[PYTHON] Pandas Benutzerhandbuch "Zusammenführen und Verbinden und Verketten" (offizielles Dokument Japanische Übersetzung)
Dieser Artikel ist eine maschinelle Übersetzung der offiziellen Pandas-Dokumentation Benutzerhandbuch - Zusammenführen, Verbinden und Verketten. Es ist eine Modifikation der unnatürlichen Sätze des Clubs.
Wenn Sie falsche Übersetzungen, alternative Übersetzungen, Fragen usw. haben, verwenden Sie bitte den Kommentarbereich oder bearbeiten Sie die Anfrage.
zusammenführen, verbinden und verketten
pandas bietet verschiedene Arten von Set-Operationen und verschiedene Funktionen zum Indizieren und relationale algebraische Funktionen in Join / Merge-Operationen, um Serien oder DataFrames einfach zu verbinden.
Objekt verketten
concat () Funktion (existiert im Haupt-Pandas-Namespace) Erledigt die mühsame Arbeit, Verkettungsoperationen entlang einer Achse auszuführen, während beliebige Mengenoperationen (Vereinigung oder Schnittmenge) an den Indizes anderer Achsen (falls vorhanden) ausgeführt werden. Beachten Sie, dass wir "wenn ja" sagen, da die Serie nur eine Verbindungsachse hat. Bevor wir uns mit den Details von Concat und seinen Möglichkeiten befassen, finden Sie hier ein einfaches Beispiel.
Bevor wir uns mit den Details von "concat" und seinen Möglichkeiten befassen, hier ein einfaches Beispiel.
In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']},
...: index=[0, 1, 2, 3])
...:
In [2]: df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
...: 'B': ['B4', 'B5', 'B6', 'B7'],
...: 'C': ['C4', 'C5', 'C6', 'C7'],
...: 'D': ['D4', 'D5', 'D6', 'D7']},
...: index=[4, 5, 6, 7])
...:
In [3]: df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
...: 'B': ['B8', 'B9', 'B10', 'B11'],
...: 'C': ['C8', 'C9', 'C10', 'C11'],
...: 'D': ['D8', 'D9', 'D10', 'D11']},
...: index=[8, 9, 10, 11])
...:
In [4]: frames = [df1, df2, df3]
In [5]: result = pd.concat(frames)
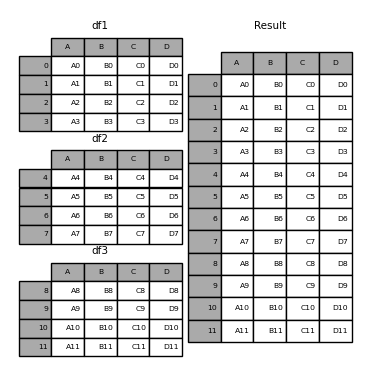
Ähnlich wie die Geschwisterfunktion ndpy.concatenate von ndarrays verwendet pandas.concat eine Liste oder ein Wörterbuch ähnlicher Objekte sowie einige konfigurierbare" Was tun mit anderen Achsen "-Verarbeitung. Verketten.
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, copy=True)
--objs: Sequenz oder Zuordnung von Series- oder DataFrame-Objekten. Wenn ein Wörterbuch übergeben wird, werden die sortierten Schlüssel als * Schlüssel * -Argumente verwendet. Wenn nicht, wird der Wert ausgewählt (siehe unten). Keine Objekte werden implizit ausgeschlossen. Wenn alle None sind, tritt ein Wertefehler auf.
--Achse: {0, 1,…}, Standard ist 0. Geben Sie die zu verbindenden Achsen an.
--join: {'inner', 'äußere'}, Standard ist 'äußere'. Umgang mit Indizes auf anderen Achsen. Das Äußere ist die Summe (Vereinigung) und das Innere ist der gemeinsame Teil (Schnittpunkt).
--ignore_index: Boolescher Wert, Standard ist False. Wenn True, wird der Indexwert auf der verketteten Achse nicht verwendet. Die resultierenden Achsen sind mit 0,…, n -1 gekennzeichnet. Dies ist nützlich, wenn Sie Objekte verketten, die keine aussagekräftigen Indexinformationen auf der Verkettungsachse haben. Beachten Sie, dass die Indexwerte auf den anderen Achsen weiterhin in der Verknüpfung berücksichtigt werden.
--keys: Sequenz, Standard ist None. Erstellt einen hierarchischen Index unter Verwendung des übergebenen Schlüssels als äußerste Ebene. Wenn mehrere Ebenen bestanden werden, muss der Tapple enthalten sein.
--levels: Liste der Sequenzen, Standard ist None. Die spezifische Ebene (eindeutiger Wert), die zum Erstellen des MultiIndex verwendet wird. Wenn Keine, wird es aus Schlüsseln abgeleitet.
--names: Liste, Standard ist None. Der Name der Ebene des resultierenden hierarchischen Index.
-- verify_integrity: Boolescher Wert, Standard ist False. Überprüfen Sie, ob die neue Verbindungsachse Duplikate enthält. Dies kann im Vergleich zur tatsächlichen Datenverkettung sehr teuer sein.
--copy: Boolescher Wert, Standard ist True. Bei False werden die Daten nicht unnötig kopiert.
Ohne eine Erklärung sind die meisten dieser Argumente möglicherweise nicht sinnvoll. Schauen wir uns das obige Beispiel noch einmal an. Angenommen, Sie möchten jedem Teil eines DataFrames vor dem Beitritt einen bestimmten Schlüssel zuordnen. Sie können dies mit dem Argument "keys" tun.
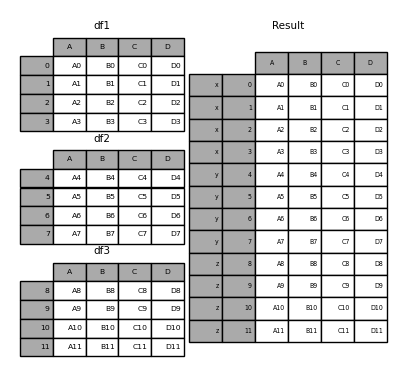
In [6]: result = pd.concat(frames, keys=['x', 'y', 'z'])
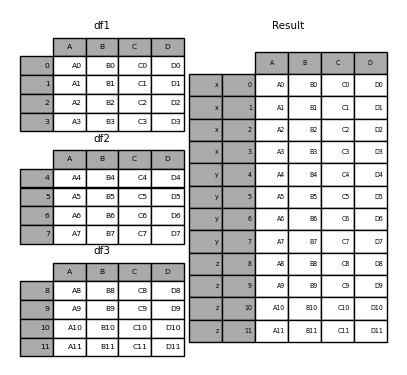
Wie Sie sehen können (wenn Sie den Rest des Dokuments lesen), verfügt der resultierende Objektindex über einen hierarchischen Index (https://qiita.com/nkay/items/63afdd4e96f21efbf62b#hierarchical). Es gibt einen Index (Multi-Index). Dies bedeutet, dass Sie jeden Block nach Schlüssel auswählen können.
In [7]: result.loc['y']
Out[7]:
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
Es ist nicht schwer zu erkennen, wie nützlich dies ist. Weitere Informationen zu dieser Funktion finden Sie weiter unten.
: ballot_box_with_check: ** Hinweis **
concat ()(daherappend ()) sind die Daten Beachten Sie, dass das Erstellen einer vollständigen Kopie und die ständige Wiederverwendung dieser Funktion die Leistung erheblich beeinträchtigen. Wenn Sie die Operation mit mehreren Datasets verwenden müssen, verwenden Sie die Listeneinschlussnotation.
frames = [ process_your_file(f) for f in files ]
result = pd.concat(frames)
Stellen Sie Operationen auf anderen Achsen ein
Wenn Sie mehrere DataFrames kombinieren, können Sie auswählen, wie andere Achsen (außer den verbundenen Achsen) behandelt werden sollen. Dies kann auf zwei Arten erfolgen:
- Wenn Sie allen beitreten möchten (Summe, Vereinigung), setzen Sie "join =" Outer ". Dies ist die Standardoption, da sie zu keinem Informationsverlust führt.
- Wenn Sie einen gemeinsamen Teil (Schnittpunkt) nehmen möchten, setzen Sie "join =" inner ".
Hier ist ein Beispiel für jede dieser Methoden: Erstens ist das Verhalten, wenn der Standardwert "join =" äußere "ist
In [8]: df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
...: 'D': ['D2', 'D3', 'D6', 'D7'],
...: 'F': ['F2', 'F3', 'F6', 'F7']},
...: index=[2, 3, 6, 7])
...:
In [9]: result = pd.concat([df1, df4], axis=1, sort=False)
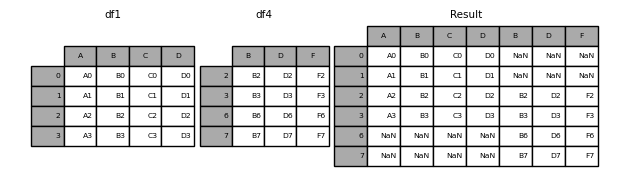
: Warnung: ** Warnung ** _ In Version 0.23.0 geändert _
join = 'Outer'sortiert standardmäßig andere Achsen (in diesem Fall Spalten). Zukünftige Versionen von Pandas werden nicht standardmäßig sortiert. Hier haben wirsort = Falseangegeben und das neue Verhalten ausgewählt.
Wenn Sie dasselbe mit join = 'inner' tun,
In [10]: result = pd.concat([df1, df4], axis=1, join='inner')

