[PYTHON] Visualisieren Sie mit Cytoscape 2 Eisenbahnstreckendaten als Grafik
Einführung
Diese Serie verwendet Cytoscape, IPython Notebook, [Pandas](http: // pandas). Dies ist ein Artikel für Visualisierungspraktiker, in dem der Prozess der tatsächlichen Visualisierung von Diagrammen basierend auf öffentlichen Daten mithilfe von Open Source-Tools wie .pydata.org /) vorgestellt wird.
Änderungsprotokoll
- 17.08.2014 (So): Einige Zahlen und Sätze wurden aktualisiert.
- 08.09.2014: Es wurde vorerst in der 4. Sitzung abgeschlossen.
Datenverarbeitung in einer interaktiven Umgebung
 __ Abbildung 1__: Eine Grafik, die Eisenbahnsysteme in ganz Japan verbindet. Hochauflösende Version ist hier
__ Abbildung 1__: Eine Grafik, die Eisenbahnsysteme in ganz Japan verbindet. Hochauflösende Version ist hier
Einführung
Letztes Mal verarbeitete die aus der Datenquelle heruntergeladene Datei mit IPython Notebook. Wir haben es sogar in Cytoscape geladen. Im vorherigen Zustand gibt es jedoch kein Problem beim Anordnen von Knoten (Stationen) unter Verwendung von Längen- und Breitengraden, aber die tatsächlichen Routendaten selbst sind keine Graphen. Die folgende Abbildung zeigt einen anderen automatischen Layout-Algorithmus aus den vorherigen Daten. % 87% E3% 83% AB_ (% E3% 82% B0% E3% 83% A9% E3% 83% 95% E6% 8F% 8F% E7% 94% BB% E3% 82% A2% E3% 83% Visualisiert mit AB% E3% 82% B4% E3% 83% AA% E3% 82% BA% E3% 83% A0)):
 (Hochauflösende Version ist hier)
(Hochauflösende Version ist hier)
Wenn Sie hineinzoomen, können Sie sehen, dass es Verbindungen für jede Zeile gibt, aber jede unabhängig existiert:
Damit funktionieren das automatische Layout, die Pfadsuche und andere Funktionen nicht gut. Zunächst möchte ich dieses Problem lösen, indem ich wie zuvor interaktiv mit IPython Notebook programmiere und dann die von öffentlichen Einrichtungen bereitgestellten Daten integriere und visualisiere.
Dieses Ziel
- Verbinden Sie die verbundenen Routen mit verschiedenen Arten von Kanten, um die geteilten Routendaten in landesweite Diagrammdaten umzuwandeln.
- Erhalten Sie Daten über die Anzahl der Passagiere, die von einer öffentlichen Einrichtung in den Bahnhof ein- und aussteigen, und verarbeiten Sie sie zu einem Formular, das von Cytoscape gelesen werden kann.
- Beziehen Sie die Themenfarbe jeder Route von Wikipedia und verarbeiten Sie sie in CSV
- Integrieren Sie alle Daten in Cytoscape und erstellen Sie ein Visualisierungsbeispiel
Ein Notizbuch, das die eigentliche Arbeit aufzeichnet
Ich werde es von Zeit zu Zeit hinzufügen, aber Sie können die Aufzeichnung der tatsächlichen Arbeit hier sehen:
Dies kann auf Ihrem Computer durchgeführt werden, solange Sie die in Ihrem Notebook verwendeten Bibliotheken installiert haben. Selbst wenn Sie kein Python-Programmierer sind, machen Sie nichts Kompliziertes, sodass Sie es verstehen können, indem Sie den Anweisungen in den Notizen folgen. Die im Notebook durchgeführte Datenvorverarbeitung ist wie folgt.
