[PYTHON] Zeichnen Sie Excel-Daten mit matplotlib (2)
Ich möchte Daten aus einer beliebigen Position (Bereich) auf einer Excel-Tabelle extrahieren und mit matplotlib grafisch darstellen
Ich möchte einen Datenrahmen aus einem Datenrahmen erstellen
Nur die Teile (X1, Y1) bis (X4, Y4) der Excel-Daten (siehe unten) werden von Pandas gelesen Möchten Sie es separat in einen Datenrahmen machen? Das mache ich oft. (Weil ich Excel-Daten erstelle, ohne vorher nachzudenken ...)
(Abbildung unten) Die X- und Y-Teile können mit der in [(1) oben] beschriebenen Methode schnell gelesen werden (http://qiita.com/gitytm15/items/13bacd27fa4b37707b3a).
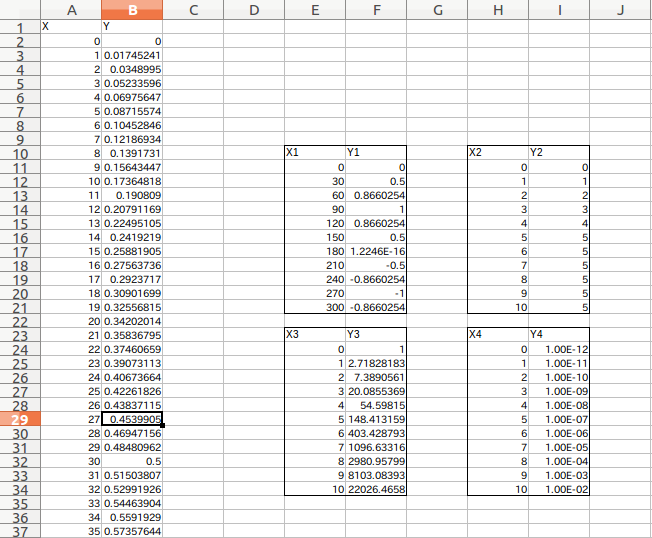
Dies ist sehr praktisch, da Sie es später genießen können, wenn es sich um einen Datenrahmen handelt. Mit einem solchen Excel-Datenblatt ist das Erstellen eines Datenrahmens in erster Linie mühsam ...
Dieses Mal ist es ein Memo, aus diesem Datenrahmen einen untergeordneten Datenrahmen zu erstellen. Es scheint Code zu geben, der mit nur einer Zeile gelöst werden kann, was einfacher ist als diese. Während ich damit herumspielte, konnte ich die Datenrahmenstruktur auf verschiedene Weise verstehen, daher möchte ich sie notieren.
Lesen Sie den übergeordneten Datenrahmen
Excel-Dateien können mit Pandas auf einmal gelesen werden und es ist leicht zu gewinnen, aber in den meisten Fällen haben meine verdammten Excel-Daten keinen richtigen Index oder keine Spalte.
Daher möchte ich einen neuen Datenrahmen (untergeordnetes Element) erstellen, indem ich den Bereich der gelesenen Daten (übergeordnetes Element) spezifiziere.
Geben Sie zu Beginn die gleichen Importeinstellungen und Dateipfade wie gewohnt an.
# coding: utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
#Geben Sie den Speicherort der Ubuntu-Schriftartdatei an(C:\Windows\Fonts\Beliebige Schriftart)
fp = FontProperties(fname="/usr/share/fonts/truetype/fonts-japanese-gothic.ttf")
####################################################################
filepath='~/Desktop/sample2.xls' #Xls-Dateispeicherort
Lesen Sie den übergeordneten Datenrahmen
#Übergeordneter Datenrahmen
df=pd.read_excel(filepath) #Laden Sie in Pandas DataFrame
Erstellen Sie einen untergeordneten Datenrahmen
Fernlesung von iloc
Geben Sie sofort den Bereich des übergeordneten df an und extrahieren Sie die Daten. Hier wird es mit iloc angegeben.
#Geben Sie den Zellbereich an, den Sie grafisch darstellen möchten
df1=df.iloc[8:20,4:6] #[Zeilenanfang: Ende,Spaltenbeginn:Ende]Geben Sie mit an
df1=df1.reset_index(drop=True) #Rollen Sie den Index erneut
Das gesamte (10. bis 21. Zeile, E-F-Spalte) einschließlich der Beschriftungen X1 und Y1 in der folgenden Abbildung ist angegeben. Vielleicht wegen des Headers und der Regel, bei Null zu beginnen Das Ablesen der angegebenen Position direkt aus der Zelle des Blattes ist etwas sinnlich. Daher ist es gut, den Bereich anzugeben, während Sie einen Treffer hinzufügen und drucken (df1).