Angenommen, Sie möchten den * exakten Index * des ursprünglichen DataFrame wiederverwenden.
In [11]: result = pd.concat([df1, df4], axis=1).reindex(df1.index)
Ebenso können Sie vor dem Beitritt einen Index erstellen.
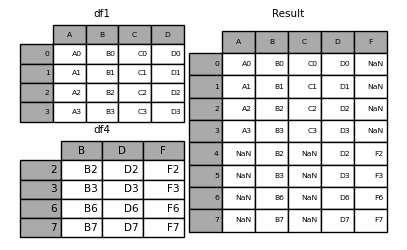
In [12]: pd.concat([df1, df4.reindex(df1.index)], axis=1)
Out[12]:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3

Verkettung mit "Anhängen"
[Append ()] von Series und DataFrame (https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.append.html#pandas.DataFrame.append) Die Instanzmethode ist eine praktische Verknüpfung zu concat (). In Wirklichkeit gingen diese Methoden "concat" voraus. Sie verbinden sich entlang der Achse = 0, dh des Index.
In [13]: result = df1.append(df2)

Bei "DataFrame" sind die Zeilen immer getrennt (auch wenn sie denselben Wert haben), die Spalten jedoch nicht.
In [14]: result = df1.append(df4, sort=False)

"Anhängen" kann auch mehrere Objekte empfangen und kombinieren.
In [15]: result = df1.append([df2, df3])

: ballot_box_with_check: ** Hinweis ** Der Listentyp
append ()fügt der ursprünglichen Liste ein Element hinzu und gibt None zurück, aber diese Pandasappend ()/stable/reference/api/pandas.DataFrame.append.html#pandas.DataFrame.append) gibt eine Kopie vondf1** unverändert ** unddf2verkettet zurück.
Ignorieren Sie den Index der Verbindungsachse
Bei "DataFrame" -Objekten, die keine aussagekräftigen Indizes haben, möchten Sie möglicherweise doppelte Indizes ignorieren, wenn Sie sie verbinden. Verwenden Sie dazu das Argument ignore_index.
In [16]: result = pd.concat([df1, df4], ignore_index=True, sort=False)
Dieses Argument gilt auch für DataFrame.append () gültig.
In [17]: result = df1.append(df4, ignore_index=True, sort=False)

Kombinieren von Daten mit unterschiedlicher Anzahl von Dimensionen
Sie können auch ein "Series" -Objekt und ein "DataFrame" -Objekt kombinieren. Series wird in DataFrame konvertiert, wobei der Name ( name) der Spaltenname ist.
In [18]: s1 = pd.Series(['X0', 'X1', 'X2', 'X3'], name='X')
In [19]: result = pd.concat([df1, s1], axis=1)
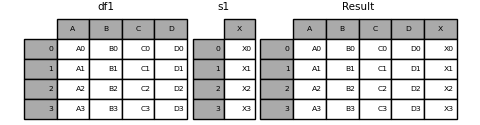
: ballot_box_with_check: ** Hinweis ** Da wir "Series" mit "DataFrame" kombiniert haben, "DataFrame.assign ()" Ich konnte das gleiche Ergebnis wie # pandas.DataFrame.assign) erzielen. Verwenden Sie "concat", um eine beliebige Anzahl von Pandas-Objekten ("DataFrame" oder "Series") zu verketten.
Wenn eine unbenannte "Serie" übergeben wird, wird dem Spaltennamen eine Seriennummer hinzugefügt.
In [20]: s2 = pd.Series(['_0', '_1', '_2', '_3'])
In [21]: result = pd.concat([df1, s2, s2, s2], axis=1)
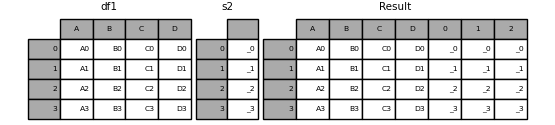
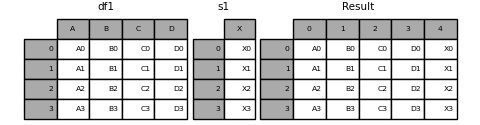
Wenn Sie "ignore_index = True" übergeben, werden alle Namensreferenzen entfernt.
In [22]: result = pd.concat([df1, s1], axis=1, ignore_index=True)
Weiterer Beitritt mit Gruppenschlüssel
Das Argument "keys" wird häufig verwendet, um neue Spaltennamen zu überschreiben, wenn ein neuer "DataFrame" aus einer vorhandenen "Serie" erstellt wird. Das Standardverhalten ist, dass wenn der ursprüngliche "Serie" einen Namen hat, der resultierende "Datenrahmen" diesen erbt.
In [23]: s3 = pd.Series([0, 1, 2, 3], name='foo')
In [24]: s4 = pd.Series([0, 1, 2, 3])
In [25]: s5 = pd.Series([0, 1, 4, 5])
In [26]: pd.concat([s3, s4, s5], axis=1)
Out[26]:
foo 0 1
0 0 0 0
1 1 1 1
2 2 2 4
3 3 3 5
Sie können einen vorhandenen Spaltennamen mit dem Argument keys durch einen neuen überschreiben.
In [27]: pd.concat([s3, s4, s5], axis=1, keys=['red', 'blue', 'yellow'])
Out[27]:
red blue yellow
0 0 0 0
1 1 1 1
2 2 2 4
3 3 3 5
Betrachten Sie eine Variation des ersten Beispiels.
In [28]: result = pd.concat(frames, keys=['x', 'y', 'z'])

