Erstellen Sie mit Python einen Entscheidungsbaum von 0 (1. Übersicht)
Was ist ein Entscheidungsbaum?
Beispiel eines Entscheidungsbaums
Zum Beispiel, wenn Sie die folgenden Daten haben: Wenn Wetter, Temperatur, Luftfeuchtigkeit und Wind wie folgt sind, ist der Tag, an dem Sie Golf gespielt haben, mit 〇 und der Tag, an dem Sie nicht gegangen sind, mit x gekennzeichnet. Angenommen, Sie haben 14 solcher Daten.
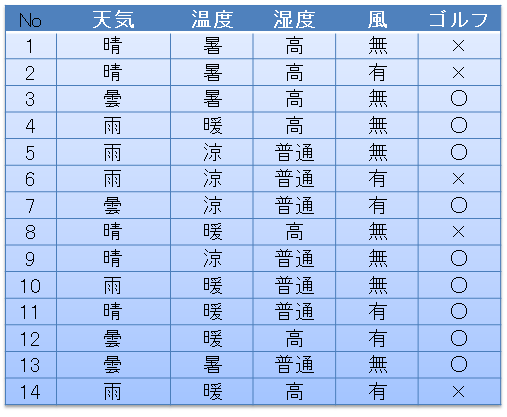
Wann gehen Sie aus diesen Daten zum Golf? Die als Baumstrukturregel beschriebene, wie unten gezeigt, wird als Entscheidungsbaum oder Entscheidungsbaum bezeichnet.
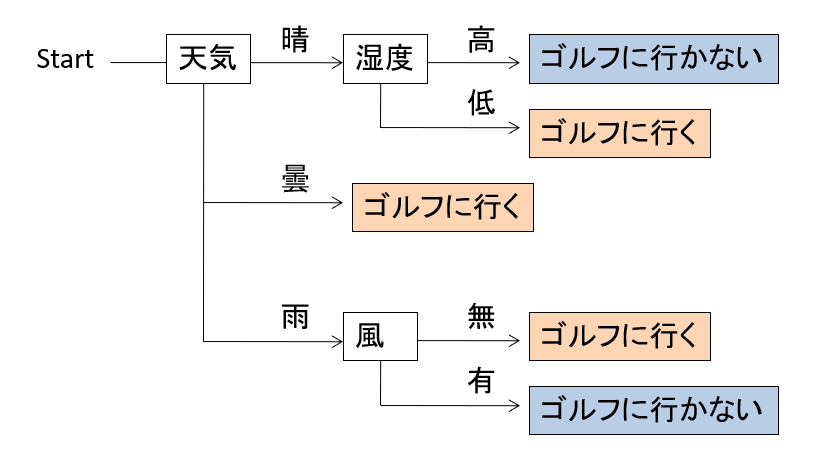
Wenn Sie sich beispielsweise diesen Entscheidungsbaum von Anfang an ansehen, überprüfen Sie zuerst das Wetter und dann die Luftfeuchtigkeit, wenn er in Ordnung ist. Gehen Sie Golf, wenn er hoch ist, und nicht, wenn er niedrig ist. Wenn Sie zum Anfang zurückkehren und das Wetter bewölkt ist, können Sie auch daran denken, unabhängig von anderen Bedingungen Golf zu spielen.
Über diesen Artikel
Ein Algorithmus, der automatisch einen solchen Entscheidungsbaum aus Daten erstellt, ist bekannt. In diesem Artikel verwenden wir Python, um einen Algorithmus namens ID3 zu implementieren.
Akademische Position des Entscheidungsbaums
Entscheidungsbäume gehören zum überwachten Lernen und Klassifikationslernen, hauptsächlich zum maschinellen Lernen, das Teil der KI ist. Dieses Klassifizierungslernen ist ein allgemeiner Begriff für eine Methode, bei der Lerndaten mit korrekten Antwortdaten angegeben werden und daraus automatisch ein Modell erstellt wird, das die richtige Antwort ableitet. Deep Learning [^ 1], das gute Ergebnisse bei der Bilderkennung erzielt hat und in den letzten Jahren populär geworden ist, ist auch eine Art des Klassifikationslernens. Der Unterschied zwischen Deep Learning und dem Entscheidungsbaum besteht darin, ob die generierten Regeln in einer vom Menschen verständlichen Form vorliegen oder nicht. Im Gegensatz zu Deep Learning, das eine Antwort geben soll, dessen Grund dem Menschen jedoch unbekannt ist, sind die Regeln wie im vorherigen Beispiel des Entscheidungsbaums leicht zu verstehen. Erstellen Sie daher ein Programm, das die Antwort automatisch einfach als Klassifizierungslernen findet. Darüber hinaus wird der Algorithmus zur Generierung von Entscheidungsbäumen auch unter dem Gesichtspunkt des Data Mining verwendet, z. B. zum Erstellen eines Entscheidungsbaums, um den Menschen das Verständnis der Daten zu erleichtern.
