[PYTHON] Traçage de données polyvalent avec pandas + matplotlib
Python comme langage de calcul scientifique et technologique
Pourquoi les calculs scientifiques et technologiques tels que l'analyse des données sont-ils effectués en Python en premier lieu? Cela dépend principalement des deux points suivants.
- Des bibliothèques étendues telles que NumPy, pandas, matplotlib sont disponibles
- Peut être utilisé comme un langage de colle très polyvalent
R peut être plus facile si vous ne faites que des calculs en utilisant des blocs de données et en les traçant. Cependant, compléter l'analyse statistique avec Python polyvalent permet une plus large gamme d'applications dans divers domaines.
NumPy
La plupart des analyses statistiques impliquent des opérations vectorielles. NumPy propose ndarray, une implémentation rapide et économe en mémoire de tableaux multidimensionnels. Il permet des opérations vectorielles de grande dimension qui ne peuvent pas être réalisées avec des tableaux et des objets de hachage inhérents aux langages de programmation. Vous pouvez également faire des références d'index sophistiquées (= utiliser des tableaux d'entiers pour les références d'index).
Opération scalaire vectorielle
Le calcul scientifique et technologique étant compliqué, il serait difficile d'écrire une boucle pour chaque élément du vecteur. Par conséquent, on peut dire que le calcul vectoriel est presque indispensable. Dans NumPy, vous pouvez également écrire des opérations ndarray et scalaires comme suit:
arr = np.array ( [[1., 2., 3.], [4., 5., 6.]] ) #objet ndarray
arr * arr #Intégration vectorielle
# => array([[ 1., 4., 9.],
# [ 16., 25., 36.]])
arr - arr #Soustraction vectorielle
# => array([[ 0., 0., 0.],
# [ 0., 0., 0.]])
1 / arr #Arithmétique scalaire et ndarray
# => array([[ 1. , 0.5 , 0.33333333],
# [ 0.25 , 0.2 , 0.16666667]])
arr2d = np.array ([[1,2,3],[4,5,6],[7,8,9]])
arr2d[:2] #Référence d'index par tranche
# => array([[1, 2, 3],
# [4, 5, 6]])
arrf = np.arange(32).reshape((8,4))
arrf # => array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11],
# [12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23],
# [24, 25, 26, 27],
# [28, 29, 30, 31]])
arrf[[1,5,7,2]][:,[0,3,1,2]] #Voir l'index de fantaisie
# => array([[ 4, 7, 5, 6],
# [20, 23, 21, 22],
# [28, 31, 29, 30],
# [ 8, 11, 9, 10]])
Redéfinir la structure des données avec les pandas
Alors que NumPy seul est très utile, les pandas offrent une structure de données encore plus semblable à R. Ce sont la série et le DataFrame. Le terme trame de données est également fréquemment utilisé dans R, de sorte que ceux qui ont utilisé R le connaîtront. Une série est un objet de type tableau unidimensionnel et un bloc de données a une structure de données tabulaire en ligne et en colonne.
Tracer avec des pandas + matplotlib
Matplotlib, qui apparaît souvent dans les articles jusqu'à Hier, est une bibliothèque puissante pour la visualisation de données. En combinant cela avec des pandas, vous pouvez dessiner et visualiser divers résultats d'analyse de données. Bougeons immédiatement nos mains car nous donnerons des explications détaillées sur les manuels et les sites Web officiels.
