[PYTHON] 100 Sprachverarbeitung Knock 2015 Kapitel 5 Abhängigkeitsanalyse (40-49)
Ich habe versucht, "Kapitel 5 Abhängigkeitsanalyse (40-49)" von [100 Schlägen] zu lösen (http://www.cl.ecei.tohoku.ac.jp/nlp100/). Dies ist eine Fortsetzung von Kapitel 4 Morphologische Analyse (30-39).
Umgebung
- OS X El Capitan Version 10.11.4
- Python 3.5.1
Referenzierte Seite
Ich war ziemlich süchtig nach der Einführung von CaboCha, Pydot und Graphviz und "49. Extraktion von Abhängigkeitspfaden zwischen Nomenklaturen", aber ich konnte es lösen, indem ich auf die folgende Seite verwies.
- 100 Klopfen natürlicher Sprachverarbeitung Kapitel 5 Abhängigkeitsanalyse (erste Hälfte)
- 100 Klopfen natürlicher Sprachverarbeitung Kapitel 5 Abhängigkeitsanalyse (zweite Hälfte)
- 100 Sprachverarbeitung klopft Version 2015 (46-49)
- CaboCha offizielle Website
- Abhängigkeitsanalyse beginnend mit CaboCha
- Zusammenfassung zum Zeichnen von Grafiken in Graphviz- und Punktsprachen
- Zeichnen einer Baumstruktur in Python 3 mit graphviz
- [AttributeError: module 'pydot' has no attribute 'graph_from_dot_data' in spyder] (http://stackoverflow.com/questions/35285142/attributeerror-module-pydot-has-no-attribute-graph-from-dot-data-in-spyder)
Vorbereitung
Bibliothek zu verwenden
import CaboCha
import pydotplus
import subprocess
Abhängig analysierten Text speichern
Verwenden Sie CaboCha, um den Text (neko.txt) von Natsume Sosekis Roman "Ich bin eine Katze" abhängig zu machen und zu analysieren, und speichern Sie das Ergebnis in einer Datei namens neko.txt.cabocha. Verwenden Sie diese Datei, um ein Programm zu implementieren, das die folgenden Fragen beantwortet.
def make_analyzed_file(input_file_name: str, output_file_name: str) -> None:
"""
Analysieren Sie abhängig eine einfache japanische Satzdatei und speichern Sie sie in einer Datei.
(Leerzeichen entfernen.)
:param input_file_name Einfacher japanischer Satzdateiname
:param output_file_Name Abhängig vom Namen der analysierten Textdatei
"""
c = CaboCha.Parser()
with open(input_file_name, encoding='utf-8') as input_file:
with open(output_file_name, mode='w', encoding='utf-8') as output_file:
for line in input_file:
tree = c.parse(line.lstrip())
output_file.write(tree.toString(CaboCha.FORMAT_LATTICE))
make_analyzed_file('neko.txt', 'neko.txt.cabocha')
40. Lesen des Ergebnisses der Abhängigkeitsanalyse (Morphologie)
Implementieren Sie die Klasse Morph, die die Morphologie darstellt. Diese Klasse hat eine Oberflächenform (Oberfläche), eine Basisform (Basis), ein Teilwort (pos) und eine Teilwortunterklassifikation 1 (pos1) als Elementvariablen. Lesen Sie außerdem das Analyseergebnis von CaboCha (neko.txt.cabocha), drücken Sie jeden Satz als Liste von Morph-Objekten aus und zeigen Sie die morphologische Elementzeichenfolge des dritten Satzes an.
class Morph:
"""
Eine Klasse, die eine Morphologie darstellt
"""
def __init__(self, surface, base, pos, pos1):
"""
Es hat eine Oberflächenform (Oberfläche), eine Grundform (Basis), einen Teiltext (pos) und eine Teiltextunterklassifizierung 1 (pos1) als Mitgliedsvariablen..
"""
self.surface = surface
self.base = base
self.pos = pos
self.pos1 = pos1
def is_end_of_sentence(self) -> bool: return self.pos1 == 'Phrase'
def __str__(self) -> str: return 'surface: {}, base: {}, pos: {}, pos1: {}'.format(self.surface, self.base, self.pos, self.pos1)
def make_morph_list(analyzed_file_name: str) -> list:
"""
Lesen Sie die abhängigkeitsanalytische Satzdatei und drücken Sie jeden Satz als Liste von Morph-Objekten aus.
