[PYTHON] 100 Sprachverarbeitung Knock 2020 Kapitel 10: Maschinelle Übersetzung (90-98)
Neulich wurde 100 Language Processing Knock 2020 veröffentlicht. Ich selbst arbeite erst seit einem Jahr an natürlicher Sprache und kenne die Details nicht, aber ich werde alle Probleme lösen und veröffentlichen, um meine technischen Fähigkeiten zu verbessern.
Alle müssen auf dem Jupiter-Notizbuch ausgeführt werden, und die Einschränkungen der Problemstellung können bequem verletzt werden.
Der Quellcode ist auch auf Github. Ja.
Kapitel 9 ist hier.
Ich habe Python 3.8.2 verwendet. Ich habe 4 Tesla V100 für die GPU verwendet.
Kapitel 10: Maschinelle Übersetzung
In diesem Kapitel wird ein neuronales maschinelles Übersetzungsmodell unter Verwendung des japanischen und englischen Übersetzungskorpus Kyoto Free Translation Task (KFTT) erstellt. Machen. Um ein neuronales maschinelles Übersetzungsmodell zu erstellen, fairseq, Hugging Face Transformers, [OpenNMT-py] Nutzen Sie vorhandene Tools wie (https://github.com/OpenNMT/OpenNMT-py).
Verwenden Sie fairseq für die Bibliothek.
Die letzte 99. Frage ist die Frage der Erstellung einer Webanwendung. Es ist unmöglich, es mit einem Jupyter-Notebook zu machen, also werde ich es in einem anderen Artikel machen.
90. Datenaufbereitung
Laden Sie den Datensatz für maschinelle Übersetzung herunter. Formatieren Sie Trainingsdaten, Entwicklungsdaten und Auswertungsdaten und führen Sie bei Bedarf eine Vorverarbeitung durch, z. B. eine Tokenisierung. Verwenden Sie zu diesem Zeitpunkt jedoch Morphologie (Japanisch) und Wörter (Englisch) als Token-Einheit.
Laden Sie die KFTT-Daten herunter und entpacken Sie sie.
tar zxvf kftt-data-1.0.tar.gz
Tokenisieren Sie die Daten auf japanischer Seite mit GiNZA.
cat kftt-data-1.0/data/orig/kyoto-train.ja | sed 's/\s+/ /g' | ginzame > train.ginza.ja
cat kftt-data-1.0/data/orig/kyoto-dev.ja | sed 's/\s+/ /g' | ginzame > dev.ginza.ja
cat kftt-data-1.0/data/orig/kyoto-test.ja | sed 's/\s+/ /g' | ginzame > test.ginza.ja
for src, dst in [
('train.ginza.ja', 'train.spacy.ja'),
('dev.ginza.ja', 'dev.spacy.ja'),
('test.ginza.ja', 'test.spacy.ja'),
]:
with open(src) as f:
lst = []
tmp = []
for x in f:
x = x.strip()
if x == 'EOS':
lst.append(' '.join(tmp))
tmp = []
elif x != '':
tmp.append(x.split('\t')[0])
with open(dst, 'w') as f:
for line in lst:
print(line, file=f)
Es ist eine schlechte Einstellung, die Ausgabedatei auf "~ .spacy.ja" zu setzen, aber ich denke, dass es in Ordnung ist, weil ich es getan habe. Sie können solche Daten erstellen.
Yukifune (Shushu, 1420 (Oei 27))-1506 (3. Jahr von Eisho)) ist ein Thema, und er war ein Tuschemaler und Zen-Priester, der in der Muromachi-Ära in der zweiten Hälfte des 15. Jahrhunderts tätig war und auch als Malerheiliger bezeichnet wird.
Es hat die japanische Tuschemalerei komplett verändert.
諱 hieß "Toyo" oder "Sesshu".
Er wurde in Bichu-koku geboren und zog nach seiner Ankunft in Kyoto und Sogoku-ji nach Suo-koku.
Danach begleitete er den Boten, um in China (Ming) chinesische Tuschemalerei zu studieren.
