[PYTHON] Pandas Benutzerhandbuch "Manipulieren fehlender Daten" (offizielles Dokument Japanische Übersetzung)
Dieser Artikel ist eine teilweise maschinelle Übersetzung der offiziellen Pandas-Dokumentation Benutzerhandbuch - Arbeiten mit fehlenden Daten. Es ist eine Modifikation eines unnatürlichen Satzes.
Wenn Sie falsche Übersetzungen, alternative Übersetzungen, Fragen usw. haben, verwenden Sie bitte den Kommentarbereich oder bearbeiten Sie die Anfrage.
Fehlende Daten bearbeiten
In diesem Abschnitt werden fehlende Werte (NA) für Pandas beschrieben.
: information_source: ** Hinweis ** Die Entscheidung, "NaN" intern zu verwenden, um fehlende Daten anzuzeigen, erfolgte hauptsächlich aus Gründen der Einfachheit und Leistung. Ab Pandas 1.0 versuchen einige optionale Datentypen, native NA-Skalare mithilfe eines maskenbasierten Ansatzes zu testen. Weitere Informationen finden Sie unter [hier](# experimentell na skalar, um fehlende Werte anzuzeigen).
Wert als "fehlend"
Da Daten in vielen Formen und Formaten vorliegen, möchten Pandas flexibel mit fehlenden Daten umgehen können. NaN ist die Standardmarkierung für fehlende Werte für Rechengeschwindigkeit und Benutzerfreundlichkeit, sollte jedoch für Gleitkomma-, Ganzzahl-, Boolesche und verschiedene Arten von Datentypen für allgemeine Objekte leicht zu erkennen sein. .. In vielen Fällen wird jedoch auch Pythons "Keine" gefunden, und "fehlt" oder "nicht verfügbar" oder "NA" muss berücksichtigt werden.
: information_source: ** Hinweis ** Wenn Sie möchten, dass die Berechnung "inf" und "-inf" als "NA" betrachtet, können Sie sie mit "pandas.options.mode.use_inf_as_na = True" festlegen.
In [**]: df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e', 'f', 'h'],
....: columns=['one', 'two', 'three'])
....:
In [**]: df['four'] = 'bar'
In [**]: df['five'] = df['one'] > 0
In [**]: df
Out[**]:
one two three four five
a 0.469112 -0.282863 -1.509059 bar True
c -1.135632 1.212112 -0.173215 bar False
e 0.119209 -1.044236 -0.861849 bar True
f -2.104569 -0.494929 1.071804 bar False
h 0.721555 -0.706771 -1.039575 bar True
In [**]: df2 = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'])
In [**]: df2
Out[**]:
one two three four five
a 0.469112 -0.282863 -1.509059 bar True
b NaN NaN NaN NaN NaN
c -1.135632 1.212112 -0.173215 bar False
d NaN NaN NaN NaN NaN
e 0.119209 -1.044236 -0.861849 bar True
f -2.104569 -0.494929 1.071804 bar False
g NaN NaN NaN NaN NaN
h 0.721555 -0.706771 -1.039575 bar True
Pandas isna () erleichtert das Erkennen fehlender Werte (manchmal durch Arrays unterschiedlicher Datentypen). /pandas.isna.html#pandas.isna) </ code> und notna () # pandas.notna) </ code> -Funktion wird bereitgestellt. Dies sind auch Methoden für Serien- und DataFrame-Objekte.
In [**]: df2['one']
Out[**]:
a 0.469112
b NaN
c -1.135632
d NaN
e 0.119209
f -2.104569
g NaN
h 0.721555
Name: one, dtype: float64
In [**]: pd.isna(df2['one'])
Out[**]:
a False
b True
c False
d True
e False
f False
g True
h False
Name: one, dtype: bool
In [**]: df2['four'].notna()
Out[**]:
a True
b False
c True
d False
e True
f True
g False
h True
Name: four, dtype: bool
In [**]: df2.isna()
Out[**]:
one two three four five
a False False False False False
b True True True True True
c False False False False False
d True True True True True
e False False False False False
f False False False False False
g True True True True True
h False False False False False
: Warnung: ** Warnung ** Es ist zu beachten, dass in Python (und NumPy) "nan" nicht äquivalent und "None" ** äquivalent ** ist. Beachten Sie, dass pandas / NumPy "None" wie "np.nan" behandelt, während "np.nan! = Np.nan" verwendet wird.
In [**]: None == None # noqa: E711 Out[**]: True In [**]: np.nan == np.nan Out[**]: FalseDaher liefern Skalaräquivalenzvergleiche für "Keine / np.nan" im Vergleich zu den oben genannten keine nützlichen Informationen.
In [**]: df2['one'] == np.nan Out[**]: a False b False c False d False e False f False g False h False Name: one, dtype: bool
Ganzzahliger Datentyp und fehlende Daten
Da "NaN" eine Gleitkommazahl ist, wird eine Spalte mit Ganzzahlen mit mindestens einem fehlenden Wert in einen Gleitkommazahl-Datentyp konvertiert (weitere Informationen finden Sie unter Integer NA-Unterstützung (https: // pandas). Siehe pydata.org/pandas-docs/stable/user_guide/gotchas.html#gotchas-intna)). pandas bietet ein Array von Ganzzahlen, die fehlende Werte enthalten können. Dies kann durch explizite Angabe des Datentyps verwendet werden.
In [**]: pd.Series([1, 2, np.nan, 4], dtype=pd.Int64Dtype())
Out[**]:
0 1
1 2
2 <NA>
3 4
dtype: Int64
Es kann auch durch Angabe des String-Alias "dtype =" Int64 "verwendet werden (beachten Sie das obere" I ").
Weitere Informationen finden Sie unter Fehlende ganzzahlige Datentypen (https://pandas.pydata.org/pandas-docs/stable/user_guide/integer_na.html#integer-na).
Zeitreihendaten (Datum / Uhrzeit)
Für den Typ datetime64 \ [ns ] steht "NaT" für den fehlenden Wert. Dies ist ein pseudo-nativer Sentinel-Wert, der durch einen einzelnen NumPy-Datentyp (datetime64 \ [ns ]) dargestellt werden kann. Das Pandas-Objekt bietet Kompatibilität zwischen "NaT" und "NaN".
