[PYTHON] 100 Sprachverarbeitung Knock 2020 Kapitel 4: Morphologische Analyse
Neulich wurde 100 Language Processing Knock 2020 veröffentlicht. Ich selbst arbeite erst seit einem Jahr an natürlicher Sprache und kenne die Details nicht, aber ich werde alle Probleme lösen und veröffentlichen, um meine technischen Fähigkeiten zu verbessern.
Alle müssen auf dem Jupiter-Notizbuch ausgeführt werden, und die Einschränkungen der Problemstellung können bequem verletzt werden. Der Quellcode ist auch auf Github. Ja.
Kapitel 3 ist hier.
Die Umgebung ist Python 3.8.2 und Ubuntu 18.04.
Kapitel 4: Morphologische Analyse
Verwenden Sie MeCab, um den Text (neko.txt) von Natsume Sosekis Roman "Ich bin eine Katze" morphologisch zu analysieren und das Ergebnis in einer Datei namens neko.txt.mecab zu speichern. Verwenden Sie diese Datei, um ein Programm zu implementieren, das die folgenden Fragen beantwortet.
Bitte laden Sie den erforderlichen Datensatz von [hier] herunter (https://nlp100.github.io/ja/ch04.html).
Die heruntergeladene Datei wird unter "Daten" abgelegt.
Morphologische Analyse mit MeCab
Code
mecab < data/neko.txt > data/neko.txt.mecab
Sie können eine Datei mit Inhalten wie diesem erhalten
Ein Substantiv,Nummer,*,*,*,*,einer,Ichi,Ichi
EOS
EOS
Symbol,Leer,*,*,*,*, , ,
Mein Substantiv,Gleichbedeutend,Allgemeines,*,*,*,ich,Wagahai,Wagahai
Ist ein Assistent,Hilfe,*,*,*,*,Ist,C.,Beeindruckend
Cat Nomen,Allgemeines,*,*,*,*,Katze,Katze,Katze
Mit Hilfsverb,*,*,*,Besondere,Kontinuierlicher Typ,Ist,De,De
Ein Hilfsverb,*,*,*,Fünf Schritte, La Linie Al,Grundform,Gibt es,Al,Al
.. Symbol,Phrase,*,*,*,*,。,。,。
30. Lesen der Ergebnisse der morphologischen Analyse
Implementieren Sie ein Programm, das die Ergebnisse der morphologischen Analyse liest (neko.txt.mecab). Jedes morphologische Element wird jedoch in einem Zuordnungstyp mit dem Schlüssel der Oberflächenform (Oberfläche), der Grundform (Basis), einem Teil des Wortes (pos) und einem Teil der Wortunterklassifizierung 1 (pos1) gespeichert, und ein Satz wird als Liste morphologischer Elemente (Zuordnungstyp) ausgedrückt. Machen wir das. Verwenden Sie für die restlichen Probleme in Kapitel 4 das hier erstellte Programm.
Bereiten Sie eine Funktion vor, um die Oberflächenschichtform, die Grundform, die Teilenummer und die Teilklassenteilung 1 aus jeder Zeile der Ausgabe von MeCab zu extrahieren. Gibt None zurück, wenn das Ende des Satzes erreicht ist.
Code
def line_to_dict(line):
line = line.rstrip()
if line == 'EOS':
return None
lst = line.split('\t')
pos = lst[1].split(',')
dct = {
'surface' : lst[0],
'pos' : pos[0],
'pos1' : pos[1],
'base' : pos[6],
}
return dct
Konvertieren Sie die Ausgabe von MeCab in die Liste der Ausgaben der obigen Funktion.
