[PYTHON] Graphique des données Excel avec matplotlib (2)
Je souhaite extraire des données d'une position arbitraire (plage) sur une feuille Excel et les représenter graphiquement avec matplotlib
Je souhaite créer un bloc de données à partir d'un bloc de données
Seules les parties (X1, Y1) à (X4, Y4) des données Excel (illustrées ci-dessous) lues par les pandas Voulez-vous en faire un bloc de données séparément? Je fais souvent. (Parce que je crée des données Excel sans réfléchir à l'avance ...)
(Figure ci-dessous) Les parties X et Y peuvent être lues rapidement par la méthode décrite dans (1) ci-dessus.
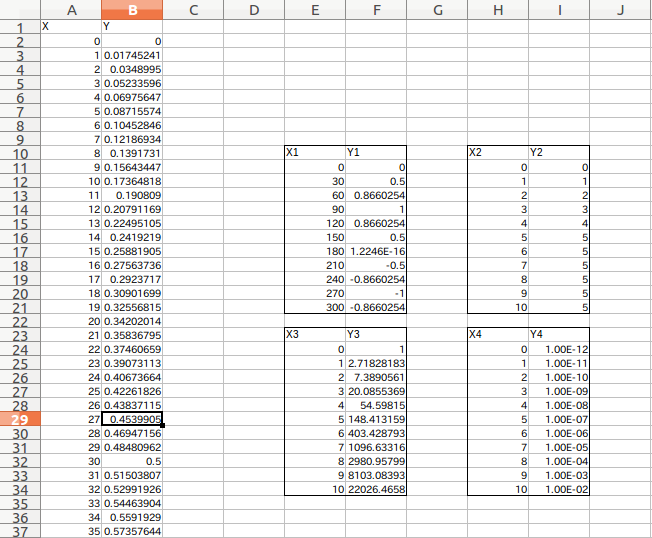
C'est très pratique car vous pouvez en profiter plus tard s'il s'agit d'une trame de données. Avec une telle feuille de données Excel, créer un bloc de données est en premier lieu gênant ...
Cette fois, c'est un mémo pour créer un bloc de données enfant à partir de ce bloc de données. Il semble y avoir du code qui peut être résolu avec une seule ligne, ce qui est plus facile que cela, Pendant que je jouais avec, j'ai pu comprendre la structure de la trame de données de différentes manières, alors j'aimerais en prendre note.
Lire le bloc de données parent
Les fichiers Excel peuvent être lus d'un coup avec des pandas et il est facile de gagner, mais dans la plupart des cas, mes putains de données Excel n'ont pas d'index ou de colonne approprié.
Donc, je voudrais créer un nouveau bloc de données (enfant) en spécifiant la plage des données lues (parent).
Au début, spécifiez les mêmes paramètres d'importation et le même chemin de fichier que d'habitude.
# coding: utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
#Spécifiez l'emplacement du fichier de police ubuntu(C:\Windows\Fonts\Toute police)
fp = FontProperties(fname="/usr/share/fonts/truetype/fonts-japanese-gothic.ttf")
####################################################################
filepath='~/Desktop/sample2.xls' #Emplacement du fichier xls
Lire le bloc de données parent
#Cadre de données parent
df=pd.read_excel(filepath) #Charger dans Pandas DataFrame
Créer un bloc de données enfant
Lecture à distance par iloc
Immédiatement, spécifiez la plage du df parent et extrayez les données. Ici, il est spécifié à l'aide d'iloc.
#Spécifiez la plage de cellules que vous souhaitez représenter graphiquement
df1=df.iloc[8:20,4:6] #[Début de ligne: fin,Début de colonne:Fin]Précisez avec
df1=df1.reset_index(drop=True) #Relancer l'index
La totalité (10e à 21e lignes, colonne E-F), y compris les étiquettes X1 et Y1 dans la figure ci-dessous, est spécifiée. Peut-être à cause de l'en-tête et de la règle de partir de zéro La lecture de la position spécifiée directement à partir de la cellule de la feuille est un peu absurde. Par conséquent, il est bon de spécifier la plage lors de l'ajout d'un hit et de l'impression (df1).