Es gibt viele Werke, nicht nur Bergwasserbilder im chinesischen Stil, sondern auch Porträtbilder sowie Blumen- und Vogelbilder.
Die kühne Komposition und die kraftvollen Pinselstriche schaffen einen einzigartigen Malstil.
Sechs der vorhandenen Werke wurden als nationale Schätze ausgewiesen, und man kann sagen, dass sie unter japanischen Malern eine außergewöhnliche Bewertung erhalten haben.
Aus diesem Grund gibt es im Kacho Zukanfu eine Vielzahl von Werken, die als "Denyukifune Brush" bezeichnet werden.
Es gibt viele Meinungsverschiedenheiten zwischen Experten, ob sie echt sind oder nicht.
Tokenisieren Sie die Daten auf der englischen Seite mit SpaCy.
import re
import spacy
nlp = spacy.load('en')
for src, dst in [
('kftt-data-1.0/data/orig/kyoto-train.en', 'train.spacy.en'),
('kftt-data-1.0/data/orig/kyoto-dev.en', 'dev.spacy.en'),
('kftt-data-1.0/data/orig/kyoto-test.en', 'test.spacy.en'),
]:
with open(src) as f, open(dst, 'w') as g:
for x in f:
x = x.strip()
x = re.sub(r'\s+', ' ', x)
x = nlp.make_doc(x)
x = ' '.join([doc.text for doc in x])
print(x, file=g)
Es ist so.
Known as Sesshu ( 1420 - 1506 ) , he was an ink painter and Zen monk active in the Muromachi period in the latter half of the 15th century , and was called a master painter .
He revolutionized the Japanese ink painting .
He was given the posthumous name " Toyo " or " Sesshu (Meine Sekte) . "
Born in Bicchu Province , he moved to Suo Province after entering SShokoku - ji Temple in Kyoto .
Later he accompanied a mission to Ming Dynasty China and learned Chinese ink painting .
His works were many , including not only Chinese - style landscape paintings , but also portraits and pictures of flowers and birds .
His bold compositions and strong brush strokes constituted an extremely distinctive style .
6 of his extant works are designated national treasures . Indeed , he is considered to be extraordinary among Japanese painters .
For this reason , there are a great many artworks that are attributed to him , such as folding screens with pictures of flowers and that birds are painted on them .
There are many works that even experts can not agree if they are really his work or not .
91. Schulung des maschinellen Übersetzungsmodells
Lernen Sie das Modell der neuronalen maschinellen Übersetzung anhand der in> 90 vorbereiteten Daten (das Modell des neuronalen Netzwerks kann entsprechend ausgewählt werden, z. B. Transformer oder LSTM).
Mit fairseq-preprocess vorverarbeiten und dann mit fairseq-train trainieren.
fairseq-preprocess -s ja -t en \
--trainpref train.spacy \
--validpref dev.spacy \
--destdir data91 \
--thresholdsrc 5 \
--thresholdtgt 5 \
--workers 20
Ausgabe
Namespace(align_suffix=None, alignfile=None, bpe=None, cpu=False, criterion='cross_entropy', dataset_impl='mmap', destdir='data91', empty_cache_freq=0, fp16=False, fp16_init_scale=128, fp16_scale_tolerance=0.0, fp16_scale_window=None, joined_dictionary=False, log_format=None, log_interval=1000, lr_scheduler='fixed', memory_efficient_fp16=False, min_loss_scale=0.0001, no_progress_bar=False, nwordssrc=-1, nwordstgt=-1, only_source=False, optimizer='nag', padding_factor=8, seed=1, source_lang='ja', srcdict=None, target_lang='en', task='translation', tensorboard_logdir='', testpref=None, tgtdict=None, threshold_loss_scale=None, thresholdsrc=5, thresholdtgt=5, tokenizer=None, trainpref='train.spacy', user_dir=None, validpref='dev.spacy', workers=20)
| [ja] Dictionary: 60247 types
| [ja] train.spacy.ja: 440288 sents, 11298955 tokens, 1.41% replaced by <unk>
| [ja] Dictionary: 60247 types
| [ja] dev.spacy.ja: 1166 sents, 25550 tokens, 1.54% replaced by <unk>
| [en] Dictionary: 55495 types
| [en] train.spacy.en: 440288 sents, 12319171 tokens, 1.58% replaced by <unk>
| [en] Dictionary: 55495 types
| [en] dev.spacy.en: 1166 sents, 26091 tokens, 2.85% replaced by <unk>
| Wrote preprocessed data to data91
fairseq-train data91 \
--fp16 \
--save-dir save91 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--update-freq 1 \
--dropout 0.2 --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 91.log
Änderungen des Verlusts während des Lernens werden in das Protokoll ausgegeben.