Informationen zum Erstellen von Umgebungen bei der Arbeit mit Python
Grundsätzlich arbeite ich an einem UNIX-basierten Betriebssystem, aber in diesem Fall ist es praktisch, eine Umgebung mit Anaconda zu erstellen:
Für diese Art der Datenbereinigung, Pandas, [NumPy](http: // www) Ich benutze oft Bibliotheken wie .numpy.org /) und SciPy, aber sie kümmern sich gut um die Abhängigkeiten der Bibliotheken hier. Darüber hinaus funktioniert es gut mit dem Befehl pip. Bibliotheksinstallation
conda install LIBRARY_NAME
Sie müssen an nichts denken, da Sie es mit dem Befehl fast lösen können.
Einzelheiten zur Datenaufbereitung
Nun wollen wir sehen, was in den Notizen los ist. Wenn möglich, ist es leichter zu verstehen, wenn Sie lesen, während Sie die Notizen tatsächlich ausführen.
Verbinden Sie nicht zusammenhängende Routendaten für jede Stationsgruppe
Stellen Sie eine Verbindung mit den Informationen mit dem Namen Station Group in den Originaldaten her. In derselben Gruppe zu sein bedeutet, dass Sie umsteigen können, wie es ist, oder dass diese Stationen zu Fuß erreichbar sind. Daher kann davon ausgegangen werden, dass die Stationen in der Gruppe praktisch mit anderen Leitungen verbunden sind. In der eigentlichen Arbeit werden wir diese Stationen in derselben Gruppe mit einer neuen Kante und Creek verbinden % E3% 83% BC% E3% 82% AF_ (% E3% 82% B0% E3% 83% A9% E3% 83% 95% E7% 90% 86% E8% AB% 96)) Masu:
 __ Abbildung 2 __: Teil des erstellten Baches
__ Abbildung 2 __: Teil des erstellten Baches
Durch Zusammenführen dieser Bäche mit den ursprünglichen Streckendaten bilden wir ein Eisenbahnnetz, das die Strecken landesweit verbindet, wie in Abbildung 1 dargestellt.
Überprüfen Sie den Status des verbundenen Diagramms
Hier, etwas abseits der Nebenstraße, befindet sich die größte Station Japans Shinjuku Nehmen wir als Beispiel% BF% E9% A7% 85). Der Bahnhof Shinjuku ist ein riesiger Knotenpunkt des Eisenbahnnetzes, an den jede Eisenbahnlinie anschließt. __ Wenn Sie sich das vorstellen, sollten Sie in der Lage sein, die Bäche zu sehen, die aus Stationen derselben Gruppe bestehen und von denen sich jede Linie radial von dort aus erstreckt __. Ich habe es tatsächlich zur Bestätigung versucht. Ich werde den Teil weglassen, der (vorerst) in Cytoscape eingelesen werden soll, aber die grundlegende Operation, um die folgende Abbildung zu erstellen, ist
- Wählen Sie Shinjuku Station Group aus der nationalen Routenkarte
- Extrahieren Sie Stationen, die innerhalb eines Hops von dort existieren (CTR-6 unter Windows / Linux Command + 6 unter Mac)
- Erstellen Sie ein neues Netzwerk aus dem gewaschenen Teilgraphen (CTR + N unter Windows / Linux, Command + N unter Mac).
- Wenden Sie den Ringlayout-Algorithmus auf die Shinjuku-Stationsgruppe und andere an
- Erstellen Sie einen einfachen Stil, um Kanten innerhalb einer Gruppe von anderen zu unterscheiden
Wenn Sie dies tun, können Sie ein Diagramm wie das folgende zeichnen:
 (
(Die grün gepunktete Linie zeigt die übertragbare Route an (zu Fuß erreichbar), und die durchgezogene Linie zeigt jede Route an. Soweit ich das sehen kann, scheint die Verbindung erfolgreich gewesen zu sein.
Ordnen Sie andere veröffentlichte Datensätze im Schienennetz zu
Jetzt haben Sie eine "weiße Eisenbahnkarte", die Sie auf Cytoscape verwenden können. Es gibt einen Grund, diese Daten als weiße Karte zu bezeichnen. Das liegt daran, dass Sie andere Datensätze in diesem Netzwerk frei zuordnen können, um Ihre eigenen Visualisierungen zu erstellen. Dies ist der Vorteil des Ablegens geografischer Daten in eine konzeptionelle Diagrammstruktur und der Verwendung in Cytoscape. Es gibt unzählige mögliche Zuordnungen, aber ein einfaches Beispiel ist:
- Schneiden Sie die Route, an der Sie interessiert sind, als Untergraphen aus und ordnen Sie ihr visuell die Anzahl der Passagiere pro Tag zu.