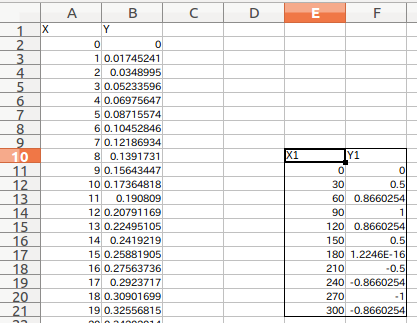
Résultat de lecture de la spécification de plage par iloc
Ici, si vous regardez df1 lu à partir de la plage spécifiée, De cette manière (illustré ci-dessous), il est lu en fonction des données de colonne (Sans nom :) du df parent, et X1 et Y1 sont également des données. Ces X1 et Y1 seront utilisés comme étiquettes pour la prochaine "trame de données enfant" à créer.
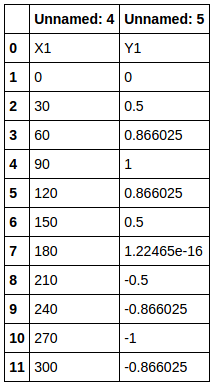
Extraire les données de colonne de la spécification de plage Lire le résultat par iloc
Par conséquent, extrayons les données de colonne (X1, Y1) de df1.
#Lister les colonnes de la première ligne → Utiliser dans les colonnes du bloc de données enfant
COL_LIST1=df1[0:1].values.flatten()
Ensuite COL_LIST1 renverra ['X1''Y1'] `` `.
J'ai obtenu les données de colonne que je voulais.
Créer un bloc de données enfant vide à l'aide de données de colonne
Créez un bloc de données enfant (co_df1) basé sur les données de colonne extraites. À ce stade, il n'y a que des données de colonne et aucun contenu.
#Trame de données enfant(empty)Créer, la colonne est le COL créé précédemment_LISTE
co_df1=pd.DataFrame({},columns=COL_LIST1,index=[])
Placer les données dans un bloc de données enfant
À l'aide de l'instruction for, chaque donnée de colonne (COL_LIST1) est bloquée dans chaque colonne du bloc de données de plage spécifié (df1). Déplacez les données vers un bloc de données enfant.
#Ecrire des données dans chaque colonne d'un bloc de données enfant(〜[1:]Récupérez les données après le libellé de la colonne en)
#Graph1
for i,col in enumerate(COL_LIST1):
#Lisez les données dans chaque colonne
co_df1[col]=df1[[i]][1:].reset_index(drop=True)
Avec df1 [[i]], les données des première et deuxième colonnes de df1 spécifiées et lues par iloc sont lues. Cependant, il contient également les données d'étiquette X1 et Y1. Donc df1[[i]][1:] Ce faisant, vous pouvez récupérer uniquement les données numériques à l'exclusion des données d'étiquette.
Cependant, si cela est laissé tel quel, les informations d'index d'origine restent et cela sera gênant plus tard. df1[[i]][1:].reset_index(drop=True) Et réinitialisez l'index.
Si vous placez ceci dans le bloc de données enfant vide co_df1 de manière séquentielle (uniquement dans COL_LIST1), le bloc de données enfant cible sera terminé.
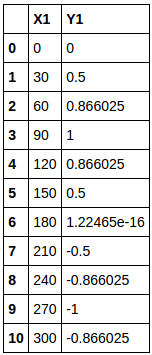
Extraire sous forme de données graphiques
Après cela, pour les données de l'axe x, y pour le tracé Jetez-le simplement.
x1=co_df1[[0]]
y1=co_df1[[1]]
Essayez de créer quatre graphiques de manière redondante
J'ai essayé de faire un graphique en convertissant toutes les données Excel X1, Y1 à X4, Y4 montrées au début en cadres de données enfants.
code
Collez celle représentée graphiquement avec quatre données enfants et celle avec une seule.
