[PYTHON] Visualisieren Sie Daten interaktiv mit TreasureData, Pandas und Jupyter.
Einführung
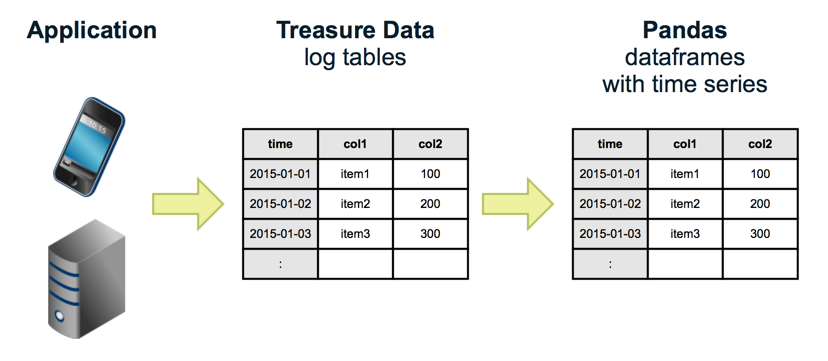
TreasureData ist ein Cloud-Dienst, mit dem Sie Zeitreihendaten wie Anwendungsprotokolle und Sensordaten einfach erfassen, speichern und analysieren können. Derzeit ist Presto als eine der Analyse-Engines verfügbar, und die gesammelten Daten können interaktiv mit SQL analysiert werden. wurde.
TreasureData hat jedoch nicht die Funktion, basierend auf den von SQL analysierten Daten zu visualisieren. Daher ist es erforderlich, die Visualisierung mit einem externen Tool wie Excel oder Tableau durchzuführen.
Dieses Mal haben wir also Pandas, eine beliebte Python-Bibliothek, und Jupyter, mit dem Sie Python interaktiv mit einem Webbrowser ausführen können. Mithilfe von SQL wird SQL interaktiv mit TreasureData zur Aggregation und Visualisierung ausgeführt.
installieren
Nutzungsumgebung
- Ubuntu 14.04
- Python 3.4
- Pandas
- Jupyterhub
TreasureData
Anmelden
Melden Sie sich auf der Seite hier an. Derzeit gibt es eine 14-tägige Testphase, in der Sie Presto verwenden können.
Pandas
Pandas ist ein Tool, das wie folgt aussieht, wenn es vom Beamten zitiert wird.
pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
Python-Installation
Ubuntu14.04 enthält Python3.4, aber Python3 ist ein Alias und problematisch, daher werden wir die Umgebung mit pyenv erstellen.
Referenz: http://qiita.com/akito1986/items/be5dcd1a502aaf22010b
$ sudo apt-get install git gcc g++ make openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev
$ cd /usr/local/
$ sudo git clone git://github.com/yyuu/pyenv.git ./pyenv
$ sudo mkdir -p ./pyenv/versions ./pyenv/shims
$ echo 'export PYENV_ROOT="/usr/local/pyenv"' | sudo tee -a /etc/profile.d/pyenv.sh
$ echo 'export PATH="${PYENV_ROOT}/shims:${PYENV_ROOT}/bin:${PATH}"' | sudo tee -a /etc/profile.d/pyenv.sh
$ source /etc/profile.d/pyenv.sh
$ pyenv -v
pyenv 20150601-1-g4198280
$ sudo visudo
#Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
Defaults env_keep += "PATH"
Defaults env_keep += "PYENV_ROOT"
$ sudo pyenv install -v 3.4.3
$ sudo pyenv global 3.4.3
$ sudo pyenv rehash
Installieren Sie Pandas
$ sudo pip install --upgrade pip
$ sudo pip install pandas
Versuchen Sie es mit Pandas aus der Shell
Weitere Informationen finden Sie unter 10 Minuten für Pandas.
