[PYTHON] Visualisez de manière interactive les données avec Treasure Data, Pandas et Jupyter.
introduction
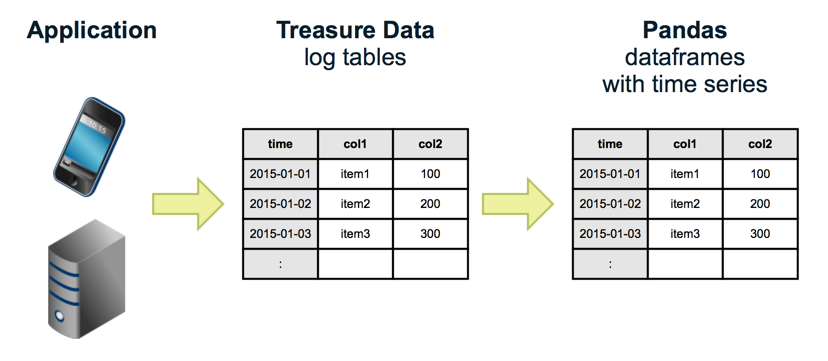
TreasureData est un service cloud qui vous permet de collecter, stocker et analyser facilement des données chronologiques telles que les journaux d'applications et les données de capteurs. Actuellement, Presto est disponible comme l'un des moteurs d'analyse, et les données collectées peuvent être analysées de manière interactive avec SQL. devenu.
Cependant, TreasureData n'a pas la fonction de visualisation basée sur les données analysées par SQL, il est donc nécessaire d'effectuer la visualisation à l'aide d'un outil externe tel qu'Excel ou Tableau.
Donc cette fois, nous avons Pandas, qui est une bibliothèque Python populaire, et Jupyter, qui vous permet d'exécuter Python de manière interactive avec un navigateur Web. En utilisant, nous exécuterons SQL de manière interactive avec TreasureData pour l'agrégation et la visualisation.
installer
Environnement d'utilisation
- Ubuntu 14.04
- Python 3.4
- Pandas
- Jupyterhub
TreasureData
S'inscrire
Inscrivez-vous à partir de la page ici. Actuellement, il existe une période d'essai de 14 jours pendant laquelle vous pouvez utiliser Presto.
Pandas
Pandas est un outil qui ressemble à ce qui suit, lorsqu'il est cité par le fonctionnaire.
pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
Installation de Python
Ubuntu14.04 inclut Python3.4, mais python3 est un alias et il est gênant, nous allons donc créer l'environnement avec pyenv.
Référence: http://qiita.com/akito1986/items/be5dcd1a502aaf22010b
$ sudo apt-get install git gcc g++ make openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev
$ cd /usr/local/
$ sudo git clone git://github.com/yyuu/pyenv.git ./pyenv
$ sudo mkdir -p ./pyenv/versions ./pyenv/shims
$ echo 'export PYENV_ROOT="/usr/local/pyenv"' | sudo tee -a /etc/profile.d/pyenv.sh
$ echo 'export PATH="${PYENV_ROOT}/shims:${PYENV_ROOT}/bin:${PATH}"' | sudo tee -a /etc/profile.d/pyenv.sh
$ source /etc/profile.d/pyenv.sh
$ pyenv -v
pyenv 20150601-1-g4198280
$ sudo visudo
#Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
Defaults env_keep += "PATH"
Defaults env_keep += "PYENV_ROOT"
$ sudo pyenv install -v 3.4.3
$ sudo pyenv global 3.4.3
$ sudo pyenv rehash
Installer Pandas
$ sudo pip install --upgrade pip
$ sudo pip install pandas
Essayez d'utiliser Pandas depuis le shell
Veuillez vous reporter à 10 minutes aux pandas.