- Berechnen Sie die Anzahl der Personen, die pro Strecke bewegt werden können (Anzahl der Züge pro Tag x Zugkapazität), und ordnen Sie den ungefähren Passagierfluss der Dicke der Kante zu.
- Schneiden Sie eine bestimmte Linie aus, extrahieren Sie die Einrichtungen entlang der Linie aus anderen geografischen Daten und stellen Sie über eine neue Kante eine Verbindung zur nächsten Station her. Geben Sie ihnen ein neues Layout und Infografik E3% 82% B0% E3% 83% A9% E3% 83% 95% E3% 82% A3% E3% 83% 83% E3% 82% AF)
Dies sind alles einfache Beispiele. Je mehr Daten Sie zuordnen können, desto größer sind die Möglichkeiten für eine weitere Visualisierung. Zunächst dachte ich, dass es einige einfache Daten geben könnte, damit ich die Grundfunktionen kennenlernen könnte, aber ich dachte, dass es leicht sein würde, die "Anzahl der Passagiere pro Tag" zu verstehen, und suchte nach öffentlich verfügbaren Daten. gestartet.
Öffentliche Daten abrufen und bereinigen
Um die Wahrheit zu sagen, ich habe bis jetzt noch keine öffentlichen japanischen Datensätze gesehen. Ich habe herausgefunden, wann ich tatsächlich danach gesucht habe, aber die Statistiken, die jedes Ministerium und jede Behörde kennt, werden vorerst veröffentlicht, aber es gibt immer noch eine starke Tendenz, sie als Satz zu veröffentlichen, den die Leute lesen __. Es ist ein sehr einfacher Datensatz namens "Anzahl der Passagiere pro Station", aber die Tabelle wird nicht als Paar von Stationsname-Nummer von Passagieren veröffentlicht. Es waren diese Daten, die ich dieses Mal "ausgegraben" habe:
Da es als XML-Datei veröffentlicht wird, dachte ich, dass es relativ einfach zu verarbeiten sein sollte, also begann ich mit der Arbeit, aber plötzlich brach der Parser zusammen. Die Ursache war ein einfacher Fehler beim Schließen des Tags.
cat S12-13.xml | sed -e "s/ksj:ailroad/ksj:railroad/" > fixed.xml
Es kann mit repariert werden.
Probleme bei der tatsächlichen Verwendung
Als ich tatsächlich meine Hände bewegte und den Inhalt untersuchte, wurde mir klar, dass es nicht so einfach sein konnte, wie ich erwartet hatte. Einige der Probleme sind:
- Die Anzahl der Passagiere entspricht nicht immer den Daten für jede Station
- Einige Daten werden mit anderen Stationen kombiniert
- Datenverlust - Einige Stationen haben überhaupt keine Daten
- ID des Gesamtziels der Gesamtdaten
- Die Gesamtmethode beim Summieren ist in natürlicher Sprache in der Spalte __ Bemerkungen __ geschrieben
- Es gibt keine ID des Gesamtziels
Zu diesem Zeitpunkt war ich etwas weniger motiviert, aber ich entschied mich, nur den Teil zu tun, den ich als Demonstration der Methode tun konnte, und fuhr fort, ohne einen solchen Teil zu sehen (ich denke, dass dies bei der Arbeit nicht geschehen wird ...). .. Nachdem ich einige lächerliche Arbeiten wie die in der Notiz gemacht hatte, bekam ich eine Tabelle wie diese:

Ich habe in das Notizbuch geschrieben, warum ich die codierten Informationen absichtlich in redundante Zeichenfolgeninformationen konvertiert habe, aber es ist einfacher, mit Visualisierungssoftware zu arbeiten, indem ich sie als für Menschen lesbare Zeichenfolge speichere. .. __ Diese Art von Arbeit ist für umfangreiche Analysen und Visualisierungen ziemlich schädlich. Bestimmen Sie daher die Größe des Datensatzes und vergleichen Sie die Benutzerfreundlichkeit mit dem Gewicht des Computers und verwenden Sie die entsprechende Methode. Lass uns wählen __.