Code
def mecab_to_list(text):
lst = []
tmp = []
for line in text.splitlines():
dct = line_to_dict(line)
if dct is not None:
tmp.append(dct)
elif tmp:
lst.append(tmp)
tmp = []
return lst
Code
with open('data/neko.txt.mecab') as f:
neko = mecab_to_list(f.read())
Ausgabe(Erste 3 Elemente)
[[{'surface': 'einer', 'pos': 'Substantiv', 'pos1': 'Nummer', 'base': 'einer'}],
[{'surface': '\u3000', 'pos': 'Symbol', 'pos1': 'Leer', 'base': '\u3000'},
{'surface': 'ich', 'pos': 'Substantiv', 'pos1': '代Substantiv', 'base': 'ich'},
{'surface': 'Ist', 'pos': 'Partikel', 'pos1': '係Partikel', 'base': 'Ist'},
{'surface': 'Katze', 'pos': 'Substantiv', 'pos1': 'Allgemeines', 'base': 'Katze'},
{'surface': 'damit', 'pos': 'Hilfsverb', 'pos1': '*', 'base': 'Ist'},
{'surface': 'Gibt es', 'pos': 'Hilfsverb', 'pos1': '*', 'base': 'Gibt es'},
{'surface': '。', 'pos': 'Symbol', 'pos1': 'Phrase', 'base': '。'}],
[{'surface': 'Name', 'pos': 'Substantiv', 'pos1': 'Allgemeines', 'base': 'Name'},
{'surface': 'Ist', 'pos': 'Partikel', 'pos1': '係Partikel', 'base': 'Ist'},
{'surface': 'noch', 'pos': 'Adverb', 'pos1': 'Hilfsanschluss', 'base': 'noch'},
{'surface': 'Nein', 'pos': 'Adjektiv', 'pos1': 'Unabhängigkeit', 'base': 'Nein'},
{'surface': '。', 'pos': 'Symbol', 'pos1': 'Phrase', 'base': '。'}]]
31. Verb
Extrahieren Sie alle Oberflächenformen des Verbs.
Code
surfaces_of_verb = {
dct['surface']
for sent in neko
for dct in sent
if dct['pos'] == 'Verb'
}
for _, verb in zip(range(10), surfaces_of_verb):
print(verb)
print('gesamt:', len(surfaces_of_verb))
Ausgabe
Selbstachtung
Aufblühen
Ausbuchtung
Loslassen
abspielen
Zu
Aushalten
Schmutz
Schlagen
Arbeiten
gesamt: 3893
32. Prototyp des Verbs
Extrahieren Sie alle Originalformen des Verbs.
Code
bases_of_verb = {
dct['base']
for sent in neko
for dct in sent
if dct['pos'] == 'Verb'
}
for _, verb in zip(range(10), bases_of_verb):
print(verb)
print('gesamt:', len(bases_of_verb))
Ausgabe
Suku
verblassen
abspielen
Dämmerung
Auffallen
Schlagen
Erscheinen
Morgen
Füllen
Schwingen
gesamt: 2300
33. "B von A"
Extrahieren Sie die Nomenklatur, in der zwei Nomenklaturen durch "Nein" verbunden sind.
Code
def tri_grams(sent):
return zip(sent, sent[1:], sent[2:])
def is_A_no_B(x, y, z):
return x['pos'] == z['pos'] == 'Substantiv' and y['base'] == 'von'
A_no_Bs = {
''.join([x['surface'] for x in tri_gram])
for sent in neko
for tri_gram in tri_grams(sent)
if is_A_no_B(*tri_gram)
}
for _, phrase in zip(range(10), A_no_Bs):
print(phrase)
print('gesamt:', len(A_no_Bs))
Nehmen Sie das Tri-Gramm und extrahieren Sie nur diejenigen, die "Nomen + + Nase" sind. Die Doppelschleife wird durch die Listeneinschlussmethode gedreht.
Ergebnis
Mein Zuhause
Thunfischfilet
Hausspross
Der zweite König
Ushigome Yamabushi
Fragen und Antworten auf der linken Seite
Katzenbeine
Besucher
Alter Mann
Außer
gesamt: 4924
34. Verkettung der Nomenklatur
Extrahieren Sie die Verkettung der Nomenklatur (Substantive, die nacheinander erscheinen) mit der längsten Übereinstimmung.
Code
def longest_nouns(sent):
lst = []
tmp = []
for dct in sent:
if dct['pos'] == 'Substantiv':
tmp.append(dct['surface'])
else:
if len(tmp) > 1:
lst.append(tmp)
tmp = []
return lst
noun_chunks = [
''.join(nouns)
for sent in neko
for nouns in longest_nouns(sent)
]
for _, chunk in zip(range(10), noun_chunks):
print(chunk)
print('gesamt:', len(noun_chunks))
Für jeden Satz wird eine Schleife gedreht, um den Teil zu extrahieren, in dem die Nomenklatur fortlaufend ist. Das Auftreten nur einer Nomenklatur wurde nicht als Verkettung angesehen.
