[PYTHON] Visualisez les données d'itinéraires ferroviaires sous forme de graphique avec Cytoscape 2
introduction
Cette série utilise Cytoscape, IPython Notebook, [Pandas](http: // pandas) Il s'agit d'un article destiné aux professionnels de la visualisation qui présente le processus de visualisation des graphiques basés sur des données publiques à l'aide d'outils open source tels que .pydata.org /).
Journal des modifications
- 17/08/2014 (dim.): Certains chiffres et phrases ont été mis à jour.
- 9/8/2014: Il a été terminé pour le moment lors de la 4e session.
Traitement des données dans un environnement interactif
 __ Figure 1__: Un graphique reliant les systèmes ferroviaires partout au Japon. La version haute résolution est ici
__ Figure 1__: Un graphique reliant les systèmes ferroviaires partout au Japon. La version haute résolution est ici
introduction
Dernière fois a traité le fichier téléchargé depuis la source de données à l'aide de IPython Notebook. Nous l'avons même chargé dans Cytoscape. Cependant, dans l'état précédent, il n'y a aucun problème pour organiser les nœuds (stations) en utilisant la latitude et la longitude, mais les données d'itinéraire proprement dites ne sont pas un graphique. La figure ci-dessous montre un autre [algorithme de mise en page] automatique (http://en.wikipedia.org/wiki/%E5%8A%9B%E5%AD%A6%E3%83%A2%E3%83] à partir des données précédentes. % 87% E3% 83% AB_ (% E3% 82% B0% E3% 83% A9% E3% 83% 95% E6% 8F% 8F% E7% 94% BB% E3% 82% A2% E3% 83% Visualisé avec AB% E3% 82% B4% E3% 83% AA% E3% 82% BA% E3% 83% A0)):
 (La version haute résolution est ici)
(La version haute résolution est ici)
Si vous effectuez un zoom avant, vous pouvez voir qu'il existe des connexions pour chaque ligne, mais chacune existe indépendamment:
Avec cela, la mise en page automatique, la recherche de chemin et d'autres fonctions ne fonctionneront pas bien. Tout d'abord, j'aimerais résoudre ce problème en programmant de manière interactive avec IPython Notebook comme auparavant, puis intégrer et visualiser les données fournies par les institutions publiques.
Ce but
- Connectez les itinéraires connectés avec différents types d'arêtes pour convertir les données d'itinéraire divisées en données graphiques nationales.
- Obtenir des données relatives au nombre de passagers montant et descendant de la gare auprès d'une institution publique et les traiter sous une forme lisible par Cytoscape.
- Obtenez la couleur du thème de chaque itinéraire sur Wikipédia et transformez-la en CSV
- Intégrez toutes les données sur Cytoscape et créez un échantillon de visualisation
Un cahier qui enregistre le travail réel
Je l'ajouterai de temps en temps, mais vous pouvez voir le compte rendu du travail réel ici:
Cela peut être fait sur votre ordinateur tant que les bibliothèques utilisées dans votre ordinateur portable sont installées. Même si vous n'êtes pas un programmeur Python, vous ne faites rien de compliqué, vous pouvez donc le comprendre en suivant les instructions dans les notes. Le prétraitement des données effectué dans le notebook est le suivant.
À propos de la construction d'environnement lors de l'utilisation de Python
En gros, je travaille sur un système d'exploitation basé sur UNIX, mais dans ce cas, il est pratique de créer un environnement avec Anaconda:
Pour ce type de nettoyage des données, Pandas, [NumPy](http: // www) J'utilise souvent des bibliothèques telles que .numpy.org /) et SciPy, mais elles prennent bien soin des dépendances des bibliothèques ici. De plus, cela fonctionne bien avec la commande pip. Installation de la bibliothèque
conda install LIBRARY_NAME
Vous ne devez penser à rien car vous pouvez presque le résoudre avec la commande.
Détails du travail de préparation des données
Voyons maintenant ce qui se passe dans les notes. Si possible, il sera plus facile de comprendre si vous lisez tout en exécutant réellement les notes.