Tracé de série
from pylab import *
from pandas import *
import matplotlib.pyplot as plt
import numpy as np
ts = Series(randn(1000), index=date_range('1/1/2000', periods=1000))
ts = ts.cumsum()
ts.plot()
plt.show()
plt.savefig("image.png ")
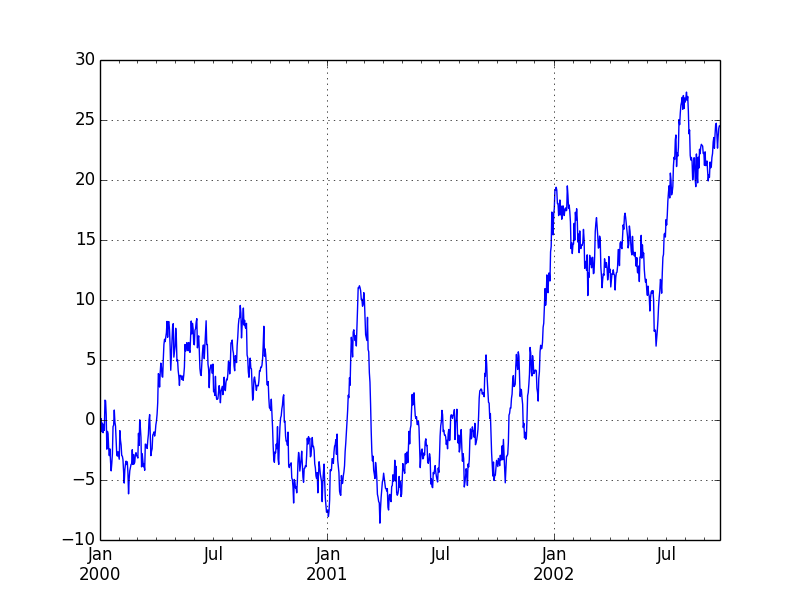
Tracé de trame de données
Afin de gérer le japonais avec matplotlib, il est nécessaire de spécifier la police. Essayons d'utiliser le japonais.
# -*- coding: utf-8 -*-
from pylab import *
from pandas import *
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import font_manager #Obligatoire pour utiliser le japonais
fontprop = matplotlib.font_manager.FontProperties(fname="/usr/share/fonts/truetype/fonts-japanese-gothic.ttf") #Spécifiez l'emplacement du fichier de police
df = DataFrame(randn(1000, 4), index=ts.index, columns=list('ABCD'))
df = df.cumsum()
plt.figure()
df.plot()
plt.legend(loc='best')
ax = df.plot(secondary_y=['A', 'B'])
ax.set_ylabel('Ventes de CD', fontdict = {"fontproperties": fontprop})
ax.right_ax.set_ylabel('Échelle AB', fontdict = {"fontproperties": fontprop})
plt.show()
plt.savefig("image2.png ")
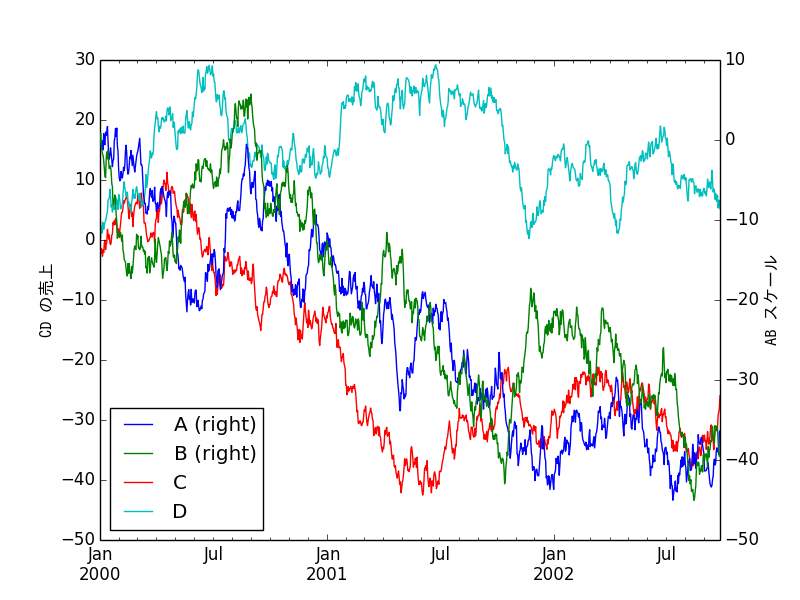
Le japonais est affiché. En fait, vous devriez ajuster un peu plus les paramètres de police.