Jupyter
Jupyter war ursprünglich eine interaktive Shell eines Webbrowsers für Python namens IPython, aber jetzt wird es umbenannt und entwickelt, um es in jeder Sprache verfügbar zu machen. Darüber hinaus ist JuptierHub eine Serverversion von Jupyter, mit der mehrere Benutzer Jupyter verwenden können. Mit Juypter erstellte Notebooks können problemlos freigegeben werden.
JupyterHub installieren
$ sudo apt-get install npm nodejs-legacy
$ sudo npm install -g configurable-http-proxy
#Verwandte Bibliotheken
$ sudo pip install zmq jsonschema
#Visualisierungsbibliothek
$ sudo apt-get build-dep python-matplotlib
$ sudo pip install matplotlib
$ git clone https://github.com/jupyter/jupyterhub.git
$ cd jupyterhub
$ sudo pip install -r requirements.txt
$ sudo pip install .
$ sudo passwd ubuntu
$ jupyterhub
Sie können Jupter jetzt über Ihren Webbrowser öffnen und darauf zugreifen. http://(IP address):8000/
Weitere detaillierte Einstellungen von JupyterHub finden Sie unter hier.
Verwenden Sie Pandas von Jupyter
Versuchen Sie zunächst, sich anzumelden. Anschließend wird das Benutzerverzeichnis des angemeldeten Benutzers angezeigt. Erstellen Sie hier ein Jupyter-Arbeitsverzeichnis und erstellen Sie ein Notizbuch, um Ihre Arbeit aufzuzeichnen.
Wählen Sie Neu-> Notizbücher (Python3).

Sie können eine Folge von Python-Befehlen in diesem Notizbuch speichern.
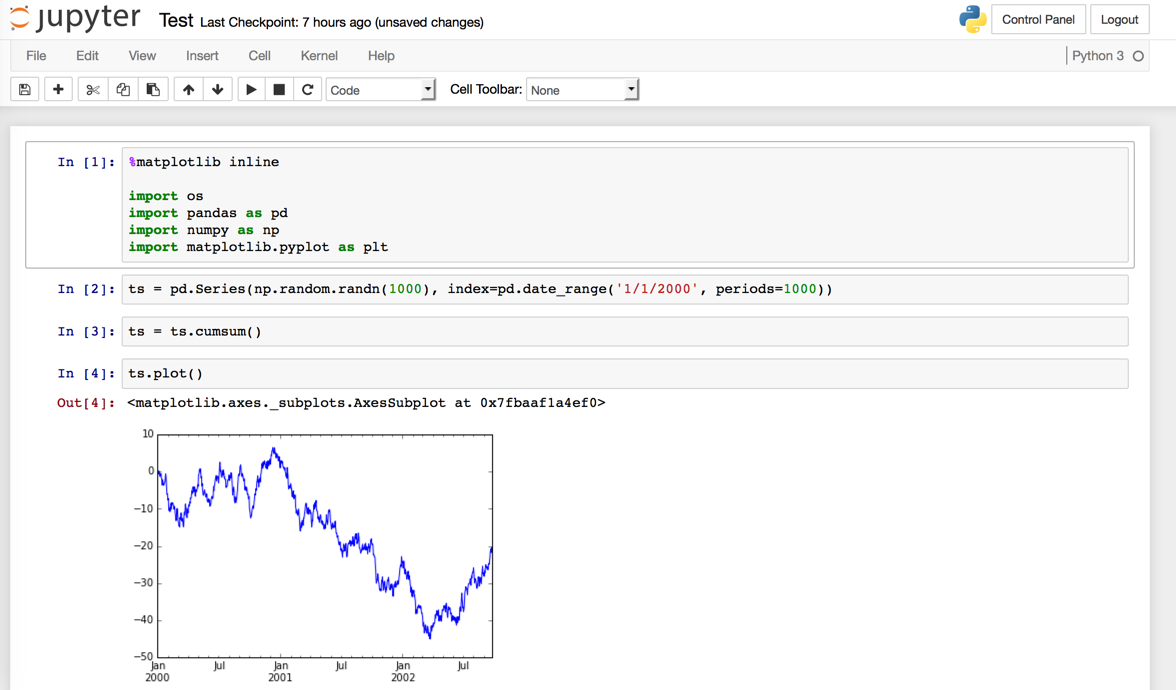
Lassen Sie uns nun basierend auf [hier] testen ((http://pandas.pydata.org/pandas-docs/stable/visualization.html#visualization)).