Connectez les données d'itinéraire disjointes pour chaque groupe de stations
Établissez une connexion en utilisant les informations appelées Station Group dans les données d'origine. Être dans le même groupe signifie que vous pouvez transférer tel quel ou que ces stations sont accessibles à pied. Par conséquent, on peut considérer que les stations du groupe sont pratiquement connectées à d'autres lignes. Dans le travail réel, nous allons connecter ces stations dans le même groupe avec un nouveau bord, et [Creek](http://ja.wikipedia.org/wiki/%E3%82%AF%E3%83%AA % E3% 83% BC% E3% 82% AF_ (% E3% 82% B0% E3% 83% A9% E3% 83% 95% E7% 90% 86% E8% AB% 96)) Masu:
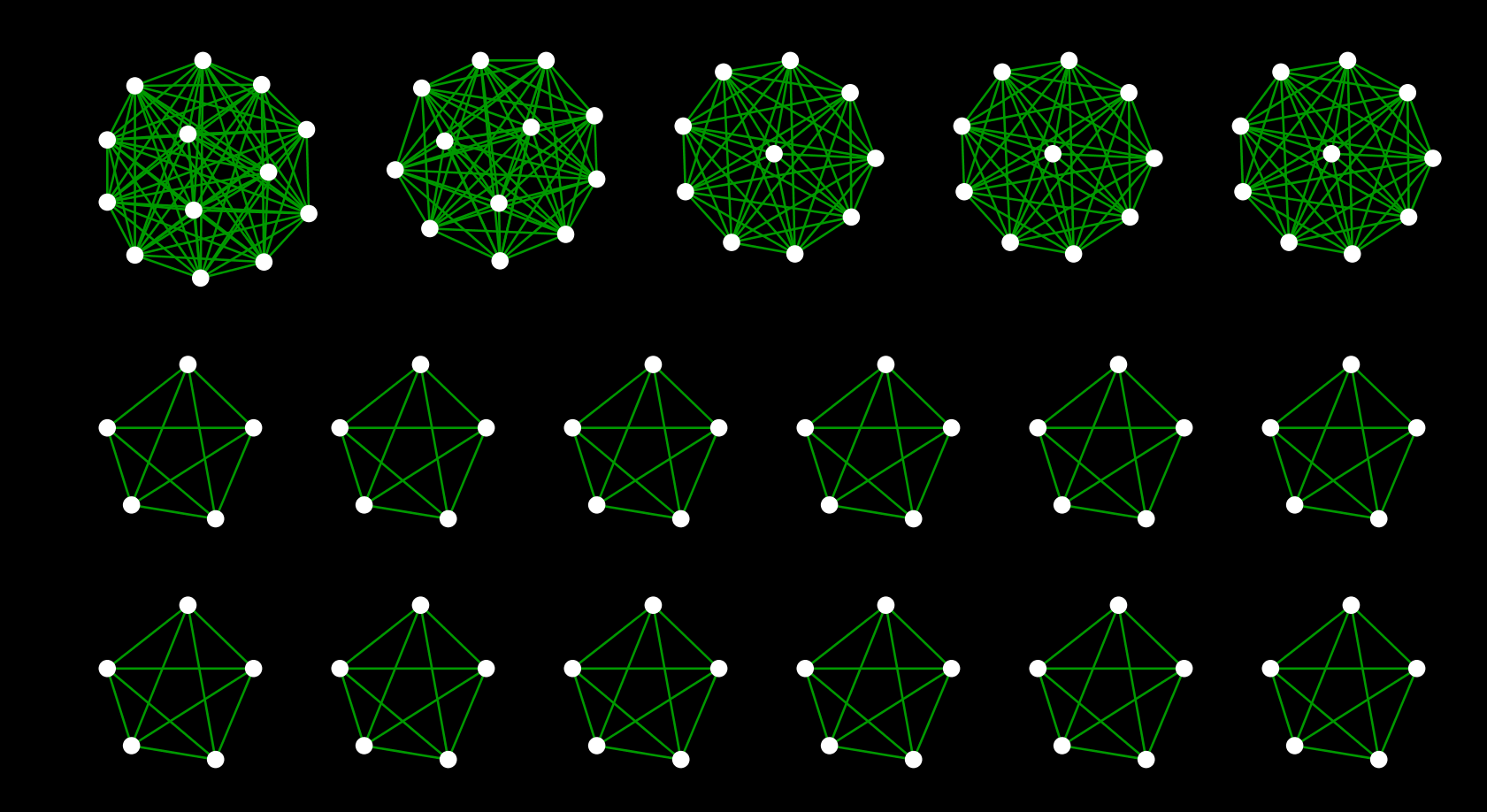 __ Figure 2 __: Une partie du ruisseau créé
__ Figure 2 __: Une partie du ruisseau créé
En fusionnant ces ruisseaux avec les données d'itinéraire d'origine, nous formerons un réseau ferroviaire qui relie les itinéraires à l'échelle nationale, comme le montre la Figure 1.