Sie können das Wörterbuch auch an "concat" übergeben. Zu diesem Zeitpunkt wird der Wörterbuchschlüssel für das Argument "keys" verwendet (sofern kein anderer Schlüssel angegeben ist).
In [29]: pieces = {'x': df1, 'y': df2, 'z': df3}
In [30]: result = pd.concat(pieces)
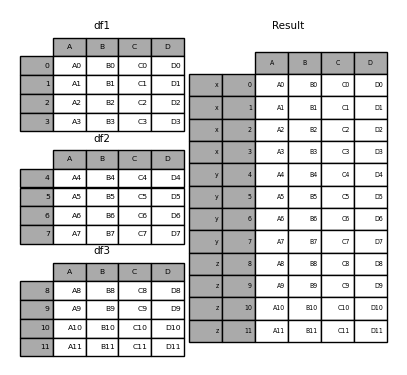
In [31]: result = pd.concat(pieces, keys=['z', 'y'])
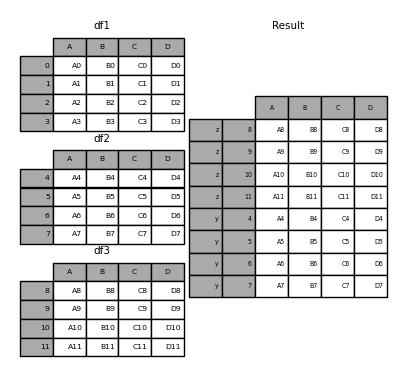
Der erstellte MultiIndex hat eine Ebene, die aus dem übergebenen Schlüssel und dem Index des DataFrame-Teils besteht.
In [32]: result.index.levels
Out[32]: FrozenList([['z', 'y'], [4, 5, 6, 7, 8, 9, 10, 11]])
Wenn Sie andere Ebenen angeben möchten (und in einigen Fällen), können Sie diese mit dem Argument "Ebenen" angeben.
In [33]: result = pd.concat(pieces, keys=['x', 'y', 'z'],
....: levels=[['z', 'y', 'x', 'w']],
....: names=['group_key'])
....:
In [34]: result.index.levels
Out[34]: FrozenList([['z', 'y', 'x', 'w'], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]])
Dies ist ziemlich esoterisch, wird jedoch für Implementierungen wie GroupBy benötigt, bei denen die Reihenfolge der kategorialen Variablen sinnvoll ist.
Zeile für DataFrame hinzufügen (anhängen)
Es ist nicht sehr effizient (weil es immer ein neues Objekt erstellt), aber Sie können dem "DataFrame" eine Zeile hinzufügen, indem Sie die "Serie" oder das Wörterbuch an das "Anhängen" übergeben. Wie eingangs erwähnt, gibt dies einen neuen "DataFrame" zurück.
In [35]: s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D'])
In [36]: result = df1.append(s2, ignore_index=True)
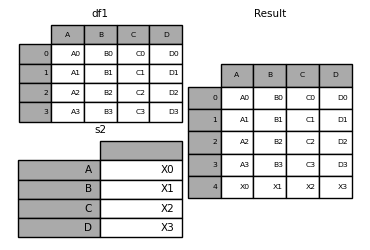
Wenn Sie möchten, dass diese Methode den ursprünglichen Index von "DataFrame" verwirft, verwenden Sie "ignore_index". Wenn Sie die Indizes beibehalten möchten, müssen Sie einen ordnungsgemäß indizierten "DataFrame" erstellen und diese Objekte anhängen oder verketten.
Sie können auch ein Wörterbuch oder eine Liste von Serien übergeben.
In [37]: dicts = [{'A': 1, 'B': 2, 'C': 3, 'X': 4},
....: {'A': 5, 'B': 6, 'C': 7, 'Y': 8}]
....:
In [38]: result = df1.append(dicts, ignore_index=True, sort=False)