:param analyzed_file_Name Abhängig vom Namen der analysierten Textdatei
:Rückgabeliste Eine Liste eines Satzes, der als Liste von Morph-Objekten dargestellt wird
"""
sentences = []
sentence = []
with open(analyzed_file_name, encoding='utf-8') as input_file:
for line in input_file:
line_list = line.split()
if (line_list[0] == '*') | (line_list[0] == 'EOS'):
pass
else:
line_list = line_list[0].split(',') + line_list[1].split(',')
#An dieser Punktlinie_Liste sieht so aus
# ['Start', 'Substantiv', 'Anwalt möglich', '*', '*', '*', '*', 'Start', 'Hajime', 'Hajime']
_morph = Morph(surface=line_list[0], base=line_list[7], pos=line_list[1], pos1=line_list[2])
sentence.append(_morph)
if _morph.is_end_of_sentence():
sentences.append(sentence)
sentence = []
return sentences
morphed_sentences = make_morph_list('neko.txt.cabocha')
#Zeigen Sie die Formularelementzeichenfolge des dritten Satzes an
for morph in morphed_sentences[2]:
print(str(morph))
41. Lesen des Abhängigkeitsanalyseergebnisses (Phrase / Abhängigkeit)
Implementieren Sie zusätzlich zu> 40 die Klauselklasse Chunk.
Diese Klasse enthält eine Liste von Morphen (Morph-Objekten), eine Liste verwandter Klauselindexnummern (dst) und eine Liste verwandter ursprünglicher Klauselindexnummern (srcs) als Mitgliedsvariablen. Lesen Sie außerdem das Analyseergebnis von CaboCha des Eingabetextes, drücken Sie einen Satz als Liste von Chunk-Objekten aus und zeigen Sie die Zeichenfolge und den Kontakt der Phrase des achten Satzes an. Verwenden Sie für die restlichen Probleme in Kapitel 5 das hier erstellte Programm.
Es gibt viele Methoden in der Chunk-Klasse, aber alles, was Sie hier brauchen, ist __init__ und __str__. Jedes Mal, wenn die nachfolgenden Fragen gelöst wurden, wurden andere Methoden hinzugefügt.
class Chunk:
def __init__(self, morphs: list, dst: str, srcs: str) -> None:
"""
Es enthält eine Liste von Morph-Elementen (Morph-Objekten) (Morphs), eine Liste verwandter Klauselindexnummern (dst) und eine Liste verwandter ursprünglicher Klauselindexnummern (srcs) als Mitgliedsvariablen.
"""
self.morphs = morphs
self.dst = int(dst.strip("D"))
self.srcs = int(srcs)
#Nachfolgend finden Sie die Methoden, die wir später verwenden werden.
def join_morphs(self) -> str:
return ''.join([_morph.surface for _morph in self.morphs if _morph.pos != 'Symbol'])
def has_noun(self) -> bool:
return any([_morph.pos == 'Substantiv' for _morph in self.morphs])
def has_verb(self) -> bool:
return any([_morph.pos == 'Verb' for _morph in self.morphs])
def has_particle(self) -> bool:
return any([_morph.pos == 'Partikel' for _morph in self.morphs])
def has_sahen_connection_noun_plus_wo(self) -> bool:
"""
"Sahen Verbindungsnomenklatur+Gibt zurück, ob "(Hilfs)" "enthalten ist..
"""
for idx, _morph in enumerate(self.morphs):
if _morph.pos == 'Substantiv' and _morph.pos1 == 'Verbindung ändern' and len(self.morphs[idx:]) > 1 and \
self.morphs[idx + 1].pos == 'Partikel' and self.morphs[idx + 1].base == 'Zu':
return True
return False
def first_verb(self) -> Morph:
return [_morph for _morph in self.morphs if _morph.pos == 'Verb'][0]
def last_particle(self) -> list:
return [_morph for _morph in self.morphs if _morph.pos == 'Partikel'][-1]
def pair(self, sentence: list) -> str:
return self.join_morphs() + '\t' + sentence[self.dst].join_morphs()
def replace_noun(self, alt: str) -> None:
"""
Nomenklatur ersetzen.
