[PYTHON] Einfaches maschinelles Lernen mit AutoAI (Teil 4) Jupyter Notebook
Einführung
Mit AutoAI, das wir zuvor eingeführt haben, wurde die Funktion zum Exportieren des erstellten Modells in Jupyter Notebook endlich freigegeben. In diesem Artikel werden wir diese Funktion als 4. Teil der Reihe "Easy Machine Learning with AutoAI" ausprobieren.
Informationen zu früheren Artikeln finden Sie unter den folgenden Links.
Einfaches maschinelles Lernen mit AutoAI (1) -Vorbereitung Einfaches maschinelles Lernen mit AutoAI (Teil 2) Modellbau Einfaches maschinelles Lernen mit AutoAI-Webdiensten (Teil 3)
Annahme
Im folgenden Verfahren wird davon ausgegangen, dass Sie in der obigen Serie "Einfaches maschinelles Lernen mit AutoAI (Teil 2) -Modellkonstruktion" abgeschlossen haben. (Teil 3) ist nicht obligatorisch.
Notizbuch exportieren
Wenn der Modellbau in (Teil 2) abgeschlossen ist, wird der in der folgenden Abbildung gezeigte Bildschirm angezeigt. (Der Bildschirm hat sich aufgrund des Versions-Upgrades von zuvor geändert.)
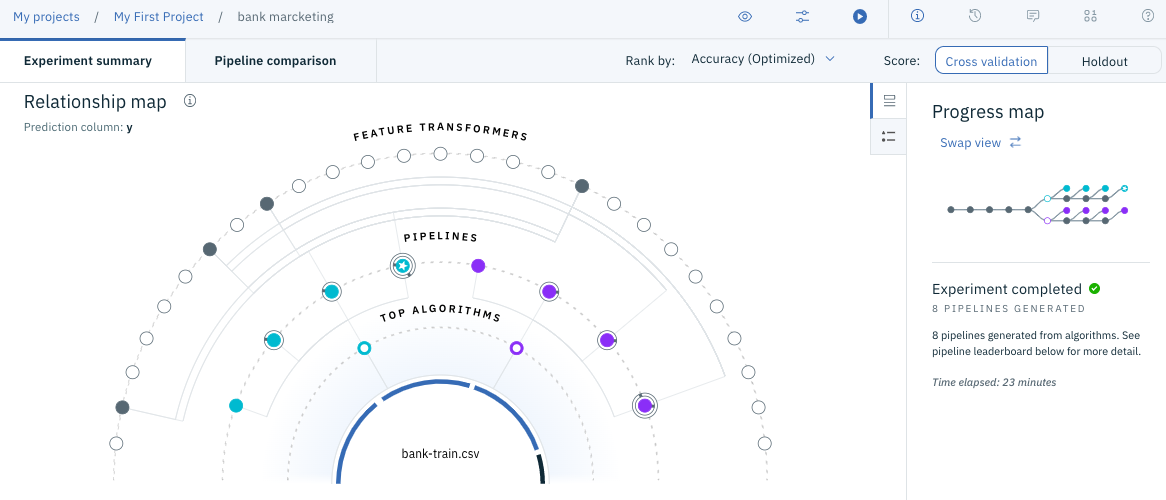
Scrollen Sie auf dem Bildschirm nach unten, um eine Liste der erstellten Modelle anzuzeigen (siehe folgende Abbildung).
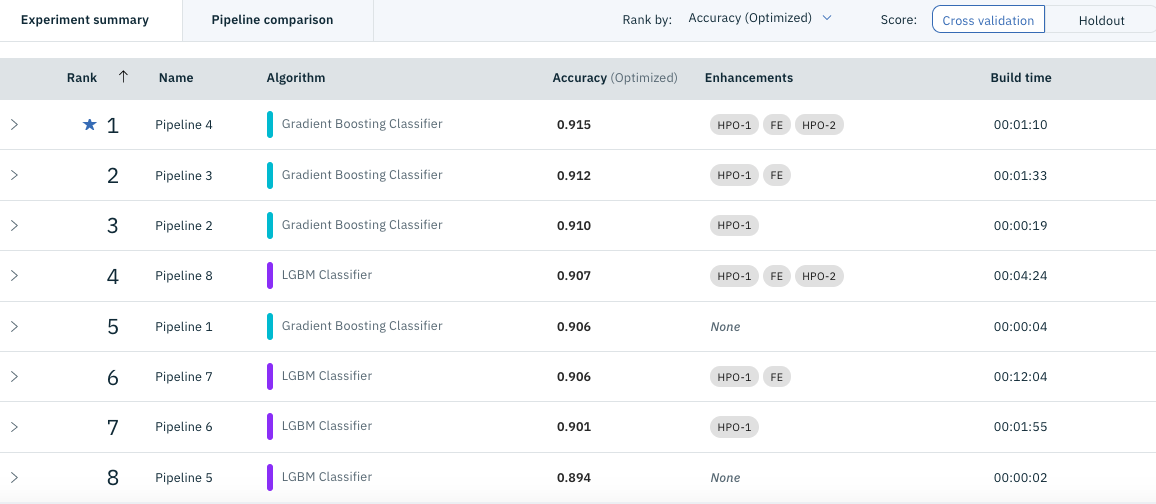
Wenn Sie hier den Mauszeiger auf die rechte Seite des zu exportierenden Modells bewegen (normalerweise oben), wird das Menü "** Speichern unter **" angezeigt. Klicken Sie also darauf und es sieht wie in der folgenden Abbildung aus. Ich werde.
