[PYTHON] Défier la rupture avec le modèle Actor-Critic renforçant l'apprentissage
introduction
Je vais contester la rupture de bloc d'OpenAI Gym.
 Image empruntée à OpenAI
https://gym.openai.com/videos/2019-10-21--mqt8Qj1mwo/Breakout-v0/poster.jpg
Image empruntée à OpenAI
https://gym.openai.com/videos/2019-10-21--mqt8Qj1mwo/Breakout-v0/poster.jpg
Cette fois, nous utiliserons Keras pour créer et former un modèle Actor-Critic. Keras est une API qui facilite l'introduction de l'apprentissage en profondeur, et je pense que c'est un bon exemple pour les débutants car il y a peu de variables et de fonctions qui doivent être ajustées par vous-même.
Le modèle Actor-Critic est l'un des modèles d'apprentissage améliorés. Une explication détaillée est publiée sur le blog Tensorflow. (https://www.tensorflow.org/tutorials/reinforcement_learning/actor_critic) Cependant, contrairement à l'exemple CartPole du lien, nous casserons le bloc cette fois. J'utilise le réseau CNN car il y a beaucoup plus de sauts de blocs (84x84 images par image) que quatre variables comme CartPole. La configuration détaillée sera expliquée plus loin.
Cet article est basé sur un article publié sur Github en juillet. https://github.com/leolui2004/atari_rl_ac
résultat
Je publierai le résultat en premier. 1 entraînement = 1 jeu, 5000 entraînements sur 8 heures (épisode). Le résultat prend la moyenne des 50 dernières fois. La première feuille est le score et la deuxième feuille est le nombre de pas (pas de temps).
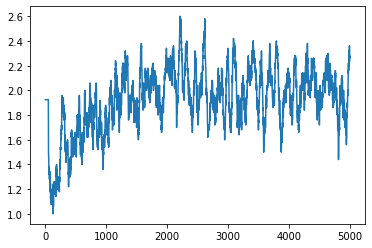
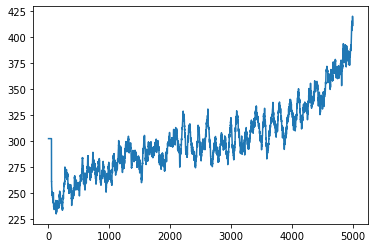
Le score semble avoir légèrement augmenté, mais le nombre de pas a donné un résultat nettement meilleur. Au fait, au début, je ne peux pas obtenir une moyenne de 50 fois, donc cela semble anormal.
manière
Le gameplay et l'apprentissage amélioré seront expliqués séparément. La partie gameplay joue le jeu dans l'environnement Gym d'OpenAI. La partie d'apprentissage par renforcement entraîne les variables reçues du jeu et reflète les actions prévues dans le jeu.
Gameplay
import gym
import random
import numpy as np
env = gym.make('Breakout-v4')
episode_limit = 5000
random_step = 20
timestep_limit = 100000 #Interdit de jouer pour toujours
model_train = 1 #Aucune formation lorsqu'il est réglé sur 0(Lecture aléatoire)
log_save = 1 #S'il est défini sur 0, le journal ne sera pas enregistré
log_path = 'atari_ac_log.txt'
score_list = []
step_list = []
for episode in range(episode_limit):
#Réinitialisez l'environnement avant de jouer à chaque fois
observation = env.reset()
score = 0
#Ne rien faire avec le premier nombre aléatoire d'étapes pour randomiser la position de la balle
for _ in range(random.randint(1, random_step)):
observation_last = observation
observation, _, _, _ = env.step(0)
#Encoder les données observées de l'action(Je t'expliquerai plus tard)
state = encode_initialize(observation, observation_last)
for timestep in range(timestep_limit):
observation_last = observation
#Obtenez l'action à prédire à partir du modèle(Je t'expliquerai plus tard)
action = action_choose(state[np.newaxis, :], epsilon, episode, action_space)
#Action basée sur l'action prévue
observation, reward, done, _ = env.step(action)
#Encoder les données observées de l'action(Je t'expliquerai plus tard)
state_next = encode(observation, observation_last, state)
if model_train == 1:
#Envoyer les données d'observation de l'action au modèle pour l'apprentissage(Je t'expliquerai plus tard)
network_learn(state[np.newaxis, :], action, reward, state_next[np.newaxis, :], done)
state = state_next
score += reward
#Fin de partie ou pas de temps_Atteindre la limite(résiliation forcée)
if done or timestep == timestep_limit - 1:
#Enregistrer les résultats
score_list.append(score)
step_list.append(timestep)
if log_save == 1:
log(log_path, episode, timestep, score)
print('Episode {} Timestep {} Score {}'.format(episode + 1, timestep, score))
break
#Une fonction qui randomise les actions dans une certaine mesure(Je t'expliquerai plus tard)
epsilon = epsilon_reduce(epsilon, episode)
env.close()
Renforcer l'apprentissage
La partie codée est la conversion en niveaux de gris, le redimensionnement et la synthèse de quatre images (frames) 84x84 consécutives. Cela signifie que vous pouvez enregistrer davantage l'action de la balle et qu'il est plus facile de vous entraîner.