Abrufen von Farbinformationen zum Routenthema durch Schaben
Da das WWW mit der Idee begann, von Menschen lesbare Texte zu verknüpfen, wird eine große Menge von Daten als Tabellen veröffentlicht, die für das Lesen von Menschen ausgelegt sind, ohne dass davon ausgegangen wird, dass sie von Maschinen verarbeitet werden. Und solche Daten sind überraschend nützlich und die Informationen, die Sie verwenden möchten, sind vergraben.
Wenn Sie das Netzwerk mit Cytoscape visualisieren, können Sie frei eine benutzerdefinierte Farbkarte für alle Elemente auf dem Bildschirm erstellen. Für diesen Datensatz ist es einfacher zu verstehen und effektiver, etwas zu verwenden, mit dem die Benutzer vertraut sind, als die Farbcodierung selbst festzulegen. Für Tokyo Metro sind die folgenden Farben Standard:
 ([Wikimedia Commons](http://commons.wikimedia.org/wiki/File:Tokyo_metro_map.png#mediaviewer/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB : Von Tokyo_metro_map.png))
([Wikimedia Commons](http://commons.wikimedia.org/wiki/File:Tokyo_metro_map.png#mediaviewer/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB : Von Tokyo_metro_map.png))
Ich habe mich gefragt, ob ich diese Farbinformationen in einem Dateiformat erhalten könnte, das von einer Maschine leicht gelesen werden kann, aber leider konnte ich sie nicht finden (bitte lassen Sie es mich wissen, wenn jemand es weiß). Es wurde jedoch gut als lesbarer Satz veröffentlicht:
- [Liste der Farben der japanischen Eisenbahnlinie](http://ja.wikipedia.org/wiki/%E6%97%A5%E6%9C%AC%E3%81%AE%E9%89%84%E9%81] % 93% E3% 83% A9% E3% 82% A4% E3% 83% B3% E3% 82% AB% E3% 83% A9% E3% 83% BC% E4% B8% 80% E8% A6% A7 )
Also habe ich beschlossen, es gewaltsam aus dieser Seite herauszuschneiden. Es gibt verschiedene Ausnahmen zu den in diesem Text vergrabenen Daten, aber in vielen Fällen gibt es einige Muster, so dass es einfach ist, einen kurzen Blick darauf zu werfen:
<tr style="height:20px;">
<td>Zeile 3</td>
<td>
<a href="/wiki/%E6%9D%B1%E4%BA%AC%E3%83%A1%E3%83%88%E3%83%AD%E9%8A%80%E5%BA%A7%E7%B7%9A" title="Tokyo Metro Ginza Line">
Ginza Linie
</a>
</td>
<td>G</td>
<td style="background:#f39700; width:20px;"> </td>
<td><b>Orange</b></td>
</tr>
Wenn Sie die Daten __ # f39700__ in diesem mit dem Schlüssel __ Tokyo Metro Ginza Line __ kombinieren, werden sie von Cytoscape gelesen und die Farbdaten lauten _ [Passthrough Mapping](http: //wiki.cytoscape). Sie können es so verwenden, wie es mit .org / Cytoscape_3 / UserManual # Cytoscape_3.2BAC8-UserManual.2BAC8-Styles.How_Mappings_Work) _ ist. Glücklicherweise hat Python viele Bibliotheken für diese Art von Scraping-Arbeit, deshalb habe ich sie verwendet, um einen groben Schnitt zu machen. Diese Arbeit kann beliebig verbessert werden, aber zu Demonstrationszwecken kann sie schmutzig sein, daher habe ich die Ergebnisse auf ein Minimum beschränkt.