Sous-repérage
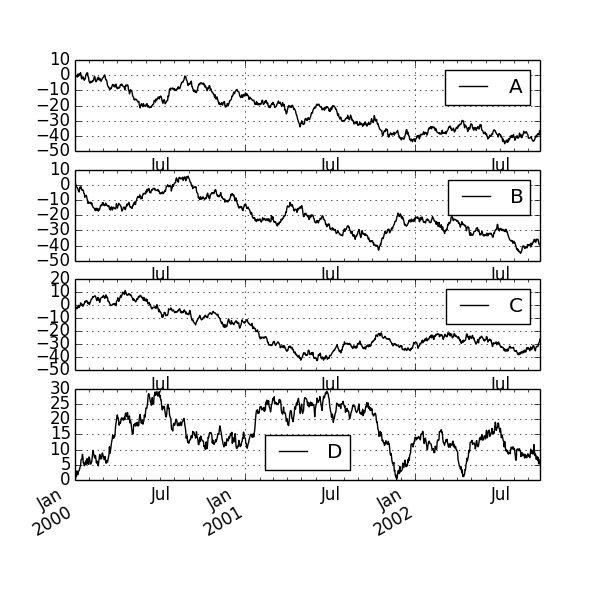
matplotlib permet également au sous-tracé de dessiner des tracés dans les tracés.
df.plot(subplots=True, figsize=(6, 6)); plt.legend(loc='best')
plt.show()
plt.savefig("image3.png ")
fig, axes = plt.subplots(nrows=2, ncols=2)
df['A'].plot(ax=axes[0,0]); axes[0,0].set_title('A')
df['B'].plot(ax=axes[0,1]); axes[0,1].set_title('B')
df['C'].plot(ax=axes[1,0]); axes[1,0].set_title('C')
df['D'].plot(ax=axes[1,1]); axes[1,1].set_title('D')
plt.show()