from skimage.color import rgb2gray
from skimage.transform import resize
frame_length = 4
frame_width = 84
frame_height = 84
def encode_initialize(observation, last_observation):
processed_observation = np.maximum(observation, last_observation)
processed_observation_resize = np.uint8(resize(rgb2gray(processed_observation), (frame_width, frame_height)) * 255)
state = [processed_observation_resize for _ in range(frame_length)]
state_encode = np.stack(state, axis=0)
return state_encode
def encode(observation, last_observation, state):
processed_observation = np.maximum(observation, last_observation)
processed_observation_resize = np.uint8(resize(rgb2gray(processed_observation), (frame_width, frame_height)) * 255)
state_next_return = np.reshape(processed_observation_resize, (1, frame_width, frame_height))
state_encode = np.append(state[1:, :, :], state_next_return, axis=0)
return state_encode
La partie réseau et formation est la plus difficile, mais elle ressemble à ceci lorsqu'elle est représentée pour la première fois dans un diagramme.
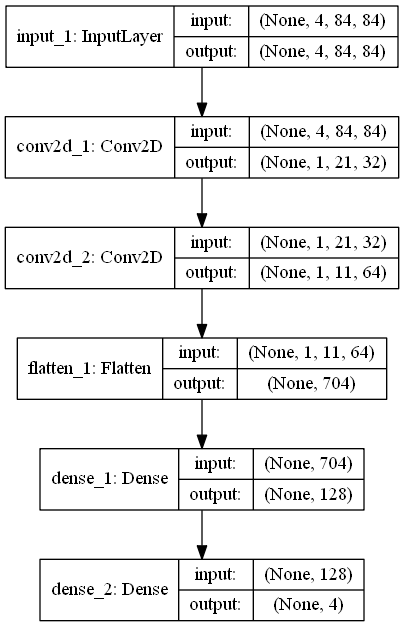
Envoyez les données pré-encodées à la couche Conv2D de 2 couches. Puis aplatissez-le et envoyez-le aux deux couches denses. Enfin, il existe quatre sorties (NOPE, FIRE, LEFT, RIGHT selon les spécifications d'OpenAI Gym Breakout-v4). À propos, la fonction d'activation est relu, la fonction de perte est conforme à l'article et le taux d'apprentissage est de 0,001 pour l'acteur et le critique.