Vérifiez l'état du graphe connecté
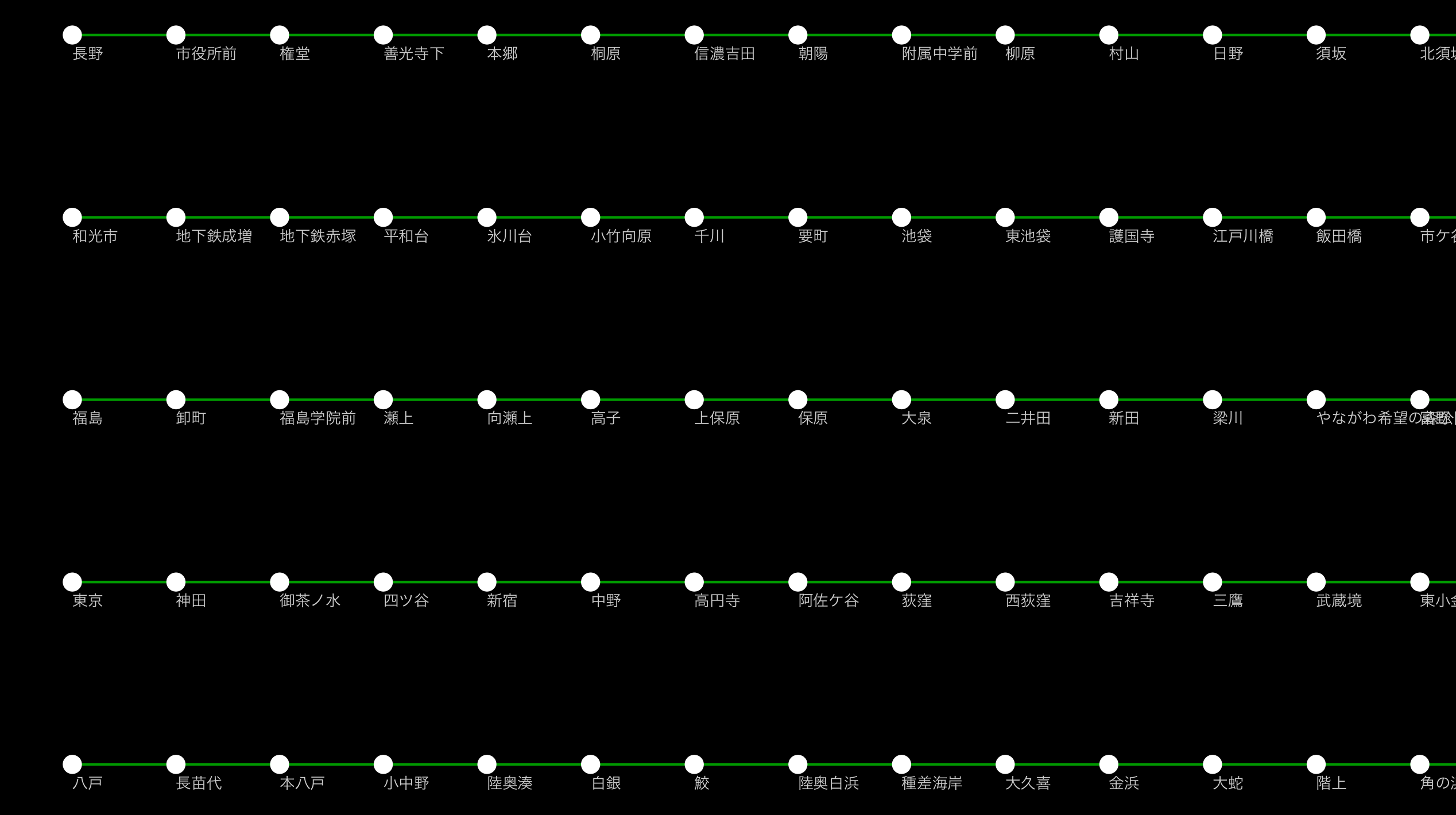
Ici, un peu en retrait de la route secondaire, comment la crique a été incorporée est la plus grande station du Japon [Shinjuku](http://ja.wikipedia.org/wiki/%E6%96%B0%E5%AE Prenons% BF% E9% A7% 85) comme exemple. La gare de Shinjuku est une énorme plaque tournante du réseau ferroviaire, chaque ligne ferroviaire étant reliée. __ Si vous visualisez cela, vous devriez être en mesure de voir les ruisseaux constitués de stations appartenant au même groupe et chaque ligne s'étendant radialement à partir de là __. Je l'ai essayé pour confirmation. Je vais omettre la partie à lire dans Cytoscape (pour l'instant), mais l'opération de base pour faire la figure suivante est
- Sélectionnez Shinjuku Station Group sur la carte routière nationale
- Extraire les stations qui existent dans 1 saut à partir de là (CTR-6 sur Windows / Linux Command + 6 sur Mac)
- Créer un nouveau réseau à partir du graphe partiel lavé (CTR + N sous Windows / Linux, Command + N sur Mac)
- Appliquer l'algorithme de disposition de l'anneau au groupe de stations de Shinjuku et à d'autres
- Créez un style simple pour distinguer les bords d'un groupe des autres
Si vous faites cela, vous pouvez dessiner un diagramme comme celui ci-dessous:
 (
(La ligne pointillée verte indique l'itinéraire transférable (à distance de marche) et la ligne continue indique chaque itinéraire. Pour autant que je puisse voir cela, il semble que la connexion a réussi.