In [**]: df2 = df.copy()
In [**]: df2['timestamp'] = pd.Timestamp('20120101')
In [**]: df2
Out[**]:
one two three four five timestamp
a 0.469112 -0.282863 -1.509059 bar True 2012-01-01
c -1.135632 1.212112 -0.173215 bar False 2012-01-01
e 0.119209 -1.044236 -0.861849 bar True 2012-01-01
f -2.104569 -0.494929 1.071804 bar False 2012-01-01
h 0.721555 -0.706771 -1.039575 bar True 2012-01-01
In [**]: df2.loc[['a', 'c', 'h'], ['one', 'timestamp']] = np.nan
In [**]: df2
Out[**]:
one two three four five timestamp
a NaN -0.282863 -1.509059 bar True NaT
c NaN 1.212112 -0.173215 bar False NaT
e 0.119209 -1.044236 -0.861849 bar True 2012-01-01
f -2.104569 -0.494929 1.071804 bar False 2012-01-01
h NaN -0.706771 -1.039575 bar True NaT
In [**]: df2.dtypes.value_counts()
Out[**]:
float64 3
object 1
datetime64[ns] 1
bool 1
dtype: int64
Fehlende Daten einfügen
Sie können fehlende Werte einfach einfügen, indem Sie sie einem Container zuweisen. Die tatsächlich verwendeten fehlenden Werte werden basierend auf dem Datentyp ausgewählt.
Beispielsweise verwendet ein numerischer Container immer "NaN", unabhängig von der Art des angegebenen fehlenden Werts.
In [**]: s = pd.Series([1, 2, 3])
In [**]: s.loc[0] = None
In [**]: s
Out[**]:
0 NaN
1 2.0
2 3.0
dtype: float64
Ebenso verwenden Zeitreihencontainer immer "NaT".
Für Objektcontainer verwenden Pandas den angegebenen Wert.
In [**]: s = pd.Series(["a", "b", "c"])
In [**]: s.loc[0] = None
In [**]: s.loc[1] = np.nan
In [**]: s
Out[**]:
0 None
1 NaN
2 c
dtype: object
Berechnung für fehlende Daten
Fehlende Werte breiten sich auf natürliche Weise durch arithmetische Operationen zwischen Pandas-Objekten aus.
In [**]: a
Out[**]:
one two
a NaN -0.282863
c NaN 1.212112
e 0.119209 -1.044236
f -2.104569 -0.494929
h -2.104569 -0.706771
In [**]: b
Out[**]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e 0.119209 -1.044236 -0.861849
f -2.104569 -0.494929 1.071804
h NaN -0.706771 -1.039575
In [**]: a + b
Out[**]:
one three two
a NaN NaN -0.565727
c NaN NaN 2.424224
e 0.238417 NaN -2.088472
f -4.209138 NaN -0.989859
h NaN NaN -1.413542
Übersicht über die Datenstruktur (und hier -docs / stabil / reference / series.html # api-series-stats) und hier Alle in (Liste von) beschriebenen beschreibenden Statistiken und Berechnungsmethoden werden geschrieben, um die fehlenden Daten zu erklären. Zum Beispiel:
- Beim Summieren der Daten wird der NA-Wert (fehlend) als Null behandelt.
- Wenn alle Daten NA sind, ist das Ergebnis 0.
cumsum () </ code> und < Kumulative Methoden wie Code> cumprod () </ code> Ignoriert standardmäßig NA-Werte, behält sie jedoch im resultierenden Array bei. Verwenden Sieskipna = False, um dieses Verhalten zu überschreiben und den NA-Wert einzuschließen.
In [**]: df
Out[**]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e 0.119209 -1.044236 -0.861849
f -2.104569 -0.494929 1.071804
h NaN -0.706771 -1.039575
In [**]: df['one'].sum()
Out[**]: -1.9853605075978744
In [**]: df.mean(1)
Out[**]:
a -0.895961
c 0.519449
e -0.595625
f -0.509232
h -0.873173
dtype: float64
In [**]: df.cumsum()
Out[**]:
one two three
a NaN -0.282863 -1.509059
c NaN 0.929249 -1.682273
e 0.119209 -0.114987 -2.544122
f -1.985361 -0.609917 -1.472318
h NaN -1.316688 -2.511893
In [**]: df.cumsum(skipna=False)
Out[**]:
one two three
a NaN -0.282863 -1.509059
c NaN 0.929249 -1.682273
e NaN -0.114987 -2.544122
f NaN -0.609917 -1.472318
h NaN -1.316688 -2.511893
Gesamtleistung / Gesamtleistung in leeren / fehlenden Daten
: Warnung: ** Warnung ** Dieses Verhalten ist der aktuelle Standard in Version 0.22.0 und entspricht dem Standardwert "numpy". Zuvor gab die Summe / Summenleistung für alle NAs oder leeren Serien / Datenrahmen NaN zurück. Weitere Informationen finden Sie unter v0.22.0 whatsnew.
Die Summe der Spalten einer Serie oder eines DataFrame, die leer sind oder alle NA enthalten, ist 0.
In [**]: pd.Series([np.nan]).sum()
Out[**]: 0.0
In [**]: pd.Series([], dtype="float64").sum()
Out[**]: 0.0
Die Gesamtleistung einer leeren Serie oder einer DataFrame-Spalte oder aller NA beträgt 1.
In [**]: pd.Series([np.nan]).prod()
Out[**]: 1.0
In [**]: pd.Series([], dtype="float64").prod()
Out[**]: 1.0
Fehlende Werte in GroupBy
GroupBy schließt NA-Gruppen automatisch aus. Dieses Verhalten stimmt mit R überein. Zum Beispiel
In [**]: df
Out[**]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e 0.119209 -1.044236 -0.861849
f -2.104569 -0.494929 1.071804
h NaN -0.706771 -1.039575
In [**]: df.groupby('one').mean()
Out[**]:
two three
one
-2.104569 -0.494929 1.071804
0.119209 -1.044236 -0.861849
Weitere Informationen finden Sie im Abschnitt groupby hier [https://pandas.pydata.org/pandas-docs/stable/user_guide/groupby.html#groupby-missing].
Ausschluss / Ausfüllen fehlender Daten
Das Pandas-Objekt ist mit verschiedenen Datenmanipulationsmethoden zum Umgang mit fehlenden Daten ausgestattet.
Füllen Sie die fehlenden Werte aus
fillna () </ code> fehlt Sie können die Werte mit nicht fehlenden Daten "füllen".
** Ersetzen Sie fehlende Werte durch skalare Werte **
In [**]: df2
Out[**]:
one two three four five timestamp
a NaN -0.282863 -1.509059 bar True NaT
c NaN 1.212112 -0.173215 bar False NaT
e 0.119209 -1.044236 -0.861849 bar True 2012-01-01
f -2.104569 -0.494929 1.071804 bar False 2012-01-01
h NaN -0.706771 -1.039575 bar True NaT
In [**]: df2.fillna(0)
Out[**]:
one two three four five timestamp
a 0.000000 -0.282863 -1.509059 bar True 0
c 0.000000 1.212112 -0.173215 bar False 0
e 0.119209 -1.044236 -0.861849 bar True 2012-01-01 00:00:00
f -2.104569 -0.494929 1.071804 bar False 2012-01-01 00:00:00
h 0.000000 -0.706771 -1.039575 bar True 0
In [**]: df2['one'].fillna('missing')
Out[**]:
a missing
c missing
e 0.119209
f -2.10457
h missing
Name: one, dtype: object
** Füllen Sie die Lücken mit Vorwärts- oder Rückwärtsdaten aus **
Verbreiten Sie nicht fehlende Werte vorwärts oder rückwärts, indem Sie ähnliche Parameter wie Reindex verwenden (https://pandas.pydata.org/pandas-docs/stable/user_guide/basics.html#basics-reindexing). Sie können.
