[PYTHON] Beginnen Sie mit dem maschinellen Lernen mit SageMaker
Einführung
Erstellen und Bereitstellen eines Modells für maschinelles Lernen gemäß dem AWS-Mitarbeiter Erste Schritte mit Amazon SageMaker Ich beschloss, den Flow bis zu üben.
Ich werde diesen Artikel als meine eigene praktische Lernnotiz veröffentlichen.
Inhaltsverzeichnis
- [Was ist maschinelles Lernen](#Was ist maschinelles Lernen)
- [Übersicht über SageMaker](#Übersicht über SageMaker)
- Tutorial
- Schlussfolgerung
Was ist maschinelles Lernen?
Hier weggelassen. Eine Übersicht finden Sie weiter unten.
Maschinelles Lernen von Grund auf neu (Überblick über maschinelles Lernen)
Übersicht über SageMaker
Weitere Informationen finden Sie in der offiziellen AWS Amazon SageMaker-Dokumentation.
Amazon SageMaker ist ein vollständig verwalteter maschineller Lerndienst. Mit Amazon SageMaker können Datenwissenschaftler und Entwickler schnell und einfach Modelle für maschinelles Lernen erstellen und trainieren und diese direkt in einer sofort einsatzbereiten gehosteten Umgebung bereitstellen. Greifen Sie einfach über eine integrierte Jupyter-Authoring-Notebook-Instanz auf Datenquellen für Recherchen und Analysen zu, sodass Sie keinen Server mehr verwalten müssen. Sie können auch gängige Algorithmen für maschinelles Lernen verwenden. Solche