Ausgabe
In Menschen
Das Schlechteste
Rechtzeitig
Ein Haar
Dann Katze
einmal
Puupuu und Rauch
In der Villa
Drei Haare
Anders als Student
gesamt: 7335
35. Häufigkeit des Auftretens von Wörtern
Finden Sie die Wörter, die im Satz erscheinen, und ihre Häufigkeit des Auftretens, und ordnen Sie sie in absteigender Reihenfolge der Häufigkeit des Auftretens an.
Code
from collections import Counter
Code
surfaces = [
dct['surface']
for sent in neko
for dct in sent
]
cnt = Counter(surfaces).most_common()
for _, (word, freq) in zip(range(10), cnt):
print(word, freq)
Sie haben gerade die Nummer mit "Zähler" gezählt.
Ausgabe
9194
。 7486
6868
、 6772
Ist 6420
Bis 6243
6071
Und 5508
Ist 5337
3988
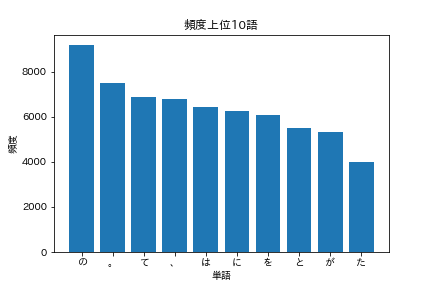
36. Top 10 der häufigsten Wörter
Zeigen Sie die 10 am häufigsten vorkommenden Wörter und ihre Häufigkeit des Auftretens in einem Diagramm an (z. B. einem Balkendiagramm).
Code
import matplotlib.pyplot as plt
import japanize_matplotlib
Ich möchte matplotlib verwenden, aber Japanisch wird damit allein nicht gut angezeigt. Das Importieren von japanize_matplotlib funktioniert einwandfrei.
Code
words = [word for word, _ in cnt[:10]]
freqs = [freq for _, freq in cnt[:10]]
plt.bar(words, freqs)
plt.title('Top 10 der häufigsten Wörter')
plt.xlabel('Wort')
plt.ylabel('Frequenz')
plt.show()
Sie sollten eine Grafik wie die folgende sehen.
37. Top 10 Wörter, die häufig zusammen mit "Katze" vorkommen
Zeigen Sie 10 Wörter an, die häufig zusammen mit "cat" (hohe Häufigkeit des gemeinsamen Auftretens) und deren Häufigkeit des Auftretens in einem Diagramm (z. B. einem Balkendiagramm) vorkommen.
Wörter, die "zusammen vorkommen", erscheinen im selben Satz.
Code
co_occured = []
for sent in neko:
if any(dct['base'] == 'Katze' for dct in sent):
words = [dct['base'] for dct in sent if dct['base'] != 'Katze']
co_occured.extend(words)
cnt = Counter(co_occured).most_common()
for _, (word, freq) in zip(range(10), cnt):
print(word, freq)
Ausgabe
391
Ist 272
、 252
Bis 250
232
231
229
。 209
Und 202
Ist 180
Ehrlich gesagt ist es langweilig mit nur Hilfswörtern, also werde ich die Teile einschränken.
Code
co_occured = []
for sent in neko:
if any(dct['base'] == 'Katze' for dct in sent):
words = [
dct['base']
for dct in sent
if dct['base'] != 'Katze'
and dct['pos'] in {'Substantiv', 'Verb', 'Adjektiv', 'Adverb'}
]
co_occured.extend(words)
cnt = Counter(co_occured).most_common()
for _, (word, freq) in zip(range(10), cnt):
print(word, freq)
Ausgabe
144
* 63
Sache 59
Ich 58
58
Dort 55
55
Mensch 40
Nicht 39
Sagen Sie 38
Da es eine große Sache ist, werfen wir einen Blick auf einige Sätze, in denen Katzen und Menschen nebeneinander existieren.
Code
for sent in neko[:1000]:
if any(dct['base'] == 'Katze' for dct in sent) and any(dct['base'] == 'Mensch' for dct in sent):
lst = [dct['surface'] for dct in sent]
print(''.join(lst))
Code
Shira-kun vergoss Tränen und erzählte die ganze Geschichte. Damit unsere Katzen die Liebe von Eltern und Kindern vervollständigen und ein schönes Familienleben führen können, müssen wir gegen Menschen kämpfen und sie zerstören. Es war.