92. Anwenden des maschinellen Übersetzungsmodells
Implementieren Sie ein Programm, das einen bestimmten (willkürlichen) japanischen Satz mit dem in> 91 erlernten neuronalen maschinellen Übersetzungsmodell ins Englische übersetzt.
Wenden Sie das Übersetzungsmodell mit "fairseq -active" auf die Testdaten an.
fairseq-interactive --path save91/checkpoint10.pt data91 < test.spacy.ja | grep '^H' | cut -f3 > 92.out
93. Messung der BLEU-Punktzahl
Messen Sie den BLEU-Score in den Bewertungsdaten, um die Qualität des in> 91 erlernten neuronalen maschinellen Übersetzungsmodells zu untersuchen.
Verwenden Sie fairseq-score. Es gibt verschiedene Arten von BLEU, daher ist es möglicherweise besser, Sacrebleu anzugeben. Maschinelle Übersetzung Ich verstehe nichts. Ich hoffe, Sie haben die Fairseq-Dokumentation gelesen.
fairseq-score --sys 92.out --ref test.spacy.en
Ausgabe
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='92.out')
BLEU4 = 22.71, 53.4/27.8/16.7/10.7 (BP=1.000, ratio=1.009, syslen=27864, reflen=27625)
94. Strahlensuche
Führen Sie die Strahlensuche ein, wenn Sie den übersetzten Text mit dem in> 91 erlernten neuronalen maschinellen Übersetzungsmodell decodieren. Zeichnen Sie die Änderung der BLEU-Punktzahl auf dem Entwicklungssatz auf, während Sie die Strahlbreite entsprechend von 1 auf 100 ändern.
Ändern Sie die Strahlbreite von 1 auf 20. Ist es nicht zu lang, um auf 100 zu kommen?
for N in `seq 1 20` ; do
fairseq-interactive --path save91/checkpoint10.pt --beam $N data91 < test.spacy.ja | grep '^H' | cut -f3 > 94.$N.out
done
for N in `seq 1 20` ; do
fairseq-score --sys 94.$N.out --ref test.spacy.en > 94.$N.score
done
Lesen Sie die Partitur und machen Sie eine Grafik.
import matplotlib.pyplot as plt
def read_score(filename):
with open(filename) as f:
x = f.readlines()[1]
x = re.search(r'(?<=BLEU4 = )\d*\.\d*(?=,)', x)
return float(x.group())
xs = range(1, 21)
ys = [read_score(f'94.{x}.score') for x in xs]
plt.plot(xs, ys)
plt.show()
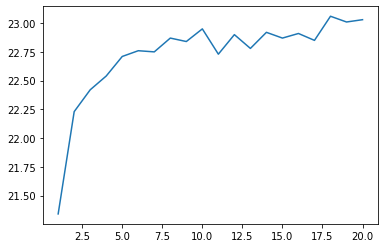
Die Strahlensuche ist wichtig
95. Unterformulierung
Ändern Sie die Token-Einheit von einem Wort oder einer Morphologie in ein Unterwort und wiederholen Sie das Experiment 91-94.
Die japanische Seite verwendete Satzstück.
import sentencepiece as spm
spm.SentencePieceTrainer.Train('--input=kftt-data-1.0/data/orig/kyoto-train.ja --model_prefix=kyoto_ja --vocab_size=16000 --character_coverage=1.0')
sp = spm.SentencePieceProcessor()
sp.Load('kyoto_ja.model')
for src, dst in [
('kftt-data-1.0/data/orig/kyoto-train.ja', 'train.sub.ja'),
('kftt-data-1.0/data/orig/kyoto-dev.ja', 'dev.sub.ja'),
('kftt-data-1.0/data/orig/kyoto-test.ja', 'test.sub.ja'),
]:
with open(src) as f, open(dst, 'w') as g:
for x in f:
x = x.strip()
x = re.sub(r'\s+', ' ', x)
x = sp.encode_as_pieces(x)
x = ' '.join(x)
print(x, file=g)
Es ist so.