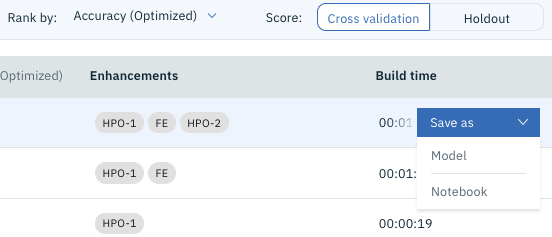
Wählen Sie hier unten "Notebook". Sie sollten einen Bildschirm wie den folgenden sehen.
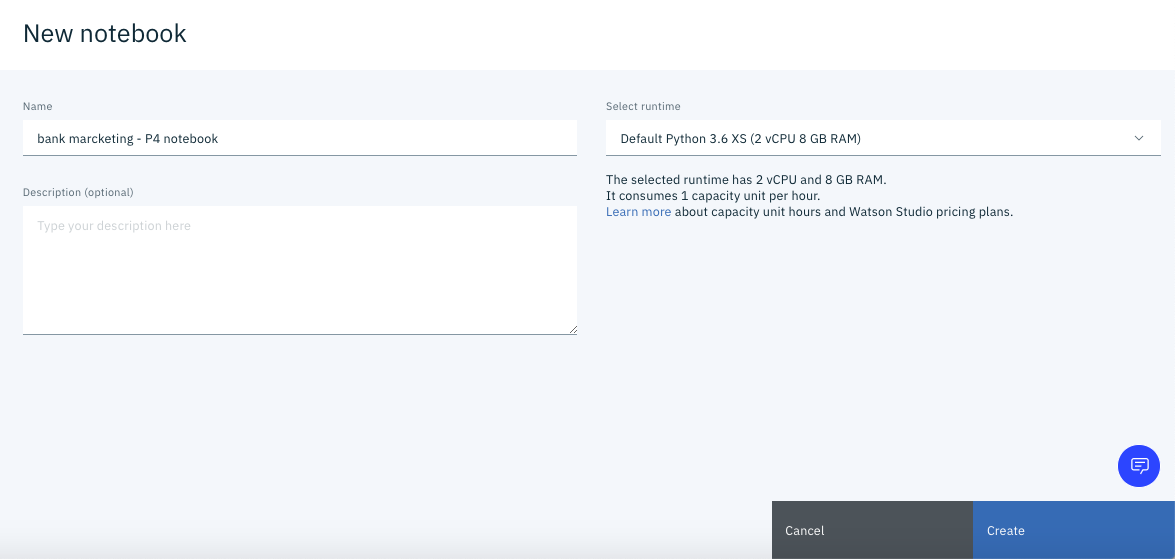
Klicken Sie unten rechts auf dem Bildschirm auf "** Erstellen **".
Warten Sie eine Weile, und wenn der folgende Bildschirm angezeigt wird, haben Sie erfolgreich exportiert. (Hinweis: Ab dem 03.04.2020 scheint es immer noch instabil zu sein und kann unterwegs fehlschlagen. Versuchen Sie es in diesem Fall erneut.)
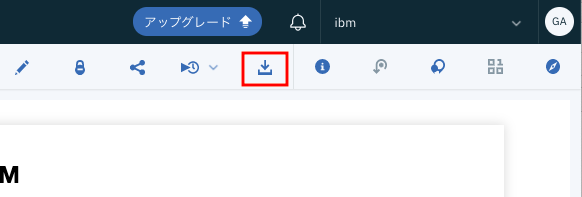
Zu diesem Zeitpunkt kann das Notebook als Code für das Jupyter-Notebook in Watson Studio verwendet werden. Das ist jedoch nicht sehr interessant, daher möchte ich es extern ausführen (Jupyter Notebook auf Mac PC). Klicken Sie dazu auf das ** Download-Symbol ** im roten Rahmen in der folgenden Abbildung. Der Download sollte automatisch starten.