In [**]: df
Out[**]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e 0.119209 -1.044236 -0.861849
f -2.104569 -0.494929 1.071804
h NaN -0.706771 -1.039575
In [**]: df.fillna(method='pad')
Out[**]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e 0.119209 -1.044236 -0.861849
f -2.104569 -0.494929 1.071804
h -2.104569 -0.706771 -1.039575
** Begrenzung der Füllmenge **
Wenn Sie nur aufeinanderfolgende Lücken zu einem bestimmten Datenpunkt füllen möchten, können Sie das Schlüsselwort * limit * verwenden.
In [**]: df
Out[**]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e NaN NaN NaN
f NaN NaN NaN
h NaN -0.706771 -1.039575
In [**]: df.fillna(method='pad', limit=1)
Out[**]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e NaN 1.212112 -0.173215
f NaN NaN NaN
h NaN -0.706771 -1.039575
Die verfügbaren Ausfüllmethoden sind:
| Methode | Bewegung |
|---|---|
| pad / ffill | Füllen Sie die Löcher nach vorne |
| bfill / backfill | Füllen Sie die Löcher rückwärts aus |
Die Verwendung von pad / ffill ist in Zeitreihendaten so häufig, dass der "letzte bekannte Wert" jederzeit verfügbar ist.
ffill () </ code> ist fillna Entspricht (method = 'ffill') , [bfill ()](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.bfill.html# pandas.DataFrame.bfill) </ code> entspricht fillna (method = 'bfill').
Füllen Sie die Lücken mit Pandas-Objekten
Sie können die Lücken auch mit einem ausrichtbaren Wörterbuch oder einer Reihe ausfüllen. Der Wörterbuchschlüssel oder der Serienindex muss mit dem Spaltennamen des Rahmens übereinstimmen, den Sie ausfüllen möchten. Im folgenden Beispiel wird der Datenrahmen mit dem Durchschnitt für diese Spalte gefüllt.
In [**]: dff = pd.DataFrame(np.random.randn(10, 3), columns=list('ABC'))
In [**]: dff.iloc[3:5, 0] = np.nan
In [**]: dff.iloc[4:6, 1] = np.nan
In [**]: dff.iloc[5:8, 2] = np.nan
In [**]: dff
Out[**]:
A B C
0 0.271860 -0.424972 0.567020
1 0.276232 -1.087401 -0.673690
2 0.113648 -1.478427 0.524988
3 NaN 0.577046 -1.715002
4 NaN NaN -1.157892
5 -1.344312 NaN NaN
6 -0.109050 1.643563 NaN
7 0.357021 -0.674600 NaN
8 -0.968914 -1.294524 0.413738
9 0.276662 -0.472035 -0.013960
In [**]: dff.fillna(dff.mean())
Out[**]:
A B C
0 0.271860 -0.424972 0.567020
1 0.276232 -1.087401 -0.673690
2 0.113648 -1.478427 0.524988
3 -0.140857 0.577046 -1.715002
4 -0.140857 -0.401419 -1.157892
5 -1.344312 -0.401419 -0.293543
6 -0.109050 1.643563 -0.293543
7 0.357021 -0.674600 -0.293543
8 -0.968914 -1.294524 0.413738
9 0.276662 -0.472035 -0.013960
In [**]: dff.fillna(dff.mean()['B':'C'])
Out[**]:
A B C
0 0.271860 -0.424972 0.567020
1 0.276232 -1.087401 -0.673690
2 0.113648 -1.478427 0.524988
3 NaN 0.577046 -1.715002
4 NaN -0.401419 -1.157892
5 -1.344312 -0.401419 -0.293543
6 -0.109050 1.643563 -0.293543
7 0.357021 -0.674600 -0.293543
8 -0.968914 -1.294524 0.413738
9 0.276662 -0.472035 -0.013960
Das Ergebnis ist das gleiche wie oben, aber in den folgenden Fällen werden die Werte der Reihe "Ausfüllen" ausgerichtet.
In [**]: dff.where(pd.notna(dff), dff.mean(), axis='columns')
Out[**]:
A B C
0 0.271860 -0.424972 0.567020
1 0.276232 -1.087401 -0.673690
2 0.113648 -1.478427 0.524988
3 -0.140857 0.577046 -1.715002
4 -0.140857 -0.401419 -1.157892
5 -1.344312 -0.401419 -0.293543
6 -0.109050 1.643563 -0.293543
7 0.357021 -0.674600 -0.293543
8 -0.968914 -1.294524 0.413738
9 0.276662 -0.472035 -0.013960
Löschen von Achsenbeschriftungen mit fehlender Datentropna
Möglicherweise möchten Sie einfach die Beschriftungen aus dem Datensatz ausschließen, die sich auf die fehlenden Daten beziehen. Dazu dropna () < Verwenden Sie / code>.
In [**]: df
Out[**]:
one two three
a NaN -0.282863 -1.509059
c NaN 1.212112 -0.173215
e NaN 0.000000 0.000000
f NaN 0.000000 0.000000
h NaN -0.706771 -1.039575
In [**]: df.dropna(axis=0)
Out[**]:
Empty DataFrame
Columns: [one, two, three]
Index: []
In [**]: df.dropna(axis=1)
Out[**]:
two three
a -0.282863 -1.509059
c 1.212112 -0.173215
e 0.000000 0.000000
f 0.000000 0.000000
h -0.706771 -1.039575
In [**]: df['one'].dropna()
Out[**]: Series([], Name: one, dtype: float64)
dropna () </ Code> wird bereitgestellt. DataFrame.dropna bietet unter API erheblich mehr Optionen als Series.dropna (https://pandas.pydata.org/pandas-docs/stable/reference/frame.html#api-dataframe-missing). Sie können es nachschlagen.
Interpolation
Ab _ Version 0.23.0 _: Das Schlüsselwortargument limit_area wurde hinzugefügt.
[interpolate ()](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.interpolate.html#pandas.DataFrame. Für Serien- und Datenrahmenobjekte. Es gibt Interpolation) </ code> und standardmäßig führt es eine lineare Interpolation für die fehlenden Datenpunkte durch.