Schneeboot(14 20 Jahre(27 Jahre)-150 6 Jahre(Eisho 3 Jahre) )In dieser Ausgabe war er ein Tuschemaler und Zen-Priester, der in der Muromachi-Ära in der zweiten Hälfte des 15. Jahrhunderts tätig war und auch als Heilige Malerei bezeichnet wird.
Es veränderte die japanische Tuschemalerei.
諱 ist "usw. Yang(Schließlich)Oder "Meine Sekte(Folge)".
Geboren in Bi-China, zog er nach der Einreise nach Kyoto-Sokokuji nach Suo-koku.
Danach begleitete er den Boten nach China.(Ming)Ich habe im Laufe der Jahre chinesische Tuschemalerei gelernt.
Es gab viele Werke, und nicht nur Bergwasserbilder im chinesischen Stil, sondern auch Porträtbilder und Blumen- und Vogelbilder waren gut.
Die kühne Komposition und die kraftvollen Pinselstriche sorgen für einen einzigartigen Stil.
Sechs der vorhandenen Werke wurden als nationale Schätze ausgewiesen, und man kann sagen, dass sie unter japanischen Malern eine außergewöhnliche Bewertung erhalten haben.
Aus diesem Grund gibt es im Kacho Zukanfu eine Vielzahl von Werken, die "vom Schneeboot geschrieben" wurden.
Es gibt viele Meinungsverschiedenheiten zwischen Experten, ob sie echt sind oder nicht.
Die englische Seite verwendete subword-nmt.
subword-nmt learn-bpe -s 16000 < kftt-data-1.0/data/orig/kyoto-train.en > kyoto_en.codes
subword-nmt apply-bpe -c kyoto_en.codes < kftt-data-1.0/data/orig/kyoto-train.en > train.sub.en
subword-nmt apply-bpe -c kyoto_en.codes < kftt-data-1.0/data/orig/kyoto-dev.en > dev.sub.en
subword-nmt apply-bpe -c kyoto_en.codes < kftt-data-1.0/data/orig/kyoto-test.en > test.sub.en
so was
K@@ n@@ own as Ses@@ shu (14@@ 20 - 150@@ 6@@ ), he was an ink painter and Zen monk active in the Muromachi period in the latter half of the 15th century, and was called a master pain@@ ter.
He revol@@ ut@@ ion@@ ized the Japanese ink paint@@ ing.
He was given the posthumous name "@@ Toyo@@ " or "S@@ es@@ shu (@@ich@@Damit@@ )."
Born in Bicchu Province, he moved to Suo Province after entering S@@ Shokoku-ji Temple in Kyoto.
Later he accompanied a mission to Ming Dynasty China and learned Chinese ink paint@@ ing.
His works were man@@ y, including not only Chinese-style landscape paintings, but also portraits and pictures of flowers and bird@@ s.
His b@@ old compos@@ itions and strong brush st@@ rok@@ es const@@ ituted an extremely distinctive style.
6 of his ext@@ ant works are designated national treasu@@ res. In@@ de@@ ed, he is considered to be extraordinary among Japanese pain@@ ters.
For this reason, there are a great many art@@ works that are attributed to him, such as folding scre@@ ens with pictures of flowers and that birds are painted on them.
There are many works that even experts cannot ag@@ ree if they are really his work or not.