Algorithmen sind so optimiert, dass sie auch bei extrem großen Datenmengen in verteilten Umgebungen effizient ausgeführt werden können. Mit nativer Unterstützung für Ihre eigenen Algorithmen und Frameworks bietet Amazon SageMaker auch flexible, verteilte Schulungen, die auf Ihren spezifischen Workflow zugeschnitten werden können. Starten Sie Ihr Modell in einer sicheren und skalierbaren Umgebung mit einem einzigen Klick von Amazon SageMaker Studio oder der Amazon SageMaker-Konsole. Schulung und Hosting werden von Minute zu Minute abgerechnet. Es gibt keine Mindestgebühr oder Vorauszahlungsverpflichtung.
(Zitiert aus https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/whatis.html)
In Bezug auf die Darstellung von SageMaker gibt es mehrere Instanzen, aber welche Rollen haben die einzelnen? → Vom AWS-Mitarbeiter veröffentlichte Materialien war leicht zu verstehen und wird im Folgenden beschrieben.
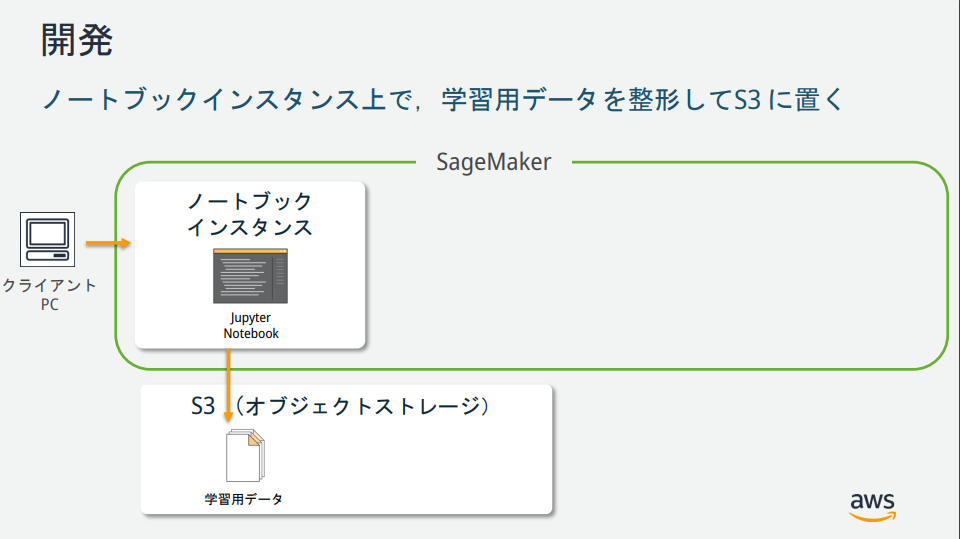
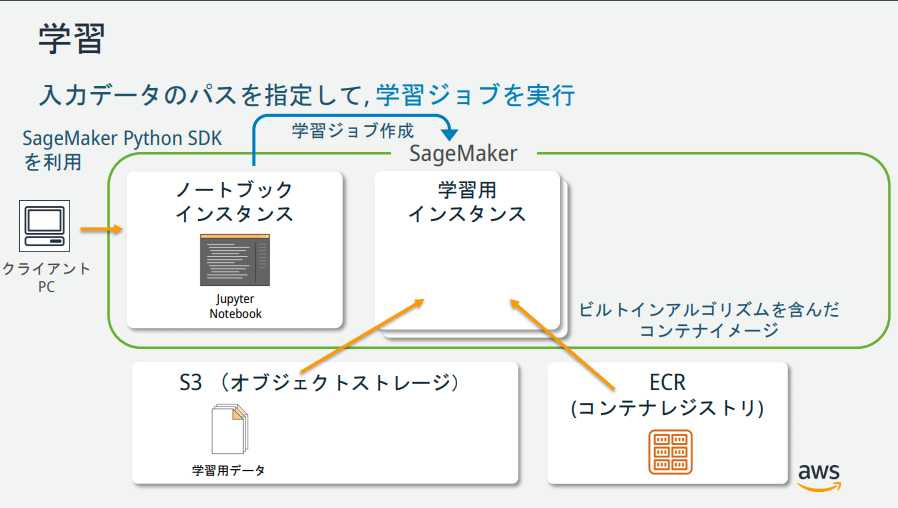
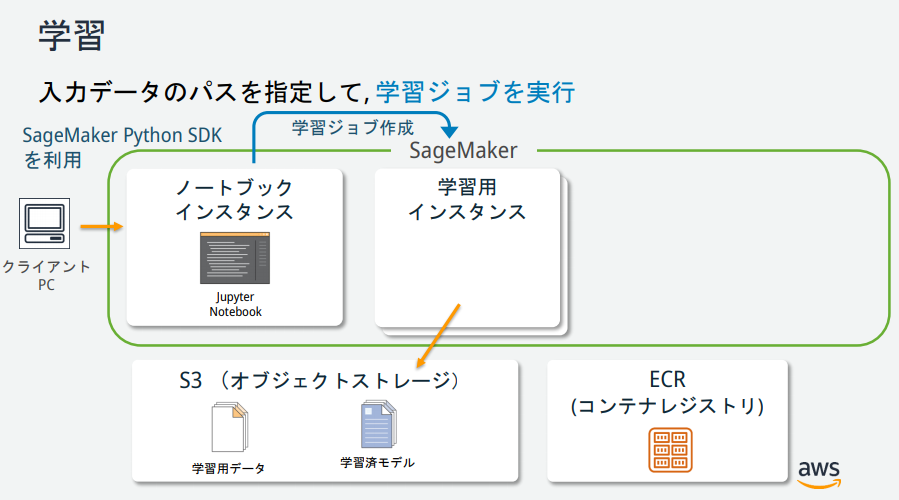
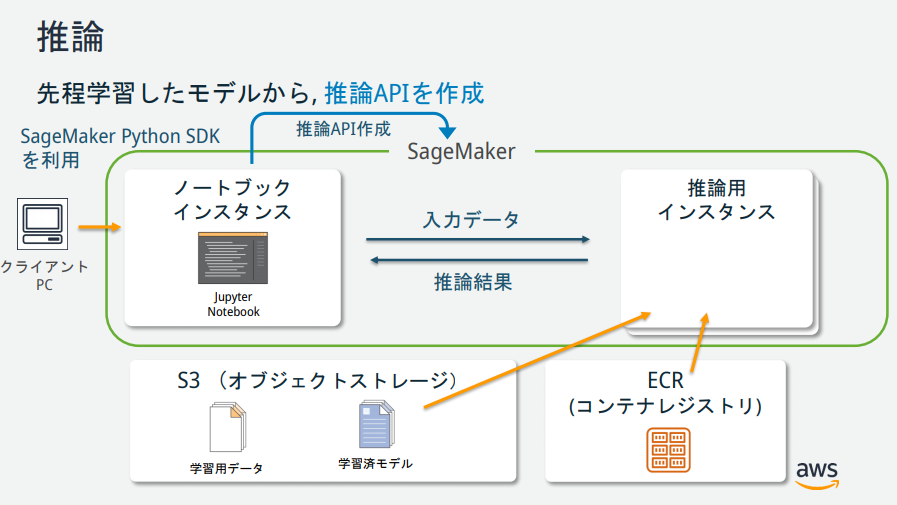
(Zitiert aus https://pages.awscloud.com/event_JAPAN_hands-on-ml_ondemand_confirmation.html)
Lernprogramm
Implementierte das offizielle AWS-Tutorial (https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/gs.html).