plt.savefig("image4.png ")
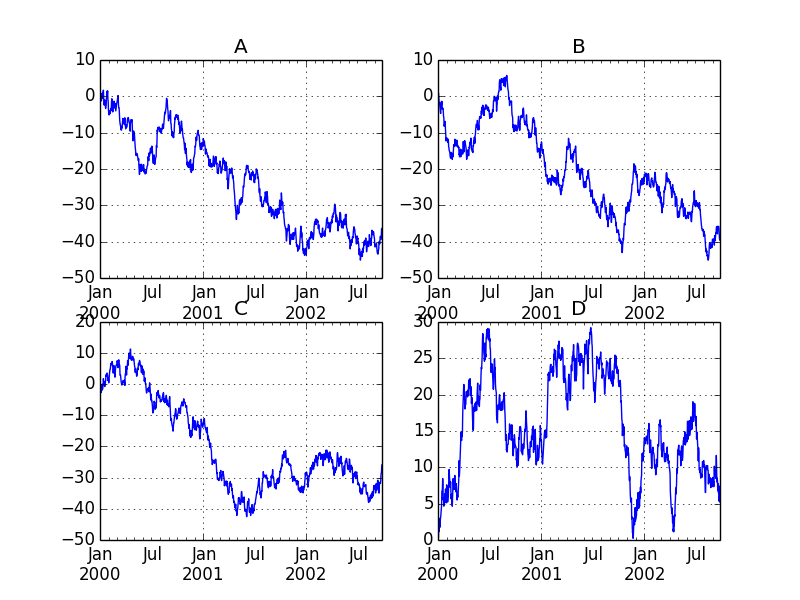
Graphique à barres
plt.figure();
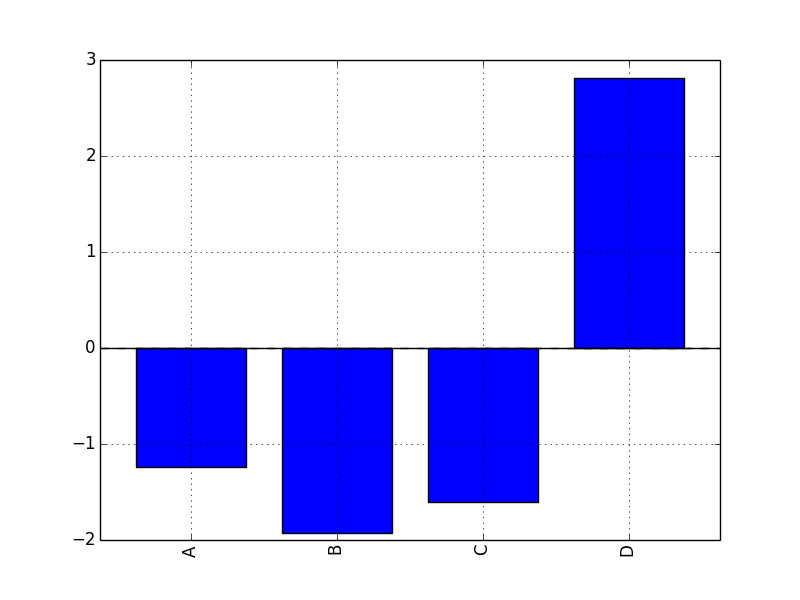
df.ix[5].plot(kind='bar'); plt.axhline(0, color='k')
plt.show()
plt.savefig("image5.png ")
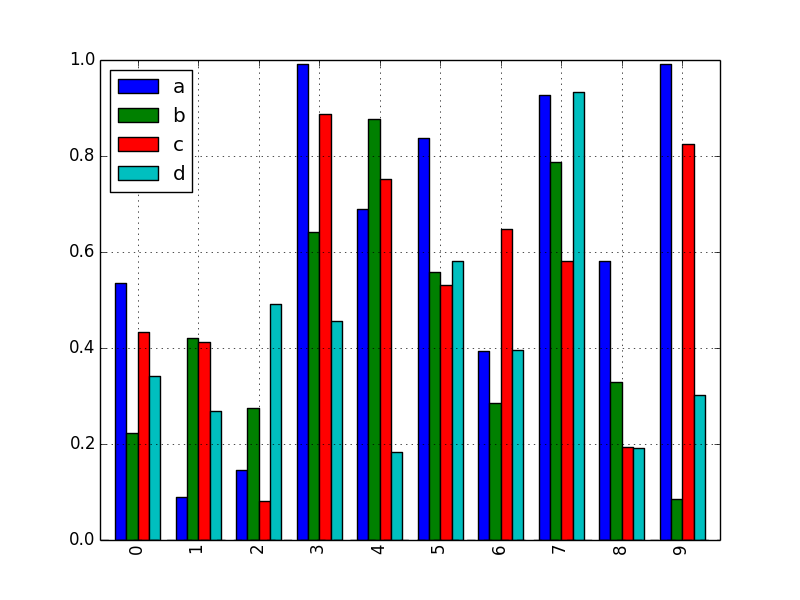
df2 = DataFrame(rand(10, 4), columns=['a', 'b', 'c', 'd'])
df2.plot(kind='bar');
plt.show()
plt.savefig("image6.png ")
Sous-repérage du graphique à barres
Bien entendu, les graphiques à barres (tout autre) peuvent également être sous-notés.