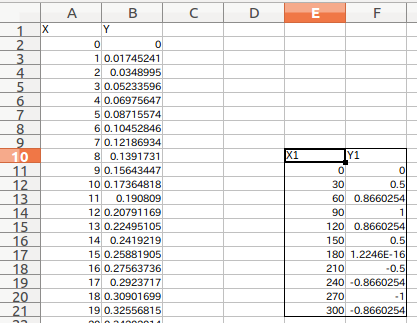
Bereichsspezifikation Leseergebnis von iloc
Wenn Sie sich df1 ansehen, lesen Sie aus dem angegebenen Bereich: Auf diese Weise (siehe unten) wird es basierend auf den Spaltendaten (Unbenannt :) des übergeordneten df gelesen, und X1 und Y1 sind ebenfalls Daten. Diese X1 und Y1 werden als Beschriftungen für den nächsten zu erstellenden "untergeordneten Datenrahmen" verwendet.
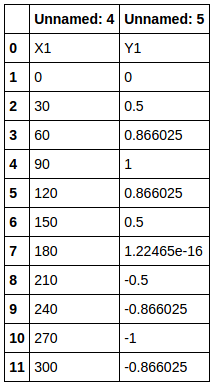
Extrahieren Sie die Spaltendaten aus dem von iloc gelesenen Ergebnis der Bereichsspezifikation
Extrahieren wir daher die Spaltendaten (X1, Y1) von df1.
#Listen Sie die Spalten in der ersten Zeile auf → Verwenden Sie sie in den Spalten des untergeordneten Datenrahmens
COL_LIST1=df1[0:1].values.flatten()
Dann gibt COL_LIST1 `` ['X1''Y1'] `zurück.
Ich habe die gewünschten Spaltendaten erhalten.
Erstellen Sie einen leeren untergeordneten Datenrahmen mit Spaltendaten
Erstellen Sie einen untergeordneten Datenrahmen (co_df1) basierend auf den extrahierten Spaltendaten. Zu diesem Zeitpunkt gibt es nur Spaltendaten und keinen Inhalt.
#Untergeordneter Datenrahmen(empty)Erstellen, die Spalte ist die zuvor erstellte COL_AUFFÜHREN
co_df1=pd.DataFrame({},columns=COL_LIST1,index=[])
Daten in einen untergeordneten Datenrahmen einfügen
Mit der for-Anweisung werden alle Spaltendaten (COL_LIST1) in jede Spalte des angegebenen Bereichsdatenrahmens (df1) gehängt. Verschieben Sie die Daten in einen untergeordneten Datenrahmen.
#Schreiben Sie Daten in jede Spalte eines untergeordneten Datenrahmens(〜[1:]Holen Sie sich die Daten nach der Spaltenbezeichnung von)
#Graph1
for i,col in enumerate(COL_LIST1):
#Lesen Sie die Daten in jeder Spalte
co_df1[col]=df1[[i]][1:].reset_index(drop=True)
Mit df1 [[i]] werden die Daten in der ersten und zweiten Spalte von df1 gelesen, die von iloc angegeben und gelesen wurden. Es enthält jedoch auch die Etikettendaten X1 und Y1. Deshalb df1[[i]][1:] Auf diese Weise können Sie nur die numerischen Daten mit Ausnahme der Etikettendaten abrufen.
Wenn dies jedoch unverändert bleibt, bleiben die ursprünglichen Indexinformationen erhalten und werden später problematisch. df1[[i]][1:].reset_index(drop=True) Und setzen Sie den Index zurück.
Wenn Sie dies nacheinander in den leeren untergeordneten Datenrahmen co_df1 einfügen (nur in COL_LIST1), wird der untergeordnete Zieldatenrahmen vervollständigt.
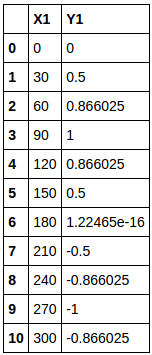
Als Diagrammdaten extrahieren
Danach für x-, y-Achsendaten für das Diagramm Wirf es einfach rein.
x1=co_df1[[0]]
y1=co_df1[[1]]
Versuchen Sie, vier Diagramme redundant zu erstellen
Ich habe versucht, ein Diagramm zu erstellen, indem ich alle am Anfang gezeigten Excel-Daten X1, Y1 in X4, Y4 in untergeordnete Datenrahmen konvertiert habe.
