Erstellen Sie mit Python einen Entscheidungsbaum von 0 und verstehen Sie ihn (5. Information Entropy)
** Erstellen Sie einen Entscheidungsbaum von Grund auf in Python und verstehen Sie ihn ** 1. Übersicht-2. Grundlagen des Python-Programms-3. Daten Analysebibliothek Pandas-4. Datenstruktur --5 Informationsentropie
Zum Erlernen von KI (maschinelles Lernen) und Data Mining verstehen wir, indem wir in Python einen Entscheidungsbaum von Grund auf neu erstellen.
5.1 Informationsentropie (durchschnittliche Informationsmenge)
Beim Erstellen eines Entscheidungsbaums aus Daten verwendet der ID3-Algorithmus einen Index namens Informationsentropie, um zu bestimmen, welches Attribut für die Verzweigung verwendet werden soll, um Daten am effizientesten zu verteilen.
Zunächst definieren wir das Konzept der Informationsmenge. Intuitiv ist die Informationsmenge = die Komplexität der Daten. Im Entscheidungsbaum werden beim Verzweigen des Baums die Daten desselben Klassenwerts gesammelt, dh die Komplexität des Klassenwerts nimmt ab. Wenn Sie überlegen, welches Attribut für die Verzweigung verwendet werden soll, reicht es daher aus, zu beurteilen, wie einfach die geteilten Daten sind.
5.1.1 Informationsmenge definieren
Die Informationsmenge entspricht dem Wert der erfassten Informationen, und es wird angenommen, dass die Informationsmenge über ein Ereignis mit einer geringen Eintrittswahrscheinlichkeit, beispielsweise das Auftreten, größer ist als die Informationsmenge über ein Ereignis mit einer hohen Eintrittswahrscheinlichkeit.
Zum Beispiel ist es informativer, wenn Sie die Antwort auf eine Frage mit fünf Auswahlmöglichkeiten kennen, als wenn Sie die Antwort auf eine Frage mit zwei Auswahlmöglichkeiten kennen.
Um das Ereignis dann an andere weiterzuleiten, nehmen wir an, dass es in eine Binärzahl codiert und an eine Kommunikationsleitung gesendet wird. Die Kommunikationsmenge (Bitlänge) zu diesem Zeitpunkt ist als Informationsmenge definiert.
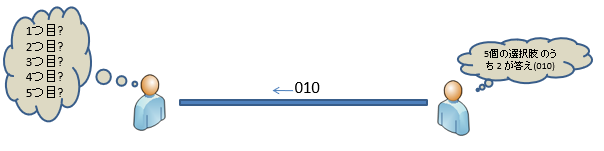
Wenn die Wahrscheinlichkeit, dass Ereignis E auftritt, P (E) ist, wird die Informationsmenge I (E), die weiß, dass Ereignis E aufgetreten ist, wie folgt definiert.
I(E) = log_2(1/P(E)) = -log_2P(E)
5.1.2 Was ist Informationsentropie (durchschnittliche Informationsmenge)?
Ein Attribut hat mehrere Attributwerte. Zum Beispiel gibt es drei Arten von Wetterattributen: sonnig, bewölkt und regnerisch. Der Durchschnittswert im Attribut der Informationsmenge, die aus jeder Auftrittswahrscheinlichkeit erhalten wird, wird als Entropie (durchschnittliche Informationsmenge) bezeichnet.
Es wird in der folgenden Formel durch H dargestellt.
H = -\sum_{E\in\Omega} P(E)\log_2{P(E)}
Beispielsweise wird die Entropie zweier Attribute, wie in der folgenden Abbildung gezeigt, wie folgt berechnet. Die gemischtere, chaotischere linke Seite hat eine höhere Entropie und die schwarz dominierte rechte Seite hat eine niedrigere Entropie als die linke.
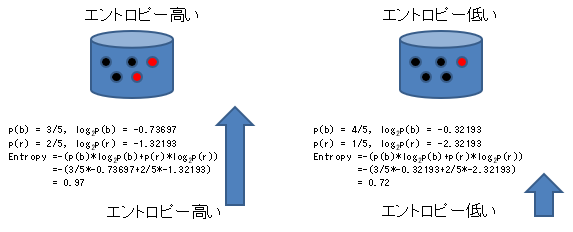
Selbst wenn Sie keine komplizierten Formeln verwenden, scheint im Fall des obigen Beispiels Komplexität erforderlich zu sein, wenn Sie die Anzahl der Schwarzen betrachten. Betrachtet man beispielsweise den Fall eines Drei-Wertes mit gelbem Zusatz, so ist die Informationsentropie, die sowohl für Zwei- als auch für Drei-Werte auf die gleiche Weise berechnet werden kann, einheitlicher und einfacher zu handhaben.