Als Referenz wird das Beispiel des exportierten Notizbuchs unten hochgeladen. Notizbuch-Link
Jupyter Notebook Vorbereitung auf die Umgebungsseite
Bereiten Sie als Nächstes die Umgebung auf der PC-Seite vor. In meinem Fall habe ich vor einiger Zeit Anacoda (4.8.1) auf meinem Mac-PC installiert und verwendet. Ich habe es in anderen Umgebungen nicht bestätigt, aber ich denke, dass es fast genauso funktioniert. Das AutoAI-Modell basiert auf der Annahme, dass es zur Laufzeit eine Bibliothek für AutoAI gibt. Der Punkt ist jedoch, dass ** diese Bibliothek im Internet für die Öffentlichkeit zugänglich ist und mit dem Befehl pip normal installiert werden kann **. Führen Sie insbesondere den folgenden Befehl aus.
$ pip install autoai-libs -U
(Diese Bibliothek scheint täglich aktualisiert zu werden, und selbst wenn sie bereits installiert ist, ist es besser, sie zu aktualisieren, wenn Sie ein Notebook verwenden. Ich habe mich daran gehalten.)
Außerdem in der Standard-Anaconda-Umgebung
$ pip install lightgbm
$ pip install xgboost
Ich glaube, ich habe es auch gebraucht. (Erinnerung ist etwas vage) Möglicherweise fehlen zur Laufzeit andere Bibliotheken, aber das Wichtigste ist, dass ** nur die im Internet veröffentlichten Bibliotheken alle Bibliotheken abdecken können, die zum Erstellen des AutoAI-Modells erforderlich sind **.
Ausführen des Modells in Jupyter Notebook
Lassen Sie uns nun das exportierte Modell in der Jupyter-Umgebung auf dem PC ausführen.
Wenn ich mir nun den Code in Notebook ansehe und die oben genannten drei Bibliotheken nicht in der ersten Zelle sind, werden sie automatisch installiert. Alternativ sind die obigen Schritte möglicherweise nicht erforderlich.
Notebook-Voränderung
Wenn Sie es auf Ihrem lokalen Jupyter ausführen möchten, ändern Sie bitte die folgenden zwei Teile des automatisch generierten Notizbuchs.
COS-Zugangsteil
Die folgenden Zellen dienen zum Herunterladen von CSV-Dateien, die in COS (Cloud Object Storage) gespeichert sind, und sind für die lokale Verwendung nicht erforderlich. Ich bin nicht vorsichtig, also werde ich es löschen.

Lokale Dateidefinition hinzufügen
Stellen Sie die lernende CSV-Datei in der Variablen "lesbar" in der Zelle unten ein. Kopieren Sie die CSV-Datei in dasselbe Verzeichnis wie Notebook.

Lauf
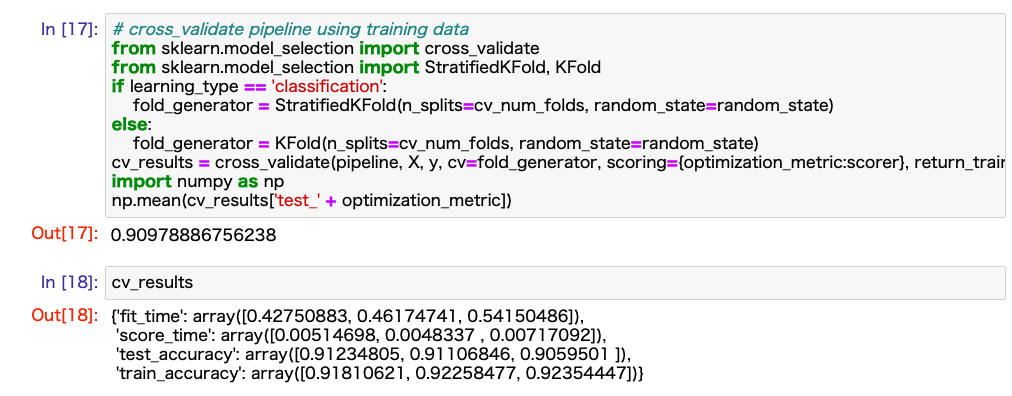
Nachdem Sie die beiden oben genannten Vorbereitungen abgeschlossen haben, sollten Sie in der Lage sein, das Modell zu erstellen und zu bewerten, indem Sie die Zellen in der Reihenfolge von oben ausführen. Ich habe ein Beispielbild des Ergebnisses angehängt.