Jupyter
Jupyter était à l'origine un shell interactif d'un navigateur Web pour Python appelé IPython, mais il est maintenant renommé et développé dans le but de le rendre disponible dans n'importe quel langage. De plus, JupyerHub est une version serveur de Jupyter qui permet à plusieurs utilisateurs d'utiliser Jupyter, ce qui facilite le partage des blocs-notes créés avec Juypter.
Installez Jupyter Hub
$ sudo apt-get install npm nodejs-legacy
$ sudo npm install -g configurable-http-proxy
#Bibliothèques associées
$ sudo pip install zmq jsonschema
#Bibliothèque de visualisation
$ sudo apt-get build-dep python-matplotlib
$ sudo pip install matplotlib
$ git clone https://github.com/jupyter/jupyterhub.git
$ cd jupyterhub
$ sudo pip install -r requirements.txt
$ sudo pip install .
$ sudo passwd ubuntu
$ jupyterhub
Vous pouvez maintenant ouvrir et accéder à Jupter depuis votre navigateur Web. http://(IP address):8000/
Pour d'autres paramètres détaillés de JupyterHub, reportez-vous à here.
Utilisez les pandas de Jupyter
Tout d'abord, essayez de vous connecter. Ensuite, le répertoire des utilisateurs de l'utilisateur connecté s'affiche. Ici, créez un répertoire de travail pour Jupyter et créez un bloc-notes pour enregistrer votre travail.
Sélectionnez Nouveau-> Notebooks (Python3).

Vous pouvez enregistrer une séquence de commandes Python dans ce bloc-notes.
Maintenant, testons en nous basant sur here.
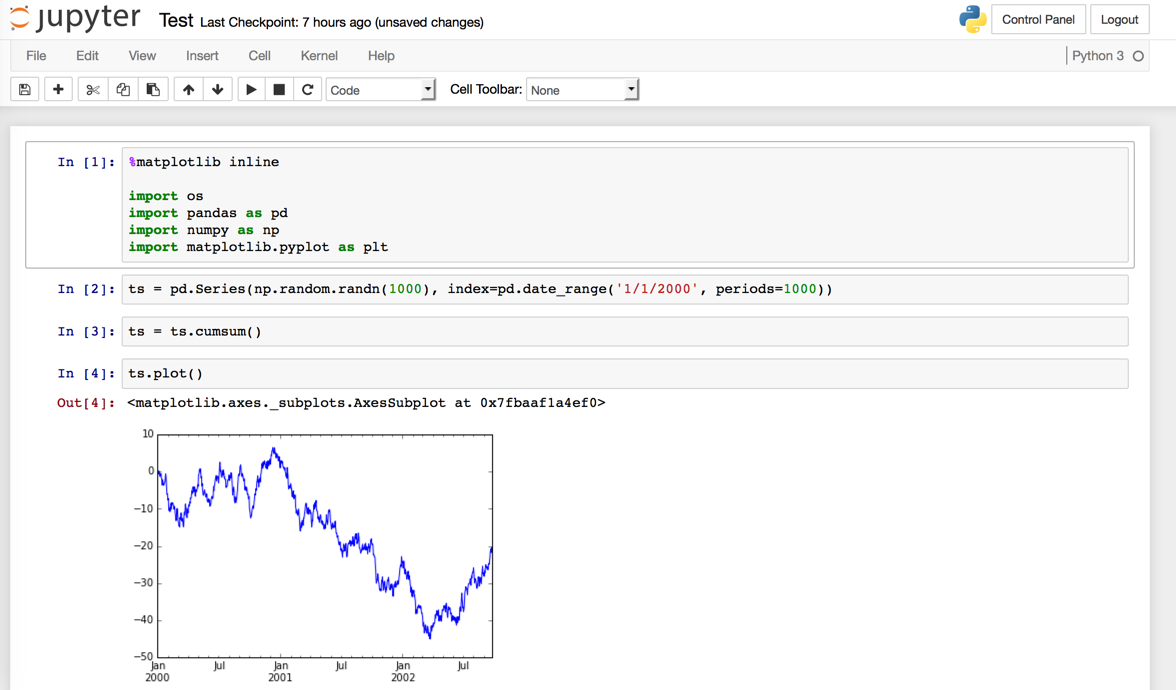
%matplotlib inline
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
ts = ts.cumsum()
ts.plot()
ToDo: Il semble que la première importation puisse être omise avec la configuration suivante, mais cela n'a pas encore été bien fait, donc je vérifie ...