Code
Fügen Sie die mit vier untergeordneten Daten und die mit nur einer grafische ein.
Grafik 4 Version
# coding: utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
#Geben Sie den Speicherort der Ubuntu-Schriftartdatei an(C:\Windows\Fonts\Beliebige Schriftart)
fp = FontProperties(fname="/usr/share/fonts/truetype/fonts-japanese-gothic.ttf")
####################################################################
filepath='~/Desktop/sample2.xls' #Xls-Dateispeicherort
#Übergeordneter Datenrahmen
df=pd.read_excel(filepath) #Laden Sie in Pandas DataFrame
#Erstellen Sie einen untergeordneten Datenrahmen aus einem übergeordneten Datenrahmen
#Geben Sie den Zellbereich an, den Sie grafisch darstellen möchten
df1=df.iloc[8:20,4:6] #[Zeilenanfang: Ende,Spaltenbeginn:Ende]Geben Sie mit an
df1=df1.reset_index(drop=True) #Rollen Sie den Index erneut
df2=df.iloc[8:20,7:9]
df2=df2.reset_index(drop=True)
df3=df.iloc[21:33,4:6]
df3=df3.reset_index(drop=True)
df4=df.iloc[21:33,7:9]
df4=df4.reset_index(drop=True)
#Säule(Name)Lesen
COL_LIST1=df1[0:1].values.flatten() #Listen Sie die Spalten in der ersten Zeile auf → Verwenden Sie sie in den Spalten des untergeordneten Datenrahmens
COL_LIST2=df2[0:1].values.flatten()
COL_LIST3=df3[0:1].values.flatten()
COL_LIST4=df4[0:1].values.flatten()
#Untergeordneter Datenrahmen(empty)Erstellen, die Spalte ist die zuvor erstellte COL_AUFFÜHREN
co_df1=pd.DataFrame({},columns=COL_LIST1,index=[])
co_df2=pd.DataFrame({},columns=COL_LIST2,index=[])
co_df3=pd.DataFrame({},columns=COL_LIST3,index=[])
co_df4=pd.DataFrame({},columns=COL_LIST4,index=[])
#Schreiben Sie Daten in jede Spalte eines untergeordneten Datenrahmens
#Graph1
for i,col in enumerate(COL_LIST1):
#Lesen Sie die Daten in jeder Spalte
co_df1[col]=df1[[i]][1:].reset_index(drop=True)
#Graph2
for i,col in enumerate(COL_LIST2):
#Lesen Sie die Daten in jeder Spalte
co_df2[col]=df2[[i]][1:].reset_index(drop=True)
#Graph3
for i,col in enumerate(COL_LIST3):
#Lesen Sie die Daten in jeder Spalte
co_df3[col]=df3[[i]][1:].reset_index(drop=True)
#Graph4
for i,col in enumerate(COL_LIST4):
#Lesen Sie die Daten in jeder Spalte
co_df4[col]=df4[[i]][1:].reset_index(drop=True)
#X in der Grafik,Extraktion von Y-Daten
#Übergeordneter Datenrahmen
x=df[[0]]
y=df[[1]]
#Untergeordneter Datenrahmen
x1=co_df1[[0]]
y1=co_df1[[1]]
x2=co_df2[[0]]
y2=co_df2[[1]]
x3=co_df3[[0]]
y3=co_df3[[1]]
x4=co_df4[[0]]
y4=co_df4[[1]]
####################################################################
#Graph
####################################################################
fig = plt.figure()
#Mehrere Grafikeinstellungen
ax1 = fig.add_subplot(221) #Graph1
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(223)
ax4 = fig.add_subplot(224)
#Einstellung der y-Achsenskala
ax1.set_yscale('linear')
ax2.set_yscale('linear')
ax3.set_yscale('log')
ax4.set_yscale('log')
#Achsenbereich
ax1.set_ylim(-1.1, 1.1)
ax1.set_xlim(0,300)
ax2.set_ylim(0,10)
ax2.set_xlim(0,10)
ax3.set_ylim(1E+0,1E+5)
ax3.set_xlim(0,10)
ax4.set_ylim(1E-13,1E+1)
ax4.set_xlim(0,10)
#Einzeltitel
ax1.set_title("Graph1",fontdict = {"fontproperties": fp},fontsize=12)
ax2.set_title("Graph2",fontdict = {"fontproperties": fp},fontsize=12)