Über den zu erstellenden Algorithmus ID3
ID3 [^ 2] ist ein Entscheidungsbaum-Generierungsalgorithmus, der 1986 von Ross Quinlan erfunden wurde. Es hat die folgenden Funktionen.
- Wir beschäftigen uns nur mit gekennzeichneten Daten wie z. B. Gehen / Nicht-Golfen, die als kategoriale Daten (nominale Skala) bezeichnet werden. Numerische Daten können nicht verarbeitet werden.
- Suchen Sie mithilfe eines Index namens Informationsentropie nach dem Attribut (Datenspalte), das die geringste Abweichung bei den Klassenattributwerten aufweist (Spalten, die Sie klassifizieren möchten).
Umgang mit numerischen Daten
Im Fall des C4.5 [^ 3] -Algorithmus, der eine Erweiterung von ID3 ist, ist es möglich, numerische Daten zu klassifizieren. Da die Grundidee jedoch mit ID3 identisch ist, wird ID3 in diesem Artikel zuerst behandelt. ..
Entwicklungsumgebung
Es wurde bestätigt, dass das unten gezeigte Programm in der folgenden Umgebung funktioniert.
- Jupiter-Notizbücher (ich habe azurblaue Notizbücher verwendet)
- Python 3.6 --import Bibliothek: Mathe, Pandas, Funktools (verwenden Sie nicht Scikit-Learn, Tensorflow usw.)
Volltext des Programms
Wenn Sie das Programm vorerst in Jupyter Notebook kopieren, funktioniert es.
id3.py
import math
import pandas as pd
from functools import reduce
#Datensatz
d = {
"Wetter":["Fein","Fein","Wolkig","Regen","Regen","Regen","Wolkig","Fein","Fein","Regen","Fein","Wolkig","Wolkig","Regen"],
"Temperatur":["Heiß","Heiß","Heiß","Warm","Ryo","Ryo","Ryo","Warm","Ryo","Warm","Warm","Warm","Heiß","Warm"],
"Feuchtigkeit":["Hoch","Hoch","Hoch","Hoch","gewöhnlich","gewöhnlich","gewöhnlich","Hoch","gewöhnlich","gewöhnlich","gewöhnlich","Hoch","gewöhnlich","Hoch"],
"Wind":["Nichts","Ja","Nichts","Nichts","Nichts","Ja","Ja","Nichts","Nichts","Nichts","Ja","Ja","Nichts","Ja"],
#Die letzte Spalte enthält die Daten, die Sie aus anderen Spalten ableiten möchten. Diese werden auch als Zielvariable und korrekte Antwortdaten bezeichnet.
"Golf":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],
}
df0 = pd.DataFrame(d)
#Lambda-Ausdruck für die Wertverteilung, Argument ist Pandas.Der Rückgabewert ist ein Array, das die Nummer jedes Werts enthält
cstr = lambda s:[k+":"+str(v) for k,v in s.value_counts().items()]
#Entscheidungsbaumdatenstruktur, Name:Der Name dieses Knotens (Trunk), df:Mit diesem Knoten verknüpfte Daten,
# edges:Im Fall einer Liste von Kanten (Zweigen), die aus diesem Knoten herauskommen, und eines Blattknotens ohne Kanten darunter sind Kanten ein leeres Array.
tree = {"name":"decision tree "+df0.columns[-1]+" "+str(cstr(df0.iloc[:,-1])),"edges":[],"df":df0}
#Durch die Baumgenerierung werden die Amtsleitungen gespeichert, die möglicherweise Zweige in dieser Option generieren können, und sie werden der Reihe nach untersucht.
#Wenn Sie einen Trunk zu opn hinzufügen, wird dieser am Ende des Arrays hinzugefügt, und der zu untersuchende Knoten wird vom Anfang von opn entfernt, sodass es sich um eine Suche mit Breitenpriorität handelt.
opn = [tree]
#Lambda-Ausdruck zur Berechnung der Entropie, Argument ist Pandas.Serie, Rückgabewert ist Entropiewert
entropy = lambda s:-reduce(lambda x,y:x+y,map(lambda x:(x/len(s))*math.log2(x/len(s)),s.value_counts()))
#Wiederholen, bis opn leer ist.
while(len(opn)!=0):
#Extrahieren Sie den Beginn von opn und extrahieren Sie die von diesem Knoten gehaltenen Daten.
node1 = opn.pop(0)
df1 = node1["df"]
#Wenn die Entropie dieses Knotens 0 ist, kann die Kante nicht mehr erweitert werden, sodass die Suche nach diesem Knoten endet.
if 0==entropy(df1.iloc[:,-1]):
continue
#Erstellen Sie eine Variable, um die Liste der Verzweigungsattributwerte zu speichern.
attrs = {}
#Untersuchen Sie alle Attribute mit Ausnahme der letzten Spalte der Klassenattribute.
for attr in list(df1)[:-1]:
#Erstellen Sie eine Variable, um die Entropie beim Verzweigen mit diesem Attribut, die Daten nach dem Verzweigen und den zu verzweigenden Attributwert zu speichern.