%matplotlib inline
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
ts = ts.cumsum()
ts.plot()
ToDo: Es scheint, dass der erste Import mit der folgenden Konfiguration weggelassen werden kann, aber es wurde noch nicht gut gemacht, also überprüfe ich ...
$ jupyterhub --generate-config
Writing default config to: jupyterhub_config.py
$ vi jupyterhub_config.py
c.IPKernelApp.matplotlib = 'inline'
c.InteractiveShellApp.exec_lines = [
'import pandas as pd',
'import numpy as np',
'import matplotlib.pyplot as plt',
]
$ mv jupyterhub_config.py .ipython/profile_default/
Integration von Treasure Data und Pandas mit pandas-td
Jetzt, da Sie Pandas und Jupyter verwenden können sollten, möchte ich auf Treasure Data zugreifen.
Hier verwenden wir eine Bibliothek namens pandas-td. Auf diese Weise können Sie drei Dinge tun.
- Fügen Sie Daten in die Tabelle von TreasureData ein
- Extrahieren Sie Daten aus der TreasureData-Tabelle
- Fragen Sie mit TreasureData ab, um Ergebnisse zu erhalten
Installation
$ sudo pip install pandas-td
Verbindungseinstellungen
%matplotlib inline
import os
import pandas as pd
import pandas_td as td
#Es ist praktisch, wenn Sie es in die Umgebungsvariable einfügen
#con = td.connect(apikey="os.environ['TD_API_KEY']", endpoint='https://api.treasuredata.com/')