$ jupyterhub --generate-config
Writing default config to: jupyterhub_config.py
$ vi jupyterhub_config.py
c.IPKernelApp.matplotlib = 'inline'
c.InteractiveShellApp.exec_lines = [
'import pandas as pd',
'import numpy as np',
'import matplotlib.pyplot as plt',
]
$ mv jupyterhub_config.py .ipython/profile_default/
Intégration de Treasure Data et Pandas à l'aide de pandas-td
Maintenant que vous devriez pouvoir utiliser Pandas et Jupyter, j'aimerais accéder à Treasure Data.
Ici, nous utiliserons une bibliothèque appelée pandas-td. En utilisant cela, vous pourrez faire trois choses.
- Mettez les données dans le tableau de TreasureData
- Extraire les données de la table TreasureData
- Interrogez avec TreasureData pour obtenir des résultats
Installation
$ sudo pip install pandas-td
Paramètres de connexion
%matplotlib inline
import os
import pandas as pd
import pandas_td as td
#C'est pratique si vous le mettez dans la variable d'environnement
#con = td.connect(apikey="os.environ['TD_API_KEY']", endpoint='https://api.treasuredata.com/')
con = td.connect(apikey="TD API KEY", endpoint='https://api.treasuredata.com/')
Émettre une requête
engine = con.query_engine(database='sample_datasets', type='presto')
# Read Treasure Data query into a DataFrame.
df = td.read_td('select * from www_access', engine)
df
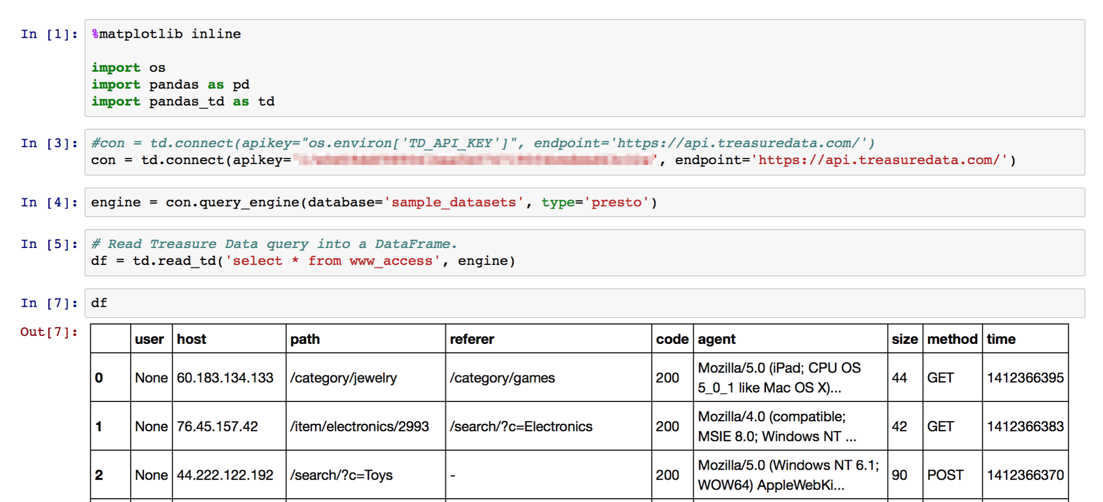
Jetez un œil à certaines des données
engine = con.query_engine(database='sample_datasets', type='presto')
con.tables('sample_datasets')
td.read_td_table('nasdaq', engine, limit=3, index_col='time', parse_dates={'time': 's'})
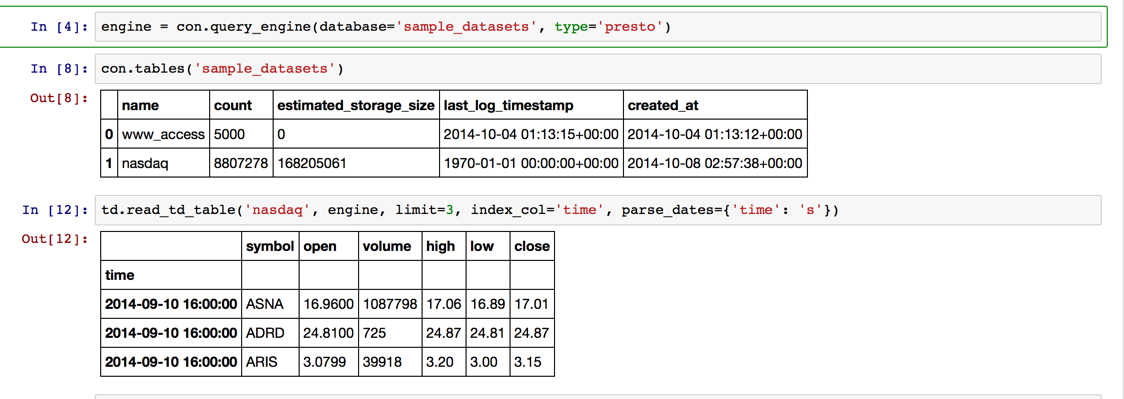
Obtenez en réduisant la période, agrégez par date et visualisez
df = td.read_td_table('nasdaq', engine, limit=None, time_range=('2010-01-01', '2010-02-01'), index_col='time', parse_dates={'time': 's'})
df.groupby(level=0).volume.sum().plot()
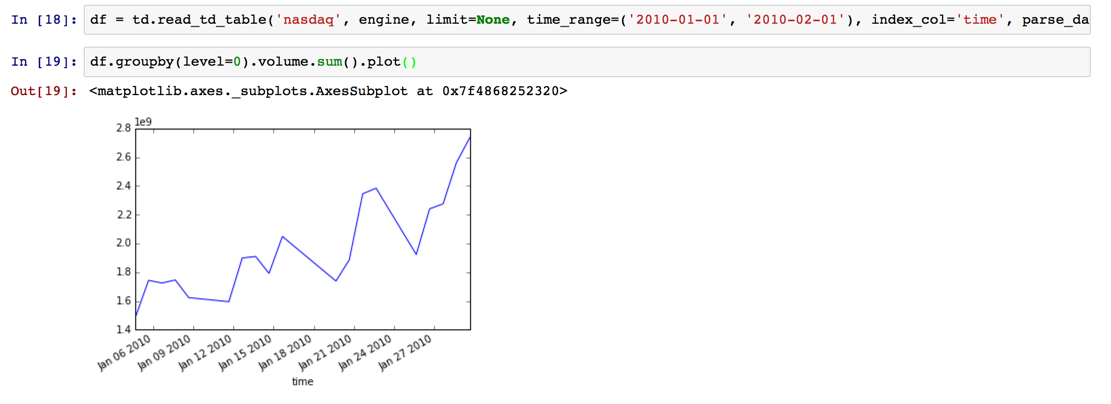
Ce qui est pratique
Vous pouvez facilement réécrire le traitement intermédiaire et réessayer. S'il est d'environ plusieurs millions, il peut être traité sur la mémoire en fonction du résultat téléchargé. Vous pouvez également importer des données à partir de fichiers MySQL et CSV.
etc.
en conclusion
Je ne peux pas nier le sentiment d'épuisement en cours de route, alors j'écrirai bientôt plus correctement.
Recommended Posts