Im folgenden Beispiel wird berechnet, dass selbst bei gleicher Anzahl von Schwarzen die Entropie höher ist, wenn der Rest in Rot und Gelb unterteilt ist, als wenn der Rest nur Rot ist.
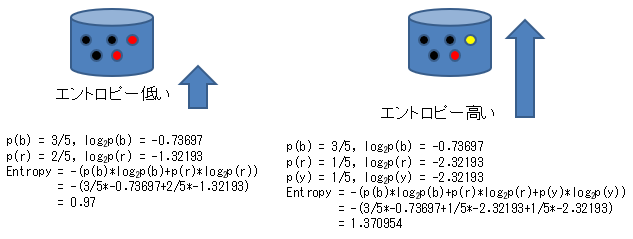
Dieser ID3-Algorithmus sucht nach Attributwerten, die die Daten in Gruppen mit geringerer Entropie unterteilen.
5.2 Berechnung der Informationsentropie
Die Informationsentropie kann durch den folgenden Lambda-Ausdruck mit DataFrame als Eingabe und Entropienummer als Ausgabe berechnet werden.
entropy = lambda df:-reduce(lambda x,y:x+y,map(lambda x:(x/len(df))*math.log2(x/len(df)),df.iloc[:,-1].value_counts()))
Dies liegt daran, dass der Lambda-Ausdruck weiter im Lambda-Ausdruck enthalten ist. Daher werde ich ihn ein wenig organisieren und wie folgt anzeigen.
entropy = lambda df:-reduce( #4.Reduzieren erstellt einen Wert aus allen Array-Elementen.
lambda x,y:x+y,#5.Einzelwerte(9,5)Addiere die Entropie aus.
map( #2.Frequenzarray(["○":9,"×":5])Anzahl der(9,5)Entropie mit der folgenden Lamda-Formel
lambda x:(x/len(df))*math.log2(x/len(df)),#3.P(E)log2(P(E))Berechnen
df.iloc[:,-1].value_counts() #1.Häufigkeit der letzten Spalte des DataFrame (z:["○":9,"×":5])
)
)
Dieser Ausdruck wird in der folgenden Reihenfolge verarbeitet:
- df.iloc [:, -1] extrahiert die letzte Spalte des DataFrame und value_counts gibt seine Häufigkeitsverteilung an (Beispiel für die Häufigkeitsverteilung: ["○": 9, "×": 5]).
- map wandelt jede der Leistungsverteilungsnummern (z. B. 9,5) in Entropiewerte um.
- (x / len (df)) * math.log2 (x / len (df)) berechnet den Ausdruck $ P (E) \ log_2 {P (E)} $ für eine Entropie.
- Verwenden Sie Reduzieren, um aus allen Elementen eines Arrays einen einzelnen Wert zu erstellen. Zum Beispiel kann es verwendet werden, um Summen, Durchschnittswerte usw. zu berechnen.
- Der Lamda-Ausdruck x, y: x + y gibt die Summe der beiden Argumente (x, y) an, dh die Summe der Arrays. Dies ist der Sigma-Teil der Entropieformel ($ - \ sum_ {E \ in \ Omega} P (E) \ log_2 {P (E)} $). Da der Ausdruck am Anfang ein Minus hat, hat er auch ein Minus vor dem Reduzieren des Programms.
5.2.1 Berechnungsbeispiel
Die Informationsentropie für die folgenden Daten beträgt 0,9402859586706309.
d = {"Golf":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"]}
#Die Entropie ist 0.9402859586706309
Wenn andererseits die ersten beiden x in ○ geändert werden und ○ zu den dominanten Daten wird (die Komplexität wird verringert), beträgt die Entropie 0,74959525725948.
d = {"Golf":["○","○","○","○","○","×","○","×","○","○","○","○","○","×"]}
#Die Entropie ist 0.74959525725948
Unten finden Sie eine Liste aller Programme, die die Informationsentropie berechnen.
import pandas as pd
from functools import reduce
import math
d = {"Golf":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"]}
df0 = pd.DataFrame(d)
entropy = lambda df:-reduce(
lambda x,y:x+y,
map(
lambda x:(x/len(df))*math.log2(x/len(df)),
df.iloc[:,-1].value_counts()
)
)
print(entropy(df0)) #Ausgabe 0.9402859586706309
Recommended Posts