Version graphique 4
# coding: utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
#Spécifiez l'emplacement du fichier de police ubuntu(C:\Windows\Fonts\Toute police)
fp = FontProperties(fname="/usr/share/fonts/truetype/fonts-japanese-gothic.ttf")
####################################################################
filepath='~/Desktop/sample2.xls' #Emplacement du fichier xls
#Cadre de données parent
df=pd.read_excel(filepath) #Charger dans Pandas DataFrame
#Créer un bloc de données enfant à partir d'un bloc de données parent
#Spécifiez la plage de cellules que vous souhaitez représenter graphiquement
df1=df.iloc[8:20,4:6] #[Début de ligne: fin,Début de colonne:Fin]Précisez avec
df1=df1.reset_index(drop=True) #Relancer l'index
df2=df.iloc[8:20,7:9]
df2=df2.reset_index(drop=True)
df3=df.iloc[21:33,4:6]
df3=df3.reset_index(drop=True)
df4=df.iloc[21:33,7:9]
df4=df4.reset_index(drop=True)
#Colonne(Nom)Lis
COL_LIST1=df1[0:1].values.flatten() #Lister les colonnes de la première ligne → Utiliser dans les colonnes du bloc de données enfant
COL_LIST2=df2[0:1].values.flatten()
COL_LIST3=df3[0:1].values.flatten()
COL_LIST4=df4[0:1].values.flatten()
#Trame de données enfant(empty)Créer, la colonne est le COL créé précédemment_LISTE
co_df1=pd.DataFrame({},columns=COL_LIST1,index=[])
co_df2=pd.DataFrame({},columns=COL_LIST2,index=[])
co_df3=pd.DataFrame({},columns=COL_LIST3,index=[])
co_df4=pd.DataFrame({},columns=COL_LIST4,index=[])
#Ecrire des données dans chaque colonne d'un bloc de données enfant
#Graph1
for i,col in enumerate(COL_LIST1):
#Lisez les données dans chaque colonne
co_df1[col]=df1[[i]][1:].reset_index(drop=True)
#Graph2
for i,col in enumerate(COL_LIST2):
#Lisez les données dans chaque colonne
co_df2[col]=df2[[i]][1:].reset_index(drop=True)
#Graph3
for i,col in enumerate(COL_LIST3):
#Lisez les données dans chaque colonne
co_df3[col]=df3[[i]][1:].reset_index(drop=True)
#Graph4
for i,col in enumerate(COL_LIST4):
#Lisez les données dans chaque colonne
co_df4[col]=df4[[i]][1:].reset_index(drop=True)
#X dans le graphique,Extraction des données Y
#Cadre de données parent
x=df[[0]]
y=df[[1]]
#Trame de données enfant
x1=co_df1[[0]]
y1=co_df1[[1]]
x2=co_df2[[0]]
y2=co_df2[[1]]
x3=co_df3[[0]]
y3=co_df3[[1]]
x4=co_df4[[0]]
y4=co_df4[[1]]
####################################################################
#Graph
####################################################################
fig = plt.figure()
#Paramètres graphiques multiples
ax1 = fig.add_subplot(221) #Graph1
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(223)
ax4 = fig.add_subplot(224)
#réglage de l'échelle de l'axe y
ax1.set_yscale('linear')
ax2.set_yscale('linear')
ax3.set_yscale('log')
ax4.set_yscale('log')
#Gamme d'axes
ax1.set_ylim(-1.1, 1.1)
ax1.set_xlim(0,300)
ax2.set_ylim(0,10)
ax2.set_xlim(0,10)
ax3.set_ylim(1E+0,1E+5)
ax3.set_xlim(0,10)
ax4.set_ylim(1E-13,1E+1)
ax4.set_xlim(0,10)
#Titre individuel
ax1.set_title("Graph1",fontdict = {"fontproperties": fp},fontsize=12)
ax2.set_title("Graph2",fontdict = {"fontproperties": fp},fontsize=12)
ax3.set_title("Graph3",fontdict = {"fontproperties": fp},fontsize=12)
