Machen Sie mit Python einen Entscheidungsbaum von 0 und verstehen Sie ihn (4. Datenstruktur)
** Erstellen und Verstehen von Entscheidungsbäumen in Python von Grund auf ** 1. Übersicht-2. Grundlagen des Python-Programms-3. Daten Analysebibliothek Pandas --4 Datenstruktur
Zum Erlernen von KI (maschinelles Lernen) und Data Mining verstehen wir, indem wir in Python einen Entscheidungsbaum von Grund auf neu erstellen.
4.1 Datenstruktur
Die Datenstruktur ist eine Darstellung der Anordnung der einzelnen Daten.
Array

Die einzelnen Daten sind in einer Reihe angeordnet. Um ein Datenelement zu identifizieren, benötigen Sie eine Kennung, z. B. die Anzahl der Daten.
#Beispiel für die Implementierung eines Arrays in Python
a = [2,6,4,5,1,8]
Tabelle, zweidimensionales Array
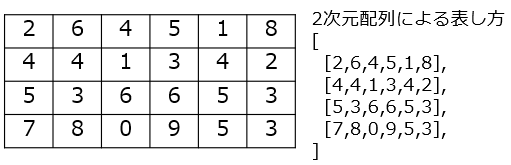 Es gibt mehrere Datenspalten, wobei einzelne Daten in einer Ebene angeordnet sind. Um ein Datenelement zu identifizieren, benötigen Sie zwei Bezeichner, z. B. die Nummer in der Spalte.
Es gibt mehrere Datenspalten, wobei einzelne Daten in einer Ebene angeordnet sind. Um ein Datenelement zu identifizieren, benötigen Sie zwei Bezeichner, z. B. die Nummer in der Spalte.
#Beispielimplementierung einer Tabelle in Python
a = [
[2,6,4,5,1,8],
[4,4,1,3,4,2],
[5,3,6,6,5,3],
[7,8,0,9,5,3],
]
Baum, Baumstruktur
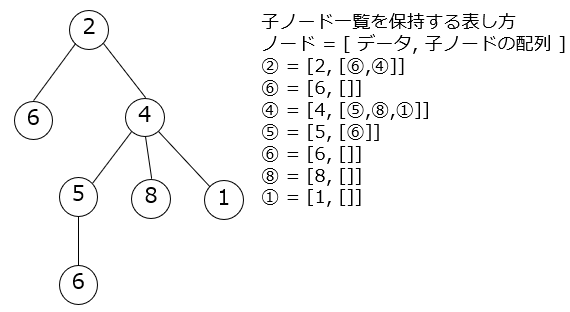
Es ist eine Datenstruktur, die einzelne Daten mit einer Linie verbindet. Die Linie zirkuliert jedoch nicht, wenn beispielsweise die Route von einem Daten zum anderen betrachtet wird, ist die mit einer Route die Baumstrukturdaten. Es wird oft als Baum dargestellt, der sich von oben nach unten erstreckt, wie unten gezeigt. Linien werden Kanten und Zweige genannt, Daten werden Knoten genannt, Daten mit Linien darunter werden Stämme und Knoten genannt, Daten ohne Linien werden Blätter und Blätter genannt, und obere Daten werden Wurzelknoten und Wurzeln genannt. Ich werde dich anrufen. Die Linie kann einseitig mit einem Pfeil sein.
#Beispiel für die Baumimplementierung in Python Enthält eine Liste der untergeordneten Knoten.
# [Wert,Array der untergeordneten Knotenliste]Beispielsweise wird der obige Baum wie folgt von oben nach unten und von links nach rechts implementiert.
#Abgesehen von dieser Implementierungsmethode gibt es Methoden wie die Verwendung einer Klasse und das Halten eines übergeordneten Knotens.
tree = \
[2,[
[6,[]],
[4,[
[5,[
[6,[]],
]],
[8,[]],
[1,[]],
]],
]]
#Funktion zur Anzeige der Baumstruktur
def tstr(node,indent=""):
print(indent+str(node[0]))
for c in node[1]: #Schleife auf untergeordneten Knoten
tstr(c,indent+"+-")
tstr(tree)
#Ausgabe
# 2
# +-6
# +-4
# +-+-5
# +-+-+-6
# +-+-8
# +-+-1
#Wenn Sie nicht den ganzen Baum auf einmal machen wollen, sondern einen nach dem anderen
#Erstellen Sie alle Blattknoten, die keine untergeordneten Knoten haben. Der Variablenname ist die Nummer aus der Zeile (Spalte) und links.
n10 = [6,[]]
n21 = [8,[]]
n22 = [1,[]]
n40 = [6,[]]
#Erstellen Sie alle untergeordneten Knoten in der Reihenfolge des generierten Knotens.
n20 = [5,[n40]]
n11 = [4,[n20,n21,n22]]
n00 = [2,[n10,n11]]
#Baumstruktur anzeigen, den angegebenen Knoten als Wurzelknoten anzeigen.