"""
for _morph in self.morphs:
if _morph.pos == 'Substantiv':
_morph.surface = alt
def __str__(self) -> str:
return 'srcs: {}, dst: {}, morphs: ({})'.format(self.srcs, self.dst, ' / '.join([str(_morph) for _morph in self.morphs]))
def make_chunk_list(analyzed_file_name: str) -> list:
"""
Lesen Sie die abhängigkeitsanalytische Satzdatei und drücken Sie jeden Satz als Liste von Chunk-Objekten aus.
:param analyzed_file_Name Abhängig vom Namen der analysierten Textdatei
:Rückgabeliste Eine Liste eines Satzes, der als Liste von Chunk-Objekten dargestellt wird
"""
sentences = []
sentence = []
_chunk = None
with open(analyzed_file_name, encoding='utf-8') as input_file:
for line in input_file:
line_list = line.split()
if line_list[0] == '*':
if _chunk is not None:
sentence.append(_chunk)
_chunk = Chunk(morphs=[], dst=line_list[2], srcs=line_list[1])
elif line_list[0] == 'EOS': # End of sentence
if _chunk is not None:
sentence.append(_chunk)
if len(sentence) > 0:
sentences.append(sentence)
_chunk = None
sentence = []
else:
line_list = line_list[0].split(',') + line_list[1].split(',')
#An dieser Punktlinie_Liste sieht so aus
# ['Start', 'Substantiv', 'Anwalt möglich', '*', '*', '*', '*', 'Start', 'Hajime', 'Hajime']
_morph = Morph(surface=line_list[0], base=line_list[7], pos=line_list[1], pos1=line_list[2])
_chunk.morphs.append(_morph)
return sentences
chunked_sentences = make_chunk_list('neko.txt.cabocha')
#Zeigen Sie die Formularelementzeichenfolge des dritten Satzes an
for chunk in chunked_sentences[2]:
print(str(chunk))
42. Anzeige des Satzes der betroffenen Person und der betroffenen Person
Extrahieren Sie den gesamten Text der ursprünglichen Klausel und der zugehörigen Klausel in tabulatorgetrenntem Format. Geben Sie jedoch keine Symbole wie Satzzeichen aus.
Ich werde jeden Satz zur Vereinfachung der Verwendung in 44 zusammenfassen.
def is_valid_chunk(_chunk, sentence):
return _chunk.join_morphs() != '' and _chunk.dst > -1 and sentence[_chunk.dst].join_morphs() != ''
paired_sentences = [[chunk.pair(sentence) for chunk in sentence if is_valid_chunk(chunk, sentence)] for sentence in chunked_sentences if len(sentence) > 1]
print(paired_sentences[0:100])
43. Extrahieren Sie Klauseln mit Nomenklaturen in Bezug auf Klauseln mit Verben
Wenn sich Klauseln mit Nomenklatur auf Klauseln mit Verben beziehen, extrahieren Sie sie in tabulatorgetrennten Formaten. Geben Sie jedoch keine Symbole wie Satzzeichen aus.
Dies ist einfach, da in der Chunk-Klasse verschiedene praktische Methoden implementiert sind.
for sentence in chunked_sentences:
for chunk in sentence:
if chunk.has_noun() and chunk.dst > -1 and sentence[chunk.dst].has_verb():
print(chunk.pair(sentence))
44. Visualisierung abhängiger Bäume
Visualisieren Sie den Abhängigkeitsbaum eines bestimmten Satzes als gerichteten Graphen. Konvertieren Sie zur Visualisierung den Abhängigkeitsbaum in die DOT-Sprache und verwenden Sie Graphviz. Verwenden Sie pydot, um gerichtete Diagramme direkt aus Python zu visualisieren.
