[PYTHON] [Renforcer l'apprentissage] DQN avec votre propre bibliothèque
TL;DR J'ai implémenté DQN en utilisant ma propre bibliothèque Replay Buffer cpprb.
Recommandé car il a un haut degré de liberté et d'efficacité (je le souhaite)
1. Contexte et contexte
Apprentissage amélioré tel que Open AI / Baselines et Ray / RLlib Avec un ensemble d'environnements, vous pouvez expérimenter différents algorithmes avec un peu de code.
Par exemple, dans Open AI / Baselines, le README officiel indique qu'il vous suffit d'exécuter la commande suivante pour entraîner Atari's Pong avec DQN.
python -m baselines.run --alg=deepq --env=PongNoFrameskip-v4 --num_timesteps=1e6
D'un autre côté, il est facile de tester des algorithmes existants, mais lorsque les chercheurs et les développeurs de bibliothèques essaient de créer de nouveaux algorithmes propriétaires, je pense que c'est trop gros pour commencer.
Certains de mes amis qui étudient l'apprentissage par renforcement utilisent également des bibliothèques d'apprentissage profond telles que TensorFlow, mais d'autres parties ont été implémentées indépendamment (semble-t-il).
Vers la fin de 2018, un ami a déclaré: "Êtes-vous intéressé par Cython? Le tampon de relecture implémenté en Python est (selon la situation) aussi lent que la partie apprentissage de l'apprentissage profond, et je veux accélérer avec Cython." C'est cpprb que j'ai été invité à implémenter (mémoire).
(L'ami a utilisé cpprb et TensorFlow 2.x pour publier une bibliothèque d'apprentissage améliorée appelée tf2rl, qui est également fortement recommandée!)
2. Caractéristiques
Dans ce contexte, cpprb a commencé à être implémenté, nous le développons donc en mettant l'accent sur un degré élevé de liberté et d'efficacité.
2.1 Haut degré de liberté
Vous pouvez décider librement du nom, de la taille et du type de la variable à enregistrer dans le tampon en les spécifiant au format dict.
Par exemple, dans un cas extrême, vous pouvez enregistrer next_next_obs, previous_act, secondary_reward.
import numpy as np
from cpprb import ReplayBuffer
buffer_size = 1024
#shape et dtype peuvent être spécifiés pour chaque variable. La valeur par défaut est{"shape":1,"dtype": np.float32}
rb = ReplayBuffer(buffer_size,
{"obs": {"shape": (3,3)},
"act": {"shape": 3, "dtype": np.int},
"rew": {},
"done": {},
"next_obs": {"shape": (3,3)},
"next_next_obs": {"shape": (3,3)},
"previous_act": {"shape": 3, "dtype": np.int},
"secondary_reward": {}})
# Key-Spécifiez au format Valeur (si la variable spécifiée à l'initialisation est insuffisante`KeyError`)
rb.add(obs=np.zeros(shape=(3,3)),
act=np.ones(3,dtype=np.int),
rew=0.5,
done=0,
next_obs=np.zeros(shape=(3,3)),
next_next_obs=np.ones(shape=(3,3)),
previous_act=np.ones(3,dtype=np.int),
secondary_reward=0.3)
2.2 Efficacité
C'est assez rapide car l'arborescence de segments, qui est la cause de la lenteur de la rediffusion d'expérience prioritaire, est implémentée en C ++ via Cython.
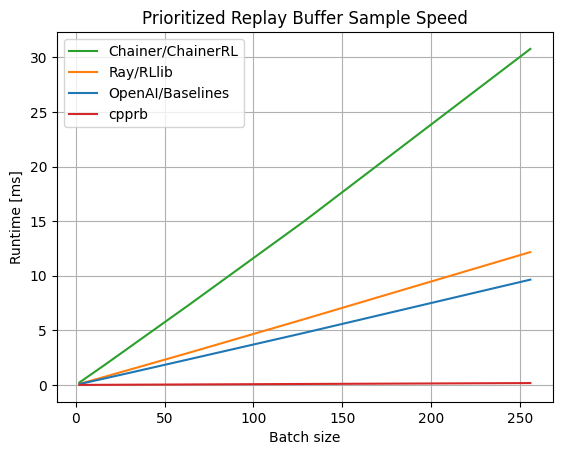
Pour ce qui est de l'indice de référence, il est extrêmement rapide. (Depuis avril 2020. Pour la dernière version, accédez au Site du projet)
Remarque: dans l'ensemble de l'apprentissage de renforcement, non seulement la vitesse de l'arborescence des segments, mais également des mesures telles que la parallélisation réussie de la recherche sont importantes.
3. Installation
(Voir aussi la dernière méthode install car les informations peuvent être obsolètes)
3.1 Installation binaire
Puisqu'il est publié sur PyPI, il peut être installé à l'aide de pip (ou d'outils similaires).