tstr(n11)
#Ausgabe
# 4
# +-5
# +-+-6
# +-8
# +-1
Netzwerk, Grafik
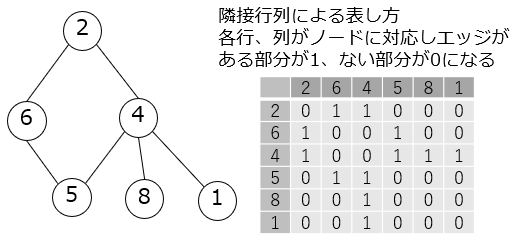 Es ist eine Datenstruktur, die Daten mit einer Kreislinie mit einer Linie verbindet. Ähnlich wie bei der Baumstruktur kann die Linie mit einem Pfeil in eine Richtung verlaufen. Einzelne Daten werden als Knoten und Linien als Kanten bezeichnet. Da es häufig keine Ausgangspunkte für Daten wie eine Baumstruktur gibt, nennen wir nicht oft Routen, Stämme, Blätter usw.
Es ist eine Datenstruktur, die Daten mit einer Kreislinie mit einer Linie verbindet. Ähnlich wie bei der Baumstruktur kann die Linie mit einem Pfeil in eine Richtung verlaufen. Einzelne Daten werden als Knoten und Linien als Kanten bezeichnet. Da es häufig keine Ausgangspunkte für Daten wie eine Baumstruktur gibt, nennen wir nicht oft Routen, Stämme, Blätter usw.
#Implementierungsbeispiel für ein Netzwerk in Python
import pandas as pd
#Es wird angenommen, dass der Name des Knotens und der Wert übereinstimmen.
#Wenn Name und Wert nicht übereinstimmen, benötigen Sie Daten, um den Wert vom Namen zu subtrahieren.
nodes = [2,6,4,5,8,1]
#Definieren Sie den Verbindungsstatus von Knoten in Form einer Matrix. Knoten 2(Die erste Zeile)Vom Knoten 6(2. Zeile)Wenn es eine Kante gibt
#Der Wert von 1 Zeile und 2 Spalten der Matrix ist 1 und 0, wenn keine Kante vorhanden ist. Diese Matrix wird als benachbarte Matrix bezeichnet.
df = pd.DataFrame(
[
# 2,6,4,5,8,Gibt es eine Verbindung zu einem Knoten?
[ 0,1,1,0,0,0], #Von 2 Knoten
[ 1,0,0,1,0,0], #Von 6 Knoten
[ 1,0,0,1,1,1], #Von 4 Knoten
[ 0,1,1,0,0,0], #Von 5 Knoten
[ 0,0,1,0,0,0], #Von 8 Knoten
[ 0,0,1,0,0,0], #Von einem Knoten
],columns=nodes,index=nodes)
print(df)
#Ausgabe
# 2 6 4 5 8 1
# 2 0 1 1 0 0 0
# 6 1 0 0 1 0 0
# 4 1 0 0 1 1 1
# 5 0 1 1 0 0 0
# 8 0 0 1 0 0 0
# 1 0 0 1 0 0 0
#Das Netzwerk wird von matplotlib und einer Bibliothek namens networkx gezeichnet.
import matplotlib.pyplot as plt
import networkx as nx
plt.figure(figsize=(4,4))
plt.axis("off")
nx.draw_networkx(nx.from_pandas_adjacency(df))
plt.show()
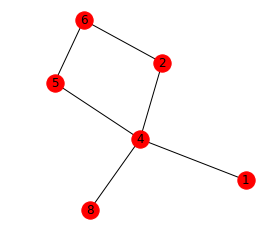
Beispiel für eine Netzwerkausgabe
4.2 Beispiel für die Python-Implementierung des Entscheidungsbaums
Der Entscheidungsbaum kann, wie der Name schon sagt, durch eine Baumstruktur dargestellt werden. Die vom Knoten gehaltenen Daten enthalten neben der Liste der untergeordneten Knoten mit einer Baumstruktur die Regeln für die Verzweigung und die Liste der Daten, die diesen Knoten erreichen können, im Entscheidungsbaum.
Platzieren Sie einen leeren Knoten auf dem Stammknoten und ordnen Sie alle Daten wie unten gezeigt zu. Die an den Knoten angehängte [...] Nummer repräsentiert die Datennummer der Originaldaten, aus denen dieser Entscheidungsbaum erstellt wird. Und vom Stammknoten aus können nur die Daten ausgedrückt werden, die die Bedingungen der untergeordneten Knoten erfüllen. Die Knoten im Entscheidungsbaum, die zum Golf gehen und nicht zum Golf gehen, können anhand der dem Knoten zugeordneten Daten gefunden werden.