Cartographier d'autres ensembles de données publiés sur le réseau ferroviaire
Vous avez maintenant une "carte blanche des chemins de fer" que vous pouvez utiliser sur Cytoscape. Il y a une raison d'appeler ces données une carte blanche. C'est parce que __ vous pouvez librement mapper d'autres ensembles de données sur ce réseau pour créer vos propres visualisations __. C'est l'avantage de déposer des données géographiques dans une structure de graphe conceptuel, et l'intérêt de les utiliser dans Cytoscape. Il existe une myriade de mappages possibles, mais un exemple simple est:
- Découpez l'itinéraire qui vous intéresse sous forme de sous-graphique et cartographiez visuellement le nombre de passagers par jour.
- Calculez le nombre de personnes pouvant être déplacées par itinéraire (nombre de trains par jour x capacité du train) et mappez le flux approximatif de passagers à l'épaisseur du bord.
- Découpez une certaine ligne, extrayez les installations le long de la ligne à partir d'autres données géographiques et connectez-vous à la station la plus proche en utilisant un nouveau bord. Donnez-leur une nouvelle mise en page et [Infographie](http://en.wikipedia.org/wiki/%E3%82%A4%E3%83%B3%E3%83%95%E3%82%A9% E3% 82% B0% E3% 83% A9% E3% 83% 95% E3% 82% A3% E3% 83% 83% E3% 82% AF)
Ce sont tous des exemples simples, mais plus vous pouvez mapper de données, plus grandes sont les possibilités de visualisation ultérieure. Tout d'abord, j'ai pensé qu'il pourrait y avoir des données simples pour que je puisse expérimenter les fonctions de base, mais j'ai pensé qu'il serait facile de comprendre le nombre de passagers par jour, alors j'ai cherché des données accessibles au public. commencé.
Obtention et nettoyage des données publiques
Pour dire la vérité, je n'ai pas vraiment vu de jeux de données publics japonais jusqu'à présent. Quand j'ai commencé à le chercher, j'ai découvert que les statistiques que chaque ministère et agence connaissaient étaient ouvertes au public, mais il y a toujours une forte tendance à la publier sous forme de phrase que les gens peuvent lire __. Il s'agit d'un ensemble de données très simple appelé "Nombre de passagers par gare", mais le tableau n'est pas publié sous la forme d'une paire nom_base_de passagers. Ce sont ces données que j'ai "fouillé" cette fois:
Puisqu'il est publié sous forme de fichier XML, j'ai pensé qu'il devrait être relativement facile à traiter, j'ai donc commencé à travailler, mais l'analyseur s'est soudainement cassé. La cause était une simple erreur de fermeture de la balise,
cat S12-13.xml | sed -e "s/ksj:ailroad/ksj:railroad/" > fixed.xml
Il peut être réparé avec.
Problèmes lors de l'utilisation réelle
Quand j'ai déplacé mes mains et examiné le contenu, j'ai réalisé que cela ne pouvait pas être aussi simple que je m'y attendais. Certains des problèmes sont:
- Le nombre de passagers ne correspond pas toujours aux données de chaque gare
- Certaines données sont combinées avec d'autres stations
- Perte de données - Certaines stations n'ont pas de données en premier lieu
- ID de la destination totale des données totales
- La méthode du total lors de la totalisation est écrite en langage naturel dans la colonne __ remarques __
- Il n'y a pas d'identifiant de la destination totale
À ce stade, j'étais un peu moins motivé, mais j'ai décidé de ne faire que la partie que je pouvais faire comme démonstration de la méthode, et j'ai procédé sans voir une telle partie (je pense que cela ne se fera pas au travail ...) .. Après avoir fait un travail ridicule comme celui de la note, j'ai obtenu un tableau comme celui-ci:

J'ai écrit dans le cahier pourquoi j'ai volontairement converti les informations codées en informations de chaîne de caractères redondantes, mais il est plus facile de travailler avec un logiciel de visualisation en l'enregistrant sous forme de chaîne de caractères lisible par l'homme. .. __ Ce type de travail est plutôt nuisible pour l'analyse et la visualisation à grande échelle, alors déterminez la taille de l'ensemble de données, etc., comparez la commodité avec le poids de l'ordinateur et utilisez une méthode appropriée. Choisissons __.