def sentence_to_dot(idx: int, sentence: list) -> str:
head = "digraph sentence{} ".format(idx)
body_head = "{ graph [rankdir = LR]; "
body_list = ['"{}"->"{}"; '.format(*chunk_pair.split()) for chunk_pair in sentence]
return head + body_head + ''.join(body_list) + '}'
def sentences_to_dots(sentences: list) -> list:
_dots = []
for idx, sentence in enumerate(sentences):
_dots.append(sentence_to_dot(idx, sentence))
return _dots
def save_graph(dot: str, file_name: str) -> None:
g = pydotplus.graph_from_dot_data(dot)
g.write_jpeg(file_name, prog='dot')
dots = sentences_to_dots(paired_sentences)
for idx in range(101, 104):
save_graph(dots[idx], 'graph{}.jpg'.format(idx))
[Beispiel] Abhängiger Baum für den 101. Satz

[Beispiel] Abhängiger Baum für den 102. Satz

[Beispiel] Abhängiger Baum für den 103. Satz
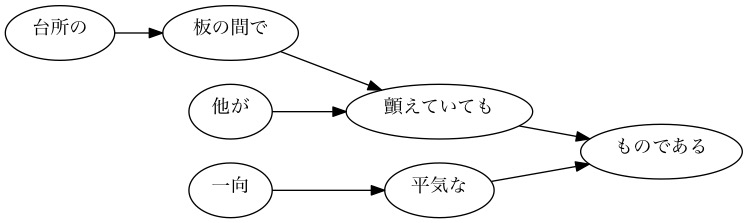
- Übrigens scheint "schwanken" als "zittern" gelesen zu werden.
45. Extraktion von Verbfallmustern
Ich möchte den diesmal verwendeten Satz als Korpus betrachten und die möglichen Fälle japanischer Prädikate untersuchen. Stellen Sie sich Verben als Prädikate und verbale Assistenten vor, die sich auf Verben als Fälle beziehen, und geben Sie Prädikate und Fälle in tabulatorgetrennten Formaten aus. Stellen Sie jedoch sicher, dass der Ausgang den folgenden Spezifikationen entspricht.
- In einer Klausel, die ein Verb enthält, wird die Grundform des Verbs ganz links als Prädikat verwendet.
- Der Fall ist das Hilfswort, das sich auf das Prädikat bezieht
- Wenn es mehrere Hilfswörter (Phrasen) gibt, die sich auf das Prädikat beziehen, ordnen Sie alle Hilfswörter in Wörterbuchreihenfolge an, die durch Leerzeichen getrennt sind.
Betrachten Sie den Beispielsatz (8. Satz von neko.txt.cabocha), dass "ich hier zum ersten Mal einen Menschen gesehen habe". Dieser Satz enthält zwei Verben, "begin" und "see", und der Ausdruck "begin" wurde als "here" analysiert, und der Ausdruck zu "see" wurde als "I am" und "thing" analysiert. In diesem Fall sollte die Ausgabe wie folgt sein.
Am Anfang Sehen
Speichern Sie die Ausgabe dieses Programms in einer Datei und überprüfen Sie die folgenden Elemente mit UNIX-Befehlen.
- Kombination von Prädikaten und Fallmustern, die häufig im Korpus vorkommen
- Das Fallmuster der Verben "do", "see" und "give" (in der Reihenfolge der Häufigkeit des Auftretens im Korpus anordnen)
def case_patterns(_chunked_sentences: list) -> list:
"""
Verbfallmuster(Kombination von Verb und Hilfs)Gibt eine Liste von zurück.("Kaku" ist auf Englisch"Case"Es scheint, dass.)
:param _chunked_Sätze Eine Liste der nach Sätzen geordneten Morphologie
:Fallmuster zurückgeben(Zum Beispiel['geben', ['Zu', 'Zu']])Liste von
"""
_case_pattern = []
for sentence in _chunked_sentences:
for _chunk in sentence:
if not _chunk.has_verb():
continue
particles = [c.last_particle().base for c in sentence if c.dst == _chunk.srcs and c.has_particle()]
if len(particles) > 0:
_case_pattern.append([_chunk.first_verb().base, sorted(particles)])
return _case_pattern
def save_case_patterns(_case_patterns: list, file_name: str) -> None:
"""
Verbfallmuster(Kombination von Verb und Hilfs)Speichern Sie die Liste in einer Datei.
:param _case_Muster(Zum Beispiel['geben', ['Zu', 'Zu']])Liste von
:param file_name Name der Zieldatei speichern
"""
with open(file_name, mode='w', encoding='utf-8') as output_file:
for _case in _case_patterns:
output_file.write('{}\t{}\n'.format(_case[0], ' '.join(_case[1])))
save_case_patterns(case_patterns(chunked_sentences), 'case_patterns.txt')
def print_case_pattern_ranking(_grep_str: str) -> None:
"""
Korpus(case_pattern.txt)Verwenden Sie UNIX-Befehle, um die Top-20-Elemente in absteigender Reihenfolge der Häufigkeit des Auftretens anzuzeigen..