Datenbankstil DataFrame oder Named Series Join / Merge
pandas verfügt über eine voll funktionsfähige ** leistungsstarke ** In-Memory-Join-Operation, die relationalen Datenbanken wie SQL sehr ähnlich ist. Diese Methoden sind deutlich besser als andere Open-Source-Implementierungen (wie Rs base :: merge.data.frame) (und in einigen Fällen sogar um eine Größenordnung besser). Der Grund dafür ist ein sorgfältiges Algorithmus-Design und das interne Layout der DataFrame-Daten.
Weitere Informationen finden Sie unter Kochbuch.
Für Benutzer, die mit SQL vertraut sind, Pandas noch nicht kennen, Mit SQL vergleichen ) Könnte nützlich sein.
pandas bietet eine einzige Funktion "merge ()" als Einstiegspunkt für alle Standard-Datenbankverbindungsoperationen zwischen "DataFrame" - oder "Series" -Objekten.
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
--left: DataFrame oder benanntes Serienobjekt.
--right: Ein anderer DataFrame oder ein benanntes Serienobjekt.
--on: Der Name der zu verbindenden Spalten- oder Zeilenebene. Muss sowohl im linken als auch im rechten DataFrame- oder Serienobjekt vorhanden sein. Wenn Sie dies nicht angeben und left_index und right_index`` False sind, wird davon ausgegangen, dass der gemeinsame Teil der DataFrame- oder Series-Spalten der Join-Schlüssel ist.
--left_on: Linke DataFrame- oder Serienspalten- oder Zeilenebene zur Verwendung als Schlüssel. Sie können entweder Namen auf Spalten- oder Zeilenebene oder ein Array mit einer Länge erhalten, die der Länge (Länge) Ihres DataFrame oder Ihrer Serie entspricht.
--right_on: Linke DataFrame- oder Serienspalten- oder Zeilenebene zur Verwendung als Schlüssel. Sie können entweder Namen auf Spalten- oder Zeilenebene oder ein Array mit einer Länge erhalten, die der Länge (Länge) Ihres DataFrame oder Ihrer Serie entspricht.
--left_index: Verwenden Sie für True den linken DataFrame- oder Serienindex (Zeilenbezeichnung) als Verknüpfungsschlüssel. Bei DataFrames oder Serien mit MultiIndex (Hierarchie) muss die Anzahl der Ebenen mit der Anzahl der Verknüpfungsschlüssel aus dem DataFrame oder der Serie auf der rechten Seite übereinstimmen.
--right_index: Dieselbe Spezifikation wie left_index für den DataFrame oder die Serie auf der rechten Seite.
- "wie": Einer von "links", "rechts", "außen", "innen". Der Standardwert ist "Gewinner". Details zu jeder Methode sind unten angegeben.
--
sort: Sortiert den resultierenden DataFrame mit dem Join-Schlüssel in einen Wörterbuchausdruck. Der Standardwert ist "True". Wenn Sie ihn auf "False" setzen, wird die Leistung häufig erheblich verbessert. --suffixes: Ein Tupel von Präfixen, die auf doppelte Spalten angewendet werden sollen. Der Standardwert ist "(" _x "," _y ")". --copy: Kopiert immer Daten aus dem übergebenen DataFrame- oder Named Series-Objekt, auch wenn Sie nicht neu indizieren müssen (wenn der Standardwert "True" ist). In vielen Fällen ist das Kopieren unvermeidbar, kann jedoch die Speichernutzung verbessern. Kopieren kann selten vermieden werden, aber diese Option wird weiterhin angeboten. --indicator: Fügt dem ausgegebenen DataFrame eine Spalte mit dem Namen_mergehinzu, die Informationen zur Quelle jeder Zeile enthält. "_merge" ist ein kategorialer Typ, "left_only", wenn der Zusammenführungsschlüssel nur im "linken" Datenrahmen oder in der Serie vorhanden ist, "right_only", wenn er nur im "rechten" DataFrame oder in der rechten Serie vorhanden ist, wenn er in beiden vorhanden ist Nimmt den Wert von "beides" an. --validate: Zeichenkette, Standard ist None. Wenn angegeben, überprüfen Sie, ob die Zusammenführung vom angegebenen Typ ist. - "One_to_one" oder "1: 1": Überprüft, ob der Zusammenführungsschlüssel sowohl für den linken als auch für den rechten Datensatz eindeutig ist.
- "One_to_many" oder "1: m": Überprüft, ob der Zusammenführungsschlüssel im linken Datensatz eindeutig ist.
- "Many_to_one" oder "m: 1": Überprüfen Sie, ob der Zusammenführungsschlüssel im richtigen Datensatz eindeutig ist.
- "Many_to_many" oder "m: m": Erhält ein Argument, wird aber nicht bestätigt.
_ Ab Version 0.21.0 _
: ballot_box_with_check: ** Hinweis ** In Version 0.23.0 wurde die Unterstützung für die Angabe von Zeilenebenen mit den Argumenten "on", "left_on" und "right_on" hinzugefügt. Die Unterstützung für das Zusammenführen benannter "Serien" -Objekte wurde in Version 0.24.0 hinzugefügt.
Der Rückgabetyp ist der gleiche wie "left". Wenn left ein DataFrame oder eine benannte Series ist und right eine Unterklasse von DataFrame ist, bleibt der Rückgabetyp weiterhin DataFrame.
merge ist eine Funktion im Pandas-Namespace, aber Sie können auch die DataFrame-Instanzmethodemerge ()verwenden. Der aufrufende "DataFrame" wird implizit als das Objekt links vom Join betrachtet.
Die zugehörige Methode 'join ()' verwendet intern 'merge' für Index-on-Index- (Standard) und Column-on-Index-Joins. Wenn Sie nur über den Index beitreten möchten, können Sie "DataFrame.join" verwenden, um die Eingabe zu vereinfachen.
Überblick über die Zusammenführungsmethode (relationale Algebra)
Erfahrene Benutzer relationaler Datenbanken wie SQL sind mit der Terminologie vertraut, mit der Verknüpfungsoperationen zwischen zwei tabellenähnlichen SQL-Strukturen ("DataFrame" -Objekte) beschrieben werden. Es sind einige Fälle zu berücksichtigen, deren Verständnis sehr wichtig ist.
- ** Eins-zu-Eins ** Verbinden: Zum Beispiel, wenn zwei
DataFrame-Objekte gemäß einem Index (einschließlich eines eindeutigen Werts) verbunden werden. - ** Many-to-One ** Join: Zum Beispiel, wenn ein Index (eindeutig) mit einer oder mehreren Spalten verschiedener DataFrames verknüpft wird.
- ** Viele-zu-Viele ** Verbinden: Beim Verbinden von Spalten mit Spalten.
Beim Verbinden von Spalten (wie ** Viele-zu-Viele ** -Verbindungen) werden alle Indizes des übergebenen
DataFrame-Objekts ** verworfen **.
** viele-zu-viele ** Es lohnt sich, das Ergebnis des Joins zu verstehen. Wenn in SQL und in der relationalen Standardalgebra eine Schlüsselkombination in beiden Tabellen mehrmals vorkommt, enthält die resultierende Tabelle ein ** kartesisches Produkt ** verwandter Daten. Das Folgende ist ein sehr einfaches Beispiel mit einer eindeutigen Tastenkombination.
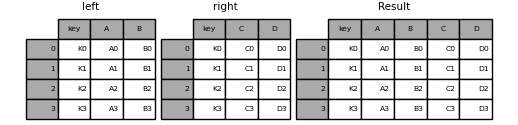
In [39]: left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [40]: right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [41]: result = pd.merge(left, right, on='key')
Das folgende Beispiel ist komplexer mit mehreren Verknüpfungsschlüsseln. Standardmäßig ist "how =" inner "", sodass nur die Tasten angezeigt werden, die links und rechts gemeinsam sind (Schnittpunkt).
In [42]: left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [43]: right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
....: 'key2': ['K0', 'K0', 'K0', 'K0'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [44]: result = pd.merge(left, right, on=['key1', 'key2'])

Das Argument "wie" gibt an, wie die in der Tabelle enthaltenen Schlüssel ermittelt werden sollen, die sich aus "Zusammenführen" ergeben. Wenn die Tastenkombination ** weder in der linken noch in der rechten Tabelle vorhanden ist **, lautet der Wert der verknüpften Tabelle "NA". Unten finden Sie eine Zusammenfassung der Option "wie" und des entsprechenden SQL-Namens.
| Zusammenführungsmethode | Name von SQL JOIN | Bewegung |
|---|---|---|
left |
LEFT OUTER JOIN |
Verwenden Sie nur die linke Taste |
right |
RIGHT OUTER JOIN |
Verwenden Sie nur den richtigen Schlüssel |
outer |
FULL OUTER JOIN |
Verwenden Sie die Summe beider Schlüssel |
inner |
INNER JOIN |
Verwenden Sie den gemeinsamen Teil beider Tasten |
In [45]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])
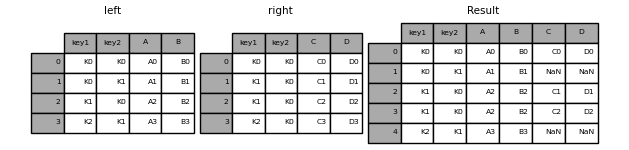
In [46]: result = pd.merge(left, right, how='right', on=['key1', 'key2'])