Obtention d'informations sur la couleur du thème d'itinéraire en grattant
Depuis que WWW a commencé avec l'idée de lier des textes lisibles par l'homme, il existe une énorme quantité de données publiées sous forme de tableaux conçus pour la lecture humaine sans supposer qu'ils seront traités par des machines. Et ces données sont étonnamment utiles et les informations que vous souhaitez utiliser sont enterrées.
Lors de la visualisation du réseau avec Cytoscape, vous pouvez créer librement une carte de couleurs personnalisée pour tous les éléments à l'écran. Pour cet ensemble de données, il est plus facile à comprendre et plus efficace d'utiliser quelque chose que les gens connaissent bien que de définir vous-même le code couleur. Pour le métro de Tokyo, les couleurs suivantes sont standard:
 ([Wikimedia Commons](http://commons.wikimedia.org/wiki/File:Tokyo_metro_map.png#mediaviewer/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB : De Tokyo_metro_map.png))
([Wikimedia Commons](http://commons.wikimedia.org/wiki/File:Tokyo_metro_map.png#mediaviewer/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB : De Tokyo_metro_map.png))
Je me suis demandé si je pouvais obtenir ces informations de couleur dans un format de fichier qui pourrait être facilement lu par une machine, mais malheureusement je ne pouvais pas les trouver (veuillez me le faire savoir si quelqu'un le sait). Cependant, il a été bien publié sous forme de phrase lisible par l'homme:
- [Liste des couleurs des lignes de chemin de fer japonaises](http://ja.wikipedia.org/wiki/%E6%97%A5%E6%9C%AC%E3%81%AE%E9%89%84%E9%81] % 93% E3% 83% A9% E3% 82% A4% E3% 83% B3% E3% 82% AB% E3% 83% A9% E3% 83% BC% E4% B8% 80% E8% A6% A7 )
J'ai donc décidé de le couper de force de cette page. Il existe diverses exceptions aux données enfouies dans ce texte, mais dans de nombreux cas, il existe des modèles, il est donc facile de jeter un coup d'œil rapide:
<tr style="height:20px;">
<td>Ligne 3</td>
<td>
<a href="/wiki/%E6%9D%B1%E4%BA%AC%E3%83%A1%E3%83%88%E3%83%AD%E9%8A%80%E5%BA%A7%E7%B7%9A" title="Ligne Tokyo Metro Ginza">
Ligne Ginza
</a>
</td>
<td>G</td>
<td style="background:#f39700; width:20px;"> </td>
<td><b>Orange</b></td>
</tr>
Si vous combinez les données __ # f39700__ avec la clé __ Tokyo Metro Ginza Line __, elles seront lues par Cytoscape et les données de couleur seront _ [Passthrough Mapping](http: //wiki.cytoscape). Vous pouvez l'utiliser tel quel avec .org / Cytoscape_3 / UserManual # Cytoscape_3.2BAC8-UserManual.2BAC8-Styles.How_Mappings_Work) _. Heureusement, Python a beaucoup de bibliothèques pour faire ce genre de travail de grattage, donc je les ai utilisées pour faire un premier montage. Ce travail peut être amélioré autant que vous le souhaitez, mais à des fins de démonstration, il peut être sale, j'ai donc gardé les résultats au minimum.
Vérifiez le résultat du grattage
Cette fois, nous allons visualiser le thème du métro de Tokyo, alors assurez-vous que les données de cette partie sont correctement prises. Faisons-le avec une doublure.
Ligne de métro grep Tokyo_colors.csv | awk -F ',' '{print "<span style=\"color:" $3 "\">" $2 "</span><br />"}' > metro_colors.html
Le résultat ressemble à ceci, et vous pouvez voir qu'il n'y a aucun problème à le comparer avec les données d'origine:
(Generated HTML)

(Original Table)

Comme mentionné ci-dessus, y compris la partie précédente, Tout le travail est enregistré dans IPython Notebook. , L'exécution elle-même prendra des dizaines de secondes. Si vous êtes intéressé, veuillez consulter le fichier texte généré (CSV). Tous ces éléments peuvent être facilement chargés dans Cytoscape.
Intégration et cartographie sur Cytoscape
Maintenant, c'est enfin la visualisation avec Cytoscape. Mais ça devient assez long, donc je reporte les détails de cette partie la prochaine fois. En guise d'aperçu suivant, je présenterai brièvement le type de traitement possible une fois qu'il est chargé dans Cytoscape.