`cat case_patterns.txt | grep '^Machen\t' | sort | uniq -c | sort -r | head -20`Druckt durch Ausführen eines Unix-Befehls wie.
Der grep-Teil ist das Argument`_grep_str`Wird gemäß hinzugefügt.
:param _grep_str Suchbedingung Verb
"""
_grep_str = '' if _grep_str == '' else '| grep \'^{}\t\''.format(_grep_str)
print(subprocess.run('cat case_patterns.txt {} | sort | uniq -c | sort -r | head -10'.format(_grep_str), shell=True))
#Kombinationen von Prädikaten und Fallmustern, die häufig im Korpus vorkommen (Top 10)
#Fallmuster der Verben "bis", "sehen" und "geben" (Top 10 in der Reihenfolge der Häufigkeit des Auftretens im Korpus)
for grep_str in ['', 'Machen', 'sehen', 'geben']:
print_case_pattern_ranking(grep_str)
46. Extraktion von Verbfallrahmeninformationen
Ändern Sie das Programm> 45 und geben Sie die Begriffe (die Klauseln, die sich auf die Prädikate selbst beziehen) in tabulatorgetrennten Formaten aus, wobei Sie den Prädikaten und Fallmustern folgen. Stellen Sie zusätzlich zur Spezifikation> 45 sicher, dass die folgenden Spezifikationen erfüllt sind.
- Der Begriff sollte eine Wortfolge der Klausel sein, die sich auf das Prädikat bezieht (das nachfolgende Verb muss nicht entfernt werden).
- Wenn es mehrere Klauseln gibt, die sich auf das Prädikat beziehen, ordnen Sie sie in derselben Norm und Reihenfolge wie die Hilfswörter an, die durch Leerzeichen getrennt sind.
Betrachten Sie den Beispielsatz (8. Satz von neko.txt.cabocha), dass "ich hier zum ersten Mal einen Menschen gesehen habe". Dieser Satz enthält zwei Verben, "begin" und "see", und der Ausdruck "begin" wurde als "here" analysiert, und der Ausdruck zu "see" wurde als "I am" und "thing" analysiert. In diesem Fall sollte die Ausgabe wie folgt sein.
Fang hier an Sehen Sie, was ich sehe
def sorted_double_list(key_list: list, value_list: list) -> tuple:
"""
Nimmt zwei Listen als Argumente, diktiert eine Liste als Schlüssel und die andere Liste als Wert, sortiert nach Schlüssel, zerlegt sich dann in zwei Listen und kehrt als Taple zurück.
:param key_Liste Eine Schlüsselliste beim Sortieren
:param value_Liste sortiert nach Listenschlüssel
:return key_Zwei Listenlisten nach Liste sortiert
"""
double_list = list(zip(key_list, value_list))
double_list = dict(double_list)
double_list = sorted(double_list.items())
return [pair[0] for pair in double_list], [pair[1] for pair in double_list]
def case_frame_patterns(_chunked_sentences: list) -> list:
"""
Das Rahmenmuster für Verbfälle(Kombination von Verb und Hilfs)Gibt eine Liste von zurück.
:param _chunked_Sätze Eine Liste der nach Sätzen geordneten Morphologie
:Fallmuster zurückgeben(Zum Beispiel['Machen', ['Hand', 'Ist'], ['泣いHand', 'いた事だけIst']])Liste von
"""
_case_frame_patterns = []
for sentence in _chunked_sentences:
for _chunk in sentence:
if not _chunk.has_verb():
continue
clauses = [c.join_morphs() for c in sentence if c.dst == _chunk.srcs and c.has_particle()]
particles = [c.last_particle().base for c in sentence if c.dst == _chunk.srcs and c.has_particle()]
if len(particles) > 0:
_case_frame_patterns.append([_chunk.first_verb().base, *sorted_double_list(particles, clauses)])
return _case_frame_patterns
def save_case_frame_patterns(_case_frame_patterns: list, file_name: str) -> None:
"""
Verbfallmuster(Kombination von Verb und Hilfs)Speichern Sie die Liste in einer Datei.