Überprüfen Sie das Schabergebnis
Dieses Mal werden wir das Thema der Tokyo Metro visualisieren, stellen Sie also sicher, dass die Daten dieses Teils richtig aufgenommen wurden. Lass es uns mit einem Liner machen.
grep Tokyo Metro Linie_colors.csv | awk -F ',' '{print "<span style=\"color:" $3 "\">" $2 "</span><br />"}' > metro_colors.html
Das Ergebnis sieht folgendermaßen aus und Sie können sehen, dass es kein Problem gibt, es mit den Originaldaten zu vergleichen:
(Generated HTML)

(Original Table)

Wie oben erwähnt, einschließlich des vorherigen Teils, Alle Arbeiten werden in IPython Notebook aufgezeichnet. Die Ausführung selbst dauert einige zehn Sekunden. Wenn Sie interessiert sind, schauen Sie sich bitte die generierte Textdatei (CSV) an. All dies kann einfach in Cytoscape geladen werden.
Integration und Mapping auf Cytoscape
Jetzt ist es endlich Visualisierung mit Cytoscape. Aber es wird ziemlich lang, also werde ich das nächste Mal die Details dieses Teils übernehmen. Als nächste Vorschau werde ich kurz vorstellen, welche Art von Verarbeitung möglich ist, wenn sie in Cytoscape geladen wird.