ax4.set_title("Graph4",fontdict = {"fontproperties": fp},fontsize=12)
#axe
ax1.set_xlabel("x",fontdict = {"fontproperties": fp},fontsize=12)
ax1.set_ylabel("y",fontdict = {"fontproperties": fp},fontsize=12)
#terrain
ax1.plot(x1, y1,'blue',label='graph1')
ax2.plot(x2, y2,'green',label='graph2')
ax3.plot(x3, y3,'red',label='graph3')
ax4.plot(x4, y4,'black',label='graph4')
#Position de la légende
ax1.legend(loc="upper right")
ax2.legend(loc="upper left")
ax3.legend(loc="upper left")
ax4.legend(loc="upper left")
#Ajustement de la mise en page
plt.tight_layout()
#Le titre du graphique entier
fig.suptitle('Graph', fontsize=14)
plt.subplots_adjust(top=0.85)
#Enregistrer le fichier Enregistrer au format png et eps
plt.savefig("sample.png ")
plt.savefig("sample.eps")
plt.show()
Version graphique 1
# coding: utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
#Spécifiez l'emplacement du fichier de police ubuntu(C:\Windows\Fonts\Toute police)
fp = FontProperties(fname="/usr/share/fonts/truetype/fonts-japanese-gothic.ttf")
####################################################################
filepath='~/Desktop/sample2.xls' #Emplacement du fichier xls
#Cadre de données parent
df=pd.read_excel(filepath) #Charger dans Pandas DataFrame
#Créer un bloc de données enfant à partir d'un bloc de données parent
#Spécifiez la plage de cellules que vous souhaitez représenter graphiquement
df1=df.iloc[8:20,4:6] #[Début de ligne: fin,Début de colonne:Fin]Précisez avec
df1=df1.reset_index(drop=True) #Relancer l'index
#Colonne(Nom)Lis
COL_LIST1=df1[0:1].values.flatten() #Lister les colonnes de la première ligne → Utiliser dans les colonnes du bloc de données enfant
#Trame de données enfant(empty)Créer, la colonne est le COL créé précédemment_LISTE
co_df1=pd.DataFrame({},columns=COL_LIST1,index=[])
#Ecrire des données dans chaque colonne d'un bloc de données enfant(〜[1:]Récupérez les données après le libellé de la colonne en)
#Graph1
for i,col in enumerate(COL_LIST1):
#Lisez les données dans chaque colonne
co_df1[col]=df1[[i]][1:].reset_index(drop=True)
#X dans le graphique,Extraction des données Y
#Cadre de données parent
x=df[[0]]
y=df[[1]]
#Trame de données enfant
x1=co_df1[[0]]
y1=co_df1[[1]]
####################################################################
#Graph
####################################################################
fig = plt.figure()
#Paramètres graphiques multiples
ax1 = fig.add_subplot(111) #Graph1
#réglage de l'échelle de l'axe y
ax1.set_yscale('linear')
#Gamme d'axes
ax1.set_ylim(-1.1, 1.1)
ax1.set_xlim(0,300)
#Titre individuel
ax1.set_title("Graph1",fontdict = {"fontproperties": fp},fontsize=12)
#axe
ax1.set_xlabel("x",fontdict = {"fontproperties": fp},fontsize=12)
ax1.set_ylabel("y",fontdict = {"fontproperties": fp},fontsize=12)
#terrain
ax1.plot(x1, y1,'blue',label='graph1')
#Position de la légende
ax1.legend(loc="upper right")
#Ajustement de la mise en page
plt.tight_layout()
#Le titre du graphique entier
fig.suptitle('Graph', fontsize=14)
plt.subplots_adjust(top=0.85)
#Enregistrer le fichier Enregistrer au format png et eps
plt.savefig("sample.png ")
plt.savefig("sample.eps")
plt.show()
Recommended Posts