Puisque le binaire au format de roue est distribué pour Windows / Linux, dans de nombreux cas, vous pouvez l'installer avec la commande suivante sans penser à rien.
(Remarque: il est recommandé d'utiliser un environnement virtuel tel que venv ou docker.)
pip install cpprb
Remarque: macOS fait partie de la chaîne d'outils de développement standard clang, mais au lieu du type de tableau de fonctionnalité C ++ 17 std :: shared_ptr Puisque la spécialisation de n'est pas implémentée, elle ne peut pas être compilée et le binaire ne peut pas être distribué.
3.2 Installer à partir de la source
Vous devez construire vous-même à partir du code source. Vous avez besoin des éléments suivants pour créer:
- GCC >= 7.2(?)
Vous devez exécuter la compilation avec g ++ dans les variables d'environnement CC et CXX.
3. Mise en œuvre du DQN
J'ai écrit un DQN qui fonctionne sur Google Colab
Tout d'abord, installez les bibliothèques requises
!apt update > /dev/null 2>&1
!apt install -y xvfb x11-utils python-opengl > /dev/null
!pip install gym cpprb["all"] tensorflow > /dev/null
%load_ext tensorboard
import os
import datetime
import io
import base64
import numpy as np
from google.colab import files, drive
import gym
import tensorflow as tf
from tensorflow.keras.models import Sequential,clone_model
from tensorflow.keras.layers import InputLayer,Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping,TensorBoard
from tensorflow.summary import create_file_writer
from scipy.special import softmax
from tqdm import tqdm_notebook as tqdm
from cpprb import create_buffer, ReplayBuffer,PrioritizedReplayBuffer
import cpprb.gym
JST = datetime.timezone(datetime.timedelta(hours=+9), 'JST')
a = cpprb.gym.NotebookAnimation()
%tensorboard --logdir logs
#Test DQN:La modélisation
gamma = 0.99
batch_size = 1024
N_iteration = 101
N_show = 10
per_train = 100
prioritized = True
egreedy = True
loss = "huber_loss"
# loss = "mean_squared_error"
dir_name = datetime.datetime.now(JST).strftime("%Y%m%d-%H%M%S")
logdir = os.path.join("logs", dir_name)
writer = create_file_writer(logdir + "/metrics")
writer.set_as_default()
env = gym.make('CartPole-v0')
env = gym.wrappers.Monitor(env,logdir + "/video/", force=True,video_callable=(lambda ep: ep % 50 == 0))
observation = env.reset()
model = Sequential([InputLayer(input_shape=(observation.shape)), # 4 for CartPole
Dense(64,activation='relu'),
Dense(64,activation='relu'),
Dense(env.action_space.n)]) # 2 for CartPole
target_model = clone_model(model)
optimizer = Adam()
tensorboard_callback = TensorBoard(logdir, histogram_freq=1)
