[Python] Essayez facilement l'apprentissage amélioré (DQN) avec Keras-RL
introduction
Pour ceux qui veulent essayer l'apprentissage renforcé, mais veulent implémenter l'algorithme par eux-mêmes ... Nous préparerons l'environnement du sujet original et expliquerons le flux pour renforcer l'apprentissage avec keras-rl.
Environnement d'exécution
- Python 3.5
- keras 1.2.0
- keras-rl 0.2.0rc1
- Jupyter notebook
Bibliothèque à utiliser
keras
https://github.com/fchollet/keras
pip install keras
Il s'agit d'un cadre d'apprentissage en profondeur qui a été décrit comme étant facile à créer un réseau.
keras-rl https://github.com/matthiasplappert/keras-rl
C'est une bibliothèque qui implémente des algorithmes d'apprentissage par renforcement profond tels que DQN utilisant des keras. Voir ici pour les algorithmes pris en charge. Clonez et installez le référentiel git.
git clone https://github.com/matthiasplappert/keras-rl.git
pip install ./keras-rl
OpenAI gym https://github.com/openai/gym
pip install gym
Une bibliothèque avec divers environnements pour un apprentissage amélioré. installez keras-rl car il nécessite une interface de gym pour l'environnement d'apprentissage amélioré. Il existe un code pour apprendre le gym CartPole avec DQN dans l'exemple de keras-rl, alors essayez-le. Faisons le.
Créer un environnement pour un apprentissage amélioré
L'environnement d'apprentissage amélioré que keras-rl apprend implémente Env of OpenAI gym. Dans les commentaires d'Env du gymnase à implémenter, (https://github.com/openai/gym/blob/master/gym/core.py#L27)
When implementing an environment, override the following methods
in your subclass:
_step
_reset
_render
_close
_configure
_seed
And set the following attributes:
action_space: The Space object corresponding to valid actions
observation_space: The Space object corresponding to valid observations
reward_range: A tuple corresponding to the min and max possible rewards
Bien qu'il dise, au minimum, c'est OK si vous implémentez ce qui suit.
_step
_reset
action_space
observation_space
Cette fois, prenons un exemple simple de point qui se déplace sur une ligne droite, et prenons l'exemple de la manipulation de la vitesse à partir d'une position initiale aléatoire et visant à atteindre l'origine.
import gym
import gym.spaces
import numpy as np
#Manipuler la vitesse des points se déplaçant sur une ligne droite vers la cible(origine)Environnement dont le but est de passer
class PointOnLine(gym.core.Env):
def __init__(self):
self.action_space = gym.spaces.Discrete(3) #Espace d'action. Trois types: ralentissez, continuez
high = np.array([1.0, 1.0]) #Espace d'observation(state)Dimension(Deux dimensions de position et de vitesse)Et leur maximum
self.observation_space = gym.spaces.Box(low=-high, high=high) #La valeur minimale est moins la valeur maximale
#Appelé pour chaque étape
#Mis en œuvre pour recevoir une action et indiquer si l'état, la récompense ou l'épisode suivant est terminé
def _step(self, action):
#Recevoir l'action et décider du prochain état
dt = 0.1
acc = (action - 1) * 0.1
self._vel += acc * dt
self._vel = max(-1.0, min(self._vel, 1.0))
self._pos += self._vel * dt
self._pos = max(-1.0, min(self._pos, 1.0))
#L'épisode se termine lorsque les valeurs absolues de position et de vitesse sont suffisamment petites
done = abs(self._pos) < 0.1 and abs(self._vel) < 0.1
if done:
#Récompense positive une fois terminé
reward = 1.0
else:
#Récompense négative au fil du temps
#Si vous réduisez la valeur absolue à mesure que la distance se rapproche afin de vous rapprocher de l'objectif, l'apprentissage se déroulera plus rapidement.
reward = -0.01 * abs(self._pos)
#Renvoie l'état suivant, la récompense, si terminé, des informations supplémentaires
#Vide dict car il n'y a pas d'informations supplémentaires
return np.array([self._pos, self._vel]), reward, done, {}
#Appelé au début de chaque épisode et implémenté pour renvoyer l'état initial
def _reset(self):
#L'état initial est une position aléatoire, vitesse nulle
self._pos = np.random.rand()*2 - 1
self._vel = 0.0
return np.array([self._pos, self._vel])
Construire et apprendre DQN
Reportez-vous à l 'exemple keras-rl dqn_cartpole.py pour le code à construire et apprendre DQN. écrire.