Leider sind Menschen Tiere, die nicht in den Segen des Himmels getaucht wurden, soweit sie die Sprache der Gattung Cat verstehen können.
Ich möchte dem Leser ein wenig sagen, aber es ist nicht gut, dass Menschen die Angewohnheit haben, mich mit einem verächtlichen Ton zu bewerten, wie Katzen.
Es kann üblich sein, dass Lehrer, die sich ihrer Unwissenheit bewusst sind und ein stolzes Gesicht haben, glauben, dass Kühe und Pferde aus menschlichen Sardinen und Katzen aus Kuh- und Pferdemist hergestellt werden. Es ist jedoch keine sehr nette Person.
Auf der anderen Seite gibt es keine einzige Linie, Gleichheit und Gleichgültigkeit, und es scheint, dass keine Katze ihre eigenen einzigartigen Eigenschaften hat, aber wenn man in die Katzengesellschaft kriecht, ist es ziemlich kompliziert und das Wort der menschlichen Welt von 10 Menschen und 10 Farben bleibt wie es ist. Es kann auch hier angewendet werden.
Wenn man dies betrachtet, mag der Mensch Katzen im Sinne von Fairness überlegen sein, die sich aus Selbstsucht ergibt, aber Weisheit scheint Katzen unterlegen zu sein.
Es mag notwendig sein, dass eine Person wie der Meister, die beide Seiten hat, in ein Tagebuch schreibt und sein eigenes Gesicht zeigt, das der Welt im dunklen Raum nicht gezeigt wird, aber wenn es um unsere Katzengattung geht, ist es echt Es ist ein Tagebuch, daher denke ich nicht, dass es ausreicht, um so mühsame Arbeit zu leisten und meinen Ernst zu retten.
38. Histogramm
Zeichnen Sie ein Histogramm der Häufigkeit des Auftretens von Wörtern (die horizontale Achse repräsentiert die Häufigkeit des Auftretens und die vertikale Achse repräsentiert die Anzahl der Arten von Wörtern, die die Häufigkeit des Auftretens als Balkendiagramm verwenden).
Code
words = [
dct['base']
for sent in neko
for dct in sent
]
cnt = Counter(words).most_common()
freqs = [freq for _, freq in cnt]
plt.title('Histogramm')
plt.xlabel('Wort')
plt.ylabel('Frequenz')
plt.hist(freqs, bins=100, range=(1,100))
plt.show()
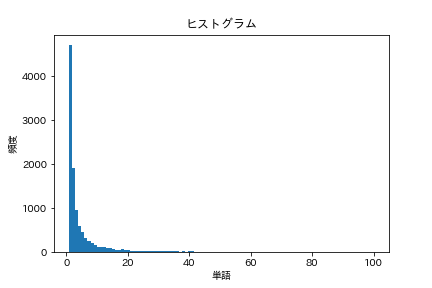
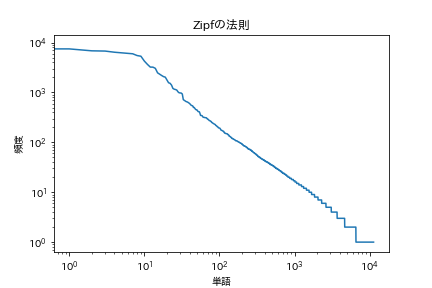
39. Zipfs Gesetz
Zeichnen Sie beide logarithmischen Diagramme mit der Häufigkeit des Auftretens von Wörtern auf der horizontalen Achse und der Häufigkeit des Auftretens auf der vertikalen Achse.
[Zip's Law](https://ja.wikipedia.org/wiki/%E3%82%B8%E3%83%83%E3%83%97%E3%81%AE%E6%B3%95%E5 % 89% 87)
Code
plt.title('Zipfs Gesetz')
plt.xlabel('Wort')
plt.ylabel('Frequenz')
plt.xscale('log')
plt.yscale('log')
plt.plot(range(len(freqs)), freqs)
plt.show()
Es sieht so aus.
Als nächstes folgt Kapitel 5
Sprachverarbeitung 100 Schläge 2020 Kapitel 5: Abhängigkeitsanalyse
Recommended Posts