In [47]: result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
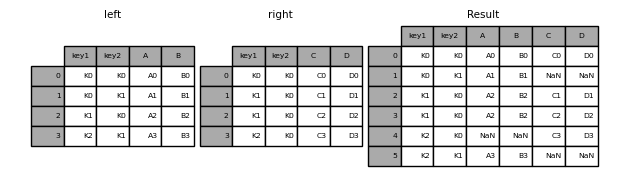
In [48]: result = pd.merge(left, right, how='inner', on=['key1', 'key2'])

Das folgende Beispiel bezieht sich auf einen DataFrame mit doppelten Verknüpfungsschlüsseln.
In [49]: left = pd.DataFrame({'A': [1, 2], 'B': [2, 2]})
In [50]: right = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 2, 2]})
In [51]: result = pd.merge(left, right, on='B', how='outer')
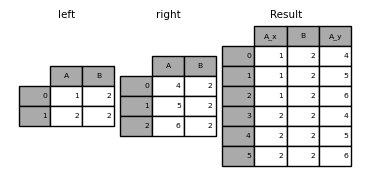
: Warnung: ** Warnung ** Beim Verbinden / Zusammenführen mit doppelten Schlüsseln wird möglicherweise ein Frame mit Zeilendimensionsmultiplikation zurückgegeben, was zu einem Speicherüberlauf führen kann. Benutzer müssen die Schlüsselvervielfältigung verwalten, bevor sie einem großen DataFrame beitreten können.
Suchen Sie nach doppelten Schlüsseln
_ Ab Version 0.21.0 _
Der Benutzer kann das Argument "validate" verwenden, um automatisch nach unerwarteten Duplikaten im Zusammenführungsschlüssel zu suchen. Die Eindeutigkeit der Schlüssel wird vor dem Verknüpfungsvorgang überprüft, um einen Speicherüberlauf zu verhindern. Das Überprüfen der Eindeutigkeit des Schlüssels ist auch ein guter Weg, um sicherzustellen, dass die Benutzerdatenstruktur den Erwartungen entspricht.
Im folgenden Beispiel wird der "B" -Wert des "DataFrame" auf der rechten Seite dupliziert. Dies ist keine Eins-zu-Eins-Zusammenführung, die im Argument "validate" angegeben ist. Daher wird eine Ausnahme ausgelöst.
In [52]: left = pd.DataFrame({'A' : [1,2], 'B' : [1, 2]})
In [53]: right = pd.DataFrame({'A' : [4,5,6], 'B': [2, 2, 2]})
In [53]: result = pd.merge(left, right, on='B', how='outer', validate="one_to_one")
...
MergeError: Merge keys are not unique in right dataset; not a one-to-one merge
Wenn Sie bereits wissen, dass der "DataFrame" auf der rechten Seite Duplikate enthält und Sie sicherstellen möchten, dass der "DataFrame" auf der linken Seite keine Duplikate enthält, können Sie stattdessen das Argument "validate =" one_to_many "verwenden. Dies löst keine Ausnahme aus.
In [54]: pd.merge(left, right, on='B', how='outer', validate="one_to_many")
Out[54]:
A_x B A_y
0 1 1 NaN
1 2 2 4.0
2 2 2 5.0
3 2 2 6.0
Zusammenführungsindikator
merge () verwendet ein Indikator-Argument. Bei "True" wird dem Ausgabeobjekt eine kategoriale Spalte vom Typ "_merge" mit einem der folgenden Werte hinzugefügt:
| Beobachtungsursprung | _mergeDer Wert der |
|---|---|
Der Join-Schlüssel lautetleftNur im Rahmen vorhanden |
left_only |
Der Join-Schlüssel lautetrightNur im Rahmen vorhanden |
right_only |
| Der Join-Schlüssel ist in beiden Frames vorhanden | both |
In [55]: df1 = pd.DataFrame({'col1': [0, 1], 'col_left': ['a', 'b']})
In [56]: df2 = pd.DataFrame({'col1': [1, 2, 2], 'col_right': [2, 2, 2]})
In [57]: pd.merge(df1, df2, on='col1', how='outer', indicator=True)
Out[57]:
col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
Das Argument "Indikator" kann auch eine Zeichenfolge akzeptieren. In diesem Fall verwendet die Indikatorfunktion den Wert der übergebenen Zeichenfolge als Namen der Indikatorspalte.
In [58]: pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column')
Out[58]:
col1 col_left col_right indicator_column
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
Datentyp der Zusammenführung
Zusammenführen enthält den Datentyp des Zusammenführungsschlüssels.
In [59]: left = pd.DataFrame({'key': [1], 'v1': [10]})
In [60]: left
Out[60]:
key v1
0 1 10
In [61]: right = pd.DataFrame({'key': [1, 2], 'v1': [20, 30]})
In [62]: right
Out[62]:
key v1
0 1 20
1 2 30
Sie können die Join-Taste gedrückt halten.
In [63]: pd.merge(left, right, how='outer')
Out[63]:
key v1
0 1 10
1 1 20
2 2 30
In [64]: pd.merge(left, right, how='outer').dtypes
Out[64]:
key int64
v1 int64
dtype: object
Wenn Werte fehlen, wird der resultierende Datentyp natürlich gesendet.
In [65]: pd.merge(left, right, how='outer', on='key')
Out[65]:
key v1_x v1_y
0 1 10.0 20
1 2 NaN 30
In [66]: pd.merge(left, right, how='outer', on='key').dtypes
Out[66]:
key int64
v1_x float64
v1_y int64
dtype: object
Beim Zusammenführen wird der ursprüngliche Datentyp "Kategorie" beibehalten. Siehe auch den Abschnitt über Kategorien (https://dev.pandas.io/docs/user_guide/categorical.html#categorical-merge).
Linker Rahmen.
In [67]: from pandas.api.types import CategoricalDtype
In [68]: X = pd.Series(np.random.choice(['foo', 'bar'], size=(10,)))
In [69]: X = X.astype(CategoricalDtype(categories=['foo', 'bar']))
In [70]: left = pd.DataFrame({'X': X,
....: 'Y': np.random.choice(['one', 'two', 'three'],
....: size=(10,))})
....:
In [71]: left
Out[71]:
X Y
0 bar one
1 foo one
2 foo three
3 bar three
4 foo one
5 bar one
6 bar three
7 bar three
8 bar three
9 foo three
In [72]: left.dtypes
Out[72]:
X category
Y object
dtype: object
Rechter Rahmen.
In [73]: right = pd.DataFrame({'X': pd.Series(['foo', 'bar'],
....: dtype=CategoricalDtype(['foo', 'bar'])),
....: 'Z': [1, 2]})
....:
In [74]: right
Out[74]:
X Z
0 foo 1
1 bar 2
In [75]: right.dtypes
Out[75]:
X category
Z int64
dtype: object
Das kombinierte Ergebnis.
In [76]: result = pd.merge(left, right, how='outer')
In [77]: result
Out[77]:
X Y Z
0 bar one 2
1 bar three 2
2 bar one 2
3 bar three 2
4 bar three 2
5 bar three 2
6 foo one 1
7 foo three 1
8 foo one 1
9 foo three 1
In [78]: result.dtypes
Out[78]:
X category
Y object
Z int64
dtype: object
: ballot_box_with_check: ** Hinweis ** Kategorietypen müssen dieselben Kategorie- und Auftragsattribute haben und * genau * identisch sein. Andernfalls wird das Ergebnis mit dem Datentyp des Kategorieelements überschrieben.
: ballot_box_with_check: ** Hinweis ** Das Zusammenfügen derselben "Kategorie" -Datentypen kann im Vergleich zum Zusammenführen von "Objekt" -Datentypen sehr leistungsfähig sein.
Indexbasierter Join
DataFrame.join () kann unterschiedliche Indizes haben Dies ist eine bequeme Methode zum Kombinieren von zwei möglichen "DataFrame" -Spalten zu einem "DataFrame". Das folgende Beispiel ist ein sehr einfaches Beispiel.
In [79]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
....: 'B': ['B0', 'B1', 'B2']},
....: index=['K0', 'K1', 'K2'])
....:
In [80]: right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
....: 'D': ['D0', 'D2', 'D3']},
....: index=['K0', 'K2', 'K3'])
....:
In [81]: result = left.join(right)
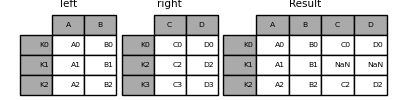
In [82]: result = left.join(right, how='outer')
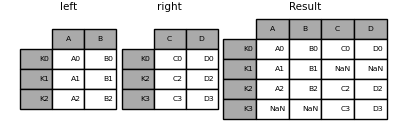
Ähnlich wie oben, mit how = 'inner',
In [83]: result = left.join(right, how='inner')
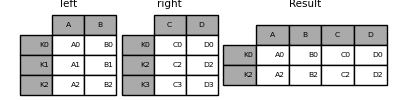
Die Ausrichtung der Daten basiert hier auf dem Index (Zeilenbeschriftung). Um dasselbe mit "Zusammenführen" zu tun, übergeben Sie ein zusätzliches Argument, das Sie auffordert, den Index zu verwenden.
In [84]: result = pd.merge(left, right, left_index=True, right_index=True, how='outer')