from keras import backend as K
from keras.layers import Dense, Input, Flatten, Conv2D
from keras.models import Model, load_model
from keras.optimizers import Adam
from keras.utils import plot_model
verbose = 0
action_dim = env.action_space.n
action_space = [i for i in range(action_dim)] # ['NOOP', 'FIRE', 'RIGHT', 'LEFT']
discount = 0.97
actor_lr = 0.001 #Taux d'apprentissage de l'acteur
critic_lr = 0.001 #taux d'apprentissage des critiques
pretrain_use = 0 #Défini sur 1 pour utiliser le modèle entraîné
actor_h5_path = 'atari_ac_actor.h5'
critic_h5_path = 'atari_ac_critic.h5'
#Construction de modèles
input = Input(shape=(frame_length, frame_width, frame_height))
delta = Input(shape=[1])
con1 = Conv2D(32, (8, 8), strides=(4, 4), padding='same', activation='relu')(input)
con2 = Conv2D(64, (4, 4), strides=(2, 2), padding='same', activation='relu')(con1)
fla1 = Flatten()(con2)
dense = Dense(128, activation='relu')(fla1) #prob,Partager la valeur
prob = Dense(action_dim, activation='softmax')(dense) #partie d'acteur
value = Dense(1, activation='linear')(dense) #partie critique
#Définition de la fonction de perte
def custom_loss(y_true, y_pred):
out = K.clip(y_pred, 1e-8, 1-1e-8) #Fixer des limites
log_lik = y_true * K.log(out) #Gradient de politique
return K.sum(-log_lik * delta)
if pretrain_use == 1:
#Utilisez un modèle entraîné
actor = load_model(actor_h5_path, custom_objects={'custom_loss': custom_loss}, compile=False)
critic = load_model(critic_h5_path)
actor = Model(inputs=[input, delta], outputs=[prob])
critic = Model(inputs=[input], outputs=[value])
policy = Model(inputs=[input], outputs=[prob])
actor.compile(optimizer=Adam(lr=actor_lr), loss=custom_loss)
critic.compile(optimizer=Adam(lr=critic_lr), loss='mean_squared_error')
#Prédire l'action
def action_choose(state, epsilon, episode, action_space):
#epsilon réglé d'abord sur 1 et diminue progressivement
#Comparé à des nombres aléatoires à chaque fois que vous agissez
#Effectuer une action aléatoire si epsilon est plus grand
if epsilon >= random.random() or episode < initial_replay:
action = random.randrange(action_dim)
else:
probabiliy = policy.predict(state)[0]
#Les résultats prévus ont des probabilités pour chacune des quatre actions
#Choisissez une action en fonction de cette probabilité
action = np.random.choice(action_space, p=probabiliy)
return action
#Apprenez les données
def network_learn(state, action, reward, state_next, done):
reward_clip = np.sign(reward)
critic_value = critic.predict(state)
critic_value_next = critic.predict(state_next)
target = reward_clip + discount * critic_value_next * (1 - int(done))
delta = target - critic_value
actions = np.zeros([1, action_dim])
actions[np.arange(1), action] = 1
actor.fit([state, delta], actions, verbose=verbose)
critic.fit(state, target, verbose=verbose)
Cette partie n'est pas directement liée à l'apprentissage amélioré en tant qu'autre fonction, mais je vais l'écrire ensemble.
import matplotlib.pyplot as plt
model_save = 1 #0 ne sauvegarde pas le modèle
score_avg_freq = 50
epsilon_start = 1.0 #Probabilité au début d'Epsilon
epsilon_end = 0.1 #epsilon probabilité la plus faible(Au moins 10%Action aléatoire avec)
epsilon_step = episode_limit
epsilon = 1.0
epsilon_reduce_step = (epsilon_start - epsilon_end) / epsilon_step
initial_replay = 200
actor_graph_path = 'atari_ac_actor.png'
critic_graph_path = 'atari_ac_critic.png'
policy_graph_path = 'atari_ac_policy.png'
#fonction d'abaissement epsilon
def epsilon_reduce(epsilon, episode):
if epsilon > epsilon_end and episode >= initial_replay:
epsilon -= epsilon_reduce_step
return epsilon
#Rédiger un journal
def log(log_path, episode, timestep, score):
logger = open(log_path, 'a')
if episode == 0:
logger.write('Episode Timestep Score\n')
logger.write('{} {} {}\n'.format(episode + 1, timestep, score))
logger.close()
if pretrain_use == 1:
if model_save == 1:
actor.save(actor_h5_path)
critic.save(critic_h5_path)
else:
if model_save == 1:
actor.save(actor_h5_path)
critic.save(critic_h5_path)
#Configuration du modèle de sortie vers le diagramme
plot_model(actor, show_shapes=True, to_file=actor_graph_path)
plot_model(critic, show_shapes=True, to_file=critic_graph_path)
plot_model(policy, show_shapes=True, to_file=policy_graph_path)
#Afficher le résultat sur la figure
xaxis = []
score_avg_list = []
step_avg_list = []
for i in range(1, episode_limit + 1):
xaxis.append(i)
if i < score_avg_freq:
score_avg_list.append(np.mean(score_list[:]))
step_avg_list.append(np.mean(step_list[:]))
else:
score_avg_list.append(np.mean(score_list[i - score_avg_freq:i]))
step_avg_list.append(np.mean(step_list[i - score_avg_freq:i]))
plt.plot(xaxis, score_avg_list)
plt.show()
plt.plot(xaxis, step_avg_list)
plt.show()
Recommended Posts