Erstellen Sie einen Amazon S3-Bucket
Erstellen Sie einen Ort (Bucket), um die für das maschinelle Lernen verwendeten Daten und das Trainingsergebnis (Modell) zu speichern.
Erstellen einer Amazon SageMaker-Notebook-Instanz
Eine Amazon SageMaker-Notebook-Instanz ist eine vollständig verwaltete EC2-Computerinstanz für maschinelles Lernen, auf der Jupyter Notebook installiert ist.
Erstellen Sie ein Jupyter-Notizbuch
Was ist ein Jupyter-Notizbuch?
Ein Open-Source-Tool, mit dem die Programmerstellung, Ausführungsergebnisse, Grafiken, Arbeitsnotizen und zugehörige Dokumente in einem als Notebook bezeichneten Dateiformat zentral verwaltet werden können. Dies ist besonders nützlich, wenn Sie ein Programm interaktiv ausführen und die nächste Arbeit ausführen möchten, während Sie sich auf das Ergebnis beziehen, z. B. Datenanalyse, oder wenn Sie das Ausgabeergebnis speichern und wie eine Arbeitsaufzeichnung mit einem Memo aufbewahren möchten. Ist.
(Zitiert aus https://www.seplus.jp/dokushuzemi/blog/2020/04/tech_words_jupyter_notebook.html)
Wählen Sie "conda_python3" unter "Neu". Ein neues Notizbuch wird erstellt.

Schreiben Sie Code, um S3 und die Rolle anzugeben.
from sagemaker import get_execution_role
role = get_execution_role()
bucket='0803-sagemaker-sample'
Laden Sie Daten herunter, untersuchen Sie sie und konvertieren Sie sie
Laden Sie den MNIST-Datensatz herunter
Was sind MNIST-Daten?
MNIST (Mixed National Institute of Standards and Technology-Datenbank) ist ein Bilddatensatz, der 60.000 handgeschriebene numerische Bilder und 10.000 Testbilder sammelt. Darüber hinaus handelt es sich auch um einen Datensatz, in dem die handschriftlichen Zahlen "0 bis 9" mit dem richtigen Antwortetikett versehen sind. Dies ist ein beliebter Datensatz für Bildklassifizierungsprobleme.
(Zitiert aus https://udemy.benesse.co.jp/ai/mnist.html)
Schreiben Sie den Code, um den MNIST-Datensatz herunterzuladen.
%%time
import pickle, gzip, numpy, urllib.request, json
# Load the dataset
urllib.request.urlretrieve("http://deeplearning.net/data/mnist/mnist.pkl.gz", "mnist.pkl.gz")
with gzip.open('mnist.pkl.gz', 'rb') as f:
train_set, valid_set, test_set = pickle.load(f, encoding='latin1')
Untersuchen Sie den Trainingsdatensatz
Fügen Sie den folgenden Python-Code in die dritte Zelle ein und klicken Sie auf die Schaltfläche "Ausführen". Die 31. Bilddaten des MNIST-Datensatzes werden zusammen mit dem Inhalt des Etiketts angezeigt.