Vorverarbeitung
fairseq-preprocess -s ja -t en \
--trainpref train.sub \
--validpref dev.sub \
--destdir data95 \
--workers 20
Zug
fairseq-train data95 \
--fp16 \
--save-dir save95 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--update-freq 1 \
--dropout 0.2 --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 95.log
Generieren
fairseq-interactive --path save95/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 95.out
Tokenize zu SpaCy
def spacy_tokenize(src, dst):
with open(src) as f, open(dst, 'w') as g:
for x in f:
x = x.strip()
x = ' '.join([doc.text for doc in nlp(x)])
print(x, file=g)
spacy_tokenize('95.out', '95.out.spacy')
Messen Sie die Punktzahl.
fairseq-score --sys 95.out.spacy --ref test.spacy.en
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='95.out.spacy')
BLEU4 = 20.36, 51.3/25.2/14.7/9.0 (BP=1.000, ratio=1.030, syslen=28463, reflen=27625)
gesenkt. Ich weiß es nicht.
Führen Sie eine Strahlensuche durch.
for N in `seq 1 10` ; do
fairseq-interactive --path save95/checkpoint10.pt --beam $N data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 95.$N.out
done
for i in range(1, 11):
spacy_tokenize(f'95.{i}.out', f'95.{i}.out.spacy')
for N in `seq 1 10` ; do
fairseq-score --sys 95.$N.out.spacy --ref test.spacy.en > 95.$N.score
done
xs = range(1, 11)
ys = [read_score(f'95.{x}.score') for x in xs]
plt.plot(xs, ys)
plt.show()
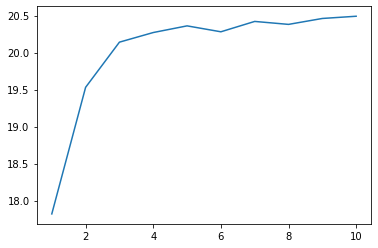
96. Visualisierung des Lernprozesses
Verwenden Sie Tools wie Tensorboard, um den Prozess zu visualisieren, mit dem das neuronale maschinelle Übersetzungsmodell trainiert wird. Verwenden Sie den Verlustfunktionswert und den BLEU-Score in den Trainingsdaten, den Verlustfunktionswert und den BLEU-Score in den Entwicklungsdaten usw. als zu visualisierende Elemente.
Sie können "--tensorboard-logdir (Speicherpfad)" für "fairseq-train" angeben. Sie können es sehen, indem Sie "pip install tensorborad tensorboardX" ausführen, tensorboard starten und localhost: 6666 (usw.) öffnen.
fairseq-train data95 \
--fp16 \
--tensorboard-logdir log96 \
--save-dir save96 \
--max-epoch 5 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.2 --weight-decay 0.0001 \
--update-freq 1 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 96.log
Ich denke, es wird so angezeigt.
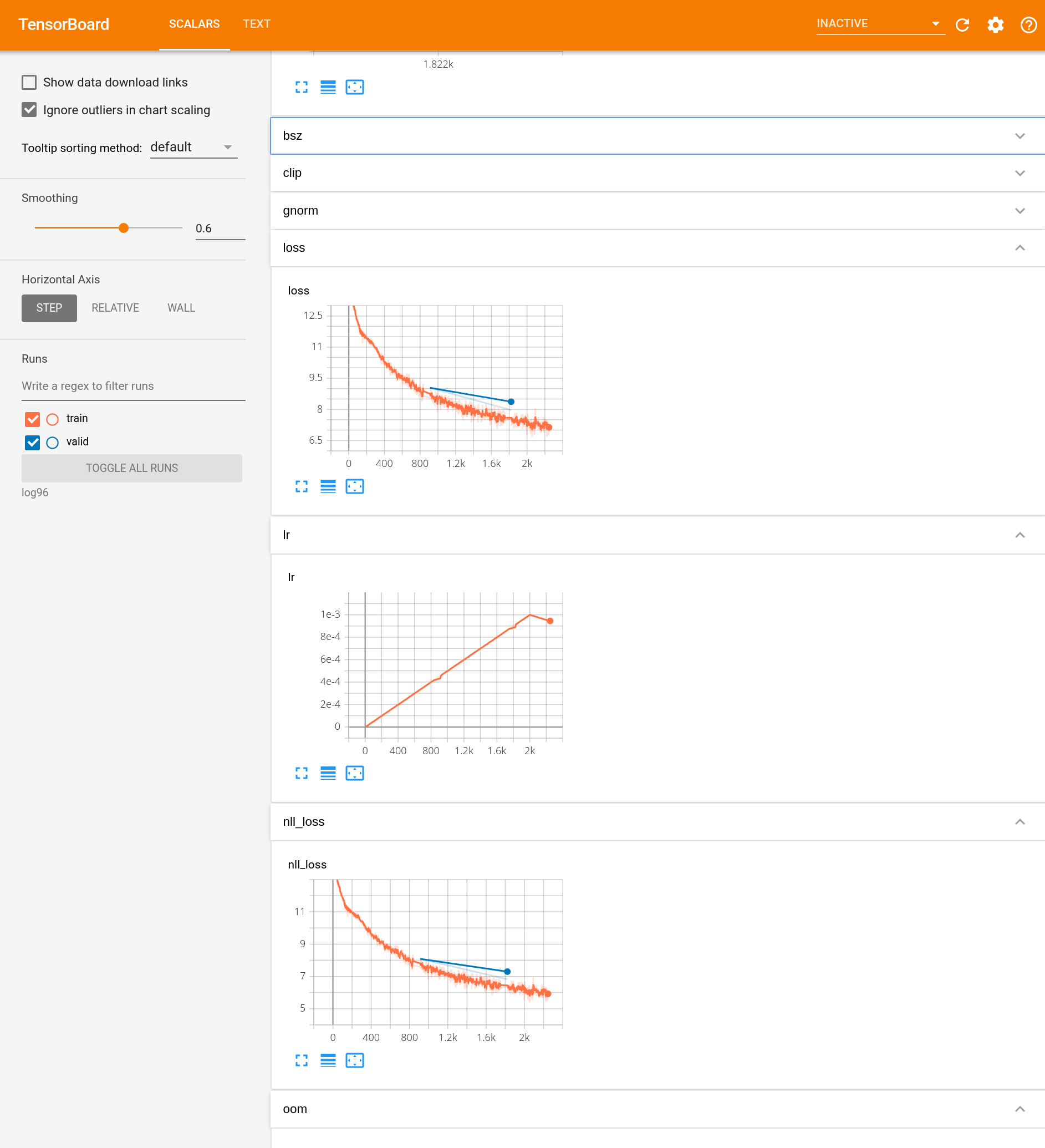
97. Hyperparameteranpassung