:param _case_frame_Muster Fallrahmen(Zum Beispiel['Machen', ['Hand', 'Ist'], ['泣いHand', 'いた事だけIst']])Liste von
:param file_name Name der Zieldatei speichern
"""
with open(file_name, mode='w', encoding='utf-8') as output_file:
for case in _case_frame_patterns:
output_file.write('{}\t{}\t{}\n'.format(case[0], ' '.join(case[1]), ' '.join(case[2])))
save_case_frame_patterns(case_frame_patterns(chunked_sentences), 'case_frame_patterns.txt')
47. Mining der funktionalen Verbsyntax
Ich möchte nur dann aufpassen, wenn das Verb wo case ein sa-varianten-Verbindungsnomen enthält. Ändern Sie 46 Programme, um die folgenden Spezifikationen zu erfüllen.
- Nur wenn die Phrase, die aus "Sahen-Verbindungsnomen + (Hilfsverb)" besteht, mit dem Verb zusammenhängt
- Das Prädikat lautet "Sahen-Verbindungsnomen + ist die Grundform von + Verb". Wenn die Phrase mehrere Verben enthält, verwenden Sie das Verb ganz links.
- Wenn es mehrere Hilfswörter (Phrasen) gibt, die sich auf das Prädikat beziehen, ordnen Sie alle Hilfswörter in Wörterbuchreihenfolge an, die durch Leerzeichen getrennt sind.
- Wenn das Prädikat mehrere Klauseln enthält, ordnen Sie alle durch Leerzeichen getrennten Begriffe an (richten Sie sie nach der Reihenfolge der Hilfswörter aus).
Zum Beispiel sollte die folgende Ausgabe aus dem Satz "Der Meister wird auf den Brief antworten, auch wenn er an einen anderen Ort kommt" erhalten werden.
Wenn ich auf den Brief antworte, mein Mann
Speichern Sie die Ausgabe dieses Programms in einer Datei und überprüfen Sie die folgenden Elemente mit UNIX-Befehlen.
--Predikate, die häufig im Korpus vorkommen (Sahen-Verbindungsnomenklatur + + Verb) --Predikate und Verbmuster, die häufig im Korpus vorkommen
def sahen_case_frame_patterns(_chunked_sentences: list) -> list:
"""
Das Rahmenmuster für Verbfälle(Kombination von Verb und Hilfs)Gibt eine Liste von zurück.
:param _chunked_Sätze Eine Liste der nach Sätzen geordneten Morphologie
:Fallmuster zurückgeben(Zum Beispiel['Machen', ['Hand', 'Ist'], ['泣いHand', 'いた事だけIst']])Liste von
"""
_sahen_case_frame_patterns = []
for sentence in _chunked_sentences:
for _chunk in sentence:
if not _chunk.has_verb():
continue
sahen_connection_noun = [c.join_morphs() for c in sentence if c.dst == _chunk.srcs and c.has_sahen_connection_noun_plus_wo()]
clauses = [c.join_morphs() for c in sentence if c.dst == _chunk.srcs and not c.has_sahen_connection_noun_plus_wo() and c.has_particle()]
particles = [c.last_particle().base for c in sentence if c.dst == _chunk.srcs and not c.has_sahen_connection_noun_plus_wo() and c.has_particle()]
if len(sahen_connection_noun) > 0 and len(particles) > 0:
_sahen_case_frame_patterns.append([sahen_connection_noun[0] + _chunk.first_verb().base, *sorted_double_list(particles, clauses)])
return _sahen_case_frame_patterns
def save_sahen_case_frame_patterns(_sahen_case_frame_patterns: list, file_name: str) -> None:
"""
Verbfallmuster(Kombination von Verb und Hilfs)Speichern Sie die Liste in einer Datei.
:param _sahen_case_frame_Muster Fallrahmen(Zum Beispiel['Machen', ['Hand', 'Ist'], ['泣いHand', 'いた事だけIst']])Liste von
:param file_name Name der Zieldatei speichern
"""
with open(file_name, mode='w', encoding='utf-8') as output_file:
for case in _sahen_case_frame_patterns:
output_file.write('{}\t{}\t{}\n'.format(case[0], ' '.join(case[1]), ' '.join(case[2])))
save_sahen_case_frame_patterns(sahen_case_frame_patterns(chunked_sentences), 'sahen_case_frame_patterns.txt')
#Prädikate, die häufig im Korpus vorkommen+Zu+動詞)ZuUNIXコマンドZu用いて確認
print(subprocess.run('cat sahen_case_frame_patterns.txt | cut -f 1 | sort | uniq -c | sort -r | head -10', shell=True))
#Verwenden Sie UNIX-Befehle, um Prädikate und Verbmuster zu überprüfen, die häufig im Korpus vorkommen
print(subprocess.run('cat sahen_case_frame_patterns.txt | cut -f 1,2 | sort | uniq -c | sort -r | head -10', shell=True))
48. Extrahieren von Pfaden von der Nomenklatur zu den Wurzeln
Extrahieren Sie für eine Klausel, die die gesamte Nomenklatur des Satzes enthält, den Pfad von dieser Klausel zum Stamm des Syntaxbaums. Der Pfad im Syntaxbaum muss jedoch die folgenden Spezifikationen erfüllen.
- Jede Klausel wird durch eine (oberflächliche) morphologische Sequenz dargestellt
- Verketten Sie die Ausdrücke jeder Klausel mit "->" von der Startklausel bis zur Endklausel des Pfads.
Aus dem Satz "Ich habe hier zum ersten Mal einen Menschen gesehen" (8. Satz von neko.txt.cabocha) sollte die folgende Ausgabe erhalten werden.
ich bin->sah Hier->Beginnen mit->Mensch->Dinge->sah Mensch->Dinge->sah Dinge->sah
Sie können klar schreiben, indem Sie die Funktion rekursiv aufrufen.
def path_to_root(_chunk: Chunk, _sentence: list) -> list:
"""
Klausel als Argument angegeben(`_chunk`)Wenn if root ist, wird diese Klausel zurückgegeben.
Klausel als Argument angegeben(`_chunk`)Wenn nicht root, wird die Klausel und der Pfad von der Klausel, zu der sie gehört, als Liste zurückgegeben.
:param _Die Klausel, die der Ausgangspunkt für Chunk Root ist
:param _Satz Der zu analysierende Text
:return list _Pfad vom Block zur Wurzel
"""
if _chunk.dst == -1:
return [_chunk]
else:
return [_chunk] + path_to_root(_sentence[_chunk.dst], _sentence)
def join_chunks_by_arrow(_chunks: list) -> str:
return ' -> '.join([c.join_morphs() for c in _chunks])
#Geben Sie nur die ersten 10 Sätze aus und überprüfen Sie die Operation
for sentence in chunked_sentences[0:10]:
for chunk in sentence:
if chunk.has_noun():
print(join_chunks_by_arrow(path_to_root(chunk, sentence)))
49. Extraktion von Abhängigkeitspfaden zwischen Nomenklatur
Extrahieren Sie den kürzesten Abhängigkeitspfad, der alle Nomenklaturpaare im Satz verbindet. Wenn jedoch die Klauselnummern des Nomenklaturpaars i und j sind (i <j), muss der Abhängigkeitspfad die folgenden Spezifikationen erfüllen.
- Ähnlich wie bei Problem 48 wird der Pfad durch Verketten der Ausdrücke (oberflächenmorphologischen Elemente) jeder Phrase von der Startklausel bis zur Endklausel mit "->" ausgedrückt.
- Ersetzen Sie die in den Abschnitten i und j enthaltene Nomenklatur durch X bzw. Y.
Darüber hinaus kann die Form des Abhängigkeitspfads auf zwei Arten betrachtet werden.
--Wenn Klausel j im Pfad von Klausel i zum Stammverzeichnis des Syntaxbaums vorhanden ist: Zeigen Sie den Pfad von Klausel i zu Klausel j an
- Anders als oben, wenn sich Klausel i und Klausel j an einer gemeinsamen Klausel k auf dem Pfad von Klausel j zur Wurzel des Syntaxbaums überschneiden: der Pfad unmittelbar vor Klausel i zu Klausel k und der Pfad unmittelbar vor Klausel j zu Klausel k, Zeigen Sie den Inhalt von Klausel k an, indem Sie ihn mit "|" verketten.
Aus dem Satz "Ich habe hier zum ersten Mal einen Menschen gesehen" (8. Satz von neko.txt.cabocha) sollte beispielsweise die folgende Ausgabe erhalten werden.