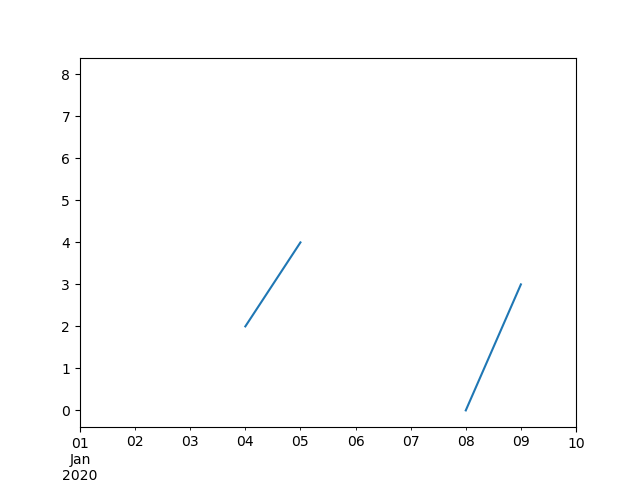
In [**]: ts
Out[**]:
2000-01-31 0.469112
2000-02-29 NaN
2000-03-31 NaN
2000-04-28 NaN
2000-05-31 NaN
...
2007-12-31 -6.950267
2008-01-31 -7.904475
2008-02-29 -6.441779
2008-03-31 -8.184940
2008-04-30 -9.011531
Freq: BM, Length: 100, dtype: float64
In [**]: ts.count()
Out[**]: 66
In [**]: ts.plot()
Out[**]: <matplotlib.axes._subplots.AxesSubplot at 0x7fc18e5ac400>
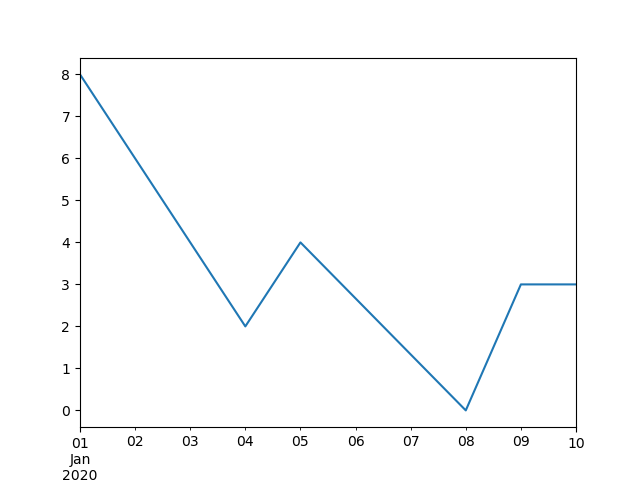
In [**]: ts.interpolate()
Out[**]:
2000-01-31 0.469112
2000-02-29 0.434469
2000-03-31 0.399826
2000-04-28 0.365184
2000-05-31 0.330541
...
2007-12-31 -6.950267
2008-01-31 -7.904475
2008-02-29 -6.441779
2008-03-31 -8.184940
2008-04-30 -9.011531
Freq: BM, Length: 100, dtype: float64
In [**]: ts.interpolate().count()
Out[**]: 100
In [**]: ts.interpolate().plot()
Out[**]: <matplotlib.axes._subplots.AxesSubplot at 0x7fc18e569880>
Sie können eine indexbasierte Interpolation mit dem Schlüsselwort method durchführen.
In [**]: ts2
Out[**]:
2000-01-31 0.469112
2000-02-29 NaN
2002-07-31 -5.785037
2005-01-31 NaN
2008-04-30 -9.011531
dtype: float64
In [**]: ts2.interpolate()
Out[**]:
2000-01-31 0.469112
2000-02-29 -2.657962
2002-07-31 -5.785037
2005-01-31 -7.398284
2008-04-30 -9.011531
dtype: float64
In [**]: ts2.interpolate(method='time')
Out[**]:
2000-01-31 0.469112
2000-02-29 0.270241
2002-07-31 -5.785037
2005-01-31 -7.190866
2008-04-30 -9.011531
dtype: float64
Verwenden Sie für Gleitkommaindizes method = 'values'.
In [**]: ser
Out[**]:
0.0 0.0
1.0 NaN
10.0 10.0
dtype: float64
In [**]: ser.interpolate()
Out[**]:
0.0 0.0
1.0 5.0
10.0 10.0
dtype: float64
In [**]: ser.interpolate(method='values')
Out[**]:
0.0 0.0
1.0 1.0
10.0 10.0
dtype: float64
Ebenso können Sie Datenrahmen interpolieren.
In [**]: df = pd.DataFrame({'A': [1, 2.1, np.nan, 4.7, 5.6, 6.8],
....: 'B': [.25, np.nan, np.nan, 4, 12.2, 14.4]})
....:
In [**]: df
Out[**]:
A B
0 1.0 0.25
1 2.1 NaN
2 NaN NaN
3 4.7 4.00
4 5.6 12.20
5 6.8 14.40
In [**]: df.interpolate()
Out[**]:
A B
0 1.0 0.25
1 2.1 1.50
2 3.4 2.75
3 4.7 4.00
4 5.6 12.20
5 6.8 14.40
Sie können eine erweiterte Interpolation durchführen, indem Sie das Argument method verwenden. Wenn Sie scipy installiert haben, können Sie den Namen der eindimensionalen Interpolationsroutine an method übergeben. Weitere Informationen finden Sie unter Dokumentation und unter Referenz [Handbuch](https: //docs.scipy). Siehe org / doc / scipy / reference / tutorial / interpolate.html). Die geeignete Interpolationsmethode hängt von der Art der Daten ab, mit denen Sie arbeiten.
- Bei Zeitreihen mit hohen Wachstumsraten kann "method =" quadratic "" angebracht sein.
- Für Werte, die nahe an der kumulativen Verteilungsfunktion liegen, sollte
method = 'pchip'funktionieren. --Betrachten Siemethod = 'akima', um fehlende Werte für ein glattes Diagramm einzugeben.
: Warnung: ** Warnung ** Diese Methoden erfordern "scipy".
In [**]: df.interpolate(method='barycentric')
Out[**]:
A B
0 1.00 0.250
1 2.10 -7.660
2 3.53 -4.515
3 4.70 4.000
4 5.60 12.200
5 6.80 14.400
In [**]: df.interpolate(method='pchip')
Out[**]:
A B
0 1.00000 0.250000
1 2.10000 0.672808
2 3.43454 1.928950
3 4.70000 4.000000
4 5.60000 12.200000
5 6.80000 14.400000
In [**]: df.interpolate(method='akima')
Out[**]:
A B
0 1.000000 0.250000
1 2.100000 -0.873316
2 3.406667 0.320034
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
Bei der Interpolation mit einer polymorphen oder Spline-Näherung müssen Sie auch die Reihenfolge der Näherung angeben.