In [85]: result = pd.merge(left, right, left_index=True, right_index=True, how='inner')

Verbinden Sie die Schlüsselspalte mit dem Index
join () ist ein optionales on-Argument , Erhält eine Spalte oder mehrere Spaltennamen. Der übergebene "DataFrame" wird entlang dieser Spalte im "DataFrame" verbunden. Die folgenden zwei Funktionsaufrufe sind genau gleichwertig.
left.join(right, on=key_or_keys)
pd.merge(left, right, left_on=key_or_keys, right_index=True,
how='left', sort=False)
Natürlich können Sie ein bequemeres Format wählen. Für viele-zu-eins-Verknüpfungen (wenn einer der "DataFrame" bereits durch den Verknüpfungsschlüssel indiziert ist) ist es möglicherweise bequemer, "Verknüpfung" zu verwenden. Hier ist ein einfaches Beispiel.
In [86]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key': ['K0', 'K1', 'K0', 'K1']})
....:
In [87]: right = pd.DataFrame({'C': ['C0', 'C1'],
....: 'D': ['D0', 'D1']},
....: index=['K0', 'K1'])
....:
In [88]: result = left.join(right, on='key')
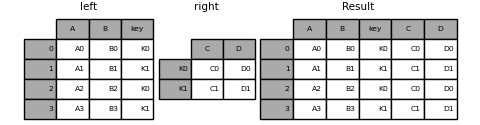
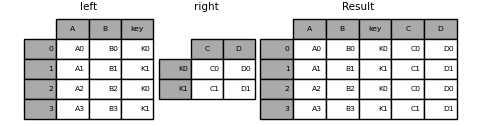
In [89]: result = pd.merge(left, right, left_on='key', right_index=True,
....: how='left', sort=False);
....:
Um mit mehreren Schlüsseln zu verbinden, muss der übergebene DataFrame "MultiIndex" haben.
In [90]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1']})
....:
In [91]: index = pd.MultiIndex.from_tuples([('K0', 'K0'), ('K1', 'K0'),
....: ('K2', 'K0'), ('K2', 'K1')])
....:
In [92]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']},
....: index=index)
....:
Dies kann kombiniert werden, indem zwei Schlüsselspaltennamen übergeben werden.
In [93]: result = left.join(right, on=['key1', 'key2'])
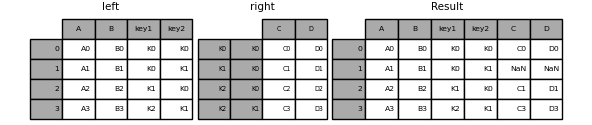
Die Standardeinstellung für "DataFrame.join" ist die Ausführung eines Links-Joins (im Wesentlichen eine "VLOOKUP" -Operation für Excel-Benutzer), bei der nur die im aufrufenden DataFrame gefundenen Schlüssel verwendet werden. Andere Verknüpfungstypen, wie z. B. innere Verknüpfungen, sind ebenso einfach durchzuführen.
In [94]: result = left.join(right, on=['key1', 'key2'], how='inner')
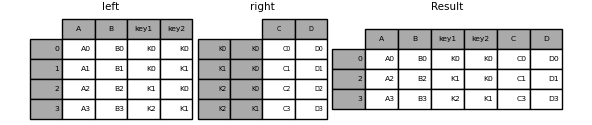
Wie oben werden dadurch die nicht übereinstimmenden Zeilen entfernt.
Verknüpfen eines einzelnen Index mit mehreren Indizes
Sie können einen einzelnen Index "DataFrame" mit einem MultiIndex zu einer Ebene von "DataFrame" kombinieren. Im Ebenennamen eines Frames mit MultiIndex stimmt die Ebene mit dem Indexnamen eines einzelnen Indexrahmens überein.
In [95]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
....: 'B': ['B0', 'B1', 'B2']},
....: index=pd.Index(['K0', 'K1', 'K2'], name='key'))
....:
In [96]: index = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
....: ('K2', 'Y2'), ('K2', 'Y3')],
....: names=['key', 'Y'])
....:
In [97]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']},
....: index=index)
....:
In [98]: result = left.join(right, how='inner')
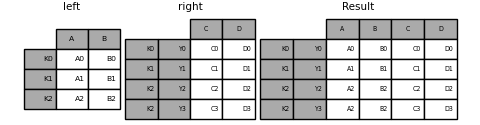
Das folgende Beispiel ist äquivalent, aber weniger redundant, speichereffizienter und schneller.
In [99]: result = pd.merge(left.reset_index(), right.reset_index(),
....: on=['key'], how='inner').set_index(['key','Y'])
....:

Kombinieren Sie zwei Multi-Indizes
Diese Methode kann nur verwendet werden, wenn der Index für das rechte Argument vollständig im Join verwendet wird und eine Teilmenge des Index für das linke Argument ist, wie im folgenden Beispiel.
In [100]: leftindex = pd.MultiIndex.from_product([list('abc'), list('xy'), [1, 2]],
.....: names=['abc', 'xy', 'num'])
.....:
In [101]: left = pd.DataFrame({'v1': range(12)}, index=leftindex)
In [102]: left
Out[102]:
v1
abc xy num
a x 1 0
2 1
y 1 2
2 3
b x 1 4
2 5
y 1 6
2 7
c x 1 8
2 9
y 1 10
2 11
In [103]: rightindex = pd.MultiIndex.from_product([list('abc'), list('xy')],
.....: names=['abc', 'xy'])
.....:
In [104]: right = pd.DataFrame({'v2': [100 * i for i in range(1, 7)]}, index=rightindex)
In [105]: right
Out[105]:
v2
abc xy
a x 100
y 200
b x 300
y 400
c x 500
y 600
In [106]: left.join(right, on=['abc', 'xy'], how='inner')
Out[106]:
v1 v2
abc xy num
a x 1 0 100
2 1 100
y 1 2 200
2 3 200
b x 1 4 300
2 5 300
y 1 6 400
2 7 400
c x 1 8 500
2 9 500
y 1 10 600
2 11 600
Wenn diese Bedingung nicht erfüllt ist, können Sie den folgenden Code verwenden, um einen Join von zwei Multi-Indizes durchzuführen.
In [107]: leftindex = pd.MultiIndex.from_tuples([('K0', 'X0'), ('K0', 'X1'),
.....: ('K1', 'X2')],
.....: names=['key', 'X'])
.....:
In [108]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
.....: 'B': ['B0', 'B1', 'B2']},
.....: index=leftindex)
.....:
In [109]: rightindex = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
.....: ('K2', 'Y2'), ('K2', 'Y3')],
.....: names=['key', 'Y'])
.....:
In [110]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3']},
.....: index=rightindex)
.....:
In [111]: result = pd.merge(left.reset_index(), right.reset_index(),
.....: on=['key'], how='inner').set_index(['key', 'X', 'Y'])
.....:
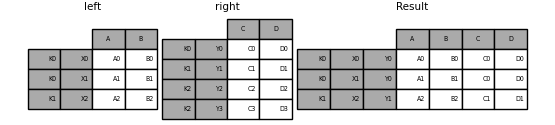
Mit einer Kombination aus Spalten- und Indexebene zusammenführen
_ Ab Version 0.23 _
Die Zeichenfolge, die als on ・ left_on ・ right_on -Parameter übergeben wird, kann sich entweder auf den Spaltennamen oder den Namen der Indexebene beziehen. Auf diese Weise können Sie "DataFrame" -Instanzen mit einer Kombination aus Indexebenen und Spalten zusammenführen, ohne den Index zurückzusetzen.
In [112]: left_index = pd.Index(['K0', 'K0', 'K1', 'K2'], name='key1')
In [113]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
.....: 'B': ['B0', 'B1', 'B2', 'B3'],
.....: 'key2': ['K0', 'K1', 'K0', 'K1']},
.....: index=left_index)
.....:
In [114]: right_index = pd.Index(['K0', 'K1', 'K2', 'K2'], name='key1')
In [115]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3'],
.....: 'key2': ['K0', 'K0', 'K0', 'K1']},
.....: index=right_index)
.....:
In [116]: result = left.merge(right, on=['key1', 'key2'])
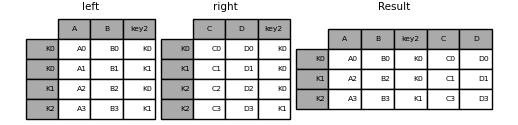
: ballot_box_with_check: ** Hinweis ** Wenn Sie einen DataFrame mit einer Zeichenfolge zusammenführen, die der Indexebene beider Frames entspricht, wird die Indexebene als Indexebene des resultierenden DataFrame beibehalten.
: ballot_box_with_check: ** Hinweis ** Wenn Sie einen DataFrame nur mit einigen Ebenen von * MultiIndex * zusammenführen, werden die zusätzlichen Ebenen aus den zusammengeführten Ergebnissen entfernt. Um diese Ebenen beizubehalten, verwenden Sie "reset_index" in ihrem Ebenennamen, um sie in die Spalte zu verschieben, bevor Sie die Zusammenführung durchführen.
: ballot_box_with_check: ** Hinweis ** Wenn die Zeichenfolge sowohl mit dem Spaltennamen als auch mit dem Namen der Indexebene übereinstimmt, wird eine Warnung ausgelöst und die Spalte hat Vorrang. Dies kann in zukünftigen Versionen zu mehrdeutigen Fehlern führen.
Spalten mit doppelten Werten
Das Argument "Suffixe" der Zusammenführung benötigt ein Tupel von Zeichenfolgen, um die doppelten Spaltennamen in der Eingabe "DataFrame" zu ergänzen und die resultierende Spalte zu verdeutlichen.
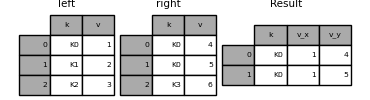
In [117]: left = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'v': [1, 2, 3]})
In [118]: right = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'v': [4, 5, 6]})
In [119]: result = pd.merge(left, right, on='k')
In [120]: result = pd.merge(left, right, on='k', suffixes=['_l', '_r'])
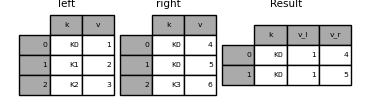
Funktioniert genauso für DataFrame.join () Es gibt "lsuffix" - und "rsuffix" -Argumente.
In [121]: left = left.set_index('k')
In [122]: right = right.set_index('k')
In [123]: result = left.join(right, lsuffix='_l', rsuffix='_r')