X ist|In Y.->Beginnen mit->Mensch->Dinge|sah X ist|Genannt Y.->Dinge|sah X ist|Y.|sah In X.->Beginnen mit-> Y In X.->Beginnen mit->Mensch-> Y X genannt-> Y
Ich wusste nicht, was ich tun wollte, indem ich die Problemstellung las, aber 100 Verarbeitung natürlicher Sprache klopft an Kapitel 5 Abhängigkeitsanalyse (zweite Hälfte) und [Sprache] Verarbeitung von 100 Schlägen Ausgabe 2015 (46-49)](http://kenichia.hatenablog.com/entry/2016/02/11/221513) Ich habe gelesen und verstanden, dass dies der Fall ist.
Wenn Sie anfangen, den Code zu schreiben, während Sie das Problem auflösen, ohne es zu wissen, werden Sie es allmählich verstehen. Erklären Sie, wie Sie das Problem aufgeschlüsselt haben, indem Sie im folgenden Code ein wenig mehr Kommentare schreiben. Ich hoffe es wird hilfreich sein.
def noun_pairs(_sentence: list):
"""
Gibt eine Liste aller Paare zurück, die aus allen Nomenklaturklauseln des als Argument übergebenen Satzes gebildet werden können.
"""
from itertools import combinations
_noun_chunks = [_chunk for _chunk in _sentence if _chunk.has_noun()]
return list(combinations(_noun_chunks, 2))
def common_chunk(path_i: list, path_j: list) -> Chunk:
"""
Wenn sich Klausel i und Klausel j mit einer gemeinsamen Klausel k auf dem Pfad zur Wurzel des Syntaxbaums überschneiden, wird Klausel k zurückgegeben..
"""
_chunk_k = None
path_i = list(reversed(path_i))
path_j = list(reversed(path_j))
for idx, (c_i, c_j) in enumerate(zip(path_i, path_j)):
if c_i.srcs != c_j.srcs:
_chunk_k = path_i[idx - 1]
break
return _chunk_k
for sentence in chunked_sentences:
#Liste der Nomenklaturpaare
n_pairs = noun_pairs(sentence)
if len(n_pairs) == 0:
continue
for n_pair in n_pairs:
chunk_i, chunk_j = n_pair
#Ersetzen Sie die in den Abschnitten i und j enthaltene Nomenklatur durch X bzw. Y.
chunk_i.replace_noun('X')
chunk_j.replace_noun('Y')
#Pfad von den Klauseln i und j zu root(Chunk-Typ-Liste)
path_chunk_i_to_root = path_to_root(chunk_i, sentence)
path_chunk_j_to_root = path_to_root(chunk_j, sentence)
if chunk_j in path_chunk_i_to_root:
#Wenn Klausel j auf dem Pfad von Klausel i zum Stamm des Syntaxbaums vorhanden ist
#Index auf dem Pfad von Klausel i von Klausel j zum Stamm des Syntaxbaums
idx_j = path_chunk_i_to_root.index(chunk_j)
#Zeigen Sie den Pfad von Klausel i zu Klausel j
print(join_chunks_by_arrow(path_chunk_i_to_root[0: idx_j + 1]))
else:
#Anders als oben, wenn sich Klausel i und Klausel j an einer gemeinsamen Klausel k auf der Route von der Wurzel des Syntaxbaums überschneiden
#Get Klausel k
chunk_k = common_chunk(path_chunk_i_to_root, path_chunk_j_to_root)
if chunk_k is None:
continue
#Index auf dem Pfad von Klausel i von Klausel k zur Wurzel des Syntaxbaums
idx_k_i = path_chunk_i_to_root.index(chunk_k)
#Index auf dem Pfad von Klausel j von Klausel k zum Stamm des Syntaxbaums
idx_k_j = path_chunk_j_to_root.index(chunk_k)
#Der Pfad unmittelbar vor der Passage i zur Klausel k, der Pfad unmittelbar vor der Passage j zur Klausel k und der Inhalt der Klausel k"|"Anzeige durch Verbinden mit
print(' | '.join([join_chunks_by_arrow(path_chunk_i_to_root[0: idx_k_i]),
join_chunks_by_arrow(path_chunk_j_to_root[0: idx_k_j]),
chunk_k.join_morphs()]))
Recommended Posts