%matplotlib inline
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (2,10)
def show_digit(img, caption='', subplot=None):
if subplot==None:
_,(subplot)=plt.subplots(1,1)
imgr=img.reshape((28,28))
subplot.axis('off')
subplot.imshow(imgr, cmap='gray')
plt.title(caption)
show_digit(train_set[0][30], 'This is a {}'.format(train_set[1][30]))
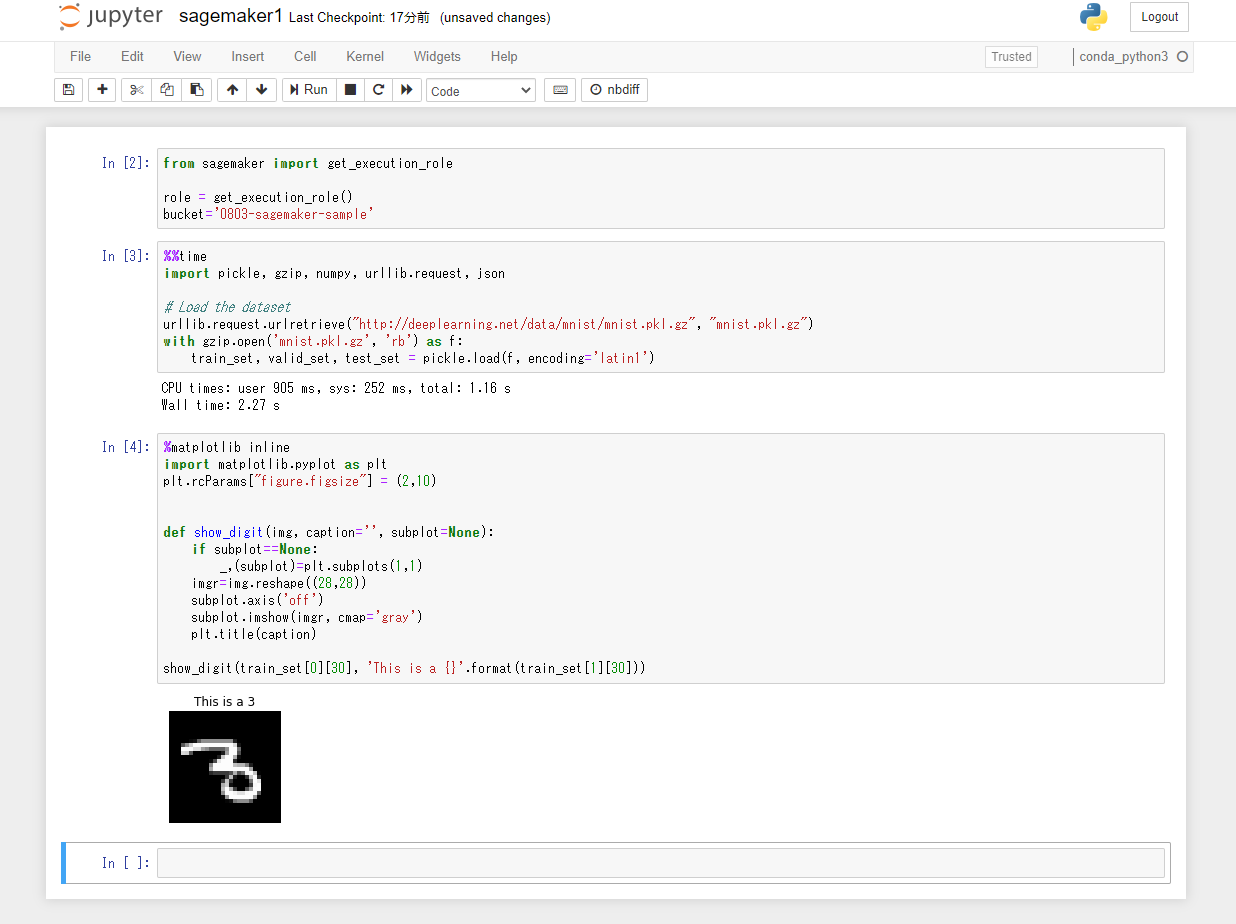
Trainiere das Modell
Wählen Sie einen Trainingsalgorithmus
Maschinelles Lernen erfordert normalerweise einen Bewertungsprozess, um einen geeigneten Algorithmus für das Modell zu finden. Dieses Mal haben wir uns für k-means entschieden, einen der in SageMaker integrierten Algorithmen. Daher überspringen wir den Bewertungsprozess.
