe in diesem Beispiel die Matrix c aufgetragen.
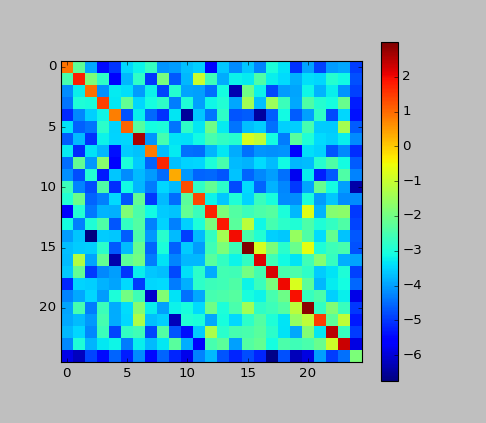 Aus dem hohen Wert der Hauptdiagonalen können wir erkennen, dass das CRF "in Richtung der Unterdrückung der Änderung der Beschriftung arbeitet". In HMM war das fast so.
Aus dem hohen Wert der Hauptdiagonalen können wir erkennen, dass das CRF "in Richtung der Unterdrückung der Änderung der Beschriftung arbeitet". In HMM war das fast so.
Zusammenfassung
Bitte verzeihen Sie mir, da der vollständige Quellcode niemandem angezeigt werden kann. Ich bin ein Forschungsstudent zum Thema automatische Ohrkopie, daher habe ich das Gelernte in gewissem Umfang vorgestellt (auch als Missionar im MIR-Bereich). Formal ist es ein wirklich einfaches Modell für die Serienkennzeichnung, aber es scheint bei der Aufgabe der Code-Fortschrittserkennung immer noch recht gut zu funktionieren. Wenn Sie Lust dazu haben, können Sie DNN tiefer, CNN oder sogar RNN machen. Ich mache gerade ein etwas komplizierteres Modell, aber ich schreibe ein Papier, also hoffe ich, dass ich es wieder vorstellen kann. Ich benutze Chainer schon lange, aber es ist wirklich gut. Das Gefühl, sich so zusammensetzen zu können, wie Sie es sich vorgestellt haben, ist sehr angenehm und hilfreich. Daher das stärkste (zweites Mal).
Ergänzung: Ich habe vergessen, mich zu normalisieren
Ich habe völlig vergessen, die Eingabe in der Vorverarbeitung zu normalisieren. Was für ein Chaos. Von vorn anfangen. Setzen Sie die Normalisierung zwischen die Schritte 3 (Protokollkonvertierung) und 4 der Vorverarbeitung. Ich denke, es gibt verschiedene Möglichkeiten, dies zu tun, aber hier werde ich es mit der globalen Normalisierung der mittleren Varianz tun (finde den Mittelwert und die Var des gesamten Spektrogramms für einen Song).
norm(X)=\frac{X-mean(X)}{var(X)}
In eine Form konvertiert, mit der NN zufrieden ist, mit einem Durchschnittswert von 0 und einer Varianz von 1.
In Schritt 3 habe ich auch die sogenannte logarithmische Komprimierung überprüft. Ursprünglich war dieser Prozess ein Vorprozess zum Komprimieren des Rauschens der Feature-Menge namens Chromagram, die häufig in derselben Aufgabe verwendet wird. Da Chromagram jedoch nicht negativ ist, musste die Eigenschaft beibehalten werden, indem bei der logarithmischen Konvertierung +1 hinzugefügt wurde. In einem anderen Deep-Learning-Artikel habe ich es für die Spektrogramm-Vorverarbeitung verwendet und nachgeahmt, aber wenn ich darüber nachdenke, ist es nicht erforderlich, den Eingabewertbereich auf nicht negativ zu beschränken. Wenn ja, +1, um den Wertebereich zu komprimieren. Es ist eine Verschwendung, es zu tun. Du brauchst also nicht +1.
f(X)=log(0.01+X)
Wenn Sie das Protokoll normal schreiben, ist es in Ordnung. 0,01 dient zur Vermeidung von Nullwerten. Ich habe dies mit den verbleibenden DNN-CRF-Einstellungen erneut versucht.
| DNN(train set) | DNN(test set) | DNN-CRF(train set) | DNN-CRF(test set) |
|---|---|---|---|
| 84.8% | 77.4% | 88.6% | 82.0% |
Es ist sehr gewachsen. Schließlich ist eine Vorbehandlung wichtig. Normalisierung ist wichtig. Seien wir alle vorsichtig!
Recommended Posts