Der Desktop, an dem Sie arbeiten, mit allem, was geladen ist
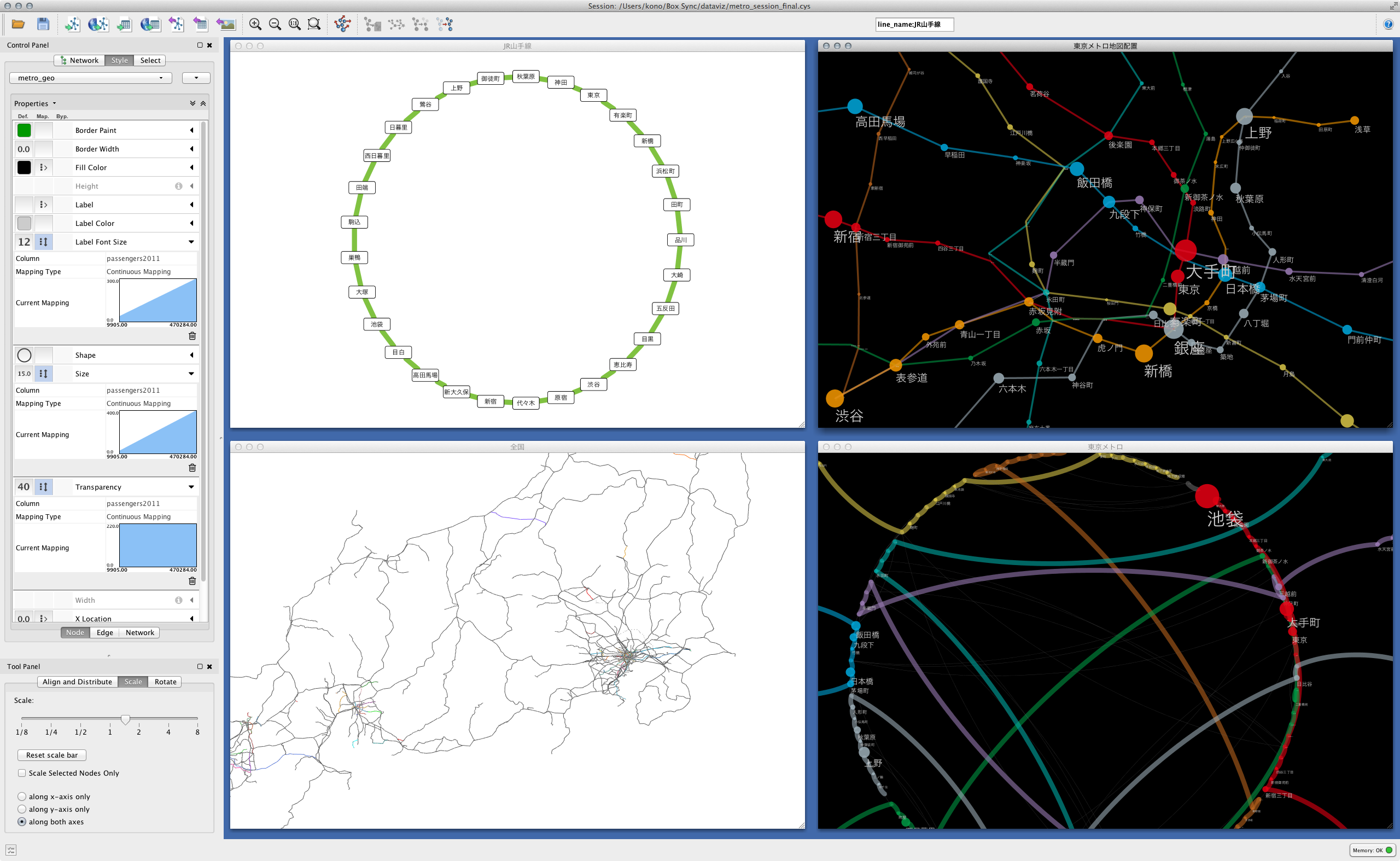 (
(Jede Station der Tokyo Metro zeigt die relative Positionsbeziehung anhand der Position auf der Karte
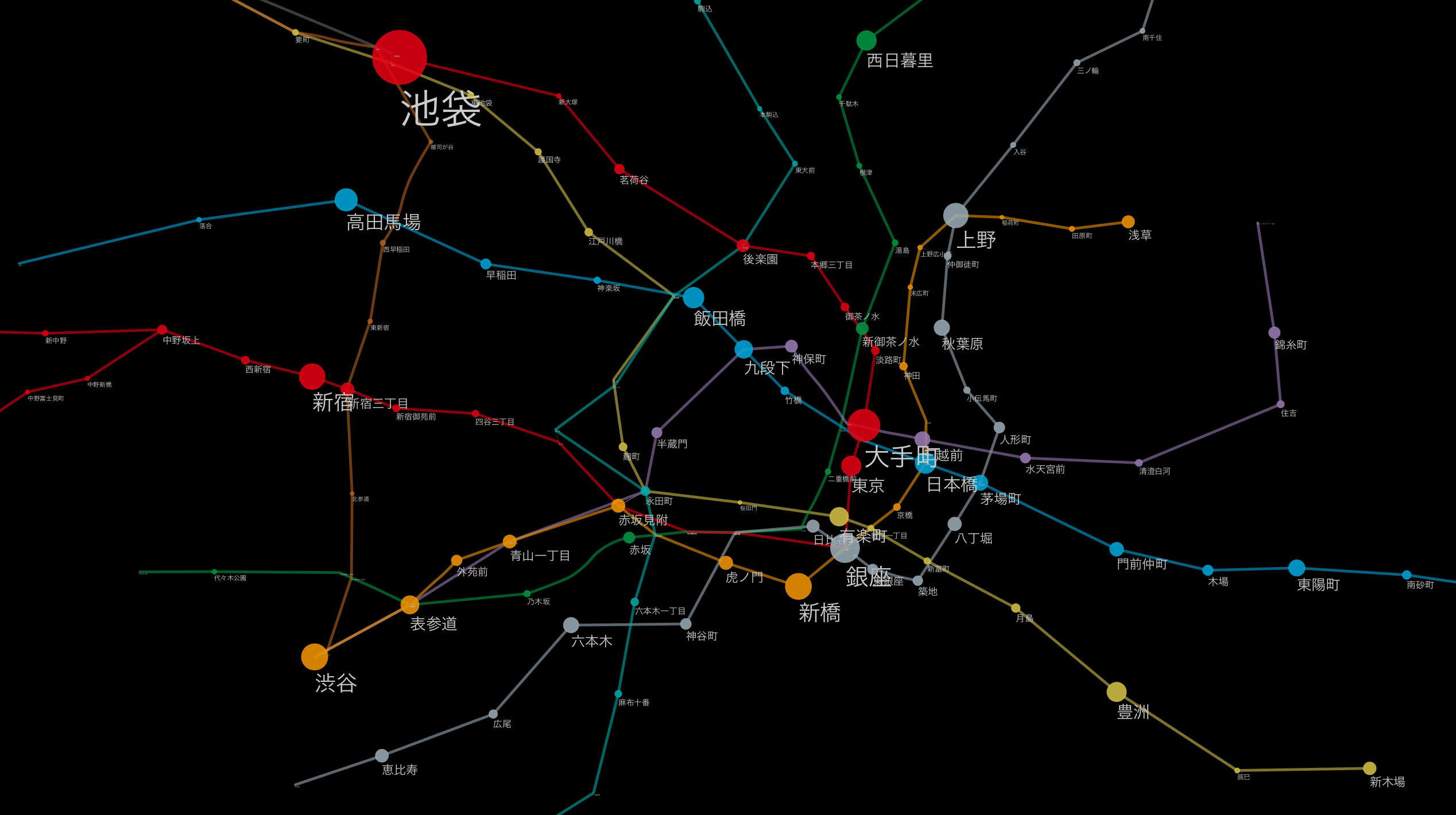 (
(Ein Beispiel für die Anwendung eines anderen Layoutalgorithmus.
Die Etikettengröße entspricht der Anzahl der Passagiere pro Tag
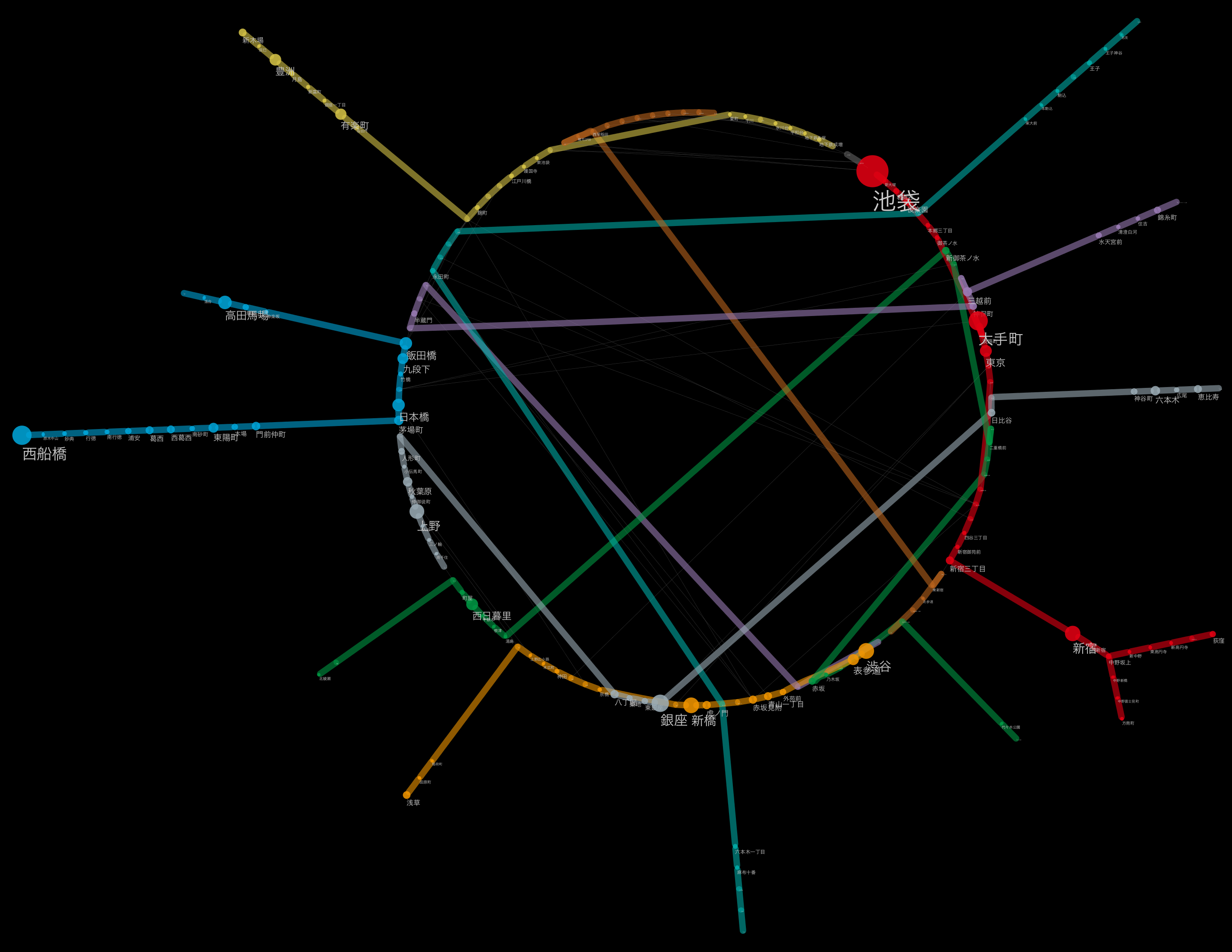 (
(Yamate-Linie als einfaches Anschlussdiagramm
 (
(Kombinieren Sie automatisches und manuelles Layout (Layout für jede Route)
 (
(Am Ende
__ "Alle öffentlichen Statistiken werden in maschinenlesbarer Form veröffentlicht, mit Code sprechenden Personen können sie neue wertschöpfende Anwendungen erstellen, und Statistiker erhalten aus den Ergebnissen ihrer Integration neue Erkenntnisse."