Was ist k-bedeutet
Die K-Means-Methode ist einer der Standardalgorithmen für das Clustering. Details werden hier weggelassen.
Ausbildungsjob schaffen
Fügen Sie den folgenden Python-Code in die 4. Zelle ein und klicken Sie auf die Schaltfläche "Ausführen".
from sagemaker import KMeans
data_location = 's3://{}/kmeans_highlevel_example/data'.format(bucket)
output_location = 's3://{}/kmeans_example/output'.format(bucket)
print('training data will be uploaded to: {}'.format(data_location))
print('training artifacts will be uploaded to: {}'.format(output_location))
kmeans = KMeans(role=role,
train_instance_count=2,
train_instance_type='ml.c4.8xlarge',
output_path=output_location,
k=10,
data_location=data_location)
Durchführung von Schulungen
Führen Sie ein Modelltraining durch. Fügen Sie den folgenden Python-Code in die 5. Zelle ein und klicken Sie auf die Schaltfläche "Ausführen". Das Training dauert ca. 10 Minuten.
%%time
kmeans.fit(kmeans.record_set(train_set[0]))
Wenn Sie S3 überprüfen, nachdem das Modell trainiert wurde, finden Sie die Modelltrainingsdaten und die Modellartefakte, die während des Modelltrainings generiert wurden.
Stellen Sie das Modell in Amazon SageMaker bereit
Um das Modell für SageMaker bereitzustellen, müssen Sie die folgenden drei Schritte ausführen.
--Erstellen Sie ein Modell in SageMaker --Erstellen von Endpunkteinstellungen --Erstellen Sie den Endpunkt
Sie können diese Aufgaben mit nur einer Methode ausführen, die als Bereitstellen bezeichnet wird. Fügen Sie den folgenden Python-Code in die 6. Zelle ein und klicken Sie auf die Schaltfläche "Ausführen".
%%time
kmeans_predictor = kmeans.deploy(initial_instance_count=1,
instance_type='ml.m4.xlarge')
Überprüfen Sie das Modell
Überprüfen Sie das Modell, da es bereitgestellt wurde. Fügen Sie den folgenden Python-Code in die 7. Zelle ein und klicken Sie auf die Schaltfläche "Ausführen".
result = kmeans_predictor.predict(valid_set[0][28:29])
print(result)
Das Inferenzergebnis für das 30. Bild des Datensatzes valid_set wird erhalten. Es ist ersichtlich, dass die 28. Daten von valid_set zu Cluster 6 gehören.
[label {
key: "closest_cluster"
value {
float32_tensor {
values: 6.0
}
}
}
label {
key: "distance_to_cluster"
value {
float32_tensor {
values: 6.878328800201416
}
}
}
]
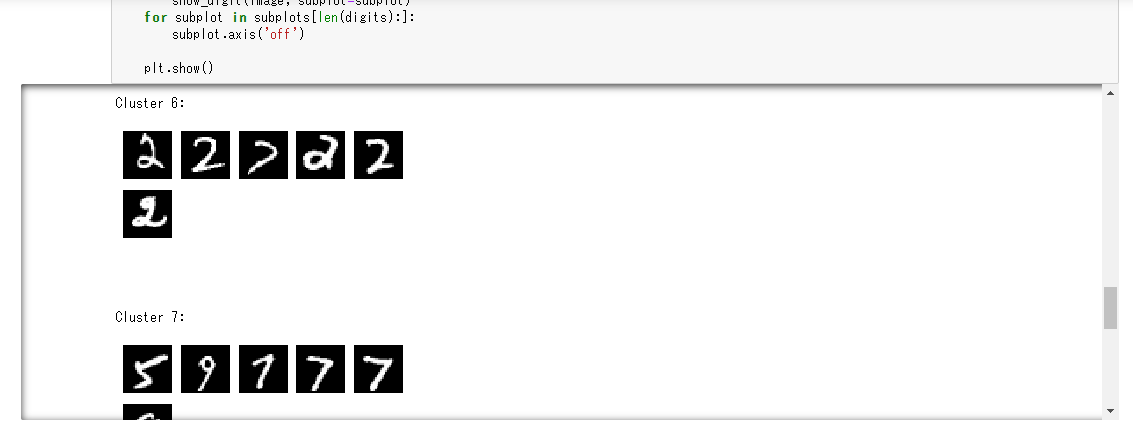
Dann werden die Inferenzergebnisse für 100 Teile ab dem Beginn des valid_set-Datensatzes erfasst. Fügen Sie den folgenden Python-Code in die 8. und 9. Zelle ein und klicken Sie der Reihe nach auf die Schaltfläche "Ausführen".