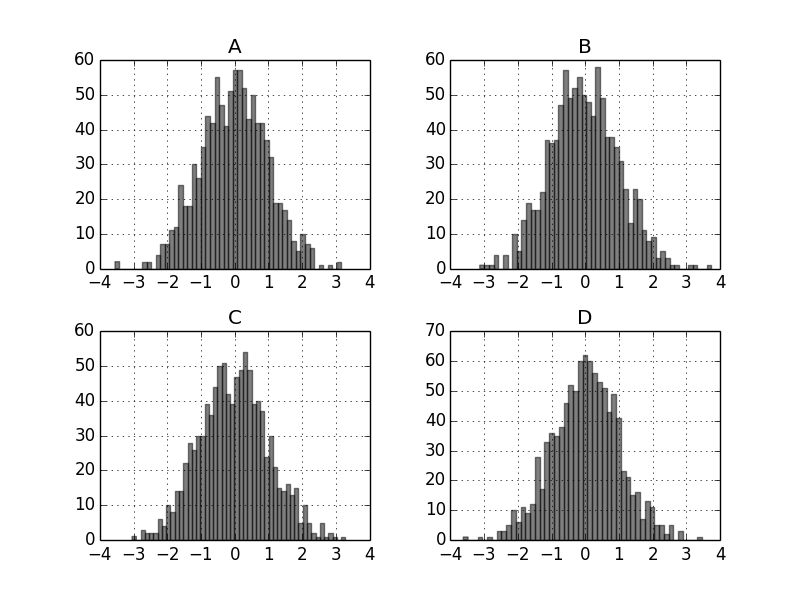
df.diff().hist(color='k', alpha=0.5, bins=50)
plt.show()
plt.savefig("image8.png ")
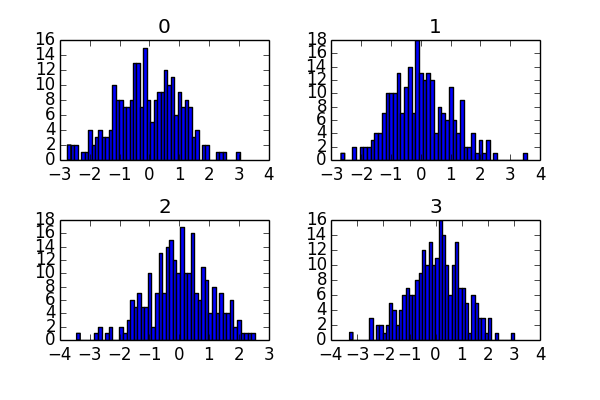
data = Series(randn(1000))
data.hist(by=randint(0, 4, 1000), figsize=(6, 4))
plt.show()
plt.savefig("image9.png ")
Visualisation de données diverses
matplotlib peut tracer une grande variété d'autres graphiques, mais en voici quelques-uns.
from pandas.tools.plotting import bootstrap_plot
data = Series(rand(1000))
bootstrap_plot(data, size=50, samples=500, color='grey')
plt.show()
plt.savefig("image12.png ")
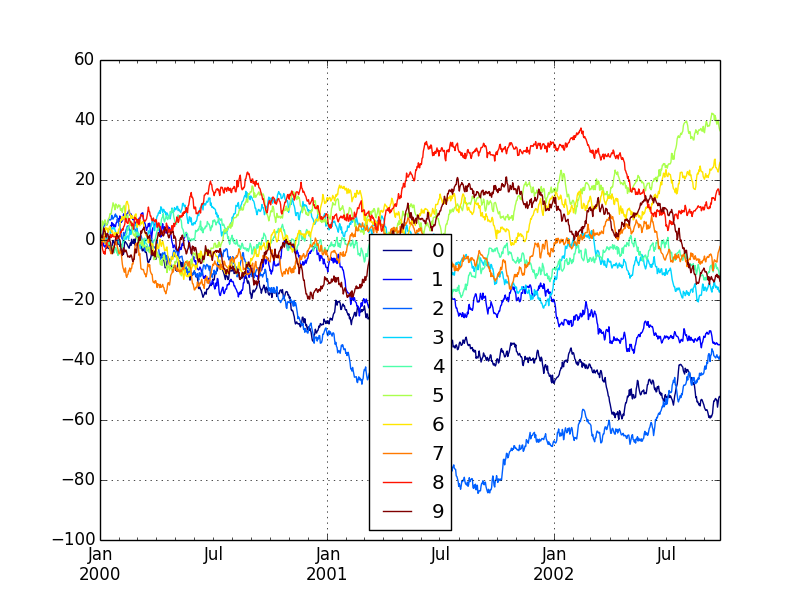
df = DataFrame(randn(1000, 10), index=ts.index)
df = df.cumsum()
plt.figure()
df.plot(colormap='jet')
plt.show()
plt.savefig("image13.png ")
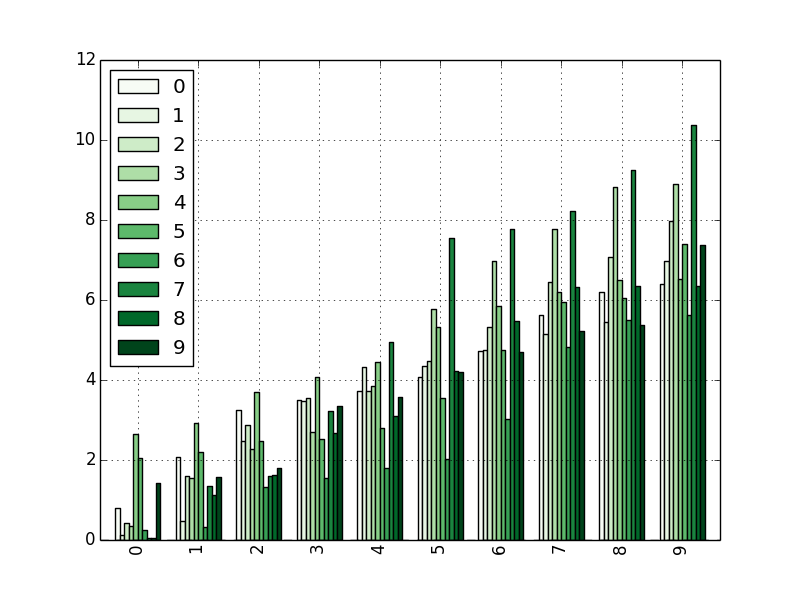
dd = DataFrame(randn(10, 10)).applymap(abs)
dd = dd.cumsum()
plt.figure()
dd.plot(kind='bar', colormap='Greens')
plt.show()
plt.savefig("image14.png ")
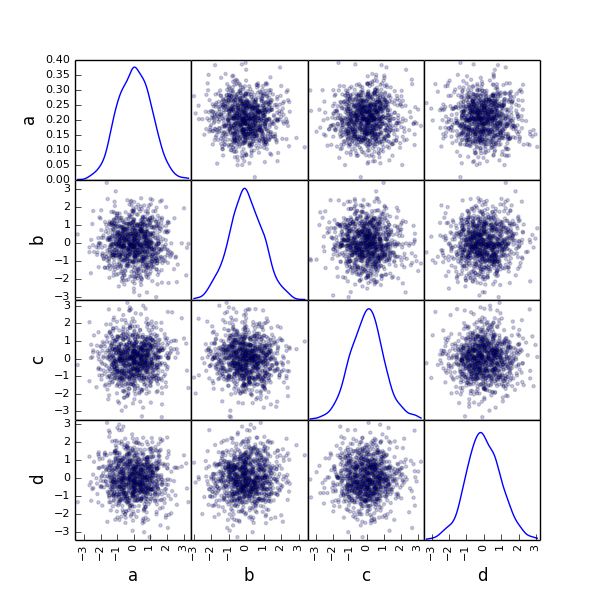
from pandas.tools.plotting import scatter_matrix
df = DataFrame(randn(1000, 4), columns=['a', 'b', 'c', 'd'])
scatter_matrix(df, alpha=0.2, figsize=(6, 6), diagonal='kde')
plt.show()
plt.savefig("image11.png ")
Considération
Nous avons constaté que NumPy fournit des opérations vectorielles avancées, que les pandas fournissent des structures de données de type R et que matplotlib fournit une visualisation facile à comprendre de leurs calculs. Avec un outil aussi puissant, ce serait très encourageant pour l'analyse des données. En statistique et en apprentissage automatique, les calculs liés à l'algèbre linéaire sont presque indispensables, mais il est important de se familiariser d'abord avec ces bibliothèques avec ces connaissances.
référence
Pour une explication détaillée, veuillez vous référer aux informations sur chaque site officiel.
NumPy http://www.numpy.org/
pandas http://pandas.pydata.org/
matplotlib http://matplotlib.org/#
Recommended Posts