Eine solche Welt könnte eines Tages kommen. Aber zumindest für den Moment ist dies die Realität. Das Aufdecken "schmutziger Daten", das Bereinigen und Zusammenstellen in einer verwendbaren Form ist eine sehr stetige und langweilige Aufgabe, aber derzeit ein unvermeidbarer Prozess. Die Werkzeuge sind fertig. Wenn Sie Code schreiben können, bewegen Sie Ihre Hand und listen Sie auf, was falsch ist. Und lassen Sie es uns dem Anbieter sagen. Auf lange Sicht ist dies wahrscheinlich die einzige Lösung.
Jeder, der das Notizbuch gelesen hat, wird verstehen, dass es ein allgemeiner Klick ist. Im Gegensatz zur Programmierung habe ich beim Vorbereiten von Daten für eine bestimmte Visualisierung die Richtlinie __, dass Sie zurücklesen können, was Sie getan haben, anstatt __ Effizienz oder Eleganz. In Bezug auf die Wiederverwendbarkeit des Workflows sind weiterhin Versuche und Irrtümer erforderlich, aber anstatt aufwändigere Dinge als nötig zu tun, Visualisierungs-Apps (Cytoscape natürlich D3.js Es kann erforderlich sein, dass sich Personen, die im Bereich der Visualisierung arbeiten, darauf konzentrieren, einen benutzerfreundlichen Datensatz zu erstellen, der in (einschließlich der in erstellten benutzerdefinierten Visualisierungsanwendungen) verwendet werden kann, und mit der Arbeit fortfahren, während einige Kompromisse eingegangen werden. nicht. Jetzt ist es möglich, Tools wie Git, IPython Notebook und RStudio zu kombinieren, um automatisch Datensätze zu speichern, einschließlich des stressfreien Denkens. Ich denke, es ist eine gute Idee, diese zu verwenden, um nach und nach einen Workflow zu finden, der zu Ihnen passt.
Es tut mir leid für diejenigen, die keine Mitglieder sind, da es sich um eine FB-Gruppe handelt. Wenn Sie jedoch an einer solchen Visualisierung interessiert sind, treten Sie dieser Gruppe bei. Wir planen, Probleme und Know-how zu teilen. Eine Gruppe für Menschen, die ihre Hände im Bereich der Visualisierung bewegen.
Fortsetzung vom 3.
Recommended Posts