ax3.set_title("Graph3",fontdict = {"fontproperties": fp},fontsize=12)
ax4.set_title("Graph4",fontdict = {"fontproperties": fp},fontsize=12)
#Achse
ax1.set_xlabel("x",fontdict = {"fontproperties": fp},fontsize=12)
ax1.set_ylabel("y",fontdict = {"fontproperties": fp},fontsize=12)
#Handlung
ax1.plot(x1, y1,'blue',label='graph1')
ax2.plot(x2, y2,'green',label='graph2')
ax3.plot(x3, y3,'red',label='graph3')
ax4.plot(x4, y4,'black',label='graph4')
#Legendenposition
ax1.legend(loc="upper right")
ax2.legend(loc="upper left")
ax3.legend(loc="upper left")
ax4.legend(loc="upper left")
#Layoutanpassung
plt.tight_layout()
#Der Titel des gesamten Diagramms
fig.suptitle('Graph', fontsize=14)
plt.subplots_adjust(top=0.85)
#Datei speichern Als PNG und EPS speichern
plt.savefig("sample.png ")
plt.savefig("sample.eps")
plt.show()
Grafik 1 Version
# coding: utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
#Geben Sie den Speicherort der Ubuntu-Schriftartdatei an(C:\Windows\Fonts\Beliebige Schriftart)
fp = FontProperties(fname="/usr/share/fonts/truetype/fonts-japanese-gothic.ttf")
####################################################################
filepath='~/Desktop/sample2.xls' #Xls-Dateispeicherort
#Übergeordneter Datenrahmen
df=pd.read_excel(filepath) #Laden Sie in Pandas DataFrame
#Erstellen Sie einen untergeordneten Datenrahmen aus einem übergeordneten Datenrahmen
#Geben Sie den Zellbereich an, den Sie grafisch darstellen möchten
df1=df.iloc[8:20,4:6] #[Zeilenanfang: Ende,Spaltenbeginn:Ende]Geben Sie mit an
df1=df1.reset_index(drop=True) #Rollen Sie den Index erneut
#Säule(Name)Lesen
COL_LIST1=df1[0:1].values.flatten() #Listen Sie die Spalten in der ersten Zeile auf → Verwenden Sie sie in den Spalten des untergeordneten Datenrahmens
#Untergeordneter Datenrahmen(empty)Erstellen, die Spalte ist die zuvor erstellte COL_AUFFÜHREN
co_df1=pd.DataFrame({},columns=COL_LIST1,index=[])
#Schreiben Sie Daten in jede Spalte eines untergeordneten Datenrahmens(〜[1:]Holen Sie sich die Daten nach der Spaltenbezeichnung von)
#Graph1
for i,col in enumerate(COL_LIST1):
#Lesen Sie die Daten in jeder Spalte
co_df1[col]=df1[[i]][1:].reset_index(drop=True)
#X in der Grafik,Extraktion von Y-Daten
#Übergeordneter Datenrahmen
x=df[[0]]
y=df[[1]]
#Untergeordneter Datenrahmen
x1=co_df1[[0]]
y1=co_df1[[1]]
####################################################################
#Graph
####################################################################
fig = plt.figure()
#Mehrere Grafikeinstellungen
ax1 = fig.add_subplot(111) #Graph1
#Einstellung der y-Achsenskala
ax1.set_yscale('linear')
#Achsenbereich
ax1.set_ylim(-1.1, 1.1)
ax1.set_xlim(0,300)
#Einzeltitel
ax1.set_title("Graph1",fontdict = {"fontproperties": fp},fontsize=12)
#Achse
ax1.set_xlabel("x",fontdict = {"fontproperties": fp},fontsize=12)
ax1.set_ylabel("y",fontdict = {"fontproperties": fp},fontsize=12)
#Handlung
ax1.plot(x1, y1,'blue',label='graph1')
#Legendenposition
ax1.legend(loc="upper right")
#Layoutanpassung
plt.tight_layout()
#Der Titel des gesamten Diagramms
fig.suptitle('Graph', fontsize=14)
plt.subplots_adjust(top=0.85)
#Datei speichern Als PNG und EPS speichern
plt.savefig("sample.png ")
plt.savefig("sample.eps")
plt.show()
Recommended Posts