Le bureau sur lequel vous travaillez avec tout chargé
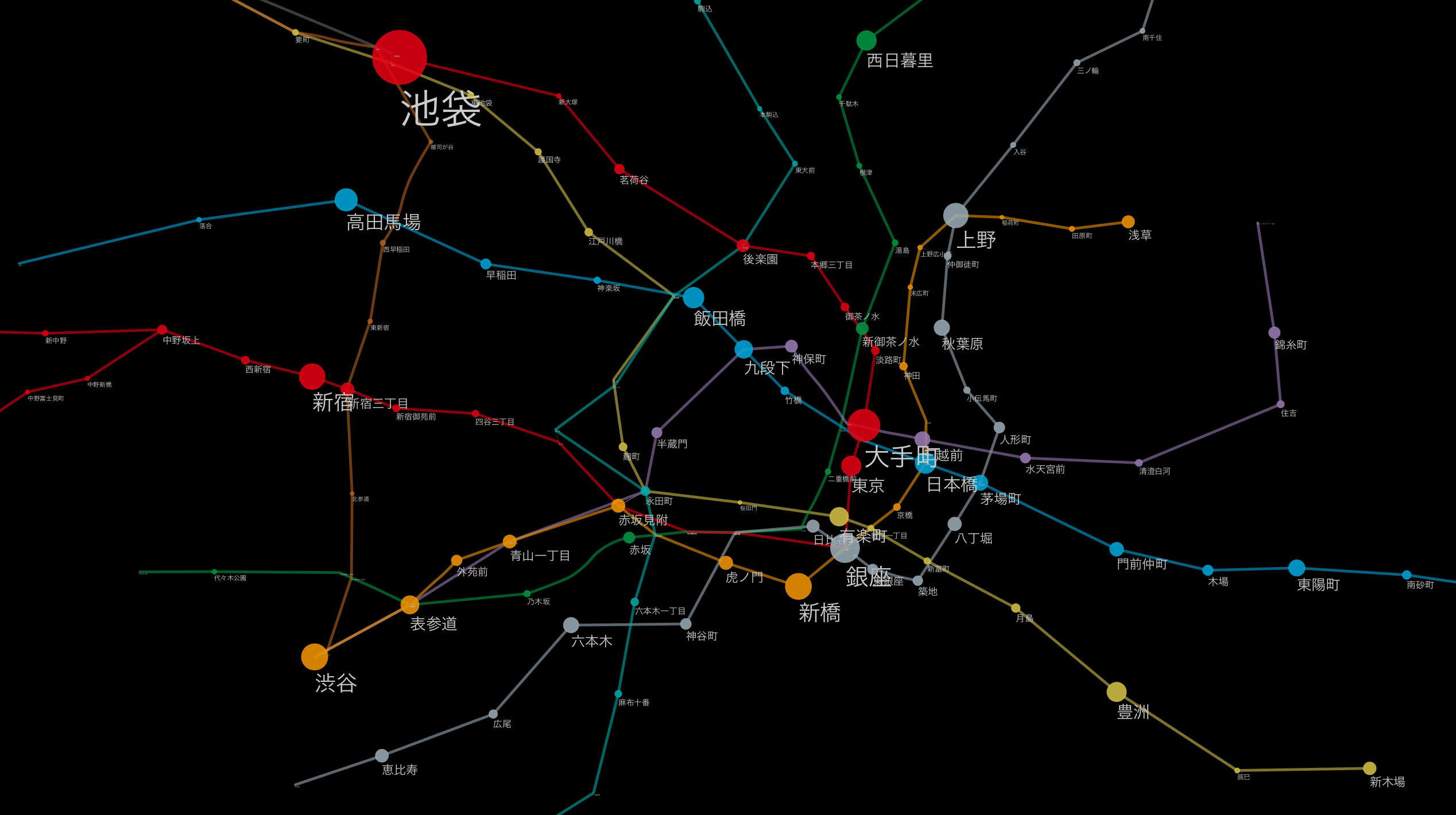
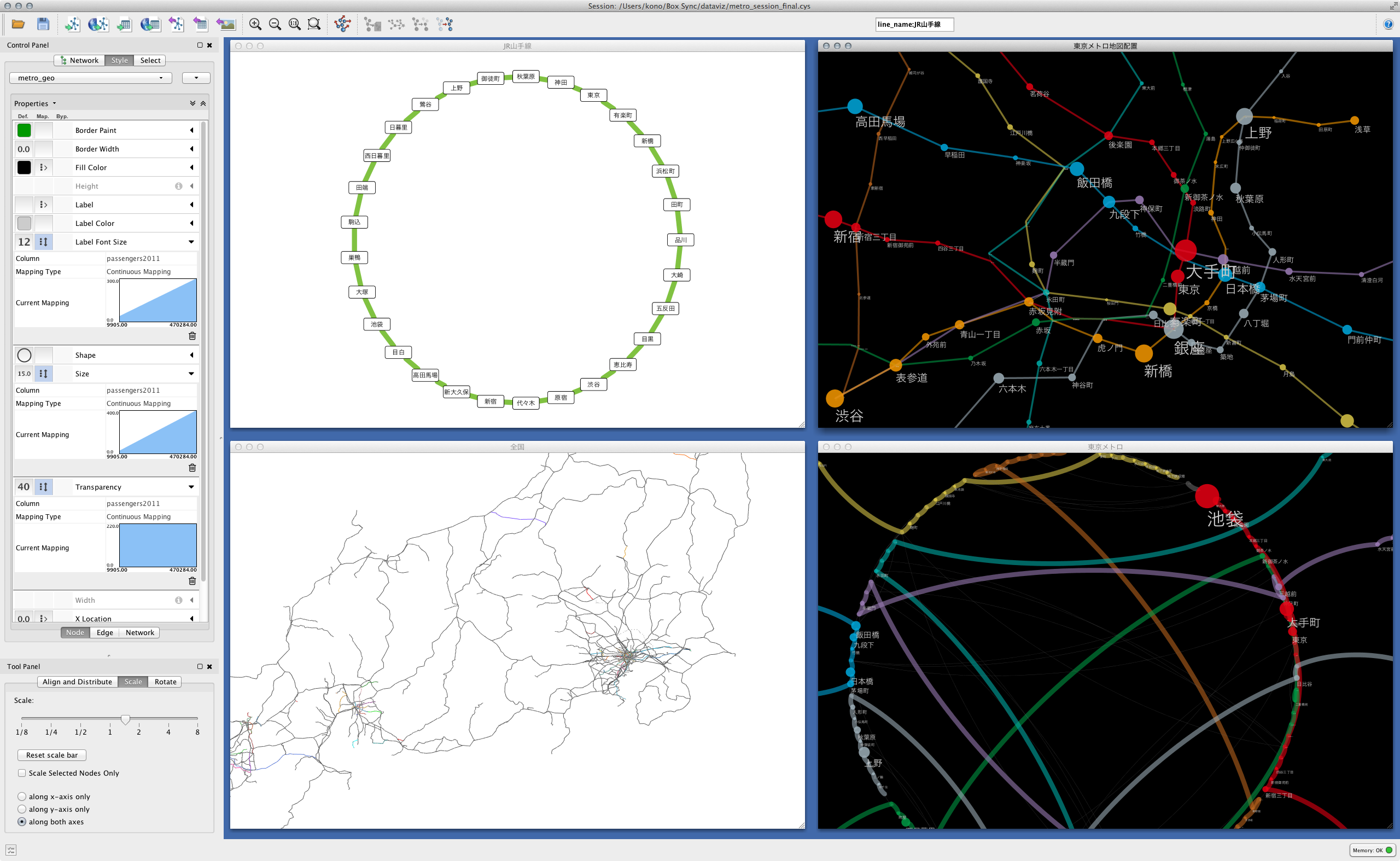 (
(Chaque station du métro de Tokyo montrant la relation de position relative en utilisant la position sur la carte
 (
(Un exemple d'application d'un autre algorithme de mise en page.
La taille des étiquettes correspond au nombre de passagers par jour
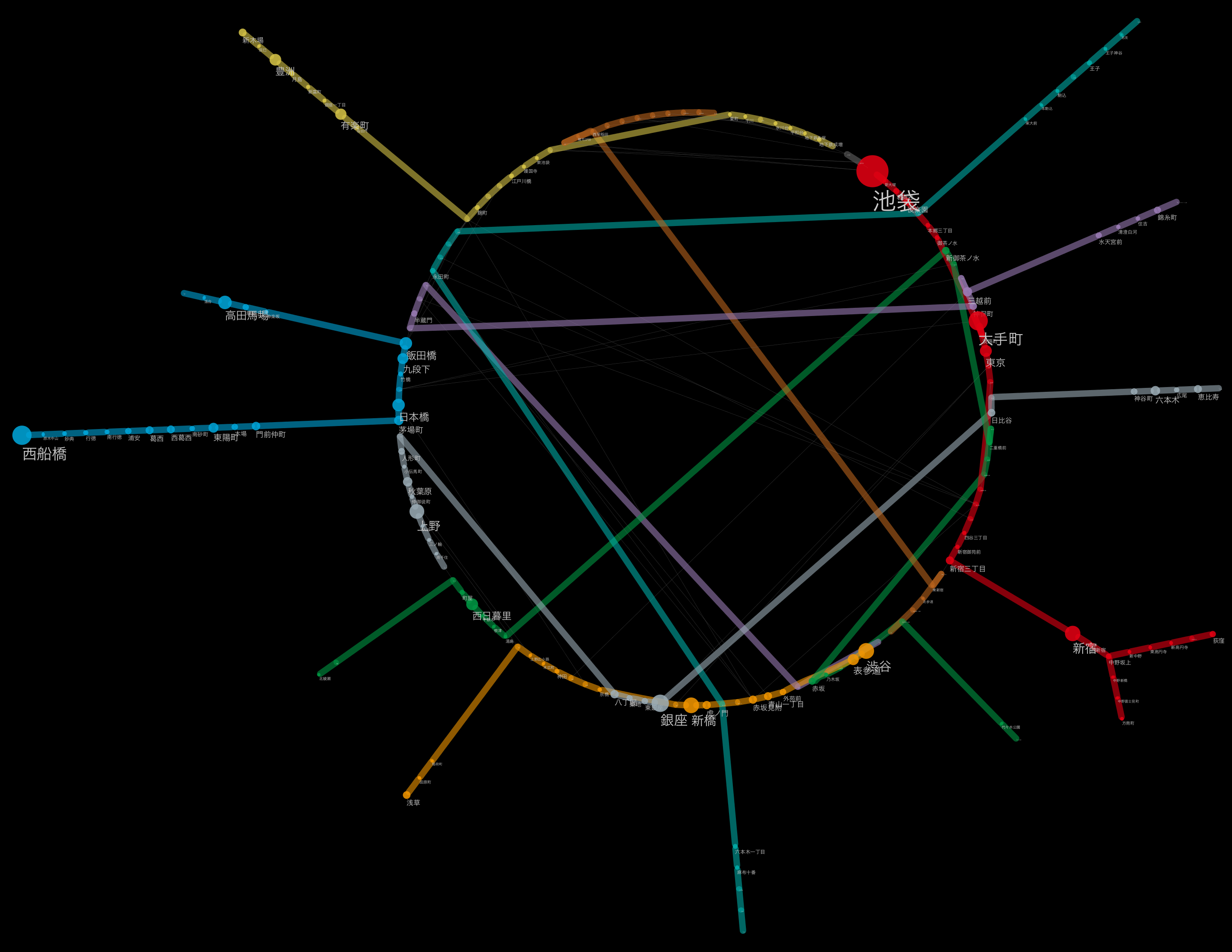 (
(Ligne Yamate comme simple schéma de connexion
 (
(Combinez la mise en page automatique et manuelle (mise en page appliquée pour chaque itinéraire)
 (
(À la fin
__ "Toutes les statistiques publiques sont publiées sous une forme lisible par machine, les personnes qui parlent de code les utilisent pour créer de nouvelles applications créatrices de valeur et les statisticiens obtiennent de nouvelles informations à partir des résultats de leur intégration."