attrs[attr] = {"entropy":0,"dfs":[],"values":[]}
#Untersuchen Sie alle möglichen Werte für dieses Attribut.
for value in set(df1[attr]):
#Daten nach Attributwert filtern.
df2 = df1[df1[attr]==value]
#Berechnen Sie die Entropie und speichern Sie die zugehörigen Daten bzw. Werte.
attrs[attr]["entropy"] += entropy(df2.iloc[:,-1])*len(df2)/len(df1)
attrs[attr]["dfs"] += [df2]
attrs[attr]["values"] += [value]
pass
pass
#Wenn keine Attribute vorhanden sind, die Klassenwerte trennen können, beenden Sie die Untersuchung dieses Knotens.
if len(attrs)==0:
continue
#Holen Sie sich das Attribut, das die Entropie minimiert.
attr = min(attrs,key=lambda x:attrs[x]["entropy"])
#Addieren Sie den Wert jedes Verzweigungsattributs und die Daten nach der Verzweigung zum Baum bzw. zum opn.
for d,v in zip(attrs[attr]["dfs"],attrs[attr]["values"]):
tree2 = {"name":attr+"="+v,"edges":[],"df":d.drop(columns=attr)}
node1["edges"].append(tree2)
opn.append(tree2)
pass
#Den Datensatz ausgeben.
print(df0,"\n-------------")
#Methode zum Konvertieren von Baum in Zeichen, Argument ist Baum:Baumdatenstruktur, Einzug:Einzug beim Ausdrücken von Zeichen,
#Der Rückgabewert ist eine Zeichendarstellung des Baums. Diese Methode wird rekursiv aufgerufen, um alles im Baum in Zeichen zu konvertieren.
def tstr(tree,indent=""):
#Erstellen Sie eine Zeichendarstellung für diesen Knoten.
s = indent+tree["name"]+str(cstr(tree["df"].iloc[:,-1]) if len(tree["edges"])==0 else "")+"\n"
#Schleife für alle Kanten von diesem Knoten.
for e in tree["edges"]:
#Fügen Sie die Zeichendarstellung des untergeordneten Knotens zur Zeichendarstellung dieses Knotens hinzu.
s += tstr(e,indent+" ")
pass
return s
#Drücken Sie den Baum als Zeichen aus und geben Sie ihn aus.
print(tstr(tree))
Ausführungsergebnis
Bei der Ausführung wird der Entscheidungsbaum als Zeichenschreibweise ausgegeben.
Entscheidungsbaum Golf
Wetter=Fein
Feuchtigkeit=Hoch['×:3']
Feuchtigkeit=gewöhnlich['○:2']
Wetter=Regen
Wind=Ja['×:2']
Wind=Nichts['○:3']
Wetter=Wolkig['○:4']
Ändern Sie das Attribut (Datenspalte), das Sie lernen möchten
Die letzte Datenspalte d ist das Klassenattribut (die Datenspalte, die Sie klassifizieren möchten).
data.py
d = {
"Wetter":["Fein","Fein","Wolkig","Regen","Regen","Regen","Wolkig","Fein","Fein","Regen","Fein","Wolkig","Wolkig","Regen"],
"Temperatur":["Heiß","Heiß","Heiß","Warm","Ryo","Ryo","Ryo","Warm","Ryo","Warm","Warm","Warm","Heiß","Warm"],
"Feuchtigkeit":["Hoch","Hoch","Hoch","Hoch","gewöhnlich","gewöhnlich","gewöhnlich","Hoch","gewöhnlich","gewöhnlich","gewöhnlich","Hoch","gewöhnlich","Hoch"],
"Golf":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],
#Das letzte Attribut ist das Klassenattribut (Attribut, das den Zweck der Klassifizierung darstellt).
"Wind":["Nichts","Ja","Nichts","Nichts","Nichts","Ja","Ja","Nichts","Nichts","Nichts","Ja","Ja","Nichts","Ja"],
}
Wenn Sie beispielsweise den Wind zuletzt wie oben laufen lassen, erhalten Sie das folgende Ergebnis.
Entscheidungsbaum Wind['Nichts:8', 'Ja:6']
Golf=×
Wetter=Regen['Ja:2']
Wetter=Fein
Temperatur=Heiß
Feuchtigkeit=Hoch['Nichts:1', 'Ja:1']
Temperatur=Warm['Nichts:1']
Golf=○
Wetter=Wolkig
Temperatur=Heiß['Nichts:2']
Temperatur=Ryo['Ja:1']
Temperatur=Warm['Ja:1']
Wetter=Fein
Temperatur=Ryo['Nichts:1']
Temperatur=Warm['Ja:1']
Wetter=Regen['Nichts:3']
Wenn es Wind / keinen Wind gibt, werden Regeln aufgestellt, wie z. B. nicht Golf zu spielen und sich beim Gehen zuerst zu verzweigen.
Recommended Posts