In [**]: df.interpolate(method='spline', order=2)
Out[**]:
A B
0 1.000000 0.250000
1 2.100000 -0.428598
2 3.404545 1.206900
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
In [**]: df.interpolate(method='polynomial', order=2)
Out[**]:
A B
0 1.000000 0.250000
1 2.100000 -2.703846
2 3.451351 -1.453846
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
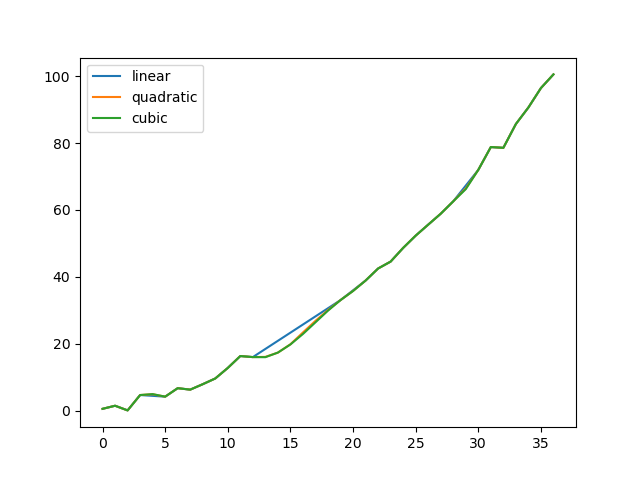
Vergleichen wir verschiedene Methoden.
In [**]: np.random.seed(2)
In [**]: ser = pd.Series(np.arange(1, 10.1, .25) ** 2 + np.random.randn(37))
In [**]: missing = np.array([4, 13, 14, 15, 16, 17, 18, 20, 29])
In [**]: ser[missing] = np.nan
In [**]: methods = ['linear', 'quadratic', 'cubic']
In [**]: df = pd.DataFrame({m: ser.interpolate(method=m) for m in methods})
In [**]: df.plot()
Out[**]: <matplotlib.axes._subplots.AxesSubplot at 0x7fc18e5b6c70>
Ein weiterer Anwendungsfall ist die Interpolation mit neuen Werten. Angenommen, Sie haben 100 Beobachtungen aus einer Verteilung. Nehmen wir an, Sie interessieren sich besonders für das, was in der Nähe des Zentrums passiert. Sie können mit neuen Werten interpolieren, indem Sie die Methoden "Reindex" und "Interpolieren" von Pandas kombinieren.
In [**]: ser = pd.Series(np.sort(np.random.uniform(size=100)))
#Interpolation für neuen Index
In [**]: new_index = ser.index | pd.Index([49.25, 49.5, 49.75, 50.25, 50.5, 50.75])
In [**]: interp_s = ser.reindex(new_index).interpolate(method='pchip')
In [**]: interp_s[49:51]
Out[**]:
49.00 0.471410
49.25 0.476841
49.50 0.481780
49.75 0.485998
50.00 0.489266
50.25 0.491814
50.50 0.493995
50.75 0.495763
51.00 0.497074
dtype: float64
Interpolationsgrenzen
Wie bei anderen Pandas-Methoden zum Ausfüllen der Lücke [interpolate ()](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.interpolate.html#pandas.DataFrame .interpolate) </ code> verwendet das Schlüsselwortargument limit. Mit diesem Argument können Sie die Anzahl der aufeinanderfolgenden NaN-Werte begrenzen, die seit der letzten gültigen Beobachtung eingegeben wurden.
In [**]: ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan,
....: np.nan, 13, np.nan, np.nan])
....:
In [**]: ser
Out[**]:
0 NaN
1 NaN
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
dtype: float64
#Füllen Sie alle Werte in einer Reihe vorwärts
In [**]: ser.interpolate()
Out[**]:
0 NaN
1 NaN
2 5.0
3 7.0
4 9.0
5 11.0
6 13.0
7 13.0
8 13.0
dtype: float64
#Füllen Sie nur einen Wert vorwärts
In [**]: ser.interpolate(limit=1)
Out[**]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 NaN
6 13.0
7 13.0
8 NaN
dtype: float64
Standardmäßig wird der NaN-Wert vorwärts gefüllt. Verwenden Sie den Parameter limit_direction, um Löcher von hinten oder in beide Richtungen zu füllen.
#Füllen Sie ein Loch nach hinten
In [**]: ser.interpolate(limit=1, limit_direction='backward')
Out[**]:
0 NaN
1 5.0
2 5.0
3 NaN
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
dtype: float64
#Füllen Sie ein Loch in beide Richtungen
In [**]: ser.interpolate(limit=1, limit_direction='both')
Out[**]:
0 NaN
1 5.0
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 13.0
8 NaN
dtype: float64
#Füllen Sie alle Werte, die in beide Richtungen aufeinander folgen
In [**]: ser.interpolate(limit_direction='both')
Out[**]:
0 5.0
1 5.0
2 5.0
3 7.0
4 9.0
5 11.0
6 13.0
7 13.0
8 13.0
dtype: float64
Standardmäßig wird der NaN-Wert innerhalb (eingeschlossen) des vorhandenen gültigen Werts oder außerhalb des vorhandenen gültigen Werts gefüllt. Der in Version 0.23 eingeführte Parameter limit_area begrenzt die Eingabe auf interne oder externe Werte.
#Füllen Sie einen kontinuierlichen inneren Wert in beide Richtungen
In [**]: ser.interpolate(limit_direction='both', limit_area='inside', limit=1)
Out[**]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
dtype: float64
#Füllen Sie alle aufeinander folgenden äußeren Werte in die entgegengesetzte Richtung
In [**]: ser.interpolate(limit_direction='backward', limit_area='outside')
Out[**]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
dtype: float64
#Füllen Sie alle äußeren Werte, die in beide Richtungen kontinuierlich sind
In [**]: ser.interpolate(limit_direction='both', limit_area='outside')
Out[**]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 13.0
8 13.0
dtype: float64
Allgemeine Wertersetzung
Oft möchten Sie einen Wert durch einen anderen ersetzen.
Serie replace () </ code> und Datenrahmen replace () </ code> Ermöglicht es Ihnen, solche Ersetzungen effizient und flexibel durchzuführen.
Bei Serien können Sie einen einzelnen Wert oder eine Liste von Werten durch einen anderen Wert ersetzen.
In [**]: ser = pd.Series([0., 1., 2., 3., 4.])
In [**]: ser.replace(0, 5)
Out[**]:
0 5.0
1 1.0
2 2.0
3 3.0
4 4.0
dtype: float64
Sie können die Werteliste durch eine Liste anderer Werte ersetzen.
In [**]: ser.replace([0, 1, 2, 3, 4], [4, 3, 2, 1, 0])
Out[**]:
0 4.0
1 3.0
2 2.0
3 1.0
4 0.0
dtype: float64
Sie können auch ein Zuordnungswörterbuch angeben.
In [**]: ser.replace({0: 10, 1: 100})
Out[**]:
0 10.0
1 100.0
2 2.0
3 3.0
4 4.0
dtype: float64
Für Datenrahmen können Sie für jede Spalte einen eigenen Wert angeben.