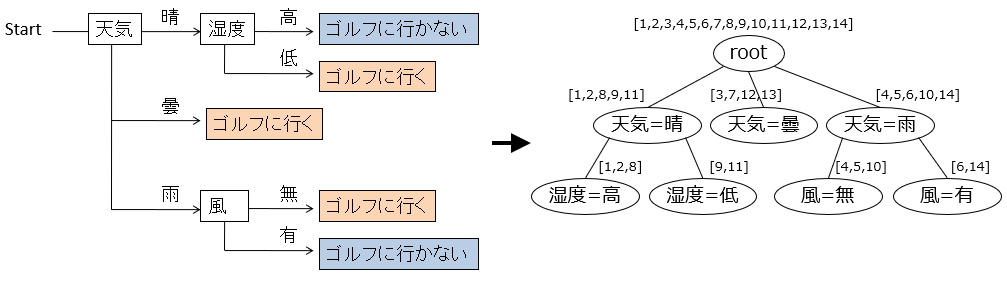
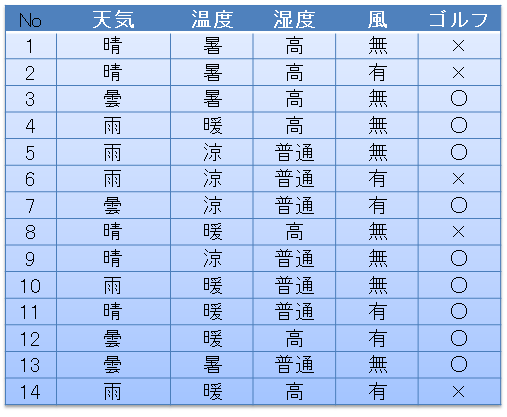
Die Python-Implementierung ist zum Beispiel: Ein Knoten ist ein assoziatives Array, der Name ist eine Zeichendarstellung des Zustands dieses Knotens, df sind die diesem Knoten zugeordneten Daten und Kanten sind eine Liste von untergeordneten Knoten.
#Baumstrukturdaten
tree = {
# name:Dieser Knoten(Stengel)s Name
"name":"decision tree "+df0.columns[-1]+" "+str(cstr(df0.iloc[:,-1])),
# df:Mit diesem Knoten verknüpfte Daten
"df":df0,
# edges:Kante kommt aus diesem Knoten heraus(Ast)Wenn der Blattknoten in der Liste keine Kante darunter hat, handelt es sich um ein leeres Array.
"edges":[],
}
Die Funktion tstr, die diese Baumstruktur kennzeichnet, sieht folgendermaßen aus:
#Lambda-Ausdruck für die Wertverteilung, Argument ist Pandas.Der Rückgabewert ist ein Array, das die Nummer jedes Werts enthält
#Geben Sie s als Wert ein_counts()Ermitteln Sie die Häufigkeit jedes Werts mit und wiederholen Sie Elemente von Wörterbuchtypdaten()Anrufen.
#sortiert sortiert in aufsteigender Reihenfolge der Häufigkeit, damit sich das Ausgabeergebnis nicht bei jeder Ausführung ändert.
#Und das Element ist der Schlüssel(k)Und Wert(v)Generieren Sie ein Array mit einer Zeichenfolge von.
cstr = lambda s:[k+":"+str(v) for k,v in sorted(s.value_counts().items())]
#Methode zum Konvertieren von Baum in Zeichen, Argument ist Baum:Baumdatenstruktur, Einzug:Einrückungen auf untergeordneten Knoten,
#Der Rückgabewert ist eine Zeichendarstellung des Baums. Diese Methode wird rekursiv aufgerufen, um alles im Baum in Zeichen zu konvertieren.
def tstr(tree,indent=""):
#Erstellen Sie eine Zeichendarstellung für diesen Knoten. Wenn dieser Knoten ein Blattknoten ist(Die Anzahl der Elemente im Kantenarray beträgt 0)Zu
#Charakterisieren Sie die Häufigkeitsverteilung in der letzten Spalte der dem Baum zugeordneten Daten df.
s = indent+tree["name"]+str(cstr(tree["df"].iloc[:,-1]) if len(tree["edges"])==0 else "")+"\n"
#Schleife an allen Kanten von diesem Knoten.
for e in tree["edges"]:
#Fügen Sie die Zeichendarstellung des untergeordneten Knotens zur Zeichendarstellung dieses Knotens hinzu.
#Fügen Sie zum Einzug weitere Zeichen zum Einzug dieses Knotens hinzu.
s += tstr(e,indent+" ")
pass
return s
Der von dieser tstr-Funktion transkribierte Entscheidungsbaum sieht folgendermaßen aus: Der Wurzelknoten zeigt den Charakter (Entscheidungsbaumgolf), der bei der ersten Erstellung der Baumvariablen festgelegt wurde, und die Häufigkeitsverteilung für alle Daten, ob Sie Golf spielen oder nicht. In jedem Knoten darunter die Regeln für die Verzweigung und im Fall von Blattknoten die Häufigkeitsverteilung für das Gehen / Nicht-Golfen in den diesem Knoten zugeordneten Daten (z. B. ['○: 2']). Wird angezeigt.
Entscheidungsbaum Golf['×:5', '○:9']
Wetter=Fein
Feuchtigkeit=gewöhnlich['○:2']
Feuchtigkeit=Hoch['×:3']
Wetter=Wolkig['○:4']
Wetter=Regen
Wind=Ja['×:2']
Wind=Nichts['○:3']