model.compile(loss = loss,
optimizer = optimizer,
metrics=['accuracy'])
a.clear()
rb = create_buffer(1e6,
{"obs":{"shape": observation.shape},
"act":{"shape": 1,"dtype": np.ubyte},
"rew": {},
"next_obs": {"shape": observation.shape},
"done": {}},
prioritized = prioritized)
action_index = np.arange(env.action_space.n).reshape(1,-1)
#Recherche initiale aléatoire
for n_episode in range (1000):
observation = env.reset()
sum_reward = 0
for t in range(500):
action = env.action_space.sample() #Sélection aléatoire d'actions
next_observation, reward, done, info = env.step(action)
rb.add(obs=observation,act=action,rew=reward,next_obs=next_observation,done=done)
observation = next_observation
if done:
break
for n_episode in tqdm(range (N_iteration)):
observation = env.reset()
for t in range(500):
if n_episode % (N_iteration // N_show)== 0:
a.add(env)
actions = softmax(np.ravel(model.predict(observation.reshape(1,-1),batch_size=1)))
actions = actions / actions.sum()
if egreedy:
if np.random.rand() < 0.9:
action = np.argmax(actions)
else:
action = env.action_space.sample()
else:
action = np.random.choice(actions.shape[0],p=actions)
next_observation, reward, done, info = env.step(action)
sum_reward += reward
rb.add(obs=observation,
act=action,
rew=reward,
next_obs=next_observation,
done=done)
observation = next_observation
sample = rb.sample(batch_size)
Q_pred = model.predict(sample["obs"])
Q_true = target_model.predict(sample['next_obs']).max(axis=1,keepdims=True)*gamma*(1.0 - sample["done"]) + sample['rew']
target = tf.where(tf.one_hot(tf.cast(tf.reshape(sample["act"],[-1]),dtype=tf.int32),env.action_space.n,True,False),
tf.broadcast_to(Q_true,[batch_size,env.action_space.n]),
Q_pred)
if prioritized:
TD = np.square(target - Q_pred).sum(axis=1)
rb.update_priorities(sample["indexes"],TD)
model.fit(x=sample['obs'],
y=target,
batch_size=batch_size,
verbose = 0)
if done:
break
if n_episode % 10 == 0:
target_model.set_weights(model.get_weights())
tf.summary.scalar("reward",data=sum_reward,step=n_episode)
rb.clear()
a.display()
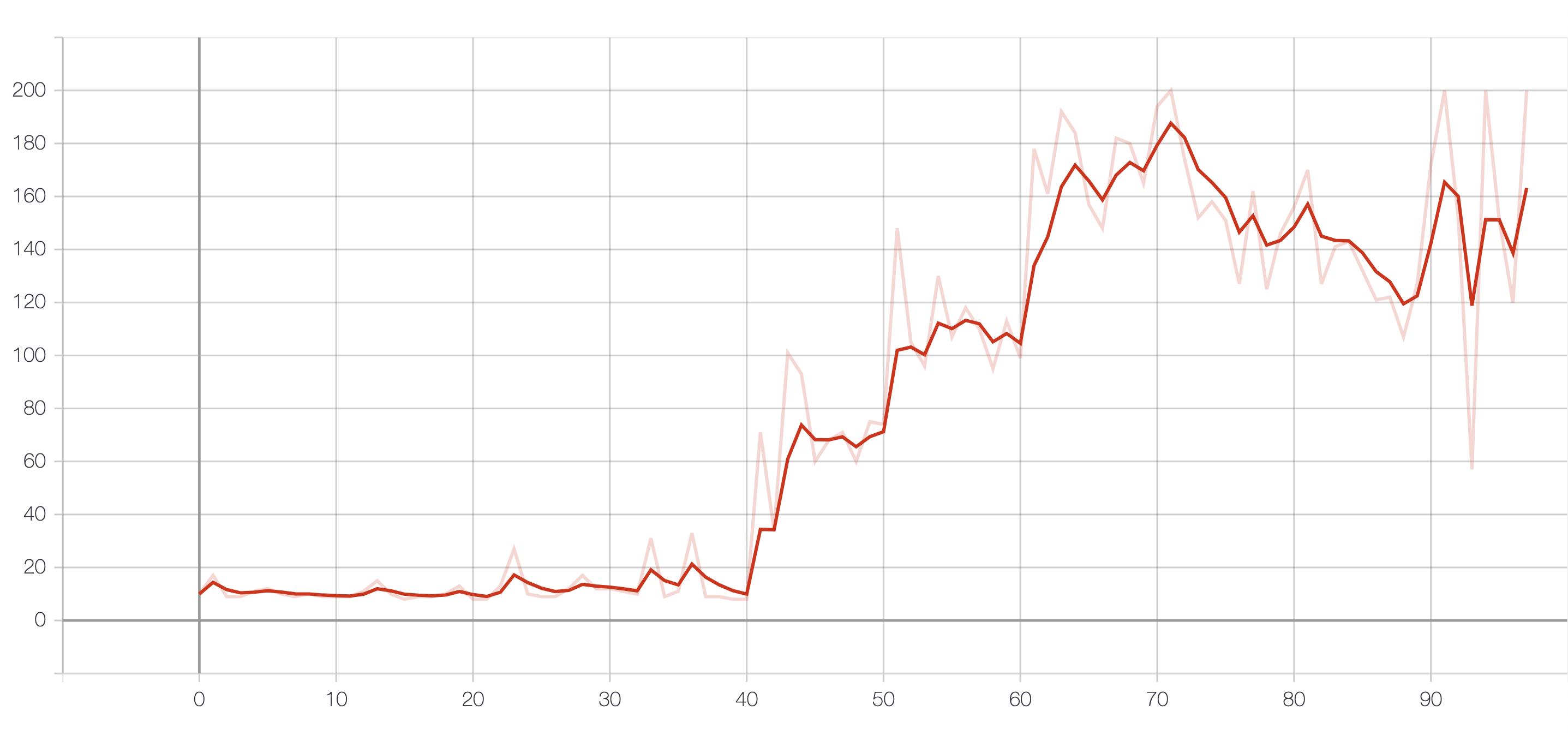
4. Résultat
Le résultat de la récompense.
6. Résumé
DQN a été implémenté à l'aide d'une bibliothèque auto-créée cpprb qui fournit un tampon de relecture pour un apprentissage amélioré.
cpprb est développé avec un haut degré de liberté et d'efficacité.
Si vous êtes intéressé, essayez-le et faites une demande de problème ou de fusion. (L'anglais est préférable, mais le japonais est également acceptable)
Lien de référence
Recommended Posts