con = td.connect(apikey="TD API KEY", endpoint='https://api.treasuredata.com/')
Stellen Sie eine Abfrage
engine = con.query_engine(database='sample_datasets', type='presto')
# Read Treasure Data query into a DataFrame.
df = td.read_td('select * from www_access', engine)
df
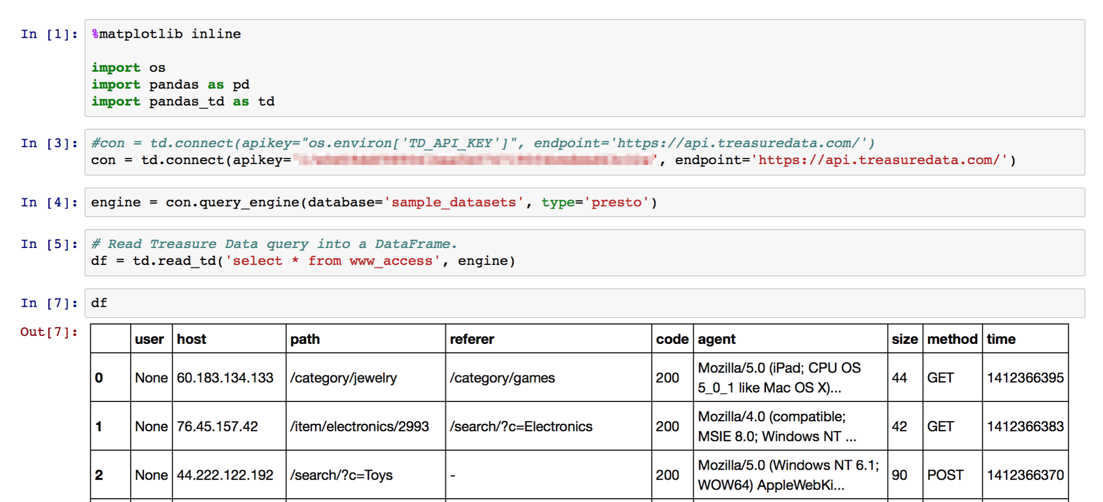
Schauen Sie sich einige Daten an
engine = con.query_engine(database='sample_datasets', type='presto')
con.tables('sample_datasets')
td.read_td_table('nasdaq', engine, limit=3, index_col='time', parse_dates={'time': 's'})
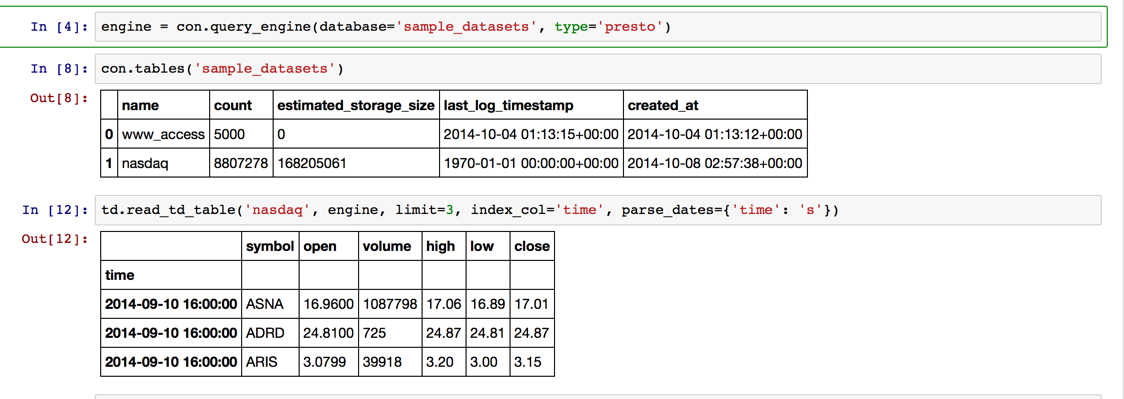
Erhalten Sie, indem Sie den Zeitraum eingrenzen, nach Datum aggregieren und visualisieren
df = td.read_td_table('nasdaq', engine, limit=None, time_range=('2010-01-01', '2010-02-01'), index_col='time', parse_dates={'time': 's'})
df.groupby(level=0).volume.sum().plot()
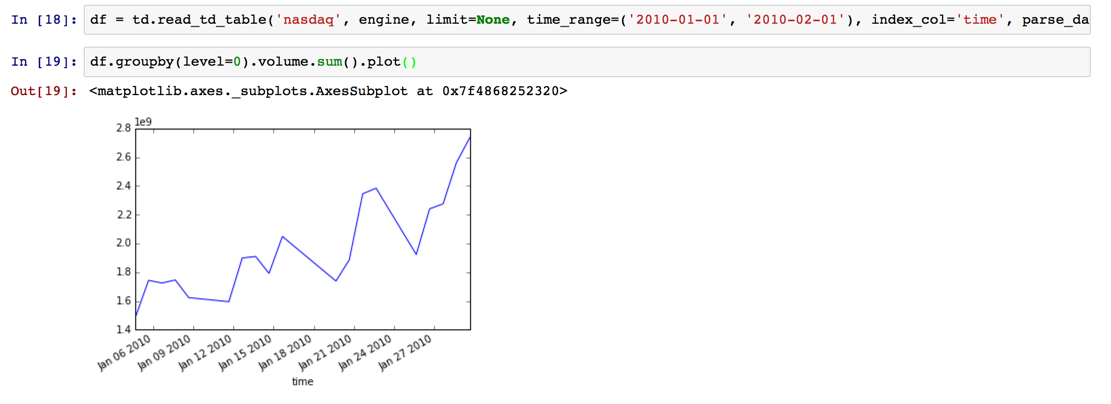
Was ist bequem
Sie können die Zwischenverarbeitung einfach umschreiben und erneut versuchen. Wenn es sich um mehrere Millionen handelt, kann es basierend auf dem heruntergeladenen Ergebnis im Speicher verarbeitet werden. Sie können auch Daten aus MySQL- und CSV-Dateien mitbringen.
etc.
abschließend
Ich kann das Gefühl der Erschöpfung auf dem Weg nicht leugnen, also werde ich bald besser schreiben.
Recommended Posts