Verbinden mehrerer DataFrames
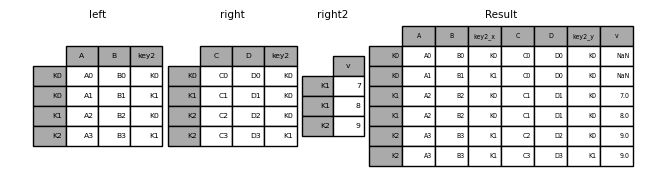
Fügen Sie [join ()] eine Liste oder ein Taple von DataFrame hinzu (https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.join.html#pandas.DataFrame.join) Sie können sie auch an den Index übergeben und mit ihnen verknüpfen.
In [124]: right2 = pd.DataFrame({'v': [7, 8, 9]}, index=['K1', 'K1', 'K2'])
In [125]: result = left.join([right, right2])
Kombinieren Sie Werte in einer Series- oder DataFrame-Spalte
Eine andere ziemlich häufige Situation besteht darin, zwei ähnlich indizierte (oder ähnlich indizierte) "Series" - oder "DataFrame" -Objekte zu haben, die den Wert eines Objekts mit dem Index des anderen übereinstimmen. Sie möchten den Wert "patchen". Ein Beispiel ist unten gezeigt.
In [126]: df1 = pd.DataFrame([[np.nan, 3., 5.], [-4.6, np.nan, np.nan],
.....: [np.nan, 7., np.nan]])
.....:
In [127]: df2 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5., 1.6, 4]],
.....: index=[1, 2])
.....:
Verwenden Sie dazu die Methode combin_first (). Ich werde.
In [128]: result = df1.combine_first(df2)
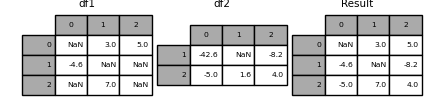
Beachten Sie, dass diese Methode den Wert nur dann vom rechten "DataFrame" erhält, wenn der linke "DataFrame" keinen Wert hat. Die zugehörige Methode update () ist keine NA. Ändern Sie den Wert.
In [129]: df1.update(df2)

Join für Zeitreihendaten
Bestellte Daten verbinden
Die Funktion merge_ordered () ermöglicht Zeitreihen und andere Bestellungen Sie können die Daten kombinieren. Es enthält ein optionales Argument "fill_method" zum Füllen und Interpolieren fehlender Daten.
In [130]: left = pd.DataFrame({'k': ['K0', 'K1', 'K1', 'K2'],
.....: 'lv': [1, 2, 3, 4],
.....: 's': ['a', 'b', 'c', 'd']})
.....:
In [131]: right = pd.DataFrame({'k': ['K1', 'K2', 'K4'],
.....: 'rv': [1, 2, 3]})
.....:
In [132]: pd.merge_ordered(left, right, fill_method='ffill', left_by='s')
Out[132]:
k lv s rv
0 K0 1.0 a NaN
1 K1 1.0 a 1.0
2 K2 1.0 a 2.0
3 K4 1.0 a 3.0
4 K1 2.0 b 1.0
5 K2 2.0 b 2.0
6 K4 2.0 b 3.0
7 K1 3.0 c 1.0
8 K2 3.0 c 2.0
9 K4 3.0 c 3.0
10 K1 NaN d 1.0
11 K2 4.0 d 2.0
12 K4 4.0 d 3.0
ab dem Zusammenführen
merge_asof () ähnelt einem geordneten linken Join , Übereinstimmung mit dem nächstgelegenen Schlüssel anstelle des Schlüssels mit der gleichen Nummer. Wählen Sie für jede Zeile des "linken DataFrame" die letzte Zeile des "rechten DataFrame" aus, in der die "Ein" -Taste kleiner als die linke Taste ist. Beide DataFrames müssen nach Schlüssel sortiert sein.
Optional kann asof merge gruppenbasierte Zusammenführungen durchführen. Dies ist eine ungefähre Übereinstimmung für die Taste "Ein" sowie eine genaue Übereinstimmung für die Taste "Nach".
Wenn Sie beispielsweise "Trades" und "Quotes" haben, führen Sie diese zusammen.
In [133]: trades = pd.DataFrame({
.....: 'time': pd.to_datetime(['20160525 13:30:00.023',
.....: '20160525 13:30:00.038',
.....: '20160525 13:30:00.048',
.....: '20160525 13:30:00.048',
.....: '20160525 13:30:00.048']),
.....: 'ticker': ['MSFT', 'MSFT',
.....: 'GOOG', 'GOOG', 'AAPL'],
.....: 'price': [51.95, 51.95,
.....: 720.77, 720.92, 98.00],
.....: 'quantity': [75, 155,
.....: 100, 100, 100]},
.....: columns=['time', 'ticker', 'price', 'quantity'])
.....:
In [134]: quotes = pd.DataFrame({
.....: 'time': pd.to_datetime(['20160525 13:30:00.023',
.....: '20160525 13:30:00.023',
.....: '20160525 13:30:00.030',
.....: '20160525 13:30:00.041',
.....: '20160525 13:30:00.048',
.....: '20160525 13:30:00.049',
.....: '20160525 13:30:00.072',
.....: '20160525 13:30:00.075']),
.....: 'ticker': ['GOOG', 'MSFT', 'MSFT',
.....: 'MSFT', 'GOOG', 'AAPL', 'GOOG',
.....: 'MSFT'],
.....: 'bid': [720.50, 51.95, 51.97, 51.99,
.....: 720.50, 97.99, 720.50, 52.01],
.....: 'ask': [720.93, 51.96, 51.98, 52.00,
.....: 720.93, 98.01, 720.88, 52.03]},
.....: columns=['time', 'ticker', 'bid', 'ask'])
.....:
In [135]: trades
Out[135]:
time ticker price quantity
0 2016-05-25 13:30:00.023 MSFT 51.95 75
1 2016-05-25 13:30:00.038 MSFT 51.95 155
2 2016-05-25 13:30:00.048 GOOG 720.77 100
3 2016-05-25 13:30:00.048 GOOG 720.92 100
4 2016-05-25 13:30:00.048 AAPL 98.00 100
In [136]: quotes
Out[136]:
time ticker bid ask
0 2016-05-25 13:30:00.023 GOOG 720.50 720.93
1 2016-05-25 13:30:00.023 MSFT 51.95 51.96
2 2016-05-25 13:30:00.030 MSFT 51.97 51.98
3 2016-05-25 13:30:00.041 MSFT 51.99 52.00
4 2016-05-25 13:30:00.048 GOOG 720.50 720.93
5 2016-05-25 13:30:00.049 AAPL 97.99 98.01
6 2016-05-25 13:30:00.072 GOOG 720.50 720.88
7 2016-05-25 13:30:00.075 MSFT 52.01 52.03
Wenden Sie standardmäßig Anführungszeichen an.
In [137]: pd.merge_asof(trades, quotes,
.....: on='time',
.....: by='ticker')
.....:
Out[137]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
Halten Sie die Zeit zwischen Quotierungszeit und Handelszeit innerhalb von "2 ms".
In [138]: pd.merge_asof(trades, quotes,
.....: on='time',
.....: by='ticker',
.....: tolerance=pd.Timedelta('2ms'))
.....:
Out[138]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 NaN NaN
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
Halten Sie die Zeit zwischen Quotierungs- und Handelszeiten innerhalb von "10 ms" und schließen Sie genaue pünktliche Übereinstimmungen aus. Schließen Sie genaue Übereinstimmungen (von Anführungszeichen) aus, beachten Sie jedoch, dass frühere Anführungszeichen bis zu diesem Punkt * weitergegeben * werden.
In [139]: pd.merge_asof(trades, quotes,
.....: on='time',
.....: by='ticker',
.....: tolerance=pd.Timedelta('10ms'),
.....: allow_exact_matches=False)
.....:
Out[139]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 NaN NaN
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 NaN NaN
3 2016-05-25 13:30:00.048 GOOG 720.92 100 NaN NaN
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN