[PYTHON] 100 Sprachverarbeitung Knock 2020 Kapitel 5: Abhängigkeitsanalyse
Neulich wurde 100 Language Processing Knock 2020 veröffentlicht. Ich selbst arbeite erst seit einem Jahr an natürlicher Sprache und kenne die Details nicht, aber ich werde alle Probleme lösen und veröffentlichen, um meine technischen Fähigkeiten zu verbessern.
Alle müssen auf dem Jupyter-Notizbuch ausgeführt werden, und die Einschränkungen der Problemstellung können bequem verletzt werden. Der Quellcode ist auch auf Github. Ja.
Kapitel 4 ist hier.
Die Umgebung ist Python 3.8.2 und Ubuntu 18.04.
Kapitel 5: Abhängigkeitsanalyse
Verwenden Sie CaboCha, um den Text (neko.txt) von Natsume Sosekis Roman "Ich bin eine Katze" abhängig zu machen und zu analysieren, und speichern Sie das Ergebnis in einer Datei namens neko.txt.cabocha. Verwenden Sie diese Datei, um ein Programm zu implementieren, das die folgenden Fragen beantwortet.
Bitte laden Sie den erforderlichen Datensatz von [hier] herunter (https://nlp100.github.io/ja/ch05.html).
Die heruntergeladene Datei wird unter "Daten" abgelegt.
Abhängigkeitsanalyse mit CaboCha
Code
cat data/neko.txt | cabocha -f3 > data/neko.txt.cabocha
Sie können in verschiedenen Formaten ausgeben, indem Sie die Option f angeben. Diesmal habe ich jedoch das XML-Format gewählt.
40. Lesen des Abhängigkeitsanalyseergebnisses (Morphologie)
Implementieren Sie die Klasse Morph, die die Morphologie darstellt. Diese Klasse hat eine Oberflächenform (Oberfläche), eine Basisform (Basis), ein Teilwort (pos) und eine Teilwortunterklassifikation 1 (pos1) als Elementvariablen. Lesen Sie außerdem das Analyseergebnis von CaboCha (neko.txt.cabocha), drücken Sie jeden Satz als Liste von Morph-Objekten aus und zeigen Sie die morphologische Elementzeichenfolge des dritten Satzes an.
Eine Implementierung der Klasse "Morph", die die Morphologie darstellt.
Code
class Morph:
def __init__(self, token):
self.surface = token.text
feature = token.attrib['feature'].split(',')
self.base = feature[6]
self.pos = feature[0]
self.pos1 = feature[1]
def __repr__(self):
return self.surface
XML lesen.
Code
import xml.etree.ElementTree as ET
with open("neko.txt.cabocha") as f:
root = ET.fromstring("<sentences>" + f.read() + "</sentences>")
Erstellen Sie eine Liste von Morphs für jeden Satz und speichern Sie sie in der Neko-Liste.
Code
neko = []
for sent in root:
sent = [chunk for chunk in sent]
sent = [Morph(token) for chunk in sent for token in chunk]
neko.append(sent)
Die dritte morphologische Sequenz von der Vorderseite von "Neko" ist gezeigt.
Code
for x in neko[2]:
print(x)
Wenn Sie ein Objekt der Klasse "Morph" "drucken", wird "repr" aufgerufen und die Oberflächenform angezeigt.
Ausgabe
ich
Ist
Katze
damit
Gibt es
。
41. Lesen des Abhängigkeitsanalyseergebnisses (Phrase / Abhängigkeit)
Implementieren Sie zusätzlich zu> 40 die Klauselklasse Chunk. Diese Klasse enthält eine Liste von Morph-Elementen (Morph-Objekten) (Morphs), eine Liste verwandter Klauselindexnummern (dst) und eine Liste verwandter ursprünglicher Klauselindexnummern (srcs) als Mitgliedsvariablen. Lesen Sie außerdem das Analyseergebnis von CaboCha des Eingabetextes, drücken Sie einen Satz als Liste von Chunk-Objekten aus und zeigen Sie die Zeichenfolge und den Kontakt der Phrase des achten Satzes an. Verwenden Sie für die restlichen Probleme in Kapitel 5 das hier erstellte Programm.
Erstellen Sie eine Blockklasse und eine Satzklasse. Blockkontakte werden nicht beim Erstellen eines Blockobjekts erstellt, sondern beim Erstellen eines Anweisungsobjekts.
Chunks und Anweisungen erben den Listentyp und können als Liste von Morphologie- bzw. Chunks behandelt werden.
Code
import re
class Chunk(list):
def __init__(self, chunk):
self.morphs = [Morph(morph) for morph in chunk]
super().__init__(self.morphs)
self.dst = int(chunk.attrib['link'])
self.srcs = []
def __repr__(self): #Wird in Q42 verwendet
return re.sub(r'[、。]', '', ''.join(map(str, self)))
Chunks werden mit __repr__ in eine Folge verketteter morphologischer Elemente konvertiert.
Zu diesem Zeitpunkt werden die Satzzeichen gemäß der Einschränkung von Problem 42 entfernt.
Code
class Sentence(list):
def __init__(self, sent):
self.chunks = [Chunk(chunk) for chunk in sent]
super().__init__(self.chunks)
for i, chunk in enumerate(self.chunks):
if chunk.dst != -1:
self.chunks[chunk.dst].srcs.append(i)
Code
neko = [Sentence(sent) for sent in root]
Jetzt können Sie die Analyseergebnisse für jeden Satz in der Liste speichern.
Code
from tabulate import tabulate
Verwenden Sie tabulate.tabulate, um es für eine einfache Anzeige anzuzeigen.
Code
table = [
[''.join([morph.surface for morph in chunk]), chunk.dst]
for chunk in neko[7]
]
tabulate(table, tablefmt = 'html', headers = ['Nummer', 'Phrase', 'Kontakt'], showindex = 'always')
Ausgabe
Nummernklausel
------ ---------- --------
0 Ich bin 5
1 hier 2
2 zum ersten Mal 3
3 Mensch 4
4 Dinge 5
5 sah.-1
42. Anzeige des Satzes der betroffenen Person und der betroffenen Person
Extrahieren Sie den gesamten Text der ursprünglichen Klausel und der zugehörigen Klausel in tabulatorgetrenntem Format. Geben Sie jedoch keine Symbole wie Satzzeichen aus.
Code
sent = neko[7]
for chunk in sent:
if chunk.dst != -1:
src = chunk
dst = sent[chunk.dst]
print(f'{src}\t{dst}')
Sie müssen lediglich die Chunks und die Chunks, denen sie zugeordnet sind, als Zeichenfolgen für jeden Chunk anzeigen.
Ausgabe
ich sah
Zum ersten Mal hier
Zum ersten Mal Mensch genannt
Menschen
ich habe etwas gesehen
43. Extrahieren Sie Klauseln mit Nomenklaturen in Bezug auf Klauseln mit Verben
Wenn sich Klauseln mit Nomenklatur auf Klauseln mit Verben beziehen, extrahieren Sie sie in tabulatorgetrennten Formaten. Geben Sie jedoch keine Symbole wie Satzzeichen aus.
Code
def has_noun(chunk):
return any(morph.pos == 'Substantiv' for morph in chunk)
def has_verb(chunk):
return any(morph.pos == 'Verb' for morph in chunk)
Code
sent = neko[7]
for chunk in sent:
if chunk.dst != -1 and has_noun(chunk) and has_verb(sent[chunk.dst]):
src = chunk
dst = sent[chunk.dst]
print(f'{src}\t{dst}')
Erstellen Sie eine Funktion, um festzustellen, ob ein Block Nomenklatur und Verben enthält, und zeigen Sie nur diejenigen an, die den Bedingungen entsprechen.
Ausgabe
ich sah
Zum ersten Mal hier
ich habe etwas gesehen
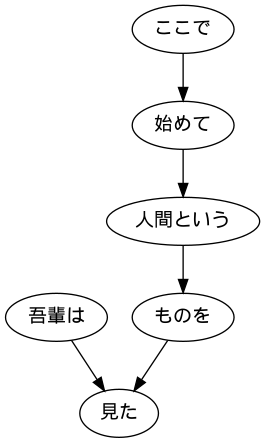
44. Visualisierung abhängiger Bäume
Visualisieren Sie den Abhängigkeitsbaum eines bestimmten Satzes als gerichteten Graphen. Zur Visualisierung ist es ratsam, den Abhängigkeitsbaum in die DOT-Sprache zu konvertieren und Graphviz zu verwenden. Verwenden Sie pydot, um gerichtete Diagramme direkt aus Python zu visualisieren.
Code
from pydot import Dot, Edge, Node
from PIL import Image
Code
sent = neko[7]
graph = Dot(graph_type = 'digraph')
#Machen Sie einen Knoten
for i, chunk in enumerate(sent):
node = Node(i, label = chunk)
graph.add_node(node)
#Machen Sie einen Zweig
for i, chunk in enumerate(sent):
if chunk.dst != -1:
edge = Edge(i, chunk.dst)
graph.add_edge(edge)
graph.write_png('sent.png')
Image.open('sent.png')
45. Extraktion von Verbfallmustern
Ich möchte den diesmal verwendeten Satz als Korpus betrachten und die möglichen Fälle japanischer Prädikate untersuchen. Stellen Sie sich das Verb als Prädikat und das Hilfsverb der Phrase, die sich auf das Verb bezieht, als Fall vor und geben Sie das Prädikat und den Fall in einem durch Tabulatoren getrennten Format aus. Stellen Sie jedoch sicher, dass die Ausgabe den folgenden Spezifikationen entspricht.
・ Verwenden Sie in einer Phrase, die ein Verb enthält, die Grundform des Verbs ganz links als Prädikat ・ Verwenden Sie die Hilfswörter für das Prädikat ・ Wenn das Prädikat mehrere Hilfswörter (Phrasen) enthält, ordnen Sie alle Hilfswörter in Wörterbuchreihenfolge an, die durch Leerzeichen getrennt sind. Betrachten Sie den Beispielsatz (8. Satz von neko.txt.cabocha), dass "ich hier zum ersten Mal einen Menschen gesehen habe". Dieser Satz enthielt zwei Verben, "begin" und "see", und die Phrase, die sich auf "begin" bezog, wurde als "here" analysiert, und die Phrase, die sich auf> "see" bezog, wurde als "I am" und "thing" analysiert. In diesem Fall sollte die Ausgabe wie folgt sein.
Starten Siehe Speichern Sie die Ausgabe dieses Programms in einer Datei und überprüfen Sie die folgenden Elemente mit UNIX-Befehlen.
・ Kombination von Prädikaten und Fallmustern, die häufig im Korpus vorkommen ・ Fallmuster der Verben "do", "see" und "give" (in der Reihenfolge der Häufigkeit des Auftretens im Korpus anordnen)
Code
def get_first_verb(chunk):
for morph in chunk:
if morph.pos == 'Verb':
return morph.base
def get_last_case(chunk):
for morph in chunk[::-1]:
if morph.pos == 'Partikel':
return morph.surface
def extract_cases(srcs):
xs = [get_last_case(src) for src in srcs]
xs = [x for x in xs if x]
xs.sort()
return xs
Bestimmen Sie, ob der Block mit einem Verb beginnt, und extrahieren Sie das Verb des ursprünglichen Blocks.
Code
with open('result/case_pattern.txt', 'w') as f:
for sent in neko:
for chunk in sent:
if verb := get_first_verb(chunk): #Beginnen Sie mit einem Verb
srcs = [sent[src] for src in chunk.srcs]
if cases := extract_cases(srcs): #Es gibt einen Assistenten
line = '{}\t{}'.format(verb, ' '.join(cases))
print(line, file=f)
Code
cat result/case_pattern.txt | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
Ausgabe
2645
1559 Tsukuka
840
553
380 greifen
Ich denke
334 zu sehen
257
253
Bis es 205 gibt
Code
cat result/case_pattern.txt | grep 'Machen' | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
Ausgabe
1239
806
313
140
Bis 102
84 Was ist
59
32
32
24 as
Code
cat result/case_pattern.txt | grep 'sehen' | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
Ausgabe
334 zu sehen
121 Siehe
40 zu sehen
25
23 vom Sehen
12 Sehen
8 zu sehen
7 Weil ich sehe
3 Ich schaue nur
3 Betrachten Sie es
Code
cat result/case_pattern.txt | grep 'geben' | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
Ausgabe
7 zu geben
4 zu geben
3 Was zu geben
Gib 1 aber gib
1 Wie zu geben
1 zu geben
1 zu geben
46. Extraktion von Verbfallrahmeninformationen
Ändern Sie das Programm> 45 und geben Sie die Begriffe (die Klauseln, die sich auf die Prädikate selbst beziehen) in tabulatorgetrennten Formaten aus, wobei Sie den Prädikaten und Fallmustern folgen. Erfüllen Sie zusätzlich zu den 45 Spezifikationen die folgenden Spezifikationen.
・ Der Begriff ist eine Wortfolge der Phrase, die sich auf das Prädikat bezieht (das nachfolgende Hilfswort muss nicht entfernt werden). ・ Wenn es mehrere Klauseln gibt, die sich auf das Prädikat beziehen, ordnen Sie sie in derselben Norm und Reihenfolge wie die Hilfswörter an, die durch Leerzeichen getrennt sind. Betrachten Sie den Beispielsatz (8. Satz von neko.txt.cabocha), dass "ich hier zum ersten Mal einen Menschen gesehen habe". Dieser Satz enthält zwei Verben, "begin" und "see", und die Phrase, die sich auf "begin" bezieht, wird als "here" analysiert, und die Phrase, die sich auf "see" bezieht, wird als "I am" und "thing" analysiert. Sollte die folgende Ausgabe erzeugen.
Beginnen Sie hier Sehen Sie, was ich sehe
Code
def extract_args(srcs):
xs = [src for src in srcs if get_last_case(src)]
xs.sort(key = lambda src : get_last_case(src))
xs = [str(src) for src in xs]
return xs
Ändern Sie den Code in Frage 45, um auch den Originalblock anzuzeigen.
Code
for sent in neko[:10]:
for chunk in sent:
if verb := get_first_verb(chunk): #Beginnt mit einem Verb
srcs = [sent[src] for src in chunk.srcs]
if cases := extract_cases(srcs): #Es gibt einen Assistenten
args = extract_args(srcs)
line = '{}\t{}\t{}'.format(verb, ' '.join(cases), ' '.join(args))
print(line)
Ausgabe
Wo man geboren wird
Ich habe keine Ahnung, ob es geboren wurde
Wo man weinen kann
Das einzige was ich geweint habe
Fang hier an
Sehen Sie, was ich sehe
Hör später zu
Fang uns
Kochen und fangen
Essen und kochen
47. Mining der funktionalen Verbsyntax
Ich möchte nur auf den Fall achten, in dem das Verb wo case eine sa-variante Verbindungsnomenklatur enthält. Ändern Sie 46 Programme, um die folgenden Spezifikationen zu erfüllen.
・ Nur wenn die Phrase bestehend aus "Sahen Verbindungsnomen + (Hilfs))" mit dem Verb verwandt ist ・ Das Prädikat lautet "Sahen-Verbindungsnomen + ist die Grundform von + Verb", und wenn die Phrase mehrere Verben enthält, wird das Verb ganz links verwendet. ・ Wenn das Prädikat mehrere Hilfswörter (Phrasen) enthält, ordnen Sie alle Hilfswörter in Wörterbuchreihenfolge an, die durch Leerzeichen getrennt sind. ・ Wenn das Prädikat mehrere Klauseln enthält, ordnen Sie alle durch Leerzeichen getrennten Begriffe an (richten Sie sie nach der Reihenfolge der Hilfswörter aus). ・ Zum Beispiel sollte die folgende Ausgabe aus dem Satz "Der Meister antwortet auf den Brief, auch wenn er an einen anderen Ort kommt" erhalten werden.
Bei der Beantwortung sagte der Eigentümer zu dem Brief Speichern Sie die Ausgabe dieses Programms in einer Datei und überprüfen Sie die folgenden Elemente mit UNIX-Befehlen.
・ Prädikate, die häufig im Korpus vorkommen (Sahen-Verbindungsnomenklatur + + Verb) ・ Prädikate und Assistentenmuster, die häufig im Korpus vorkommen
Code
def is_sahen(chunk):
return len(chunk) == 2 and chunk[0].pos1 == 'Verbindung ändern' and chunk[1].surface == 'Zu'
def split_sahen(srcs):
for i in range(len(srcs)):
if is_sahen(srcs[i]):
return str(srcs[i]), srcs[:i] + srcs[i+1:]
return None, srcs
Mit split_sahen wird der Block in Form von" Sahen verbindungsverb + wo ~ "aus dem ursprünglichen Block des Blocks extrahiert, der das Verb enthält.
Code
with open('result/sahen_pattern.txt', 'w') as f:
for sent in neko:
for chunk in sent:
if verb := get_first_verb(chunk):
srcs = [sent[src] for src in chunk.srcs]
sahen, rest = split_sahen(srcs)
if sahen and (cases := extract_cases(rest)):
args = extract_args(rest)
line = '{}\t{}\t{}'.format(sahen + verb, ' '.join(cases), ' '.join(args))
print(line, file=f)
Code
cat result/sahen_pattern.txt | cut -f 1 | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
Ausgabe
25 Antwort
19 Sag Hallo
11 reden
9 Stellen Sie eine Frage
7 imitieren
7 Streit
5 Stellen Sie eine Frage
5 Konsultieren Sie
5 Machen Sie ein Nickerchen
4 Halten Sie eine Rede
Code
cat result/sahen_pattern.txt | cut -f 1,2 | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
Ausgabe
10 Wenn Sie antworten
7 Was ist eine Antwort?
7 Sag Hallo
5 Eine Frage stellen
5 In einem Streit
4 Stellen Sie eine Frage
4 zu reden
4 Ich werde Hallo sagen
3 Weil ich antworten werde
3 Hören Sie sich den Diskurs an
48. Extrahieren von Pfaden von der Nomenklatur zu den Wurzeln
Extrahieren Sie für eine Klausel, die die gesamte Nomenklatur des Satzes enthält, den Pfad von dieser Klausel zur Wurzel des Syntaxbaums. Der Pfad im Syntaxbaum muss jedoch die folgenden Spezifikationen erfüllen.
・ Jeder Satz wird durch eine morphologische Sequenz (der Oberflächenschicht) dargestellt. ・ Verbinden Sie von der Startklausel bis zur Endklausel des Pfads die Ausdrücke jeder Klausel mit "->" Aus dem Satz "Ich habe hier zum ersten Mal einen Menschen gesehen" (8. Satz von neko.txt.cabocha) sollte die folgende Ausgabe erhalten werden.
Ich sah-> Hier-> zum ersten Mal-> Mensch-> Ich habe etwas gesehen-> Ich habe ein menschliches Ding gesehen Ich habe etwas gesehen->
Code
def trace(n, sent):
path = []
while n != -1:
path.append(n)
n = sent[n].dst
return path
Code
sent = neko[7]
heads = [n for n in range(len(sent)) if has_noun(sent[n])]
for head in heads:
path = trace(head, sent)
path = ' -> '.join([str(sent[n]) for n in path])
print(path)
Suchen Sie alle Blocknummern mit Nomenklatur und erhalten Sie den Pfad als Liste der Blocknummern, während Sie jeden Kontakt verfolgen. Schließlich sollten die Blöcke in der Reihenfolge der Pfade angezeigt werden.
Ausgabe
ich bin->sah
Hier->Beginnen mit->Mensch->Dinge->sah
Mensch->Dinge->sah
Dinge->sah
49. Extraktion von Abhängigkeitspfaden zwischen Nomenklatur
Extrahieren Sie den kürzesten Abhängigkeitspfad, der alle Nomenklaturpaare im Satz verbindet. Wenn jedoch die Klauselnummern des Nomenklaturpaars i und j sind (i <j), muss der Abhängigkeitspfad die folgenden Spezifikationen erfüllen.
・ Ähnlich wie bei Problem 48 drückt der Pfad die Darstellung jeder Klausel von der Startklausel bis zur Endklausel (Oberflächenelement-Formelementzeichenfolge) aus, indem sie mit "->" verkettet werden. ・ Ersetzen Sie die in den Abschnitten i und j enthaltene Nomenklatur durch X bzw. Y. Darüber hinaus kann die Form des Abhängigkeitspfads auf zwei Arten betrachtet werden.
・ Wenn Klausel j auf der Route von Klausel i zum Stammverzeichnis des Syntaxbaums vorhanden ist: Zeigen Sie den Pfad von Klausel i zu Klausel j an ・ Anders als oben, wenn sich Klausel i und Klausel j an einer gemeinsamen Klausel k auf dem Pfad von Klausel j zur Wurzel des Syntaxbaums überschneiden: der Pfad unmittelbar vor Klausel i zu Klausel k und der Pfad unmittelbar vor Klausel j zu Klausel k, Zeigen Sie den Inhalt von Klausel k an, indem Sie ihn mit "|" verketten. Aus dem Satz "Ich habe hier zum ersten Mal einen Menschen gesehen" (8. Satz von neko.txt.cabocha) sollte beispielsweise die folgende Ausgabe erhalten werden.
X ist|In Y.->Beginnen mit->Mensch->Dinge|sah X ist|Genannt Y.->Dinge|sah X ist|Y.|sah Mit X-> Zum ersten Mal-> Y. Mit X-> Zum ersten Mal-> Mensch-> Y. X-> Y.
Code
def extract_path(x, y, sent):
xs = []
ys = []
while x != y:
if x < y:
xs.append(x)
x = sent[x].dst
else:
ys.append(y)
y = sent[y].dst
return xs, ys, x
def remove_initial_nouns(chunk):
for i, morph in enumerate(chunk):
if morph.pos != 'Substantiv':
break
return ''.join([str(morph) for morph in chunk[i:]]).strip()
def path_to_str(xs, ys, last, sent):
xs = [sent[x] for x in xs]
ys = [sent[y] for y in ys]
last = sent[last]
if xs and ys:
xs = ['X' + remove_initial_nouns(xs[0])] + [str(x) for x in xs[1:]]
ys = ['Y' + remove_initial_nouns(ys[0])] + [str(y) for y in ys[1:]]
last = str(last)
return ' -> '.join(xs) + ' | ' + ' -> '.join(ys) + ' | ' + last
else:
xs = xs + ys
xs = ['X' + remove_initial_nouns(xs[0])] + [str(x) for x in xs[1:]]
last = 'Y' + remove_initial_nouns(last)
return ' -> '.join(xs + [last])
Code
sent = neko[7]
heads = [n for n in range(len(sent)) if has_noun(sent[n])]
print('Der Anfang des Weges:', heads)
pairs = [
(heads[n], second)
for n in range(len(heads))
for second in heads[n + 1:]
]
print('Erstes Pfadpaar: ', pairs)
print('Abhängigkeitspass:')
for x, y in pairs:
x_path, y_path, last = extract_path(x, y, sent)
path = path_to_str(x_path, y_path, last, sent)
print(path)
Zuerst erhalten wir eine Liste von Blocknummern mit Nomenklatur.
Dann bekommen Sie alle Paare dieses Stücks.
Dann wird für jedes Paar der Pfad berechnet, bis derselbe Block erreicht ist, und er wird durch "path_to_str" basierend auf jedem Pfad "x_path", "y_path" und dem letzten gemeinsamen Block "last" angegeben. In Format konvertiert.
Ausgabe
Der Anfang des Weges: [0, 1, 3, 4]
Erstes Pfadpaar: [(0, 1), (0, 3), (0, 4), (1, 3), (1, 4), (3, 4)]
Abhängigkeitspass:
X ist|In Y.->Beginnen mit->Mensch->Dinge|sah
X ist|Genannt Y.->Dinge|sah
X ist|Y.|sah
In X.->Beginnen mit->Genannt Y.
In X.->Beginnen mit->Mensch->Y.
X genannt->Y.
Als nächstes folgt Kapitel 6
Sprachverarbeitung 100 Knock 2020 Kapitel 6: Maschinelles Lernen
Recommended Posts