%%time
result = kmeans_predictor.predict(valid_set[0][0:100])
clusters = [r.label['closest_cluster'].float32_tensor.values[0] for r in result]
for cluster in range(10):
print('\n\n\nCluster {}:'.format(int(cluster)))
digits = [ img for l, img in zip(clusters, valid_set[0]) if int(l) == cluster ]
height = ((len(digits)-1)//5) + 1
width = 5
plt.rcParams["figure.figsize"] = (width,height)
_, subplots = plt.subplots(height, width)
subplots = numpy.ndarray.flatten(subplots)
for subplot, image in zip(subplots, digits):
show_digit(image, subplot=subplot)
for subplot in subplots[len(digits):]:
subplot.axis('off')
plt.show()
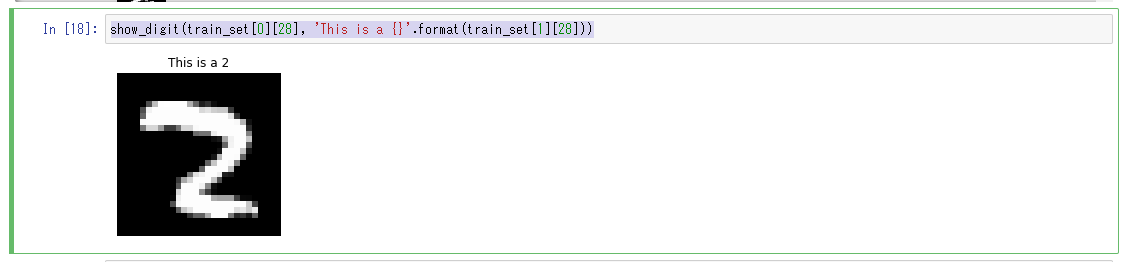
Zeigen Sie den 28. des valid_set-Datasets mit der Methode show_digit an, die unter "Untersuchen des Trainingsdatensatzes" verwendet wird. Sie können sehen, dass es sich um ein in Cluster 4 enthaltenes Bild handelt.
show_digit(train_set[0][28], 'This is a {}'.format(train_set[1][28]))
Abgeschlossen, weil das Modell bereitgestellt wurde und überprüft wurde, ob es funktioniert.
Löschen Sie die von Ihnen erstellte AWS-Ressource
Leise gelöscht. Es gibt nichts Besonderes zu erwähnen.
abschließend
Dieses Mal habe ich SagrMaker verwendet und das erste maschinelle Lernen ausprobiert. Maschinelles Lernen schien eine hohe Barriere zu haben, aber es war einfacher zu bedienen, als ich es mir vorgestellt hatte.
Wenn ich mir die jüngsten Ankündigungen der einzelnen öffentlichen Clouds ansehe, habe ich den Eindruck, dass sie versuchen, die Schwelle für maschinelles Lernen zu senken. (Ich denke, dass für die Analyse auf hoher Ebene spezielle Fähigkeiten als Ingenieur für maschinelles Lernen erforderlich sind.) Für ein bestimmtes Niveau des maschinellen Lernens können auch Nicht-Ingenieure, die sich auf maschinelles Lernen spezialisiert haben, verwaltete Dienste nutzen und ein Gefühl für Geschwindigkeit haben. Ich denke, dass Fähigkeiten zum Aufbau erforderlich sein werden, daher möchte ich weiterhin etwas über maschinelles Lernen lernen.
Referenzmaterial
So starten Sie Amazon SageMaker [Für Anfänger] Maschinelles Lernen ab Amazon SageMaker #SageMaker Praktische Erfahrung mit Amazon SageMaker für Ingenieure des maschinellen Lernens
Recommended Posts