In [**]: df = pd.DataFrame({'a': [0, 1, 2, 3, 4], 'b': [5, 6, 7, 8, 9]})
In [**]: df.replace({'a': 0, 'b': 5}, 100)
Out[**]:
a b
0 100 100
1 1 6
2 2 7
3 3 8
4 4 9
Anstatt durch den angegebenen Wert zu ersetzen, können Sie alle angegebenen Werte als fehlende Werte behandeln und interpolieren.
In [**]: ser.replace([1, 2, 3], method='pad')
Out[**]:
0 0.0
1 0.0
2 0.0
3 0.0
4 4.0
dtype: float64
Ersetzen von Zeichenketten und regulären Ausdrücken
: information_source: ** Hinweis ** Python-Strings, denen "r" vorangestellt ist, wie "r'hello world", sind sogenannte "rohe" Strings. Sie haben eine andere Backslash-Semantik als nicht festgelegte Zeichenfolgen. Backslashes in der Rohzeichenfolge werden als maskierte Backslashes interpretiert (z. B.
r '\' == '\\'). Wenn Sie sich nicht sicher sind, sollten Sie dies lesen (https://docs.python.org/3/reference/lexical_analysis.html#string-literals).
Ersetzen Sie "." Durch "NaN" (Zeichenkette → Zeichenkette).
In [**]: d = {'a': list(range(4)), 'b': list('ab..'), 'c': ['a', 'b', np.nan, 'd']}
In [**]: df = pd.DataFrame(d)
In [**]: df.replace('.', np.nan)
Out[**]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
Entfernen Sie als Nächstes die umgebenden Leerzeichen mit dem regulären Ausdruck (regulärer Ausdruck → regulärer Ausdruck).
In [**]: df.replace(r'\s*\.\s*', np.nan, regex=True)
Out[**]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
Ersetzen Sie einige andere Werte (Liste → Liste).
In [**]: df.replace(['a', '.'], ['b', np.nan])
Out[**]:
a b c
0 0 b b
1 1 b b
2 2 NaN NaN
3 3 NaN d
Liste der regulären Ausdrücke → Liste der regulären Ausdrücke.
In [**]: df.replace([r'\.', r'(a)'], ['dot', r'\1stuff'], regex=True)
Out[**]:
a b c
0 0 astuff astuff
1 1 b b
2 2 dot NaN
3 3 dot d
Suchen Sie nur die Spalte "b" (Wörterbuch → Wörterbuch).
In [**]: df.replace({'b': '.'}, {'b': np.nan})
Out[**]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
Wie im vorherigen Beispiel, jedoch einen regulären Ausdruck für die Suche verwenden (Wörterbuch für reguläre Ausdrücke → Wörterbuch).
In [**]: df.replace({'b': r'\s*\.\s*'}, {'b': np.nan}, regex=True)
Out[**]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
Sie können regex = True verwenden, um ein verschachteltes Wörterbuch mit regulären Ausdrücken zu übergeben.
In [**]: df.replace({'b': {'b': r''}}, regex=True)
Out[**]:
a b c
0 0 a a
1 1 b
2 2 . NaN
3 3 . d
Alternativ können Sie ein verschachteltes Wörterbuch wie folgt übergeben:
In [**]: df.replace(regex={'b': {r'\s*\.\s*': np.nan}})
Out[**]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
Sie können auch durch eine Gruppe von Übereinstimmungen mit regulären Ausdrücken ersetzen (Wörterbuch für reguläre Ausdrücke → Wörterbuch für reguläre Ausdrücke). Dies funktioniert auch für Listen.
In [**]: df.replace({'b': r'\s*(\.)\s*'}, {'b': r'\1ty'}, regex=True)
Out[**]:
a b c
0 0 a a
1 1 b b
2 2 .ty NaN
3 3 .ty d
Sie können eine Liste regulärer Ausdrücke übergeben, und alle Übereinstimmungen werden durch einen Skalar ersetzt (Liste regulärer Ausdrücke → reguläre Ausdrücke).
In [**]: df.replace([r'\s*\.\s*', r'a|b'], np.nan, regex=True)
Out[**]:
a b c
0 0 NaN NaN
1 1 NaN NaN
2 2 NaN NaN
3 3 NaN d
Alle Beispiele für reguläre Ausdrücke können auch das Argument "to_replace" als Argument "regex" übergeben. In diesem Fall muss das Argument "value" explizit als Name übergeben werden, oder "regex" muss ein verschachteltes Wörterbuch sein. Das vorherige Beispiel in diesem Fall sieht folgendermaßen aus:
In [**]: df.replace(regex=[r'\s*\.\s*', r'a|b'], value=np.nan)
Out[**]:
a b c
0 0 NaN NaN
1 1 NaN NaN
2 2 NaN NaN
3 3 NaN d
Dies ist nützlich, wenn Sie nicht jedes Mal, wenn Sie einen regulären Ausdruck verwenden, "regex = True" übergeben möchten.
Im obigen Beispiel "Ersetzen" ist die Übergabe eines kompilierten regulären Ausdrucks genauso gültig, wo immer Sie einen regulären Ausdruck übergeben können.
Numerischer Ersatz
replace () </ code> ist > Ähnlich wie fillna () </ code>.
In [**]: df = pd.DataFrame(np.random.randn(10, 2))
In [**]: df[np.random.rand(df.shape[0]) > 0.5] = 1.5
In [**]: df.replace(1.5, np.nan)
Out[**]:
0 1
0 -0.844214 -1.021415
1 0.432396 -0.323580
2 0.423825 0.799180
3 1.262614 0.751965
4 NaN NaN
5 NaN NaN
6 -0.498174 -1.060799
7 0.591667 -0.183257
8 1.019855 -1.482465
9 NaN NaN
Sie können mehrere Werte ersetzen, indem Sie eine Liste übergeben.
In [**]: df00 = df.iloc[0, 0]
In [**]: df.replace([1.5, df00], [np.nan, 'a'])
Out[**]:
0 1
0 a -1.02141
1 0.432396 -0.32358
2 0.423825 0.79918
3 1.26261 0.751965
4 NaN NaN
5 NaN NaN
6 -0.498174 -1.0608
7 0.591667 -0.183257
8 1.01985 -1.48247
9 NaN NaN
In [**]: df[1].dtype
Out[**]: dtype('float64')
Sie können den Datenrahmen auch direkt verarbeiten.
In [**]: df.replace(1.5, np.nan, inplace=True)
: Warnung: ** Warnung ** Beim Ersetzen mehrerer "bool" - oder "datetime64" -Objekte muss das erste Argument von "replace" ("to_replace") mit dem Typ des zu ersetzenden Werts übereinstimmen. Zum Beispiel
>>> s = pd.Series([True, False, True]) >>> s.replace({'a string': 'new value', True: False}) # raises TypeError: Cannot compare types 'ndarray(dtype=bool)' and 'str'Ein "TypeError" tritt auf, weil einer der "dict" -Tasten nicht zum Ersetzen geeignet ist.