Bonus
Testausführung mit Verifizierungsdaten
Kopieren Sie den folgenden Code in die untere Zelle des obigen Notebooks. Mit den gleichen 40.000 Verifizierungsdaten wie in (3) können Sie das Modell aufrufen und das Ergebnis der Genauigkeitsbewertung überprüfen. Beachten Sie, dass die Modelleingabedaten (Pipeline) das vorverarbeitete Ergebnis verwenden sollten.
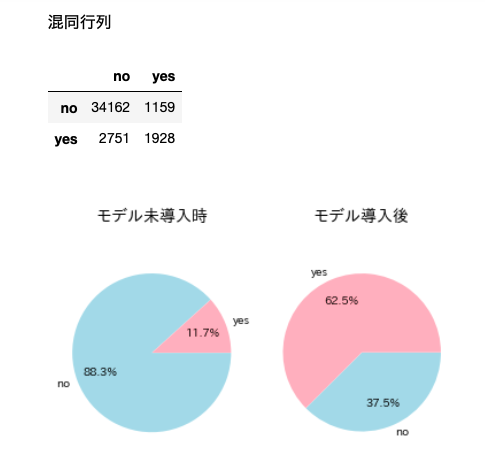
Das Endergebnisbeispiel ist unten beigefügt.
Der folgende Code wurde ebenfalls auf github hochgeladen. Zusatzcode für Notizbücher
#Genauigkeitsüberprüfung mit 40.000 im Voraus vorbereiteten Überprüfungsdaten
%matplotlib inline
#Einführung der erforderlichen Bibliotheken
!pip install japanize-matplotlib | tail -n 1
#Import der benötigten Bibliotheken
import matplotlib.pyplot as plt
#Japanische Lokalisierung
import japanize_matplotlib #Japanische Lokalisierungsmatplotlib
#In Datenrahmen laden
csv_url = 'https://raw.githubusercontent.com/makaishi2/sample-data/master/data/bank-test.csv'
df_bank_test = pd.read_csv(csv_url)
#Überprüfen Sie das Ergebnis
print('')
print('CSV-Daten zur Überprüfung')
display(df_bank_test.head())
#Extraktion der richtigen Antwortdaten korrekt
correct = df_bank_test.y.values
#Erstellen eines Eingabedatenarrays
df_sub = df_bank_test.copy()
#Zielvariablenspalte löschen
df_sub = df_sub.drop('y', axis=1)
#Überprüfen Sie das Ergebnis
print('')
print('Modelleingabedaten')
display(df_sub.head())
#Prognoseimplementierung
X_prep = preprocessing_pipeline.transform(df_sub.values)
predict = pipeline.predict(X_prep)
#Überprüfen Sie das Ergebnis
print('')
print('Vorhersageergebnis')
display(predict[:10])
#Berechnung der Verwirrungsmatrix
from sklearn.metrics import confusion_matrix
matrix = confusion_matrix(correct, predict)
df_matrix = pd.DataFrame(matrix, columns=['no', 'yes'], index=['no', 'yes'])
###Verwirrte Matrixanzeige
print()
print('Verwirrte Matrix')
display(df_matrix)
#Berechnung der Anzahl von Ja und Nein in den richtigen Antwortdaten
y_count = np.count_nonzero(correct == 'yes')
n_count = np.count_nonzero(correct == 'no')
#Anzahl von Ja und Nein in korrekten Antwortdaten unter denen, deren vorhergesagter Wert Ja war
yy_count = df_matrix.yes.yes
yn_count = df_matrix.yes.no
#Vergleich der Schlusskurse mit und ohne Modell
print()
plt.subplot(1, 2, 1)
label = ['yes', 'no']
colors = ["lightpink", "lightblue"]
x = np.array([y_count, n_count])
plt.pie(x, labels=label, colors=colors,
autopct="%1.1f%%", pctdistance=0.7)
plt.title('Wenn das Modell nicht vorgestellt wird', fontsize=14)
plt.axis('equal')
plt.subplot(1, 2, 2)
label = ['yes', 'no']
colors = ["lightpink", "lightblue"]
x = np.array([yy_count, yn_count])
plt.pie(x, labels=label, colors=colors,
autopct="%1.1f%%", pctdistance=0.7)
plt.title('Nach der Modelleinführung', fontsize=14)
plt.axis('equal')
plt.show()
Recommended Posts