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
from keras.optimizers import Adam
from rl.agents.dqn import DQNAgent
from rl.policy import EpsGreedyQPolicy
from rl.memory import SequentialMemory
env = PointOnLine()
nb_actions = env.action_space.n
#Définition du réseau DQN
model = Sequential()
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(nb_actions))
model.add(Activation('linear'))
print(model.summary())
#mémoire pour rejouer l'expérience
memory = SequentialMemory(limit=50000, window_length=1)
#La politique d'action est orthodoxe epsilon-glouton. De plus, Boltzmann QPolicy qui détermine la probabilité par la valeur Q de chaque action est disponible
policy = EpsGreedyQPolicy(eps=0.1)
dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=100,
target_model_update=1e-2, policy=policy)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])
history = dqn.fit(env, nb_steps=50000, visualize=False, verbose=2, nb_max_episode_steps=300)
#Si vous souhaitez dessiner l'état de l'apprentissage, dans Env_render()Implémenter et visualiser=Vrai,
Tests de dessin et résultats
Testez l'agent appris et essayez de dessiner les résultats. Implémentez Callback pour stocker les informations pour chaque étape (pas dans keras-rl?) Exécutez le test et tracez les résultats stockés dans Callback.
import rl.callbacks
class EpisodeLogger(rl.callbacks.Callback):
def __init__(self):
self.observations = {}
self.rewards = {}
self.actions = {}
def on_episode_begin(self, episode, logs):
self.observations[episode] = []
self.rewards[episode] = []
self.actions[episode] = []
def on_step_end(self, step, logs):
episode = logs['episode']
self.observations[episode].append(logs['observation'])
self.rewards[episode].append(logs['reward'])
self.actions[episode].append(logs['action'])
cb_ep = EpisodeLogger()
dqn.test(env, nb_episodes=10, visualize=False, callbacks=[cb_ep])
%matplotlib inline
import matplotlib.pyplot as plt
for obs in cb_ep.observations.values():
plt.plot([o[0] for o in obs])
plt.xlabel("step")
plt.ylabel("pos")
Testing for 10 episodes ...
Episode 1: reward: 0.972, steps: 17
Episode 2: reward: 0.975, steps: 16
Episode 3: reward: 0.832, steps: 44
Episode 4: reward: 0.973, steps: 17
Episode 5: reward: 0.799, steps: 51
Episode 6: reward: 1.000, steps: 1
Episode 7: reward: 0.704, steps: 56
Episode 8: reward: 0.846, steps: 45
Episode 9: reward: 0.667, steps: 63
Episode 10: reward: 0.944, steps: 29
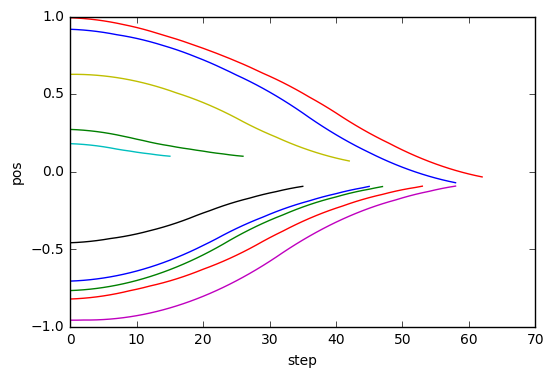
J'ai pu apprendre à passer en douceur en position 0.
Recommended Posts