Wenn Sie jedoch ein * einzelnes * Objekt wie folgt ersetzen möchten:
In [**]: s = pd.Series([True, False, True]) In [**]: s.replace('a string', 'another string') Out[**]: 0 True 1 False 2 True dtype: boolDas ursprüngliche NDFrame-Objekt wird unverändert zurückgegeben. Wir arbeiten derzeit an der Integration dieser API, aber aus Gründen der Abwärtskompatibilität können wir das letztere Verhalten nicht brechen. Weitere Informationen finden Sie unter GH6354.
Fehlende Datenübertragungsregeln und Indizierung
pandas unterstützt das Speichern von Integer- und Booleschen Arrays, diese Typen können jedoch keine fehlenden Daten speichern. Bis NumPy auf den nativen NA-Typ umstellte, gab es einige "Besetzungsregeln". Wenn die Neuindizierungsoperation zu fehlenden Daten führt, wird die Serie gemäß den in der folgenden Tabelle aufgeführten Regeln gegossen.
| Datentyp | Besetzungsziel |
|---|---|
| ganze Zahl | Schwimmende Fraktion |
| Boolescher Wert | Objekt |
| Schwimmende Fraktion | Nicht gießen |
| Objekt | Nicht gießen |
Zum Beispiel
In [**]: s = pd.Series(np.random.randn(5), index=[0, 2, 4, 6, 7])
In [**]: s > 0
Out[**]:
0 True
2 True
4 True
6 True
7 True
dtype: bool
In [**]: (s > 0).dtype
Out[**]: dtype('bool')
In [**]: crit = (s > 0).reindex(list(range(8)))
In [**]: crit
Out[**]:
0 True
1 NaN
2 True
3 NaN
4 True
5 NaN
6 True
7 True
dtype: object
In [**]: crit.dtype
Out[**]: dtype('O')
Normalerweise beschwert sich NumPy, wenn versucht wird, einen Wert von einem ndarray mithilfe eines Objektarrays anstelle eines booleschen Arrays abzurufen oder festzulegen (z. B. Auswahl eines Werts anhand einiger Kriterien). Eine Ausnahme wird ausgelöst, wenn der Boolesche Vektor NA enthält.
In [**]: reindexed = s.reindex(list(range(8))).fillna(0)
In [**]: reindexed[crit]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-138-0dac417a4890> in <module>
----> 1 reindexed[crit]
~/work/pandas/pandas/pandas/core/series.py in __getitem__(self, key)
901 key = list(key)
902
--> 903 if com.is_bool_indexer(key):
904 key = check_bool_indexer(self.index, key)
905 key = np.asarray(key, dtype=bool)
~/work/pandas/pandas/pandas/core/common.py in is_bool_indexer(key)
132 na_msg = "Cannot mask with non-boolean array containing NA / NaN values"
133 if isna(key).any():
--> 134 raise ValueError(na_msg)
135 return False
136 return True
ValueError: Cannot mask with non-boolean array containing NA / NaN values
Dies sind jedoch fillna () </ code Wenn Sie die Löcher mit> ausfüllen, funktioniert es einwandfrei.
In [**]: reindexed[crit.fillna(False)]
Out[**]:
0 0.126504
2 0.696198
4 0.697416
6 0.601516
7 0.003659
dtype: float64
In [**]: reindexed[crit.fillna(True)]
Out[**]:
0 0.126504
1 0.000000
2 0.696198
3 0.000000
4 0.697416
5 0.000000
6 0.601516
7 0.003659
dtype: float64
pandas bietet ganzzahlige Datentypen mit möglicherweise fehlenden Werten. Sie müssen diese jedoch beim Erstellen einer Reihe oder Spalte explizit angeben. Beachten Sie, dass wir das obere "I" in "dtype =" Int64 "" verwenden.
In [**]: s = pd.Series([0, 1, np.nan, 3, 4], dtype="Int64")
In [**]: s
Out[**]:
0 0
1 1
2 <NA>
3 3
4 4
dtype: Int64
Weitere Informationen finden Sie unter Fehlende ganzzahlige Datentypen (https://pandas.pydata.org/pandas-docs/stable/user_guide/integer_na.html#integer-na).
Experimenteller NA-Skalar, um fehlende Werte anzuzeigen
: Warnung: ** Warnung ** Testbetrieb: Das Verhalten von
pd.NAkann ohne Vorwarnung geändert werden.
_ Ab Version 1.0.0 _
Ab Pandas 1.0 steht der experimentelle Wert "pd.NA" (einzelne Tonne) zur Verfügung, um skalare fehlende Werte darzustellen. Derzeit werden nullfähige Ganzzahl-, Boolesche und dedizierte Zeichenfolgendatentypen als Indikatoren für fehlende Werte verwendet.
Beginnend mit Pandas 1.0 können experimentelle pd.NA-Werte (einzelne Tonnen) verwendet werden, um skalare fehlende Werte darzustellen. Zu diesem Zeitpunkt Missable Integer, Bourian und [Dedicated String](https: // qiita.com/nkay/items/3866b3f12704ec3271ca # Textdatentyp) Wird als fehlender Wertindikator im Datentyp verwendet.
Der Zweck von "pd.NA" besteht darin, "fehlende" Werte bereitzustellen, die für alle Datentypen konsistent verwendet werden können (anstelle von "np.nan", "None" und "pd.NaT", abhängig vom Datentyp. Zu).
Wenn beispielsweise in einer Reihe fehlender ganzzahliger Datentypen Werte fehlen, wird "pd.NA" verwendet.
In [**]: s = pd.Series([1, 2, None], dtype="Int64")
In [**]: s
Out[**]:
0 1
1 2
2 <NA>
dtype: Int64
In [**]: s[2]
Out[**]: <NA>
In [**]: s[2] is pd.NA
Out[**]: True
Derzeit verwendet pandas diese Datentypen noch nicht standardmäßig (beim Erstellen oder Laden von Datenrahmen oder Serien). Daher müssen Sie die Datentypen explizit angeben. Eine einfache Möglichkeit zur Konvertierung in diese Datentypen wird hier beschrieben (# Konvertierung).
Ausbreitung in Arithmetik- und Vergleichsoperationen
Im Allgemeinen verbreiten Operationen mit "pd.NA" fehlende Werte. Wenn einer der Operanden unbekannt ist, ist auch das Ergebnis der Operation unbekannt.
Zum Beispiel verbreitet sich "pd.NA" arithmetisch wie "np.nan".
In [**]: pd.NA + 1
Out[**]: <NA>
In [**]: "a" * pd.NA
Out[**]: <NA>
Selbst wenn einer der Operanden "NA" ist, gibt es einige Sonderfälle, wenn das Ergebnis bekannt ist.
