[PYTHON] 100 Sprachverarbeitung Knock 2020 Kapitel 6: Maschinelles Lernen
Neulich wurde 100 Language Processing Knock 2020 veröffentlicht. Ich selbst arbeite erst seit einem Jahr an natürlicher Sprache und kenne die Details nicht, aber ich werde alle Probleme lösen und veröffentlichen, um meine technischen Fähigkeiten zu verbessern.
Alle müssen auf dem Jupiter-Notizbuch ausgeführt werden, und die Einschränkungen der Problemstellung können bequem verletzt werden. Der Quellcode ist auch auf Github. Ja.
Kapitel 5 ist hier.
Die Umgebung ist Python 3.8.2 und Ubuntu 18.04.
Kapitel 6: Maschinelles Lernen
In diesem Kapitel verwenden wir den von Fabio Gasparetti veröffentlichten News Aggregator-Datensatz, um die Aufgabe (Kategorieklassifizierung) der Klassifizierung von Nachrichtenartikelüberschriften in die Kategorien "Business", "Wissenschaft und Technologie", "Unterhaltung" und "Gesundheit" zu bearbeiten.
Bitte laden Sie den erforderlichen Datensatz von [hier] herunter (https://nlp100.github.io/ja/ch06.html).
Die heruntergeladene Datei wird unter "Daten" abgelegt.
50. Daten erhalten und gestalten
Laden Sie den News Aggregator-Datensatz herunter und erstellen Sie die folgenden Trainingsdaten (train.txt), Verifizierungsdaten (valid.txt) und Bewertungsdaten (test.txt).
- Entpacken Sie die heruntergeladene Zip-Datei und lesen Sie die Erklärung zu readme.txt.
- Extrahieren Sie nur Fälle (Artikel), in denen die Informationsquelle (Herausgeber) "Reuters", "Huffington Post", "Businessweek", "Contactmusic.com", "Daily Mail" ist.
- Sortieren Sie die extrahierten Fälle nach dem Zufallsprinzip.
- Teilen Sie 80% der extrahierten Fälle in Trainingsdaten und die restlichen 10% in Verifizierungsdaten und Bewertungsdaten auf und speichern Sie sie unter den Dateinamen train.txt, valid.txt bzw. test.txt. Schreiben Sie einen Fall pro Zeile in die Datei und verwenden Sie ein durch Tabulatoren getrenntes Format für Kategorienamen und Artikelüberschriften. Überprüfen Sie nach dem Erstellen der Trainingsdaten und Bewertungsdaten die Anzahl der Fälle in jeder Kategorie.
Lesen Sie den Datensatz aus der Zip-Datei.
Code
import zipfile
Code
#Aus Zip-Datei lesen
with zipfile.ZipFile('data/NewsAggregatorDataset.zip') as f:
with f.open('newsCorpora.csv') as g:
data = g.read()
#Byte-String dekodieren
data = data.decode('UTF-8').splitlines()
#Tabulator begrenzt
data = [line.split('\t') for line in data]
len(data)
Ausgabe
422937
Geben Sie die Informationsquelle an und sortieren Sie sie nach dem Zufallsprinzip.
Code
publishers = {
'Reuters',
'Huffington Post',
'Businessweek',
'Contactmusic.com',
'Daily Mail',
}
data = [
lst
for lst in data
if lst[3] in publishers
]
data.sort()
len(data)
Ausgabe
13356
Verwerfen Sie alle außer dem Kategorienamen und der Artikelüberschrift.
Code
data = [
[lst[4], lst[1]]
for lst in data
]
Teilen Sie in Lern- / Verifizierungs- / Bewertungsdaten auf. sklearn hat eine Funktion mit einer ähnlichen Funktion, aber es ist nicht so schwierig, in die Black Box zu gelangen. Geben Sie einfach den Ort an, an dem ausgeschnitten und geschnitten werden soll.
Code
train_end = int(len(data) * 0.8)
valid_end = int(len(data) * 0.9)
train = data[:train_end]
valid = data[train_end:valid_end]
test = data[valid_end:]
print('Trainingsdaten', len(train))
print('Validierungsdaten', len(valid))
print('Bewertungsdaten', len(test))
Ausgabe
Trainingsdaten 10684
Validierungsdaten 1336
Bewertungsdaten 1336
In einer Datei speichern.
Code
def write_dataset(filename, data):
with open(filename, 'w') as f:
for lst in data:
print('\t'.join(lst), file = f)
Code
write_dataset('../train.txt', train)
write_dataset('../valid.txt', valid)
write_dataset('../test.txt', test)
Überprüfen Sie die Anzahl der Fälle für jede Kategorie.
Code
from collections import Counter
from tabulate import tabulate
Code
categories = ['b', 't', 'e', 'm']
category_names = ['business', 'science and technology', 'entertainment', 'health']
table = [
[name] + [freqs[cat] for cat in categories]
for name, freqs in [
('train', Counter([cat for cat, _ in train])),
('valid', Counter([cat for cat, _ in valid])),
('test', Counter([cat for cat, _ in test])),
]
]
tabulate(table, headers = categories)
Ausgabe
b t e m
----- ---- ---- ---- ---
train 4463 1223 4277 721
valid 617 168 459 92
test 547 134 558 97
51. Merkmalsextraktion
Extrahieren Sie die Funktionen aus den Trainingsdaten, Verifizierungsdaten und Bewertungsdaten und speichern Sie sie unter den Dateinamen train.feature.txt, valid.feature.txt und test.feature.txt (diese Datei wird später in Frage 70 wiederverwendet). Machen). Schreiben Sie einen Fall pro Zeile in die Datei und verwenden Sie ein durch Leerzeichen getrenntes Format für Kategorienamen und Artikelüberschriften. Entwerfen Sie die Funktionen, die für die Kategorisierung wahrscheinlich nützlich sind. Die minimale Grundlinie wäre eine Artikelüberschrift, die in eine Wortfolge konvertiert wird.
Es scheint, dass tf-idf oder ein Wortvektor verwendet werden können, aber da die Dunkelheit der Merkmalsextraktion unendlich tief ist, möchte ich im flachen Wasser gestrandet sein. Mit anderen Worten, Bag-of-Words.
Code
import re
import spacy
import nltk
Teilen Sie es in Wortketten und machen Sie sie niedriger und Stamm.
Code
nlp = spacy.load('en')
stemmer = nltk.stem.snowball.SnowballStemmer(language='english')
def tokenize(x):
x = re.sub(r'\s+', ' ', x)
x = nlp.make_doc(x) # nlp(x)Weil es anders als der langsame Tokenizer läuft
x = [stemmer.stem(doc.lemma_.lower()) for doc in x]
return x
Code
tokenized_train = [[cat, tokenize(line)] for cat, line in train]
tokenized_valid = [[cat, tokenize(line)] for cat, line in valid]
tokenized_test = [[cat, tokenize(line)] for cat, line in test]
Extrahieren Sie Token, die als Merkmalsmengen verwendet werden sollen.
Code
#Zählen Sie die Häufigkeit des Auftretens
counter = Counter([
token
for _, tokens in tokenized_train
for token in tokens
])
#Entfernen Sie hoch- und niederfrequente Wörter
vocab = [
token
for token, freq in counter.most_common()
if 2 < freq < 300
]
len(vocab)
Ausgabe
4790
Bi-Gramm ist auch eine Merkmalsmenge. Die USA und wir sind aufgrund der Senkung gleich geworden, aber wenn Bi-Gramm enthalten ist, wird "US-Lagerbestand" als Merkmalsmenge wirksam.
Code
bi_grams = Counter([
bi_gram
for _, sent in tokenized_train
for bi_gram in zip(sent, sent[1:])
]).most_common()
bi_grams = [tup for tup, freq in bi_grams if freq > 4]
len(bi_grams)
Ausgabe
3094
du sparst.
Code
with open('result/vocab_for_news.txt', 'w') as f:
for token in vocab:
print(token, file = f)
Code
with open('result/bi_grams_for_news.txt', 'w') as f:
for tup in bi_grams:
print(' '.join(tup), file = f)
Gesamtfunktionen
Code
features = vocab + [' '.join(x) for x in bi_grams]
len(features)
Ausgabe
7884
Extrahieren Sie den Funktionsbetrag und speichern Sie ihn.
Code
import numpy as np
Code
vocab_dict = {x:n for n, x in enumerate(vocab)}
bi_gram_dict = {x:n for n, x in enumerate(bi_grams)}
def count_uni_gram(sent):
lst = [0 for token in vocab]
for token in sent:
if token in vocab_dict:
lst[vocab_dict[token]] += 1
return lst
def count_bi_gram(sent):
lst = [0 for token in bi_grams]
for tup in zip(sent, sent[1:]):
if tup in bi_gram_dict:
lst[bi_gram_dict[tup]] += 1
return lst
Code
def prepare_feature_dataset(data):
ts = [categories.index(cat) for cat, _ in data]
xs = [
count_uni_gram(sent) + count_bi_gram(sent)
for _, sent in data
]
return np.array(xs, dtype=np.float32), np.array(ts, dtype=np.int8)
def write_feature_dataset(filename, xs, ts):
with open(filename, 'w') as f:
for t, x in zip(ts, xs):
line = categories[t] + ' ' + ' '.join([str(int(n)) for n in x])
print(line, file = f)
Code
train_x, train_t = prepare_feature_dataset(tokenized_train)
valid_x, valid_t = prepare_feature_dataset(tokenized_valid)
test_x, test_t = prepare_feature_dataset(tokenized_test)
Code
write_feature_dataset('result/train.feature.txt', train_x, train_t)
write_feature_dataset('result/valid.feature.txt', valid_x, valid_t)
write_feature_dataset('result/test.feature.txt', test_x, test_t)
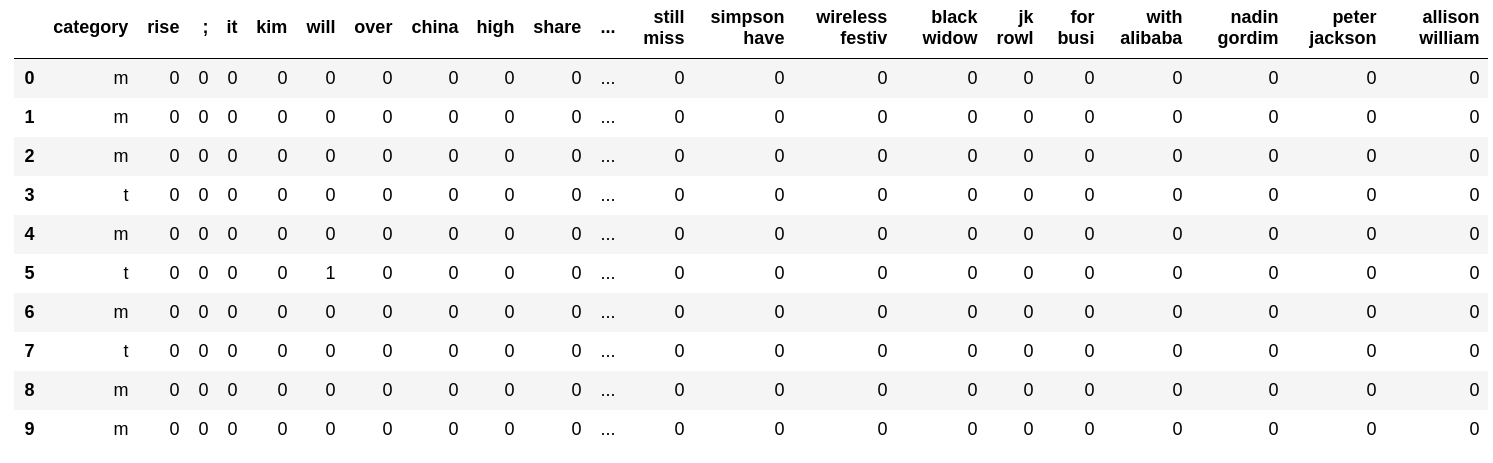
Schauen wir uns ein Beispiel an.
Code
import pandas as pd
Code
with open('result/train.feature.txt') as f:
table = [line.strip().split(' ') for _, line in zip(range(10), f)]
pd.DataFrame(table, columns=['category'] + features)
52. Lernen
Lernen Sie das logistische Regressionsmodell anhand der in> 51 erstellten Trainingsdaten.
Verwenden Sie sklearn.
Es ist so einfach wie die Implementierung einer logistischen Regression mit der Methode des steilsten Abstiegs. Wenn Sie jedoch versuchen, die Quasi-Newton-Methode zu kratzen, wird Ihr Herz durch die Hessen-Matrix gebrochen und Ihr Herz bricht um die lineare Suche herum, sodass Sie täglich eine schwere mentale Belastung haben. Es wird nicht für Menschen empfohlen. Dies ist eine Erfahrungsgeschichte, aber es besteht die Gefahr, dass seltsame Dinge ausgeführt werden, z. B. das Rollen der Aluminiumfolie und das Anhalten dort, wo die Bedingungen für die Aluminiumfolie erfüllt sind. Auf der anderen Seite kann Scikit-Learn auch im Schlaf eingesetzt werden.
Code
from sklearn.linear_model import LogisticRegression
Code
lr = LogisticRegression(max_iter=1000)
lr.fit(train_x, train_t)
Ausgabe
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
Sie können es auch tun, wenn Sie schlafen, weil Sie ein Modell erstellen und es anpassen () können. Es ist sehr leicht.
53. Prognose
Verwenden Sie das in> 52 erlernte logistische Regressionsmodell und implementieren Sie ein Programm, das die Kategorie und ihre Vorhersagewahrscheinlichkeit aus der angegebenen Artikelüberschrift berechnet.
Code
def predict(x):
out = lr.predict_proba(x)
preds = out.argmax(axis=1)
probs = out.max(axis=1)
return preds, probs
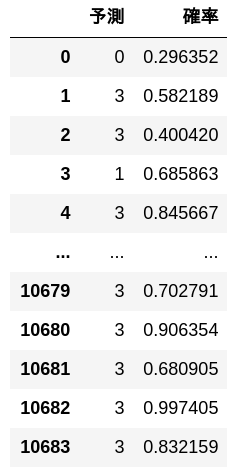
Vorausgesagt durch Trainingsdaten.
Code
preds, probs = predict(train_x)
pd.DataFrame([[y, p] for y, p in zip(preds, probs)], columns = ['Prognose', 'Wahrscheinlichkeit'])
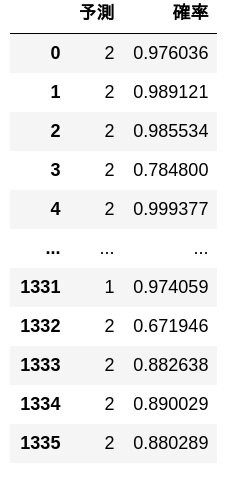
Vorausgesagt durch Bewertungsdaten.
Code
preds, probs = predict(test_x)
pd.DataFrame([[y, p] for y, p in zip(preds, probs)], columns = ['Prognose', 'Wahrscheinlichkeit'])
54. Messung der richtigen Antwortrate
Messen Sie die korrekte Antwortrate des in> 52 erlernten logistischen Regressionsmodells anhand der Trainingsdaten und Bewertungsdaten.
Code
def accuracy(lr, xs, ts):
ys = lr.predict(xs)
return (ys == ts).mean()
Code
print('Trainingsdaten')
print(accuracy(lr, train_x, train_t))
Ausgabe
Trainingsdaten
0.994664919505803
Code
print('Bewertungsdaten')
print(accuracy(lr, test_x, test_t))
Ausgabe
Bewertungsdaten
0.906437125748503
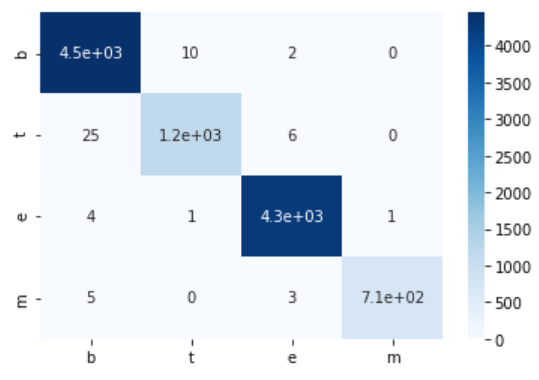
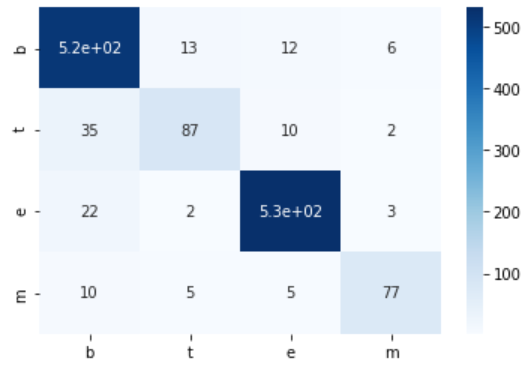
55. Erstellen einer Verwirrungsmatrix
Erstellen Sie eine Verwirrungsmatrix des in> 52 erlernten logistischen Regressionsmodells für die Trainingsdaten und Bewertungsdaten.
Sie werden glücklich sein, wenn Sie Seaborn verwenden. Ich denke, c in der Verwirrungsmatrix ist das Meer des Meeres geboren.
Code
import seaborn as sns
Code
def confusion_matrix(xs, ts):
num_class = np.unique(ts).size
mat = np.zeros((num_class, num_class), dtype=np.int32)
ys = lr.predict(xs)
for y, t in zip(ys, ts):
mat[t, y] += 1
return mat
def show_cm(cm):
sns.heatmap(cm, annot=True, cmap = 'Blues', xticklabels = categories, yticklabels = categories)
Code
train_cm = confusion_matrix(train_x, train_t)
print('Trainingsdaten')
print(train_cm)
show_cm(train_cm)
Ausgabe
Trainingsdaten
[[4451 10 2 0]
[ 25 1192 6 0]
[ 4 1 4271 1]
[ 5 0 3 713]]
Code
test_cm = confusion_matrix(test_x, test_t)
print('Bewertungsdaten')
print(test_cm)
show_cm(test_cm)
Ausgabe
Bewertungsdaten
[[516 13 12 6]
[ 35 87 10 2]
[ 22 2 531 3]
[ 10 5 5 77]]
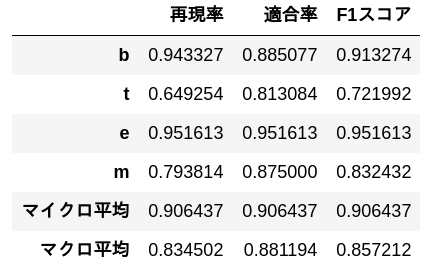
56. Messung von Präzision, Rückruf und F1-Punktzahl
Messen Sie die Genauigkeit, den Rückruf und die F1-Bewertung des logistischen Regressionsmodells, das in> 52 anhand der Bewertungsdaten gelernt wurde. Ermitteln Sie die Genauigkeitsrate, Rückrufrate und F1-Punktzahl für jede Kategorie und integrieren Sie die Leistung für jede Kategorie in den Mikro- und Makro-Durchschnitt.
Es gibt eine Funktion, die die gleiche Verarbeitung in sklearn ausführt, aber ich bin in der Lage, dies selbst zu implementieren. Einige Aufgaben verwenden den Wert $ F_ {0.5} $, und ich denke, es ist besser, ihn selbst zu schreiben.
Code
tp = test_cm.diagonal()
tn = test_cm.sum(axis=1) - tp
fp = test_cm.sum(axis=0) - tp
Code
p = tp / (tp + tn)
r = tp / (tp + fp)
F = 2 * p * r / (p + r)
Code
micro_p = tp.sum() / (tp + tn).sum()
micro_r = tp.sum() / (tp + fp).sum()
micro_F = 2 * micro_p * micro_r / (micro_p + micro_r)
micro_ave = np.array([micro_p, micro_r, micro_F])
Code
macro_p = p.mean()
macro_r = r.mean()
macro_F = 2 * macro_p * macro_r / (macro_p + macro_r)
macro_ave = np.array([macro_p, macro_r, macro_F])
Code
table = np.array([p, r, F]).T
table = np.vstack([table, micro_ave, macro_ave])
pd.DataFrame(
table,
index = categories + ['Mikrodurchschnitt'] + ['Makro-Durchschnitt'],
columns = ['Erinnern', 'Compliance-Rate', 'F1-Punktzahl'])
57. Bestätigung des Merkmalsgewichts
Überprüfen Sie die Top-10-Features mit hohen Gewichten und die Top-10-Features mit niedrigen Gewichten im logistischen Regressionsmodell, das in> 52 gelernt wurde.
Code
def show_weight(directional, N):
for i, cat in enumerate(categories):
indices = lr.coef_[i].argsort()[::directional][:N]
best = np.array(features)[indices]
weight = lr.coef_[i][indices]
print(category_names[i])
display(pd.DataFrame([best, weight], index = ['Funktionswert', 'Gewicht'], columns = np.arange(N) + 1))
Top 10 Features mit großem Gewicht
Code
show_weight(-1, 10)

Code
show_weight(1, 10)
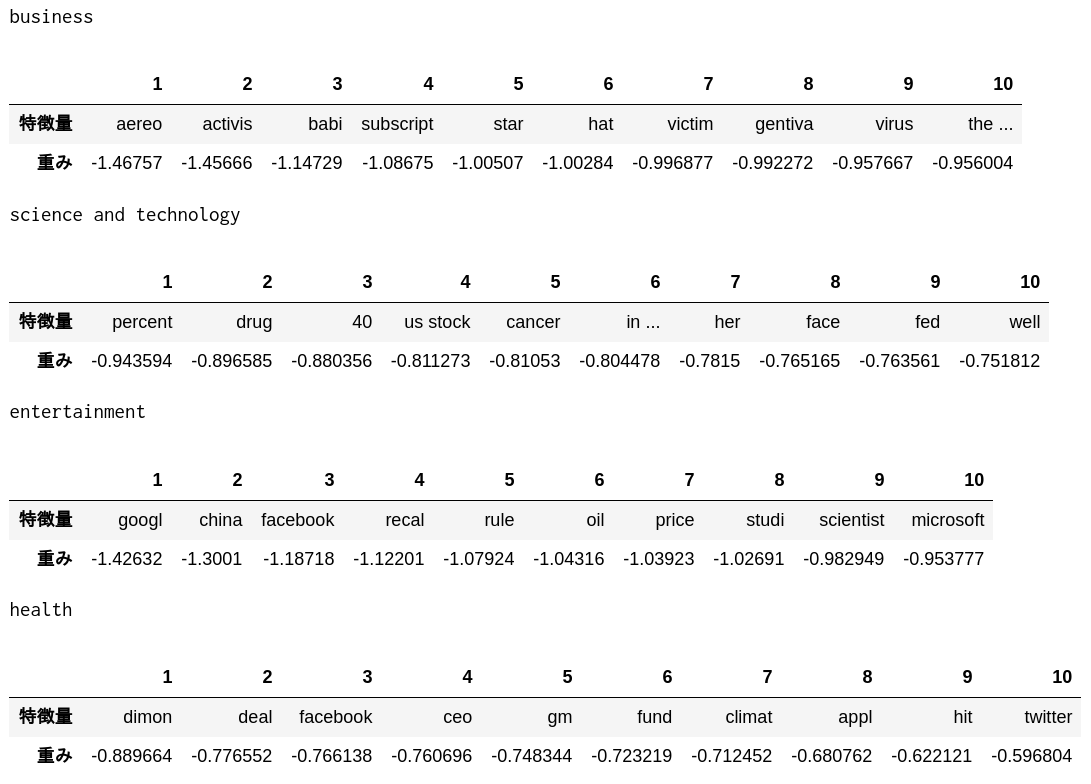
Es scheint, dass eine solche Merkmalsmenge extrahiert wurde.
58. Ändern Sie die Regularisierungsparameter
Beim Training eines logistischen Regressionsmodells kann der Grad der Überanpassung während des Trainings durch Anpassen der Regularisierungsparameter gesteuert werden. Lernen Sie das logistische Regressionsmodell mit verschiedenen Regularisierungsparametern und finden Sie die richtige Antwortrate für die Trainingsdaten, Validierungsdaten und Bewertungsdaten. Fassen Sie die Ergebnisse des Experiments in einem Diagramm mit den Regularisierungsparametern auf der horizontalen Achse und der Genauigkeitsrate auf der vertikalen Achse zusammen.
Code
import matplotlib.pyplot as plt
import japanize_matplotlib
from tqdm import tqdm
Da es einige Zeit dauert, überwachen Sie mit tqdm.tqdm.
Code
Cs = np.arange(0.1, 5.1, 0.1)
lrs = [LogisticRegression(C=C, max_iter=1000).fit(train_x, train_t) for C in tqdm(Cs)]
Code
train_accs = [accuracy(lr, train_x, train_t) for lr in lrs]
valid_accs = [accuracy(lr, valid_x, valid_t) for lr in lrs]
test_accs = [accuracy(lr, test_x, test_t) for lr in lrs]
Code
plt.plot(Cs, train_accs, label = 'Lernen')
plt.plot(Cs, valid_accs, label = 'Überprüfung')
plt.plot(Cs, test_accs, label = 'Auswertung')
plt.legend()
plt.show()
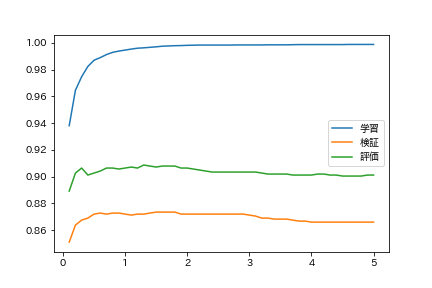
Sie lernen zu viel, dass die Regularisierung schwach ist.
59. Suche nach Hyperparametern
Lernen Sie das Kategorisierungsmodell, während Sie den Lernalgorithmus und die Lernparameter ändern. Suchen Sie den Lernalgorithmusparameter, der die höchste Genauigkeitsrate für die Bewertungsdaten ergibt.
Lassen Sie uns den Cutoff-Fehler ändern.
Code
tols = np.logspace(0, 2, 50)
lrs = [LogisticRegression(tol=tol, max_iter=1000).fit(train_x, train_t) for tol in tqdm(tols)]
Code
train_accs = [accuracy(lr, train_x, train_t) for lr in lrs]
valid_accs = [accuracy(lr, valid_x, valid_t) for lr in lrs]
test_accs = [accuracy(lr, test_x, test_t) for lr in lrs]
Code
plt.plot(tols, train_accs, label = 'Lernen')
plt.plot(tols, valid_accs, label = 'Überprüfung')
plt.plot(tols, test_accs, label = 'Auswertung')
plt.xscale('log')
plt.legend()
plt.show()
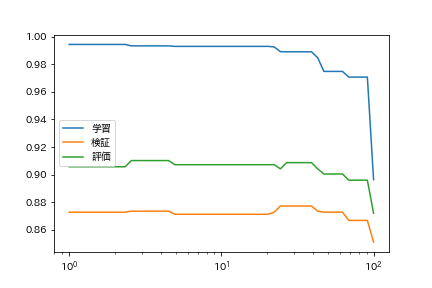
Ich würde gerne etwas anderes als logistische Regression versuchen.
Wenn ich mir das berühmte Flussdiagramm von sklearn ansehe, habe ich das Gefühl, dass etwas nicht stimmt.

Naive Buchten
Code
from sklearn.naive_bayes import MultinomialNB
Code
nb = MultinomialNB()
nb.fit(train_x, train_t)
Ausgabe
MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
Code
accuracy(nb, train_x, train_t)
Ausgabe
0.9429988768251591
Code
accuracy(nb, test_x, test_t)
Ausgabe
0.8907185628742516
Textklassifizierung COSPA stärkste naive Buchten
Lineare Stützvektormaschine
Code
from sklearn.svm import LinearSVC
Code
svc = LinearSVC(C=0.1)
svc.fit(train_x,train_t)
Ausgabe
LinearSVC(C=0.1, class_weight=None, dual=True, fit_intercept=True,
intercept_scaling=1, loss='squared_hinge', max_iter=1000,
multi_class='ovr', penalty='l2', random_state=None, tol=0.0001,
verbose=0)
Code
accuracy(svc, train_x, train_t)
Ausgabe
0.9908274054661176
Code
accuracy(svc, test_x, test_t)
Ausgabe
0.9041916167664671
Es ist sehr gut.
Als nächstes folgt Kapitel 7
Sprachverarbeitung 100 Schläge 2020 Kapitel 7: Wortvektor
Recommended Posts