Finden Sie das Modell und die Hyperparameter, die den BLEU-Score in den Entwicklungsdaten maximieren, während Sie das Modell des neuronalen Netzwerks und seine Hyperparameter ändern.
Lassen Sie uns die Abbrecher- und Lernrate ändern. Ich habe es nicht sehr gut gemacht. Außerdem betrachte ich BLEU von Testdaten anstelle von Entwicklungsdaten (nicht gut).
fairseq-train data95 \
--fp16 \
--save-dir save97_1 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.1 --weight-decay 0.0001 \
--update-freq 1 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 97_1.log
fairseq-train data95 \
--fp16 \
--save-dir save97_3 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.3 --weight-decay 0.0001 \
--update-freq 1 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 97_3.log
fairseq-train data95 \
--fp16 \
--save-dir save97_5 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.5 --weight-decay 0.0001 \
--update-freq 1 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 97_5.log
fairseq-interactive --path save97_1/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 97_1.out
fairseq-interactive --path save97_3/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 97_3.out
fairseq-interactive --path save97_5/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 97_5.out
spacy_tokenize('97_1.out', '97_1.out.spacy')
spacy_tokenize('97_3.out', '97_3.out.spacy')
spacy_tokenize('97_5.out', '97_5.out.spacy')
fairseq-score --sys 97_1.out.spacy --ref test.spacy.en
fairseq-score --sys 97_3.out.spacy --ref test.spacy.en
fairseq-score --sys 97_5.out.spacy --ref test.spacy.en
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='97_1.out.spacy')
BLEU4 = 21.42, 51.7/26.3/15.7/9.9 (BP=1.000, ratio=1.055, syslen=29132, reflen=27625)
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='97_3.out.spacy')
BLEU4 = 12.99, 38.5/16.5/8.8/5.1 (BP=1.000, ratio=1.225, syslen=33832, reflen=27625)
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='97_5.out.spacy')
BLEU4 = 3.49, 21.8/4.9/1.8/0.8 (BP=1.000, ratio=1.122, syslen=31008, reflen=27625)
Je höher die Abbrecherquote ist, desto niedriger ist die BLEU. Geheimnis
98. Domänenanpassung
Japanisch-Englischer Untertitel Corpus (JESC) und JParaCrawl Versuchen Sie, die Leistung von KFTT-Testdaten mithilfe von Übersetzungsdaten wie / lilg / jparacrawl /) zu verbessern.