Un tel monde peut venir un jour. Mais au moins pour le moment, c'est la réalité. Déterrer des «données sales», les nettoyer et les rassembler sous une forme utilisable est une tâche très régulière et ennuyeuse, mais c'est un processus inévitable à l'heure actuelle. Les outils sont prêts. Si vous pouvez écrire du code, déplacez votre main et répertoriez ce qui ne va pas. Et disons au fournisseur. À long terme, c'est probablement la seule solution.
Comme le comprendra quiconque a lu le Notebook, c'est un clic général. Contrairement à la programmation, lors de la préparation des données pour une visualisation particulière, j'ai une politique de __ selon laquelle vous pouvez relire ce que vous avez fait plutôt que __ efficacité ou élégance. Des essais et des erreurs sont toujours nécessaires en termes de réutilisabilité du flux de travail, mais il s'agit d'une application de visualisation (Cytoscape, bien sûr, D3.js plutôt que de faire des choses plus élaborées que nécessaire. Il peut être nécessaire pour les personnes travaillant dans le domaine de la visualisation de se concentrer sur la création d'un ensemble de données facile à utiliser qui peut être utilisé dans (y compris les applications de visualisation personnalisées créées dans) et de poursuivre le travail tout en faisant des compromis. ne pas. Il est désormais possible de combiner des outils tels que Git, IPython Notebook et RStudio pour sauvegarder automatiquement les enregistrements incluant le processus de réflexion sans stress. Je pense que c'est une bonne idée de les utiliser pour trouver progressivement un flux de travail qui vous convient.
Je suis désolé pour ceux qui ne sont pas membres car il s'agit d'un groupe FB, mais si vous êtes intéressé par une telle visualisation, veuillez rejoindre ce groupe. Nous prévoyons de partager les problèmes et le savoir-faire. Un groupe pour les personnes qui bougent leurs mains dans le domaine de la visualisation.
Suite du 3
Recommended Posts