In [**]: pd.NA ** 0
Out[**]: 1
In [**]: 1 ** pd.NA
Out[**]: 1
Gleichheits- und Vergleichsoperationen verbreiten auch "pd.NA". Dies unterscheidet sich vom Verhalten von "np.nan", bei dem das Vergleichsergebnis immer "Falsch" ist.
In [**]: pd.NA == 1
Out[**]: <NA>
In [**]: pd.NA == pd.NA
Out[**]: <NA>
In [**]: pd.NA < 2.5
Out[**]: <NA>
Um herauszufinden, ob der Wert gleich "pd.NA" ist, isna () Verwenden Sie die Funktion # pandas.isna) </ code>.
In [**]: pd.isna(pd.NA)
Out[**]: True
Die Ausnahme von dieser grundlegenden Ausbreitungsregel ist * Reduktion * (wie Mittelwert oder Minimum), und Pandas überspringt standardmäßig fehlende Werte. Einzelheiten finden Sie unter [oben](## Berechnung für fehlende Daten).
Logische Operation
Für logische Operationen ist pd.NA [ternäre Logik](https://ja.wikipedia.org/wiki/3value Logik) (auch Kleines Logik genannt, die sich wie R / SQL / Julia verhält) Befolgen Sie die Regeln von. Diese Logik bedeutet, fehlende Werte nur dann weiterzugeben, wenn dies logisch benötigt wird.
Wenn beispielsweise bei einer logischen Operation "oder" ("|") einer der Operanden "Wahr" ist, ist er "Falsch", unabhängig vom anderen Wert (dh selbst wenn der fehlende Wert "Wahr" ist). Außerdem wissen wir bereits, dass das Ergebnis "True" sein wird. In diesem Fall wird "pd.NA" nicht weitergegeben.
In [**]: True | False
Out[**]: True
In [**]: True | pd.NA
Out[**]: True
In [**]: pd.NA | True
Out[**]: True
Wenn andererseits einer der Operanden "False" ist, hängt das Ergebnis vom Wert des anderen Operanden ab. Daher wird sich in diesem Fall "pd.NA" ausbreiten.
In [**]: False | True
Out[**]: True
In [**]: False | False
Out[**]: False
In [**]: False | pd.NA
Out[**]: <NA>
Das Verhalten der logischen Operation "und" ("&") kann auch unter Verwendung einer ähnlichen Logik abgeleitet werden (in diesem Fall "pd.NA", wenn einer der Operanden bereits "False" ist. Propagiert nicht).
In [**]: False & True
Out[**]: False
In [**]: False & False
Out[**]: False
In [**]: False & pd.NA
Out[**]: False
In [**]: True & True
Out[**]: True
In [**]: True & False
Out[**]: False
In [**]: True & pd.NA
Out[**]: <NA>
NA im bourianischen Kontext
Fehlende Werte können nicht in Boolesche Werte konvertiert werden, da der tatsächliche Wert unbekannt ist. Folgendes führt zu einem Fehler.
In [**]: bool(pd.NA)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-167-5477a57d5abb> in <module>
----> 1 bool(pd.NA)
~/work/pandas/pandas/pandas/_libs/missing.pyx in pandas._libs.missing.NAType.__bool__()
TypeError: boolean value of NA is ambiguous
Dies bedeutet auch, dass in einem Kontext, in dem "pd.NA" mit einem Booleschen Wert ausgewertet wird, beispielsweise "wenn Bedingung: ...", "Bedingung" "pd.NA" sein kann. NA` bedeutet, dass es nicht verwendet werden kann. Verwenden Sie in einem solchen Fall isna () </ code> Sie können es verwenden, um "pd.NA" zu überprüfen oder beispielsweise die fehlenden Werte vorab zu füllen, um zu vermeiden, dass die Bedingung "pd.NA" ist.
Eine ähnliche Situation tritt auf, wenn Serien- oder Datenrahmenobjekte in der if-Anweisung verwendet werden. Siehe Verwenden von if / Truth-Anweisungen mit Pandas (https://pandas.pydata.org/pandas-docs/stable/user_guide/gotchas.html#gotchas-truth).
NumPy ufunc
pandas.NA implementiert das NumPy's __array_ufunc__ Protokoll. Die meisten Ufunc funktionieren für "NA" und geben im Allgemeinen "NA" zurück.
In [**]: np.log(pd.NA)
Out[**]: <NA>
In [**]: np.add(pd.NA, 1)
Out[**]: <NA>
: Warnung: ** Warnung ** Derzeit gibt ufunc mit ndarray und
NAeinen Objektdatentyp zurück, der mit fehlenden Werten gefüllt ist.In [**]: a = np.array([1, 2, 3]) In [**]: np.greater(a, pd.NA) Out[**]: array([<NA>, <NA>, <NA>], dtype=object)Der Rückgabetyp hier kann geändert werden, um in Zukunft einen anderen Array-Typ zurückzugeben.
Weitere Informationen zu ufunc finden Sie unter Interoperabilität von DataFrame- und NumPy-Funktionen (https://pandas.pydata.org/pandas-docs/stable/user_guide/dsintro.html#dsintro-numpy-interop). ..
Umwandlung
Wenn Sie einen Datenrahmen oder eine Serie haben, die traditionelle Typen verwendet, und Daten haben, die nicht mit np.nan dargestellt werden, hat die Serie [convert_dtypes ()](https: //). pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.convert_dtypes.html#pandas.Series.convert_dtypes) </ code>, aber convert_dtypes () im Datenrahmen Es gibt //pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.convert_dtypes.html#pandas.DataFrame.convert_dtypes) </ code> und [hier](https: // pandas). Sie können Ihre Daten konvertieren, um die neuen Datentypen von Ganzzahlen, Zeichenfolgen und Bourianen zu verwenden, die unter pydata.org/pandas-docs/stable/user_guide/basics.html#basics-dtypes aufgeführt sind. Dies ist read_csv () nach dem Laden des Datensatzes. Für Leser wie Code> und read_excel () </ code> Dies ist besonders nützlich, um den Standarddatentyp zu erraten.
In diesem Beispiel haben sich die Datentypen aller Spalten geändert, aber die Ergebnisse für die ersten 10 Spalten werden angezeigt.
In [**]: bb = pd.read_csv('data/baseball.csv', index_col='id')
In [**]: bb[bb.columns[:10]].dtypes
Out[**]:
player object
year int64
stint int64
team object
lg object
g int64
ab int64
r int64
h int64
X2b int64
dtype: object
In [**]: bbn = bb.convert_dtypes()
In [**]: bbn[bbn.columns[:10]].dtypes
Out[**]:
player string
year Int64
stint Int64
team string
lg string
g Int64
ab Int64
r Int64
h Int64
X2b Int64
dtype: object