Nachdem wir mit JParaCrawl gelernt haben, lernen wir mit KFTT neu.
import tarfile
with tarfile.open('en-ja.tar.gz') as tar:
for f in tar.getmembers():
if f.name.endswith('txt'):
text = tar.extractfile(f).read().decode('utf-8')
break
data = text.splitlines()
data = [x.split('\t') for x in data]
data = [x for x in data if len(x) == 4]
data = [[x[3], x[2]] for x in data]
with open('jparacrawl.ja', 'w') as f, open('jparacrawl.en', 'w') as g:
for j, e in data:
print(j, file=f)
print(e, file=g)
Legen Sie das Satzstück auf die japanische Seite.
with open('jparacrawl.ja') as f, open('train.jparacrawl.ja', 'w') as g:
for x in f:
x = x.strip()
x = re.sub(r'\s+', ' ', x)
x = sp.encode_as_pieces(x)
x = ' '.join(x)
print(x, file=g)
Multiplizieren Sie subword-nmt auf der englischen Seite.
subword-nmt apply-bpe -c kyoto_en.codes < jparacrawl.en > train.jparacrawl.en
Lass mich lernen.
fairseq-preprocess -s ja -t en \
--trainpref train.jparacrawl \
--validpref dev.sub \
--destdir data98 \
--workers 20
fairseq-train data98 \
--fp16 \
--save-dir save98_1 \
--max-epoch 3 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-4 --lr-scheduler inverse_sqrt --warmup-updates 4000 \
--dropout 0.1 --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 98_1.log
fairseq-interactive --path save98_1/checkpoint3.pt data98 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 98_1.out
spacy_tokenize('98_1.out', '98_1.out.spacy')
fairseq-score --sys 98_1.out.spacy --ref test.spacy.en
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='98_1.out.spacy')
BLEU4 = 8.80, 42.9/14.7/6.3/3.2 (BP=0.830, ratio=0.843, syslen=23286, reflen=27625)
Lass uns mit KFTT lernen.
fairseq-preprocess -s ja -t en \
--trainpref train.sub \
--validpref dev.sub \
--tgtdict data98/dict.en.txt \
--srcdict data98/dict.ja.txt \
--destdir data98_2 \
--workers 20
fairseq-train data98_2 \
--fp16 \
--restore-file save98_1/checkpoint3.pt \
--save-dir save98_2 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.1 --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 98_2.log
fairseq-interactive --path save98_2/checkpoint10.pt data98_2 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 98_2.out
spacy_tokenize('98_2.out', '98_2.out.spacy')
fairseq-score --sys 98_2.out.spacy --ref test.spacy.en
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='98_2.out.spacy')
BLEU4 = 22.85, 54.9/28.0/16.7/10.7 (BP=0.998, ratio=0.998, syslen=27572, reflen=27625)
Ihre Punktzahl hat sich ein wenig verbessert.
Die 90. bis 98. Frage überspringt die Suche nach Hyperparametern als Ganzes. Wenn Sie jedoch in Kapitel 10 von 100 Klopfen einen besseren Hyperparameter finden, schreiben Sie ihn bitte in den Qiita-Artikel.
Als nächstes kommt "99. Aufbau eines Übersetzungsservers"
Erstellen Sie ein Demosystem, in dem der Benutzer den Satz eingibt, den er übersetzen möchte, und das Übersetzungsergebnis im Webbrowser angezeigt wird.
Nr. 99, ich werde es bald tun.
Recommended Posts